Domain Arithmetic: One-Shot VLA Adaptation under Environmental Shifts
Pith reviewed 2026-07-02 11:33 UTC · model grok-4.3
The pith
VLA models adapt to new camera views or robot bodies using one demonstration by adding isolated domain information via weight arithmetic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
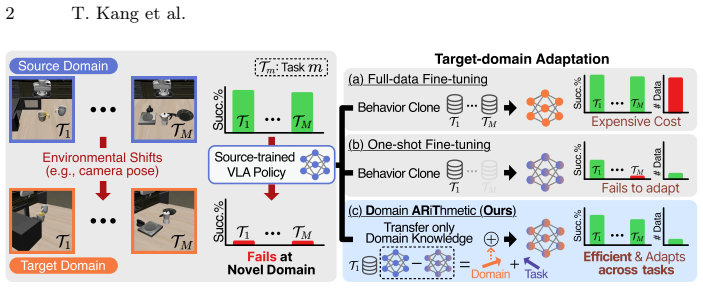
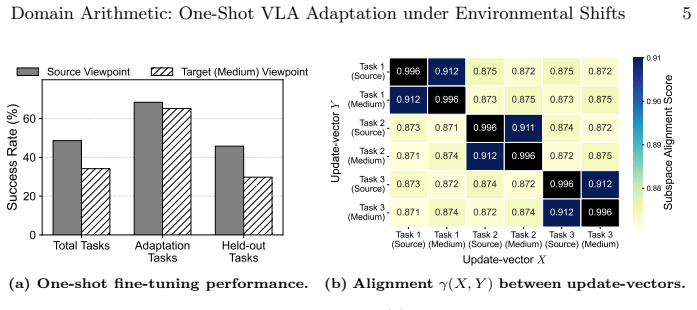
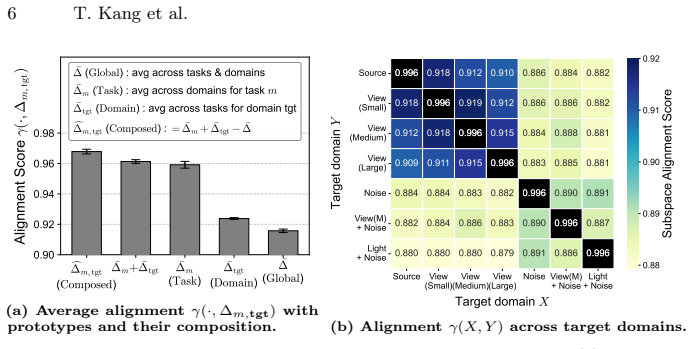
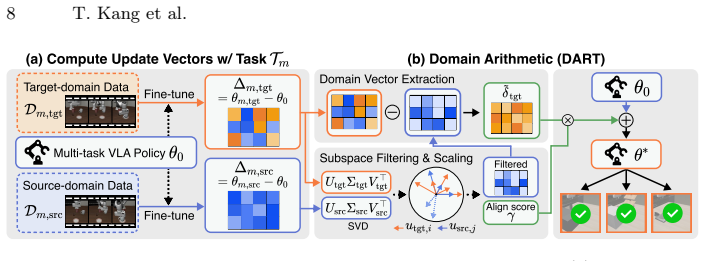
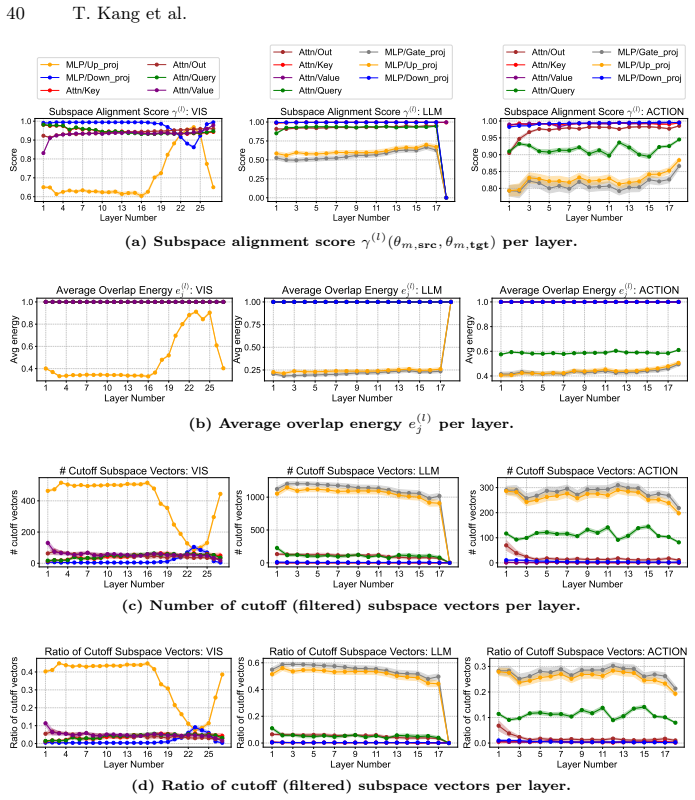
DART adapts pretrained VLA models to a target domain under environmental shifts by collecting one demonstration, extracting domain-specific information through subspace alignment between singular components in weight vectors, and incorporating that information via weight vector arithmetic.
What carries the argument
Domain ARiThmetic (DART), which isolates domain-specific information via subspace alignment of singular components in weight vectors before performing addition through vector arithmetic.
If this is right
- Only one demonstration per task is needed for adaptation instead of multiple.
- The method outperforms prior one-shot VLA adaptation techniques in both simulation and real-world tests.
- It handles both visual shifts like camera pose changes and embodiment shifts like switching between similar robot arms.
- No full retraining on target-domain data is required beyond the single demonstration.
Where Pith is reading between the lines
- The subspace alignment step could be tested on other weight-based adaptation problems outside VLA models.
- If the arithmetic generalizes, similar one-shot methods might apply to transferring policies across different sensor setups.
- Reducing data collection to one example could allow faster iteration when deploying VLA systems in new physical layouts.
Load-bearing premise
That subspace alignment between singular components in weight vectors from a single demonstration can accurately separate domain-specific information from task content and noise.
What would settle it
In controlled trials on new visual or embodiment shifts, the one-shot DART-adapted model performs no better than the unadapted baseline or falls short of models trained on multiple demonstrations from the target domain.
Figures



read the original abstract
Vision-Language-Action (VLA) models often fail to perform the same learned tasks under environmental shifts, such as changes in camera pose and shifts to a different but similar robot (e.g., from Panda to UR5e). Adapting these models to the shifted environment (i.e., target domain) often requires training on multiple demonstrations for each task, which are costly to collect. To reduce the burden of data curation and training, we propose an analogy-based method that adapts VLA models under environmental shifts through weight vector arithmetic with domain-specific information addition, named Domain ARiThmetic (DART). Unlike prior approaches, DART requires collecting only a single demonstration, enabling efficient adaptation. To accurately isolate domain-specific information for addition, DART performs subspace alignment between singular components in weight vectors to filter out noisy components. In both simulated and real-world experiments, DART outperforms existing VLA adaptation methods in one-shot scenarios across diverse visual and embodiment shifts. Code is available at https://github.com/snumprlab/dart.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Domain ARiThmetic (DART), a one-shot adaptation method for Vision-Language-Action (VLA) models under environmental shifts (e.g., camera pose changes or embodiment shifts like Panda to UR5e). It derives a domain vector via weight arithmetic from a single demonstration and applies subspace alignment using SVD on singular components to isolate domain-specific information before addition. Experiments in simulation and real-world settings claim DART outperforms prior VLA adaptation methods across visual and embodiment shifts. Code is released at https://github.com/snumprlab/dart.
Significance. If the central claims hold after addressing validation gaps, the work would meaningfully lower the data-collection cost for deploying VLA models in new environments, a practical bottleneck in robotics. The explicit release of code is a positive contribution to reproducibility.
major comments (2)
- [Method] Method section (DART derivation and subspace alignment): the claim that SVD-based alignment on singular components isolates domain factors from a single demonstration rests on an untested separability assumption. No analysis is provided of singular-spectrum stability across multiple single demonstrations of the same task, nor a control experiment showing that alignment removes trajectory/gripper/visual noise rather than useful signal. This directly undermines the one-shot isolation guarantee.
- [Experiments] Experiments section: the reported outperformance in one-shot scenarios is presented without ablations that isolate the contribution of the alignment step versus plain weight arithmetic, or without reporting variance across different choices of the single demonstration. This makes it impossible to confirm that gains arise from the proposed filtering rather than from other implementation details.
minor comments (2)
- [Method] Notation for the domain vector and the SVD truncation threshold should be defined explicitly with an equation number rather than described in prose only.
- [Experiments] Figure captions for the real-world robot setups should include the exact number of trials and success criteria to allow direct comparison with baselines.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address the major concerns point-by-point below, proposing revisions to enhance the clarity and rigor of our claims regarding DART's one-shot adaptation method.
read point-by-point responses
-
Referee: [Method] Method section (DART derivation and subspace alignment): the claim that SVD-based alignment on singular components isolates domain factors from a single demonstration rests on an untested separability assumption. No analysis is provided of singular-spectrum stability across multiple single demonstrations of the same task, nor a control experiment showing that alignment removes trajectory/gripper/visual noise rather than useful signal. This directly undermines the one-shot isolation guarantee.
Authors: The subspace alignment in DART is derived from the principle that domain shifts manifest as consistent directions in the weight space, separable via SVD from task-specific components. While we did not include explicit stability analysis in the original submission, the empirical success across diverse shifts supports the practical utility of the approach. We will revise the manuscript to include an analysis of singular spectrum stability using multiple single-demonstration examples and a control experiment to verify that the alignment primarily filters noise rather than signal. revision: yes
-
Referee: [Experiments] Experiments section: the reported outperformance in one-shot scenarios is presented without ablations that isolate the contribution of the alignment step versus plain weight arithmetic, or without reporting variance across different choices of the single demonstration. This makes it impossible to confirm that gains arise from the proposed filtering rather than from other implementation details.
Authors: We agree that ablations are necessary to attribute performance gains specifically to the subspace alignment. In the revised manuscript, we will add an ablation study comparing DART with and without the SVD-based alignment, as well as report standard deviations or variance metrics across different selections of the single demonstration used for domain vector computation. revision: yes
Circularity Check
No circularity: method is a direct procedural construction without self-referential reduction
full rationale
The paper presents DART as a procedural adaptation technique that extracts a domain vector from one demonstration via weight arithmetic, followed by SVD-based subspace alignment to filter components before addition. No equations, derivations, or claims in the provided text reduce a 'prediction' or result to the input by construction (e.g., no parameter fitted on a subset then renamed as a prediction of a related quantity). No self-citations are invoked as load-bearing for uniqueness or ansatz. The central claim rests on an empirical assumption about singular vector separability, which is an untested modeling choice rather than a definitional loop. This qualifies as a self-contained method proposal with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.14117 (2025)
Abouzeid, A., Mansour, M., Sun, Z., Song, D.: Geoaware-vla: Implicit geometry aware vision-language-action model. arXiv preprint arXiv:2509.14117 (2025)
-
[2]
PaliGemma: A versatile 3B VLM for transfer
Beyer, L., Steiner, A., Pinto, A.S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., et al.: Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: CoRL (2025)
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M.R., Finn, C., Fusai, N., Galliker, M.Y., et al.:π0.5: A vision-language-action model with open-world generalization. In: CoRL (2025)
2025
-
[5]
RSS (2025)
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. RSS (2025)
2025
-
[6]
In: CoRL (2024)
Chen, L.Y., Xu, C., Dharmarajan, K., Irshad, M.Z., Cheng, R., Keutzer, K., Tomizuka, M., Vuong, Q., Goldberg, K.: Rovi-aug: Robot and viewpoint augmenta- tion for cross-embodiment robot learning. In: CoRL (2024)
2024
-
[7]
NeurIPS (2019)
Chen, X., Wang, S., Fu, B., Long, M., Wang, J.: Catastrophic forgetting meets negative transfer: Batch spectral shrinkage for safe transfer learning. NeurIPS (2019)
2019
-
[8]
In: ICML (2025)
Cheng, R., Xiong, F., Wei, Y., Zhu, W., Yuan, C.: Whoever started the interference should end it: Guiding data-free model merging via task vectors. In: ICML (2025)
2025
-
[9]
In: ICML (2026)
Choi, H., Ahn, D., Lee, Y., Kang, T., Cho, S., Choi, J.: Scale: Self-uncertainty conditioned adaptive looking and execution for vision-language-action models. In: ICML (2026)
2026
-
[10]
In: EMNLP Workshop (2024)
Chronopoulou, A., Pfeiffer, J., Maynez, J., Wang, X., Ruder, S., Agrawal, P.: Language and task arithmetic with parameter-efficient layers for zero-shot summa- rization. In: EMNLP Workshop (2024)
2024
-
[11]
In: CoRL Workshop (2025)
Dass, S., Khaddaj, A., Engstrom, L., Madry, A., Ilyas, A., Martín-Martín, R.: Datamil: Selecting data for robot imitation learning with datamodels. In: CoRL Workshop (2025)
2025
-
[12]
In: ICRA (2025)
Dey, S., Zaech, J.N., Nikolov, N., Van Gool, L., Paudel, D.P.: Revla: Reverting visual domain limitation of robotic foundation models. In: ICRA (2025)
2025
-
[13]
In: CVPR (2026)
Fei, S., Wang, S., Shi, J., Dai, Z., Cai, J., Qian, P., Ji, L., He, X., Zhang, S., Fei, Z., et al.: Libero-plus: In-depth robustness analysis of vision-language-action models. In: CVPR (2026)
2026
-
[14]
In: CVPR (2026)
Fu, Y., Zhang, Z., Zhang, Y., Wang, Z., Huang, Z., Luo, Y.: Mergevla: Cross-skill model merging toward a generalist vision-language-action agent. In: CVPR (2026)
2026
-
[15]
RA-L (2026)
Gao, J., Belkhale, S., Dasari, S., Balakrishna, A., Shah, D., Sadigh, D.: A taxonomy for evaluating generalist robot manipulation policies. RA-L (2026)
2026
-
[16]
In: CVPR (2025)
Gargiulo, A.A., Crisostomi, D., Bucarelli, M.S., Scardapane, S., Silvestri, F., Rodola, E.: Task singular vectors: Reducing task interference in model merging. In: CVPR (2025)
2025
-
[17]
SIAM review53(2), 217–288 (2011)
Halko, N., Martinsson, P.G., Tropp, J.A.: Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM review53(2), 217–288 (2011)
2011
-
[18]
In: ICLR (2022) Domain Arithmetic: One-Shot VLA Adaptation under Environmental Shifts 17
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. In: ICLR (2022) Domain Arithmetic: One-Shot VLA Adaptation under Environmental Shifts 17
2022
-
[19]
In: ACL (2024)
Huang, S.C., Li, P.Z., Hsu, Y.C., Chen, K.M., Lin, Y.T., Hsiao, S.K., Tsai, R., Lee, H.Y.: Chat vector: A simple approach to equip llms with instruction following and model alignment in new languages. In: ACL (2024)
2024
-
[20]
In: ICLR (2023)
Ilharco, G., Ribeiro, M.T., Wortsman, M., Schmidt, L., Hajishirzi, H., Farhadi, A.: Editing models with task arithmetic. In: ICLR (2023)
2023
-
[21]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Intelligence, P., Amin, A., Aniceto, R., Balakrishna, A., Black, K., Conley, K., Connors, G., Darpinian, J., Dhabalia, K., DiCarlo, J., et al.:π∗ 0.6: a vla that learns from experience. arXiv preprint arXiv:2511.14759 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
In: CoRL (2024)
Iyer, A., Peng, Z., Dai, Y., Guzey, I., Haldar, S., Chintala, S., Pinto, L.: Open teach: A versatile teleoperation system for robotic manipulation. In: CoRL (2024)
2024
-
[23]
In: ECCV (2024)
Jang, D.H., Yun, S., Han, D.: Model stock: All we need is just a few fine-tuned models. In: ECCV (2024)
2024
-
[24]
In: ICLR (2025)
Jin, R., Hou, B., Xiao, J., Su, W.J., Shen, L.: Fine-tuning attention modules only: Enhancing weight disentanglement in task arithmetic. In: ICLR (2025)
2025
-
[25]
In: RSS (2024)
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M.K., Chen, L.Y., Ellis, K., et al.: Droid: A large-scale in-the-wild robot manipulation dataset. In: RSS (2024)
2024
-
[26]
In: RSS (2025)
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success. In: RSS (2025)
2025
-
[27]
In: CoRL (2024)
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E.P., Sanketi, P.R., Vuong, Q., et al.: Openvla: An open-source vision- language-action model. In: CoRL (2024)
2024
-
[28]
In: CoRL (2025)
Kumar, S., Dass, S., Pavlakos, G., Martín-Martín, R.: Collage: Adaptive fusion- based retrieval for augmented policy learning. In: CoRL (2025)
2025
-
[29]
In: ICRA (2024)
Lawson, D., Qureshi, A.H.: Merging decision transformers: Weight averaging for forming multi-task policies. In: ICRA (2024)
2024
-
[30]
In: ICML (2024)
Lee, S., Wang, Y., Etukuru, H., Kim, H.J., Shafiullah, N.M.M., Pinto, L.: Behavior generation with latent actions. In: ICML (2024)
2024
-
[31]
In: ICML (2024)
Li, N., Pan, A., Gopal, A., Yue, S., Berrios, D., Gatti, A., Li, J.D., Dombrowski, A.K., Goel, S., Mukobi, G., Helm-Burger, N., Lababidi, R., Justen, L., Liu, A.B., Chen, M., Barrass, I., Zhang, O., Zhu, X., Tamirisa, R., Bharathi, B., Herbert-Voss, A., Breuer, C.B., Zou, A., Mazeika, M., Wang, Z., Oswal, P., Lin, W., Hunt, A.A., Tienken-Harder, J., Shih,...
2024
-
[32]
In: CVPR (2026)
Li, W., Zhang, Q., Zhai, R., Lin, L., Wang, G.: Vla models are more generalizable than you think: Revisiting physical and spatial modeling. In: CVPR (2026)
2026
-
[33]
In: CoRL (2024)
Li, X., Hsu, K., Gu, J., Mees, O., Pertsch, K., Walke, H.R., Fu, C., Lunawat, I., Sieh, I., Kirmani, S., et al.: Evaluating real-world robot manipulation policies in simulation. In: CoRL (2024)
2024
-
[34]
In: ICML (2026)
Li, Y., Peng, Z., Zhang, J., Guo, J., Duan, Y., Shi, Y.: When shared knowledge hurts: Spectral over-accumulation in model merging. In: ICML (2026)
2026
-
[35]
arXiv preprint arXiv:2507.00416 (2025)
Lin, T., Li, G., Zhong, Y., Zou, Y., Du, Y., Liu, J., Gu, E., Zhao, B.: Evo-0: Vision-language-action model with implicit spatial understanding. arXiv preprint arXiv:2507.00416 (2025)
-
[36]
In: ICLR (2023)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: ICLR (2023)
2023
-
[37]
In: NeurIPS (2023) 18 T
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Benchmarking knowledge transfer for lifelong robot learning. In: NeurIPS (2023) 18 T. Kang et al
2023
-
[38]
In: NeurIPS (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2023)
2023
-
[39]
In: CVPR (2026)
Liu, S., Yin, Y., Wang, L., Fan, Q., Shi, Y., Li, W., Gao, Y., Tao, D.: Understanding and enforcing weight disentanglement in task arithmetic. In: CVPR (2026)
2026
-
[40]
In: CVPRW (2026)
Liu, S., Singh, I.S., Xu, Y., Duan, J., Krishna, R.: Vls: Steering pretrained robot policies via vision-language models. In: CVPRW (2026)
2026
-
[41]
In: ICLR (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019)
2019
-
[42]
In: CoRL (2023)
Mandlekar, A., Nasiriany, S., Wen, B., Akinola, I., Narang, Y., Fan, L., Zhu, Y., Fox, D.: Mimicgen: A data generation system for scalable robot learning using human demonstrations. In: CoRL (2023)
2023
-
[43]
In: ICML (2025)
Marczak, D., Magistri, S., Cygert, S., Twardowski, B., Bagdanov, A.D., van de Weijer, J.: No task left behind: Isotropic model merging with common and task- specific subspaces. In: ICML (2025)
2025
-
[44]
In: NeurIPS (2022)
Meng, K., Bau, D., Andonian, A., Belinkov, Y.: Locating and editing factual associations in gpt. In: NeurIPS (2022)
2022
-
[45]
In: ICLR (2023)
Meng, K., Sen Sharma, A., Andonian, A., Belinkov, Y., Bau, D.: Mass editing memory in a transformer. In: ICLR (2023)
2023
-
[46]
In: CoRL (2022)
Nair, S., Rajeswaran, A., Kumar, V., Finn, C., Gupta, A.: R3m: A universal visual representation for robot manipulation. In: CoRL (2022)
2022
-
[47]
In: NeurIPS (2023)
Ortiz-Jimenez, G., Favero, A., Frossard, P.: Task arithmetic in the tangent space: Improved editing of pre-trained models. In: NeurIPS (2023)
2023
-
[48]
In: ICRA (2024)
O’Neill, A., Rehman, A., Maddukuri, A., Gupta, A., Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., et al.: Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In: ICRA (2024)
2024
-
[49]
In: NeurIPS (2025)
Panariello, A., Marczak, D., Magistri, S., Porrello, A., Twardowski, B., Bagdanov, A.D., Calderara, S., van de Weijer, J.: Accurate and efficient low-rank model merging in core space. In: NeurIPS (2025)
2025
-
[50]
In: RSS (2025)
Pertsch, K., Stachowicz, K., Ichter, B., Driess, D., Nair, S., Vuong, Q., Mees, O., Finn, C., Levine, S.: Fast: Efficient action tokenization for vision-language-action models. In: RSS (2025)
2025
-
[51]
In: EMNLP (2025)
Qiu, H., Wu, Y., Li, D., Guo, J., Yao, Q.: Superpose task-specific features for model merging. In: EMNLP (2025)
2025
-
[52]
arXiv preprint arXiv:2508.21112 (2025)
Qu, D., Song, H., Chen, Q., Chen, Z., Gao, X., Ye, X., Lv, Q., Shi, M., Ren, G., Ruan, C., et al.: Eo-1: Interleaved vision-text-action pretraining for general robot control. arXiv preprint arXiv:2508.21112 (2025)
-
[53]
In: ICLR (2026)
Seo, M., Kim, T., Lee, H., Choi, J., Tuytelaars, T.: Not all clients are equal: Collaborative model personalization on heterogeneous multi-modal clients. In: ICLR (2026)
2026
-
[54]
In: NeurIPS (2022)
Shafiullah, N.M., Cui, Z., Altanzaya, A.A., Pinto, L.: Behavior transformers: Cloning kmodes with one stone. In: NeurIPS (2022)
2022
-
[55]
Action Hallucination in Generative Vision-Language-Action Models
Soh, H., Lim, E.: Action hallucination in generative visual-language-action models. arXiv preprint arXiv:2602.06339 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
In: ICLR (2025)
Stoica, G., Ramesh, P., Ecsedi, B., Choshen, L., Hoffman, J.: Model merging with svd to tie the knots. In: ICLR (2025)
2025
-
[57]
In: ICML (2025)
Sun, W., Li, Q., Geng, Y., Li, B.: Cat merging: A training-free approach for resolving conflicts in model merging. In: ICML (2025)
2025
-
[58]
In: ACL (2025)
Thakkar, M., Fournier, Q., Riemer, M., Chen, P.Y., Zouaq, A., Das, P., Chandar, S.: Combining domain and alignment vectors to achieve better knowledge-safety trade-offs in llms. In: ACL (2025)
2025
-
[59]
In: IROS (2012) Domain Arithmetic: One-Shot VLA Adaptation under Environmental Shifts 19
Todorov, E., Erez, T., Tassa, Y.: Mujoco: A physics engine for model-based control. In: IROS (2012) Domain Arithmetic: One-Shot VLA Adaptation under Environmental Shifts 19
2012
-
[60]
In: CoRL (2023)
Walke, H.R., Black, K., Zhao, T.Z., Vuong, Q., Zheng, C., Hansen-Estruch, P., He, A.W., Myers, V., Kim, M.J., Du, M., et al.: Bridgedata v2: A dataset for robot learning at scale. In: CoRL (2023)
2023
-
[61]
In: ICLR (2024)
Wang, L., Zhang, K., Zhou, A., Simchowitz, M., Tedrake, R.: Robot fleet learning via policy merging. In: ICLR (2024)
2024
-
[62]
In: ICLR (2026)
Wei, Y., Cheng, R., Jin, W., Yang, E., Shen, L., Hou, L., Du, S., Yuan, C., Cao, X., Tao, D.: Optmerge: Unifying multimodal llm capabilities and modalities via model merging. In: ICLR (2026)
2026
-
[63]
In: CoRL (2025)
Wilcox, A., Ghanem, M., Moghani, M., Barroso, P., Joffe, B., Garg, A.: Adapt3r: Adaptive 3d scene representation for domain transfer in imitation learning. In: CoRL (2025)
2025
-
[64]
In: CoRL (2025)
Xie, A., Chand, R., Sadigh, D., Hejna, J.: Data retrieval with importance weights for few-shot imitation learning. In: CoRL (2025)
2025
-
[65]
In: ICRA (2024)
Xie, A., Lee, L., Xiao, T., Finn, C.: Decomposing the generalization gap in imitation learning for visual robotic manipulation. In: ICRA (2024)
2024
-
[66]
In: NeurIPS (2023)
Yadav, P., Tam, D., Choshen, L., Raffel, C.A., Bansal, M.: Ties-merging: Resolving interference when merging models. In: NeurIPS (2023)
2023
-
[67]
In: ICLR (2026)
Yadav, Y., Zhou, Z., Wagenmaker, A., Pertsch, K., Levine, S.: Robust finetuning of vision-language-action robot policies via parameter merging. In: ICLR (2026)
2026
-
[68]
In: NeurIPS (2025)
Yang, J., Jin, D., Tang, A., Shen, L., Zhu, D., Chen, Z., Zhao, Z., Wang, D., Cui, Q., Zhang, Z., et al.: Mix data or merge models? balancing the helpfulness, honesty, and harmlessness of large language model via model merging. In: NeurIPS (2025)
2025
-
[69]
In: RSS (2025)
Yang, S., Yu, W., Zeng, J., Lv, J., Ren, K., Lu, C., Lin, D., Pang, J.: Novel demon- stration generation with gaussian splatting enables robust one-shot manipulation. In: RSS (2025)
2025
-
[70]
arXiv preprint arXiv:2602.09021 (2026)
Yu, C., Sima, C., Jiang, G., Zhang, H., Mai, H., Li, H., Wang, H., Chen, J., Wu, K., Chen, L., Zhao, L., Shi, M., Luo, P., Bu, Q., Peng, S., Li, T., Yuan, Y.:χ0: Resource-aware robust manipulation via taming distributional inconsistencies. arXiv preprint arXiv:2602.09021 (2026)
-
[71]
In: ICML (2024)
Yu, L., Yu, B., Yu, H., Huang, F., Li, Y.: Language models are super mario: Absorbing abilities from homologous models as a free lunch. In: ICML (2024)
2024
-
[72]
Scaling Robot Learning with Semantically Imagined Experience
Yu, T., Xiao, T., Stone, A., Tompson, J., Brohan, A., Wang, S., Singh, J., Tan, C., Peralta, J., Ichter, B., et al.: Scaling robot learning with semantically imagined experience. In: arXiv preprint arXiv:2302.11550 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
In: CVPR (2025)
Yun, S., Chae, S., Lee, D., Ro, Y.: Soma: Singular value decomposed minor com- ponents adaptation for domain generalizable representation learning. In: CVPR (2025)
2025
-
[74]
In: ICRA (2025)
Zhang, W., Li, Y., Qiao, Y., Huang, S., Liu, J., Dayoub, F., Ma, X., Liu, L.: Effective tuning strategies for generalist robot manipulation policies. In: ICRA (2025)
2025
-
[75]
In: ICML (2024)
Zhao, J., Zhang, Z., Chen, B., Wang, Z., Anandkumar, A., Tian, Y.: Galore: Memory-efficient llm training by gradient low-rank projection. In: ICML (2024)
2024
-
[76]
In: NAACL (2025)
Zhao, Y., Zhang, W., Wang, H., Kawaguchi, K., Bing, L.: Adamergex: Cross-lingual transfer with large language models via adaptive adapter merging. In: NAACL (2025)
2025
-
[77]
LIBERO-PRO: Towards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization
Zhou, X., Xu, Y., Tie, G., Chen, Y., Zhang, G., Chu, D., Zhou, P., Sun, L.: Libero- pro: Towards robust and fair evaluation of vision-language-action models beyond memorization. arXiv preprint arXiv:2510.03827 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
In: ICML (2024)
Zhou, Z., Chen, Z., Chen, Y., Zhang, B., Yan, J.: On the emergence of cross-task linearity in the pretraining-finetuning paradigm. In: ICML (2024)
2024
-
[79]
RA-L (2026) 20 T
Zhu, R., Sun, E., Huang, G., Celiktutan, O.: Efficient continual imitation learning with online meta-adapters. RA-L (2026) 20 T. Kang et al
2026
-
[80]
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: CoRL (2023) Domain Arithmetic: One-Shot VLA Adaptation under Environmental Shifts 21 Supplementary Material This supplementary material provides additional technic...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.