Redesign Mixture-of-Experts Routers with Manifold Power Iteration
Pith reviewed 2026-06-27 10:08 UTC · model grok-4.3
The pith
Redesigning MoE router rows to align with principal singular directions of their experts via manifold power iteration produces more effective models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a router redesign based on Manifold Power Iteration drives each router row to converge to the principal singular direction of its paired expert matrix, and that this alignment produces more effective MoE models when the models are pretrained at scales from 1B to 11B parameters.
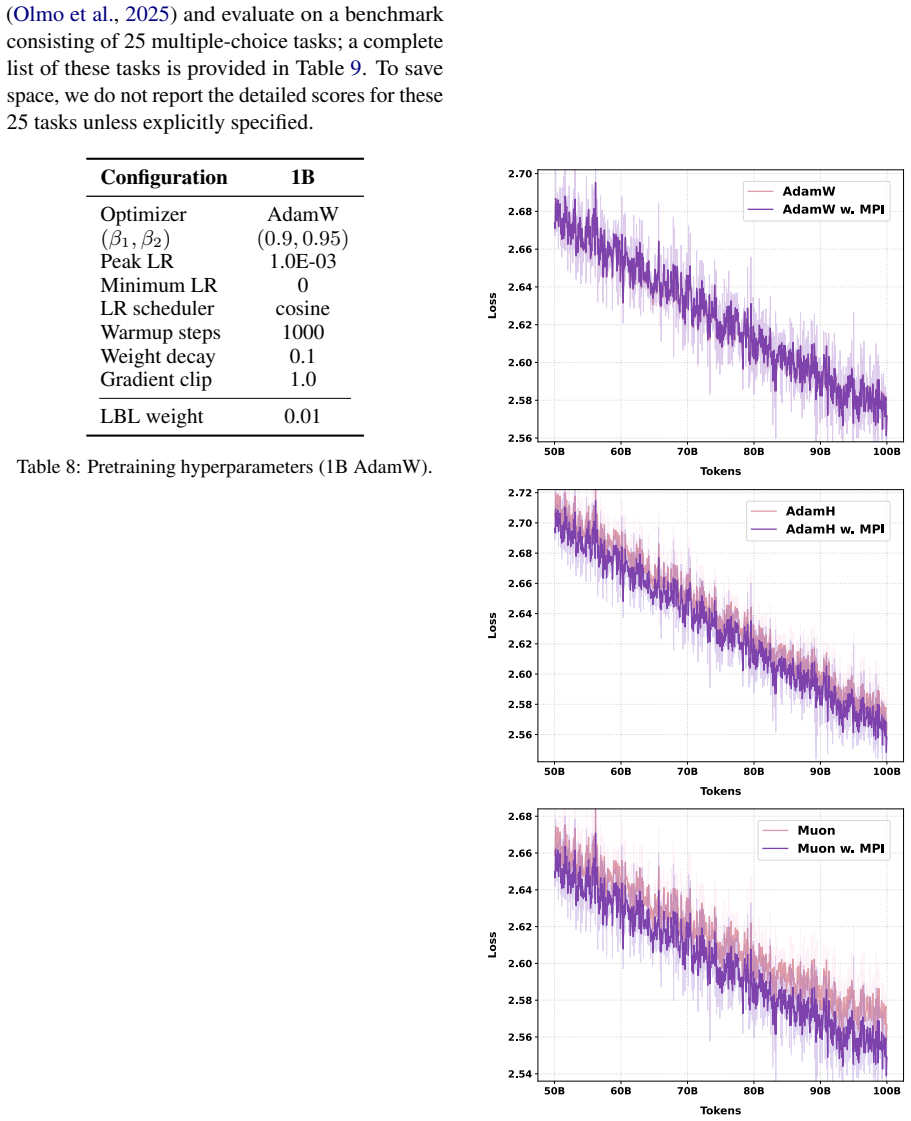
What carries the argument
Manifold Power Iteration (MPI), a 'Power-then-Retract' procedure that performs a power iteration update on router weights and then retracts onto a norm constraint.
If this is right
- Router rows converge toward the principal singular directions of the associated experts.
- The alignment improves token-expert affinity measurement and therefore expert selection.
- Pretrained MoE models from 1B to 11B parameters become more effective under this redesign.
- A concrete design principle now exists for router construction where none had been stated before.
Where Pith is reading between the lines
- The same singular-direction alignment might be applied to other matrix-based components that must summarize a larger matrix into a vector for similarity computations.
- If the convergence holds, auxiliary load-balancing losses in MoE training could potentially be relaxed because routing becomes more intrinsically matched to expert content.
- The retraction step may generalize to other constrained optimization settings on the Stiefel manifold in neural network training.
Load-bearing premise
The assumption that the principal singular direction of an expert matrix is the best mathematical description for encoding it into a router row whose dot product with tokens reflects token-expert affinity.
What would settle it
A controlled pretraining run at 1B-11B scale in which routers updated with MPI show no improvement or a clear degradation in validation loss or downstream metrics relative to identical models using standard routers.
Figures

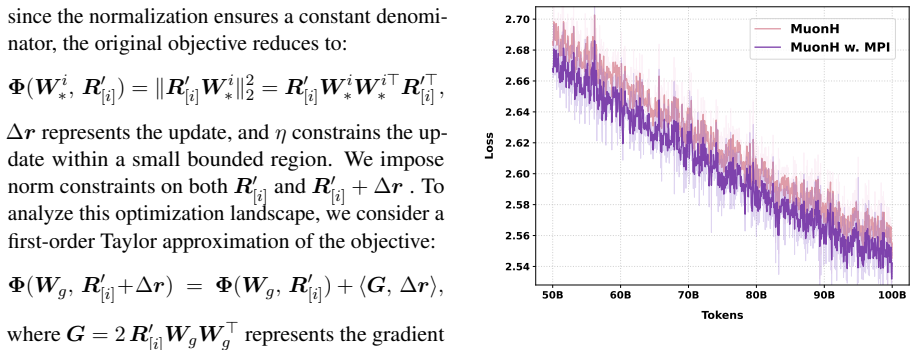
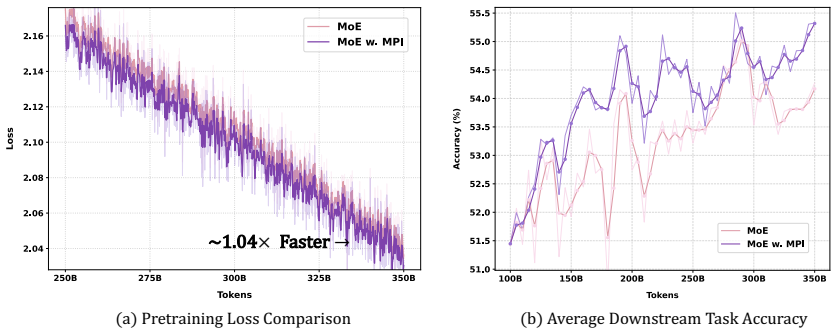
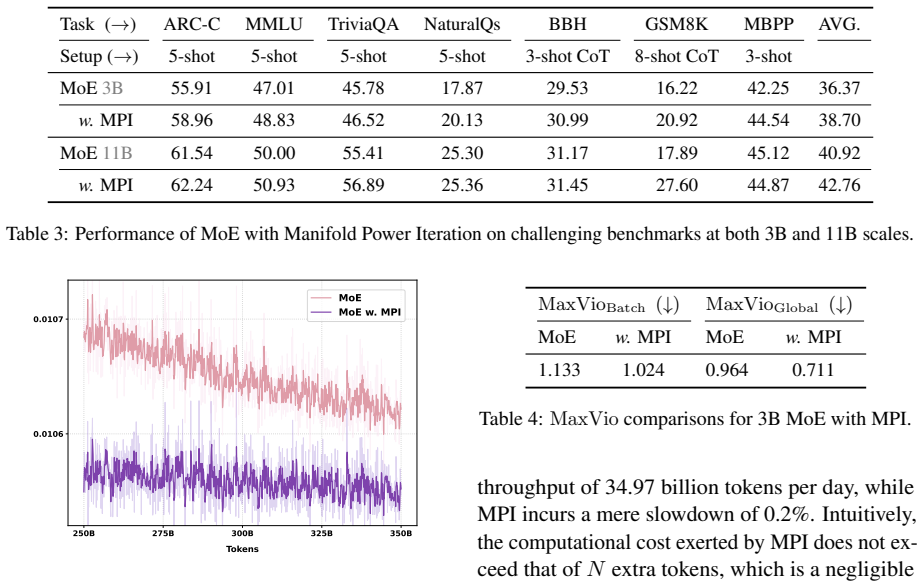
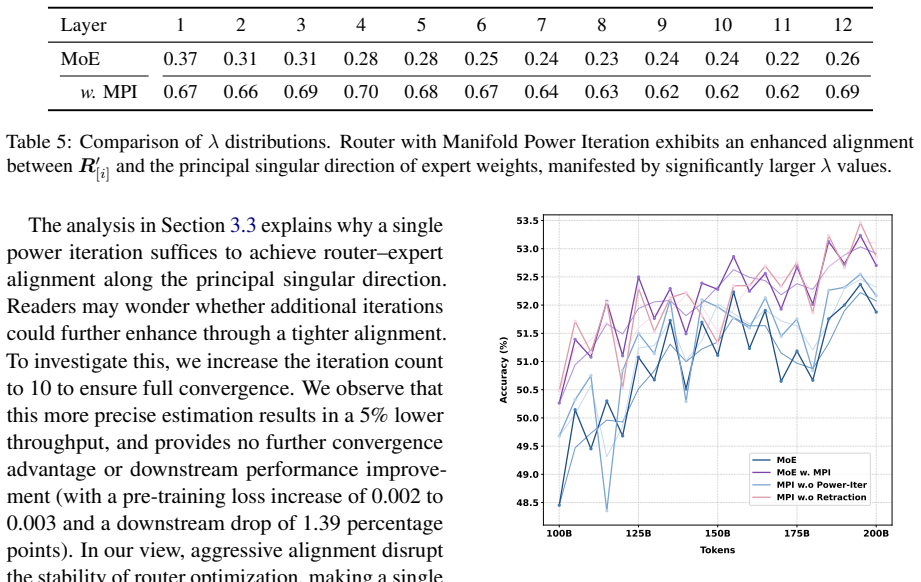
read the original abstract
Router is the cornerstone component to the Mixture-of-Experts models. Serving as expert proxies, the rows of the router matrix compute their similarity to the MoE inputs to determine which subset of experts is activated. Ideally, each router row is designed to encode the expert matrix into this representative vector, such that its dot-product with token can better reflect token-expert affinity. However, there exists no design principles to enforce this condensation. In this paper, we propose to align each router row with the principal singular direction of the associated expert, as this direction provides the most expressive mathematical description of a matrix. Based on this principle, we propose a router redesign with Manifold Power Iteration (MPI). Specifically, it introduces a "Power-then-Retract" paradigm, where a power iteration step is performed on the router weights, followed by a retraction to impose a norm constraint to ensure both efficiency and stability. Theoretically, we show that MPI drives router rows to converge toward the principal singular directions of associated experts. Empirically, we pretrain MoE model across scales from 1B to 11B parameters to confirm that this alignment facilitates more effective MoE models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that redesigning MoE routers by aligning each router row with the principal singular direction of its associated expert matrix, via a Manifold Power Iteration (MPI) procedure consisting of a power iteration step followed by retraction onto a norm constraint, yields routers whose dot products better reflect token-expert affinity. It asserts a theoretical result that MPI drives convergence to these principal singular directions and reports empirical gains from pretraining MoE models at scales from 1B to 11B parameters.
Significance. If the alignment principle is shown to improve routing quality beyond standard learned routers, the work would supply a linear-algebra-derived initialization and training rule for MoE routers that could be adopted at scale. The reported convergence guarantee and the breadth of the scaling experiments would be concrete strengths.
major comments (3)
- [Abstract] Abstract and introduction: the central design principle—that the principal (right) singular vector of an expert matrix W is the most expressive choice for the router row because it maximizes ||W v|| and thereby best encodes token-expert affinity—is asserted without derivation, comparison to alternatives (left singular vector, row-mean, top eigenvector of W^T W), or any link to the actual MoE routing loss.
- [Theory] Theoretical analysis: the convergence proof establishes that the Power-then-Retract iteration reaches the principal singular direction, yet supplies no bound or argument showing that this particular direction improves affinity or downstream loss relative to other fixed targets; the optimality claim therefore remains unconnected to the routing objective.
- [Experiments] Experiments (scaling section): the reported gains on 1B–11B models are presented without ablations that isolate the singular-direction alignment from other implementation choices (learning-rate schedule, retraction frequency, initialization), so it is unclear whether the performance lift is attributable to the claimed principle.
minor comments (2)
- [Method] Notation for the retraction operator and the precise manifold constraint should be stated explicitly with a short derivation of its effect on the power step.
- [Figures/Tables] Figure captions and table headers should clarify whether reported metrics are averaged over multiple seeds and whether expert utilization statistics are included.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the central design principle—that the principal (right) singular vector of an expert matrix W is the most expressive choice for the router row because it maximizes ||W v|| and thereby best encodes token-expert affinity—is asserted without derivation, comparison to alternatives (left singular vector, row-mean, top eigenvector of W^T W), or any link to the actual MoE routing loss.
Authors: We agree that the manuscript would benefit from expanded justification. The right singular vector maximizes ||W v||_2 by the variational definition of the largest singular value, providing the direction of strongest linear mapping from token space through the expert. In revision we will insert a short derivation of this property in the introduction, add a comparison paragraph addressing the listed alternatives (noting equivalence of the top eigenvector of W^T W to the right singular vector and the different role of the left singular vector), and clarify the indirect link to routing by noting that the router computes dot-product affinities used for expert selection. revision: yes
-
Referee: [Theory] Theoretical analysis: the convergence proof establishes that the Power-then-Retract iteration reaches the principal singular direction, yet supplies no bound or argument showing that this particular direction improves affinity or downstream loss relative to other fixed targets; the optimality claim therefore remains unconnected to the routing objective.
Authors: The theory section proves only that MPI converges to the principal singular direction; no claim is made of a direct optimality bound with respect to the routing loss. The design choice rests on the linear-algebraic motivation, with downstream benefit shown empirically. We will add a clarifying paragraph distinguishing the convergence result from any end-to-end loss guarantee and noting that a full theoretical connection to the training objective lies outside the present scope. revision: partial
-
Referee: [Experiments] Experiments (scaling section): the reported gains on 1B–11B models are presented without ablations that isolate the singular-direction alignment from other implementation choices (learning-rate schedule, retraction frequency, initialization), so it is unclear whether the performance lift is attributable to the claimed principle.
Authors: We acknowledge that isolating the alignment effect requires targeted ablations. The current results compare the full MPI procedure against standard routers at multiple scales. In the revision we will add controlled ablations that vary only retraction frequency and MPI-specific initialization while holding learning-rate schedules fixed, to better attribute the observed gains. revision: yes
Circularity Check
No circularity: alignment principle stated as premise; MPI convergence derived independently
full rationale
The paper states the core design principle directly ('align each router row with the principal singular direction of the associated expert, as this direction provides the most expressive mathematical description of a matrix') without deriving it from the MPI procedure or any self-citation. MPI is then introduced as a mechanism to enforce that alignment, with a separate theoretical argument showing convergence under the power-then-retract steps. No equations reduce a claimed result to a fitted parameter or prior self-referential definition; the empirical scaling results are external to the derivation. This matches the default case of a self-contained proposal against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Power iteration on a matrix converges to its principal singular direction under standard conditions.
Reference graph
Works this paper leans on
-
[1]
The Fourteenth International Conference on Learning Representations , year=
Fantastic Pretraining Optimizers and Where to Find Them , author=. The Fourteenth International Conference on Learning Representations , year=
-
[2]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[3]
2024 , url=
Keller Jordan and Yuchen Jin and Vlado Boza and You Jiacheng and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title=. 2024 , url=
2024
-
[4]
doi:10.57967/hf/2497 , publisher =
Lozhkov, Anton and Ben Allal, Loubna and von Werra, Leandro and Wolf, Thomas , title =. doi:10.57967/hf/2497 , publisher =
-
[5]
arXiv preprint arXiv:2002.05202 , year=
Glu variants improve transformer , author=. arXiv preprint arXiv:2002.05202 , year=
Pith/arXiv arXiv 2002
-
[6]
2017 , eprint=
Searching for Activation Functions , author=. 2017 , eprint=
2017
-
[7]
Forty-second International Conference on Machine Learning , year=
Autonomy-of-Experts Models , author=. Forty-second International Conference on Machine Learning , year=
-
[8]
The Fourteenth International Conference on Learning Representations , year=
Coupling Experts and Routers in Mixture-of-Experts via an Auxiliary Loss , author=. The Fourteenth International Conference on Learning Representations , year=
-
[9]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer. Transformer Feed-Forward Layers Are Key-Value Memories. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.446
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[10]
2025 , eprint=
Olmo 3 , author=. 2025 , eprint=
2025
-
[11]
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. arXiv:1803.05457v1 , year =
-
[12]
2021 , eprint=
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
2021
-
[13]
Weld and Luke Zettlemoyer , editor =
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[14]
arXiv preprint arXiv:2210.09261 , year=
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them , author=. arXiv preprint arXiv:2210.09261 , year=
-
[15]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[16]
arXiv preprint arXiv:2108.07732 , year=
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[17]
2026 , eprint=
Kimi K2: Open Agentic Intelligence , author=. 2026 , eprint=
2026
-
[18]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[19]
Training Deep Learning Models with Norm-Constrained LMOs , author=
-
[20]
2026 , eprint=
Controlled LLM Training on Spectral Sphere , author=. 2026 , eprint=
2026
-
[21]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
OLMoE: Open Mixture-of-Experts Language Models , author=. 2025 , eprint=
2025
-
[23]
2026 , eprint=
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
2026
-
[24]
2022 , eprint=
ST-MoE: Designing Stable and Transferable Sparse Expert Models , author=. 2022 , eprint=
2022
-
[25]
Psychometrika , year=
The approximation of one matrix by another of lower rank , author=. Psychometrika , year=
-
[26]
and Van Loan, Charles F
Golub, Gene H. and Van Loan, Charles F. , title =. 1996 , isbn =
1996
-
[27]
2024 , eprint=
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts , author=. 2024 , eprint=
2024
-
[28]
2022 , eprint=
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author=. 2022 , eprint=
2022
-
[29]
2026 , eprint=
Coupling Experts and Routers in Mixture-of-Experts via an Auxiliary Loss , author=. 2026 , eprint=
2026
-
[30]
2010 , eprint=
Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions , author=. 2010 , eprint=
2010
-
[31]
2025 , month =
Fantastic Pretraining Optimizers and Where to Find Them 2.1: Hyperball Optimization , author =. 2025 , month =
2025
-
[32]
TorchTitan: One-stop PyTorch native solution for production ready
Wanchao Liang and Tianyu Liu and Less Wright and Will Constable and Andrew Gu and Chien-Chin Huang and Iris Zhang and Wei Feng and Howard Huang and Junjie Wang and Sanket Purandare and Gokul Nadathur and Stratos Idreos , booktitle=. TorchTitan: One-stop PyTorch native solution for production ready. 2025 , url=
2025
-
[33]
Proceedings of Machine Learning and Systems , volume=
Megablocks: Efficient sparse training with mixture-of-experts , author=. Proceedings of Machine Learning and Systems , volume=
-
[34]
PyTorch: An Imperative Style, High-Performance Deep Learning Library , url =
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and Desmaison, Alban and Kopf, Andreas and Yang, Edward and DeVito, Zachary and Raison, Martin and Tejani, Alykhan and Chilamkurthy, Sasank and Steiner, Benoit and Fang, Lu an...
-
[35]
2020 , eprint=
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models , author=. 2020 , eprint=
2020
-
[36]
2025 , eprint=
OLMES: A Standard for Language Model Evaluations , author=. 2025 , eprint=
2025
-
[37]
Transactions of the Association for Computational Linguistics
Reddy, Siva and Chen, Danqi and Manning, Christopher D. C o QA : A Conversational Question Answering Challenge. Transactions of the Association for Computational Linguistics. 2019. doi:10.1162/tacl_a_00266
-
[38]
DROP : A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dua, Dheeru and Wang, Yizhong and Dasigi, Pradeep and Stanovsky, Gabriel and Singh, Sameer and Gardner, Matt. DROP : A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long ...
-
[39]
and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav , title =
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav. Natura...
-
[40]
doi:10.18653/V1/D16-1264 , url =
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264
-
[41]
Dasigi, Pradeep and Lo, Kyle and Beltagy, Iz and Cohan, Arman and Smith, Noah A. and Gardner, Matt. A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.na...
-
[42]
2024 , eprint=
LAB-Bench: Measuring Capabilities of Language Models for Biology Research , author=. 2024 , eprint=
2024
-
[43]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Paperno, Denis and Kruszewski, Germ \'a n and Lazaridou, Angeliki and Pham, Ngoc Quan and Bernardi, Raffaella and Pezzelle, Sandro and Baroni, Marco and Boleda, Gemma and Fern \'a ndez, Raquel. The LAMBADA dataset: Word prediction requiring a broad discourse context. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (...
-
[44]
Proceedings of the Conference on Health, Inference, and Learning , pages =
MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering , author =. Proceedings of the Conference on Health, Inference, and Learning , pages =. 2022 , editor =
2022
-
[45]
2020 , eprint=
What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams , author=. 2020 , eprint=
2020
-
[46]
S ci RIFF : A Resource to Enhance Language Model Instruction-Following over Scientific Literature
Wadden, David and Shi, Kejian and Morrison, Jacob and Li, Alan and Naik, Aakanksha and Singh, Shruti and Barzilay, Nitzan and Lo, Kyle and Hope, Tom and Soldaini, Luca and Shen, Shannon Zejiang and Downey, Doug and Hajishirzi, Hannaneh and Cohan, Arman. S ci RIFF : A Resource to Enhance Language Model Instruction-Following over Scientific Literature. Proc...
-
[47]
Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
-
[48]
2019 , eprint=
SocialIQA: Commonsense Reasoning about Social Interactions , author=. 2019 , eprint=
2019
-
[49]
Proceedings of the 3rd Workshop on Noisy User-generated Text , month = sep, year =
Welbl, Johannes and Liu, Nelson F. and Gardner, Matt. Crowdsourcing Multiple Choice Science Questions. Proceedings of the 3rd Workshop on Noisy User-generated Text. 2017. doi:10.18653/v1/W17-4413
-
[50]
arXiv preprint arXiv:1907.10641 , year=
WinoGrande: An Adversarial Winograd Schema Challenge at Scale , author=. arXiv preprint arXiv:1907.10641 , year=
Pith/arXiv arXiv 1907
-
[51]
Hellaswag: Can a machine really finish your sentence? In Korhonen, A., Traum, D
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin. H ella S wag: Can a Machine Really Finish Your Sentence?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1472
-
[52]
EMNLP , year=
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering , author=. EMNLP , year=
-
[53]
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan. C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.