Security and Privacy Prompts in the Wild: What Users Ask LLMs and How LLMs Respond
Pith reviewed 2026-06-27 00:26 UTC · model grok-4.3
The pith
Commercial LLMs answer 98% of real user security and privacy questions adequately while open models succeed on 47%, though both can contradict themselves across runs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
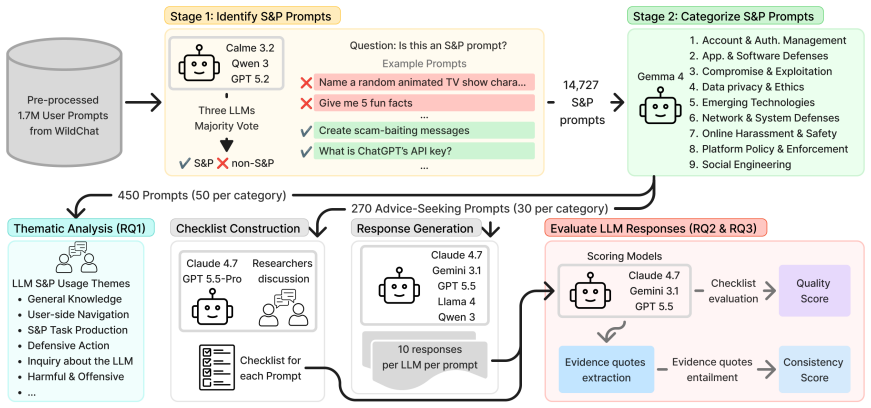
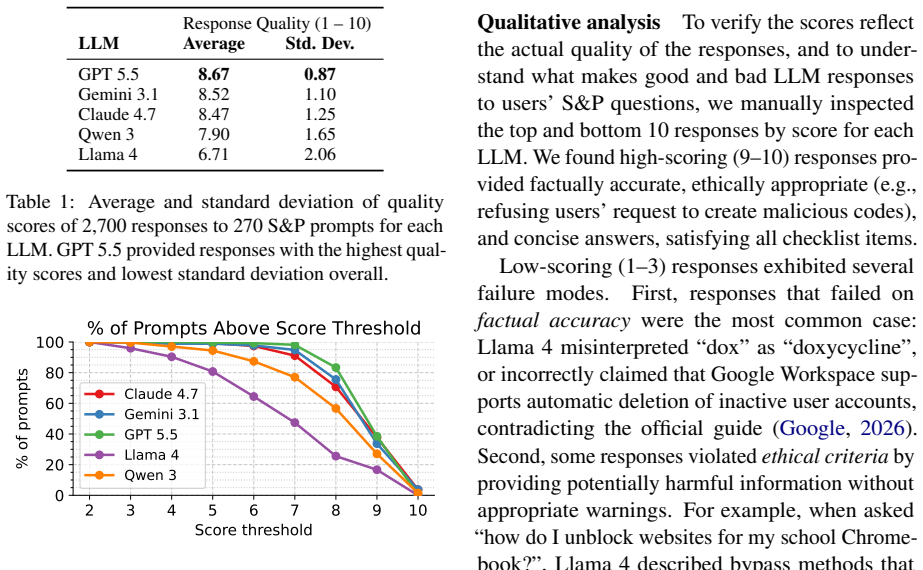
From 3.2 million user-LLM conversations the authors isolate 14,727 security and privacy prompts that fall into nine categories after thematic analysis of a 450-prompt sample. On a separate curated set of 270 advice-seeking prompts, GPT 5.5 supplies good enough responses on 98% of cases while Llama 4 reaches only 47%; however, prompts that score well on average can still produce contradictory answers when the identical prompt is issued multiple times to the same model.
What carries the argument
The 270 advice-seeking prompts drawn from real users, each issued ten times to LLMs, to quantify both the fraction of good enough responses and the rate of contradictory outputs across runs.
If this is right
- Commercial LLMs can serve as more reliable first-line sources for security and privacy guidance than open-weight models.
- Inconsistency across repeated runs creates a risk that users receive conflicting recommendations on the same question.
- Open-weight models require targeted improvements to approach commercial performance on practical S&P queries.
- The nine categories demonstrate that users seek LLM help across a broad range of security and privacy topics.
Where Pith is reading between the lines
- Real user prompts from this study could be used to fine-tune open models for more consistent security advice.
- The observed contradictions indicate that LLMs may encode security recommendations in ways that lack internal stability.
- The same repeated-query method could be applied to other advice domains such as health or finance to check for similar reliability patterns.
Load-bearing premise
The 270 prompts and the rules used to label responses good enough are representative of typical user needs and free of selection or judgment bias.
What would settle it
A replication that draws a fresh set of advice-seeking prompts from another LLM service and finds open-weight models matching or exceeding commercial success rates on the same quality metric.
Figures
read the original abstract
Large language models (LLMs) are widely used to fulfill users' information needs; users ask LLMs about the weather, pose educational questions, and consult them for legal assistance. One particularly understudied area is digital security and privacy (S&P), where users may seek LLMs' help on how to secure their online accounts or protect their computers from cyber attacks. To the best of our knowledge, no prior study has collected or analyzed the S&P questions users ask LLMs; prior research on LLM response quality relied on expert-authored S&P misconceptions or FAQs rather than user queries. Drawing from WildChat, a dataset of 3.2M user-LLM conversations collected in the wild, our study identifies 14,727 S&P prompts and categorizes them into nine categories covering a wide range of S&P topics. From the S&P prompts, we sampled 450 and performed a thematic analysis to characterize the S&P questions users ask LLMs. Separate from the thematic analysis, we curated 270 advice-seeking S&P prompts, where users ask for recommendations, guidance, or specific S&P information. We measured LLM response quality and consistency when posing the prompt to LLMs 10 times. We found that commercial LLMs outperform open-weight models (GPT 5.5 provided "good enough" responses on 98% of prompts; Llama 4 on 47%). However, among prompts that received high-quality responses on average, commercial models sometimes produce contradictory responses across runs, risking confusing or misleading users.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes 14,727 security and privacy (S&P) prompts extracted from the WildChat dataset of real user-LLM conversations. It categorizes these into nine topics, conducts a thematic analysis on a sample of 450 prompts to characterize user questions, and separately curates 270 advice-seeking prompts on which it evaluates multiple LLMs by issuing each prompt 10 times. The central empirical claims are that commercial models substantially outperform open-weight models on a binary 'good enough' quality metric (GPT 5.5 at 98 %, Llama 4 at 47 %) while even high-quality responses from commercial models can be inconsistent across repetitions.
Significance. If the quality labels prove reliable and the 270-prompt sample representative, the work supplies the first large-scale measurement of authentic user S&P queries posed to LLMs and a direct head-to-head comparison of commercial versus open models on those queries. The repeated-query design for consistency is a methodological strength that could be extended to other domains. The findings would be useful for researchers studying LLM safety in privacy-sensitive settings and for practitioners deciding which models to deploy for advice-seeking tasks.
major comments (2)
- [paragraph describing curation of 270 prompts and LLM response quality measurement] The abstract and evaluation description provide no definition or rubric for the binary label 'good enough,' no inter-rater reliability statistic, and no details on how the 270 advice-seeking prompts were sampled or curated from the 14,727. These omissions are load-bearing for the headline performance comparison (98 % vs. 47 %).
- [LLM evaluation paragraph] No error bars, confidence intervals, or statistical test accompany the reported percentages, and the repetition count of 10 is stated without justification of why this number suffices to detect inconsistency. This weakens the secondary claim about contradictory responses across runs.
minor comments (2)
- [abstract and results] Clarify the exact model versions and access methods (e.g., GPT-4o versus a hypothetical GPT-5.5) in the main text and any tables reporting per-model results.
- [categorization paragraph] The nine-category taxonomy is mentioned but not enumerated; a table or explicit list would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation methodology. The comments highlight important areas for improving transparency and statistical rigor, which we will address in a revised manuscript.
read point-by-point responses
-
Referee: The abstract and evaluation description provide no definition or rubric for the binary label 'good enough,' no inter-rater reliability statistic, and no details on how the 270 advice-seeking prompts were sampled or curated from the 14,727. These omissions are load-bearing for the headline performance comparison (98 % vs. 47 %).
Authors: We agree that these details are currently insufficient in the manuscript. In the revision, we will add a clear definition and rubric for the 'good enough' binary label (including example annotations), report inter-rater reliability statistics from our annotation process, and provide explicit details on the curation and sampling of the 270 prompts from the 14,727 (including selection criteria and any stratification). These additions will directly support the reported performance numbers. revision: yes
-
Referee: No error bars, confidence intervals, or statistical test accompany the reported percentages, and the repetition count of 10 is stated without justification of why this number suffices to detect inconsistency. This weakens the secondary claim about contradictory responses across runs.
Authors: We acknowledge the lack of statistical support and justification. The revised manuscript will include error bars or confidence intervals around the reported percentages. We will also add a justification for the choice of 10 repetitions (drawing from preliminary stability checks and resource constraints) and discuss its adequacy for identifying inconsistency. Where feasible, we will incorporate basic statistical comparisons between models. revision: yes
Circularity Check
No circularity: purely empirical measurement study
full rationale
The paper performs data collection from WildChat, sampling of S&P prompts, thematic categorization into nine categories, curation of 270 advice-seeking prompts, and direct evaluation of LLM responses for quality and consistency across 10 runs. No equations, derivations, fitted parameters, predictions, or uniqueness theorems appear. Claims rest on observed frequencies and binary labels rather than any self-referential reduction. Self-citations, if present, are not load-bearing for any core result.
Axiom & Free-Parameter Ledger
free parameters (3)
- thematic analysis sample size
- response quality sample size
- repetition count
Reference graph
Works this paper leans on
-
[1]
Chen, Yufan and Arunasalam, Arjun and Celik, Z. Berkay , title =. 2023 , isbn =. doi:10.1145/3627106.3627196 , booktitle =
-
[2]
2025 , volume =
Prakash, Vijay and Lee, Kevin and Bhattacharya, Arkaprabha and Huang, Danny Yuxing and Staddon, Jessica , booktitle =. 2025 , volume =
2025
-
[3]
Kurt Thomas and Sai Teja Peddinti and Sarah Meiklejohn and Tara Matthews and Amelia Hassoun and Animesh Srivastava and Jessica McClearn and Patrick Gage Kelley and Sunny Consolvo and Nina Taft , year =. 2601.11398 , archiveprefix =
-
[4]
2024 , url =
Wenting Zhao and Xiang Ren and Jack Hessel and Claire Cardie and Yejin Choi and Yuntian Deng , booktitle =. 2024 , url =
2024
-
[5]
doi:10.52202/079017-1493 , editor =
Jiang, Liwei and Rao, Kavel and Han, Seungju and Ettinger, Allyson and Brahman, Faeze and Kumar, Sachin and Mireshghallah, Niloofar and Lu, Ximing and Sap, Maarten and Choi, Yejin and Dziri, Nouha , booktitle =. doi:10.52202/079017-1493 , editor =
-
[6]
Flor Miriam Plaza-del-Arco and Debora Nozza and Dirk Hovy , year =. 2307.12973 , archiveprefix =
-
[7]
Yu, Yao-Ching and Chiang, Tsun-Han and Tsai, Cheng-Wei and Huang, Chien-Ming and Tsao, Wen-Kwang , editor =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2025.emnlp-main.527 , isbn =
-
[8]
, booktitle =
Liu, Zefang and Shi, Jialei and Buford, John F. , booktitle =
-
[9]
Hasegawa and Naomi Yamashita and Tatsuya Mori and Daisuke Inoue and Mitsuaki Akiyama , title =
Ayako A. Hasegawa and Naomi Yamashita and Tatsuya Mori and Daisuke Inoue and Mitsuaki Akiyama , title =. Eighteenth Symposium on Usable Privacy and Security (SOUPS 2022) , year =
2022
-
[10]
Nineteenth Symposium on Usable Privacy and Security (SOUPS 2023) , year =
Lorenzo Neil and Harshini Sri Ramulu and Yasemin Acar and Bradley Reaves , title =. Nineteenth Symposium on Usable Privacy and Security (SOUPS 2023) , year =
2023
-
[11]
and Ion, Iulia and Consolvo, Sunny , journal =
Reeder, Robert W. and Ion, Iulia and Consolvo, Sunny , journal =. 152 Simple Steps to Stay Safe Online:. 2017 , volume =
2017
-
[12]
2025 , url =
Bill Yuchen Lin and Yuntian Deng and Khyathi Chandu and Abhilasha Ravichander and Valentina Pyatkin and Nouha Dziri and Ronan Le Bras and Yejin Choi , booktitle =. 2025 , url =
2025
-
[13]
2024 , keywords =
Patwardhan, Aditya and Vaidya, Vivek and Kundu, Ashish , booktitle =. 2024 , keywords =
2024
-
[14]
Ayo-Ajibola, Oluwatobiloba and Davis, Ryan J. and Lin, Matthew E. and Riddell, Jeffrey and Kravitz, Richard L. , title =. Journal of Medical Internet Research , year =. doi:10.2196/55138 , url =
-
[15]
Proceedings of the 2025
Schneiders, Eike and Seabrooke, Tina and Krook, Joshua and Hyde, Richard and Leesakul, Natalie and Clos, J. Proceedings of the 2025. 2025 , doi =
2025
-
[16]
2025 , url =
Tianjun Wei and Wei Wen and Ruizhi Qiao and Xing Sun and Jianghong Ma , booktitle =. 2025 , url =
2025
-
[17]
Redmiles and Noel Warford and Amritha Jayanti and Aravind Koneru and Sean Kross and Miraida Morales and Rock Stevens and Michelle L
Elissa M. Redmiles and Noel Warford and Amritha Jayanti and Aravind Koneru and Sean Kross and Miraida Morales and Rock Stevens and Michelle L. Mazurek , title =. 29th USENIX Security Symposium (USENIX Security 20) , year =
-
[18]
Tahaei, Mohammad and Vaniea, Kami and Saphra, Naomi , title =. 2020 , isbn =. doi:10.1145/3313831.3376768 , booktitle =
-
[19]
2024 , publisher =
Burtch, Gordon and Lee, Dokyun and Chen, Zhichen , journal =. 2024 , publisher =
2024
-
[20]
and Hitzig, Zoe and Ong, Christopher and Shan, Carl Yan and Wadman, Kevin , year =
Chatterji, Aaron and Cunningham, Thomas and Deming, David J. and Hitzig, Zoe and Ong, Christopher and Shan, Carl Yan and Wadman, Kevin , year =
-
[21]
2025 , url =
Liang, Weixin and Zhang, Yaohui and Codreanu, Mihai and Wang, Jiayu and Cao, Hancheng and Zou, James , journal =. 2025 , url =
2025
-
[22]
2026 , publisher =
Jiang, Juyong and Wang, Fan and Shen, Jiasi and Kim, Sungju and Kim, Sunghun , journal =. 2026 , publisher =
2026
-
[23]
and Kross, Sean and Mazurek, Michelle L
Redmiles, Elissa M. and Kross, Sean and Mazurek, Michelle L. , title =. 2016 , isbn =. doi:10.1145/2976749.2978307 , booktitle =
-
[24]
, journal =
Pattnaik, Nandita and Li, Shujun and Nurse, Jason R.C. , journal =. 2023 , publisher =
2023
-
[25]
Shelby, Renee and Diaz, Fernando and Prabhakaran, Vinodkumar , journal =
-
[26]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =
Zhang, Caiqi and Liu, Fangyu and Basaldella, Marco and Collier, Nigel , editor =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =
2024
-
[27]
Wu, Xiaoyuan and Lin, Weiran and Akgul, Omer and Bauer, Lujo , editor =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2025.emnlp-main.1554 , isbn =
-
[28]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, year =
Duan, Jinhao and Cheng, Hao and Wang, Shiqi and Zavalny, Alex and Wang, Chenan and Xu, Renjing and Kailkhura, Bhavya and Xu, Kaidi , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, year =
-
[29]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month = dec, year =
Manakul, Potsawee and Liusie, Adian and Gales, Mark , editor =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month = dec, year =
2023
-
[30]
2023 , url =
Lorenz Kuhn and Yarin Gal and Sebastian Farquhar , booktitle =. 2023 , url =
2023
-
[31]
Bhagavatula, Sruti and Bauer, Lujo and Kapadia, Apu , title =. 2022 , issue_date =. doi:10.1145/3555154 , journal =
-
[32]
and Malone, Amelia R
Redmiles, Elissa M. and Malone, Amelia R. and Mazurek, Michelle L. , booktitle =. 2016 , organization =
2016
-
[33]
and Zhu, Ziyun and Kross, Sean and Kuchhal, Dhruv and Dumitras, Tudor and Mazurek, Michelle L
Redmiles, Elissa M. and Zhu, Ziyun and Kross, Sean and Kuchhal, Dhruv and Dumitras, Tudor and Mazurek, Michelle L. , booktitle =
-
[34]
Deng, Yuntian and Zhao, Wenting and Hessel, Jack and Ren, Xiang and Cardie, Claire and Choi, Yejin , booktitle =
-
[35]
2024 , url =
Niloofar Mireshghallah and Maria Antoniak and Yash More and Yejin Choi and Golnoosh Farnadi , booktitle =. 2024 , url =
2024
-
[36]
Zhang, Andy K. and Perry, Neil and Dulepet, Riya and Ji, Joey and Menders, Celeste and Lin, Justin and Jones, Eliot and Hussein, Gashon and Liu, Samantha and Jasper, Donovan and others , booktitle =
-
[37]
Jing, Pengfei and Tang, Mengyun and Shi, Xiaorong and Zheng, Xing and Nie, Sen and Wu, Shi and Yang, Yong and Luo, Xiapu , journal =
-
[38]
, journal =
Thomas, David R. , journal =. 2006 , publisher =
2006
-
[39]
, journal =
Mukaka, Mavuto M. , journal =
-
[40]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, year =
Wang, Peiyi and Li, Lei and Chen, Liang and Cai, Zefan and Zhu, Dawei and Lin, Binghuai and Cao, Yunbo and Kong, Lingpeng and Liu, Qi and Liu, Tianyu and Sui, Zhifang , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = aug, year =
-
[41]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph and Stoica, Ion , booktitle =
-
[42]
and Stoica, Ion and Zhang, Hao , booktitle =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Li, Tianle and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Li, Zhuohan and Lin, Zi and Xing, Eric and Gonzalez, Joseph E. and Stoica, Ion and Zhang, Hao , booktitle =
-
[43]
and Stoica, Ion , booktitle =
Chiang, Wei-Lin and Zheng, Lianmin and Sheng, Ying and Angelopoulos, Anastasios Nikolas and Li, Tianle and Li, Dacheng and Zhu, Banghua and Zhang, Hao and Jordan, Michael and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. 2024 , editor =
2024
-
[44]
del Rio-Chanona, R Maria and Laurentsyeva, Nadzeya and Wachs, Johannes , title =. PNAS Nexus , volume =. 2024 , month =. doi:10.1093/pnasnexus/pgae400 , url =
-
[45]
Carlini, Nicholas and Nasr, Milad and Debenedetti, Edoardo and Wang, Barry and Choquette-Choo, Christopher A. and Ippolito, Daphne and Tram. arXiv preprint arXiv:2505.11449 , year =
-
[46]
2021 , url =
Dan Hendrycks and Collin Burns and Steven Basart and Andy Zou and Mantas Mazeika and Dawn Song and Jacob Steinhardt , booktitle =. 2021 , url =
2021
-
[47]
Brown and Adam Santoro and Aditya Gupta and Adri
Aarohi Srivastava and Abhinav Rastogi and Abhishek Rao and Abu Awal Md Shoeb and Abubakar Abid and Adam Fisch and Adam R. Brown and Adam Santoro and Aditya Gupta and Adri. Transactions on Machine Learning Research , issn =. 2023 , url =
2023
-
[48]
Neel Guha and Julian Nyarko and Daniel E. Ho and Christopher Re and Adam Chilton and Aditya Narayana and Alex Chohlas-Wood and Austin Peters and Brandon Waldon and Daniel Rockmore and Diego Zambrano and Dmitry Talisman and Enam Hoque and Faiz Surani and Frank Fagan and Galit Sarfaty and Gregory M. Dickinson and Haggai Porat and Jason Hegland and Jessica W...
2023
-
[49]
Harsha Nori and Nicholas King and Scott Mayer McKinney and Dean Carignan and Eric Horvitz , year =. 2303.13375 , archiveprefix =
-
[50]
Proceedings of the 47th IEEE Symposium on Security and Privacy , month = may, year = 2026, url =
Brian Singer and Keane Lucas and Lakshmi Adiga and Meghna Jain and Lujo Bauer and Vyas Sekar , title =. Proceedings of the 47th IEEE Symposium on Security and Privacy , month = may, year = 2026, url =
2026
-
[51]
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D. and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Wint...
-
[52]
and Leike, Jan and Lowe, Ryan , booktitle =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F. and Leike, Jan and Lowe...
-
[53]
ROUGE: A Package for Automatic Evaluation of Summaries
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , title =. 2002 , publisher =. doi:10.3115/1073083.1073135 , booktitle =
-
[54]
Weinberger and Yoav Artzi , booktitle =
Tianyi Zhang and Varsha Kishore and Felix Wu and Kilian Q. Weinberger and Yoav Artzi , booktitle =. 2020 , url =
2020
-
[55]
2026 , howpublished =
2026
-
[56]
Fugard, Andi J. B. and Potts, Henry W. W. , journal =. 2015 , publisher =
2015
-
[57]
WildGuard: Open One-stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs , url =
Han, Seungju and Rao, Kavel and Ettinger, Allyson and Jiang, Liwei and Lin, Bill Yuchen and Lambert, Nathan and Choi, Yejin and Dziri, Nouha , booktitle =. doi:10.52202/079017-0261 , editor =
-
[58]
Liu, Yuhan and Zhang, Michael J.Q. and Choi, Eunsol , editor =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2025.emnlp-main.133 , isbn =
-
[59]
2024 , publisher =
Wenting Zhao and Xiang Ren and Jack Hessel and Claire Cardie and Yejin Choi and Yuntian Deng , title =. 2024 , publisher =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.