Observation-Aligned Mask Priors for Learning Physical Dynamics from Authentic Occlusions
Pith reviewed 2026-05-19 20:55 UTC · model grok-4.3
The pith
Mask priors learned from authentic occlusions create context-query splits that give every observed dimension a positive chance of being queried.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pretraining a Bayesian Flow Network on binary observation masks from the target datasets and guiding its samples with a globally normalized cross-entropy objective produces sample-specific masks whose intersection with the observed mask defines training partitions that assign strictly positive query probability to every valid observed dimension.
What carries the argument
The intersection between the guided mask and the observed mask, which partitions sparse data into context for conditioning and query targets for diffusion-based reconstruction.
If this is right
- Every valid observed dimension receives strictly positive probability of being selected as a query target.
- Training avoids zero-query dead zones and the resulting local generative collapse.
- The method yields measurable gains in MSE and PSNR on three real-world oceanographic datasets with satellite occlusions at resolutions up to 256 by 256.
- The approach supplies a practical alternative to heuristic or fixed masking rules when full observations are unavailable.
Where Pith is reading between the lines
- The same intersection construction could be tested on other domains that exhibit structured missingness, such as video sequences or medical scans.
- If the positive-query guarantee holds, the method may stabilize training on larger collections of sparse physical fields without requiring additional full-observation data.
- Extending the guidance objective to other generative backbones might preserve the dead-zone avoidance while changing reconstruction speed or fidelity.
Load-bearing premise
The pretrained Bayesian Flow Network on binary observation masks accurately captures the true distribution of authentic occlusions from the datasets.
What would settle it
A generated mask set in which at least one observed dimension has zero probability of appearing in any query split, or an experiment on the oceanographic datasets that shows no improvement in MSE or PSNR over standard diffusion baselines.
Figures






read the original abstract
Learning physical dynamics directly from incomplete observations is challenging because authentic occlusions are structured, sample-dependent, and often missing not at random, whereas existing methods typically rely on heuristic masking rules or predefined mask distributions. We propose Observation-Aligned Mask Priors, a framework that learns the distribution of authentic observation masks and uses it to construct context-query partitions for training from incomplete data. Specifically, we pretrain a Bayesian Flow Network (BFN) on binary observation masks to capture real occlusion topologies, then guide BFN sampling with a globally normalized cross-entropy objective to generate sample-specific masks aligned with each sparse observation. The intersection between the guided mask and the observed mask defines the context, and the remaining observed entries become query targets for a diffusion-based reconstruction model. We show that this intersection-based partitioning gives every valid observed dimension a strictly positive probability of being queried, preventing zero-query dead zones and local generative collapse. Experiments on three real-world oceanographic datasets with authentic satellite occlusions, across resolutions up to 256$\times$256, show consistent improvements over strong diffusion baselines in MSE and PSNR. These results demonstrate that learning mask priors from authentic occlusions is an effective alternative to heuristic masking for learning from incomplete physical observations without access to fully observed fields.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Observation-Aligned Mask Priors for learning physical dynamics from incomplete observations. A Bayesian Flow Network is pretrained on binary observation masks drawn from the target datasets to capture authentic occlusion topologies. Guided sampling via a globally normalized cross-entropy objective then produces sample-specific masks; the intersection of each guided mask with the observed mask defines the training context while the complement within the observed mask supplies query targets for a diffusion reconstruction model. The central theoretical claim is that this intersection-based partitioning assigns every valid observed dimension a strictly positive probability of being queried, thereby eliminating zero-query dead zones. Experiments on three real-world oceanographic datasets report consistent MSE and PSNR gains over diffusion baselines at resolutions up to 256×256.
Significance. If the positive-query-probability guarantee and the reported gains hold under rigorous validation, the work would supply a principled alternative to heuristic masking for training on structured, missing-not-at-random data. The use of a pretrained BFN to model real occlusion distributions and the intersection construction are technically attractive features that could reduce local generative collapse in scientific imaging domains.
major comments (3)
- [§3] The assertion that intersection-based partitioning guarantees strictly positive query probability for every observed dimension (abstract and §3) rests on the claim that the guided BFN never drives any marginal probability on the observed mask to exactly zero. No derivation or support analysis is supplied showing that the globally normalized cross-entropy objective preserves full support; the intersection definition alone does not preclude zero-probability exclusions under strong guidance correlation.
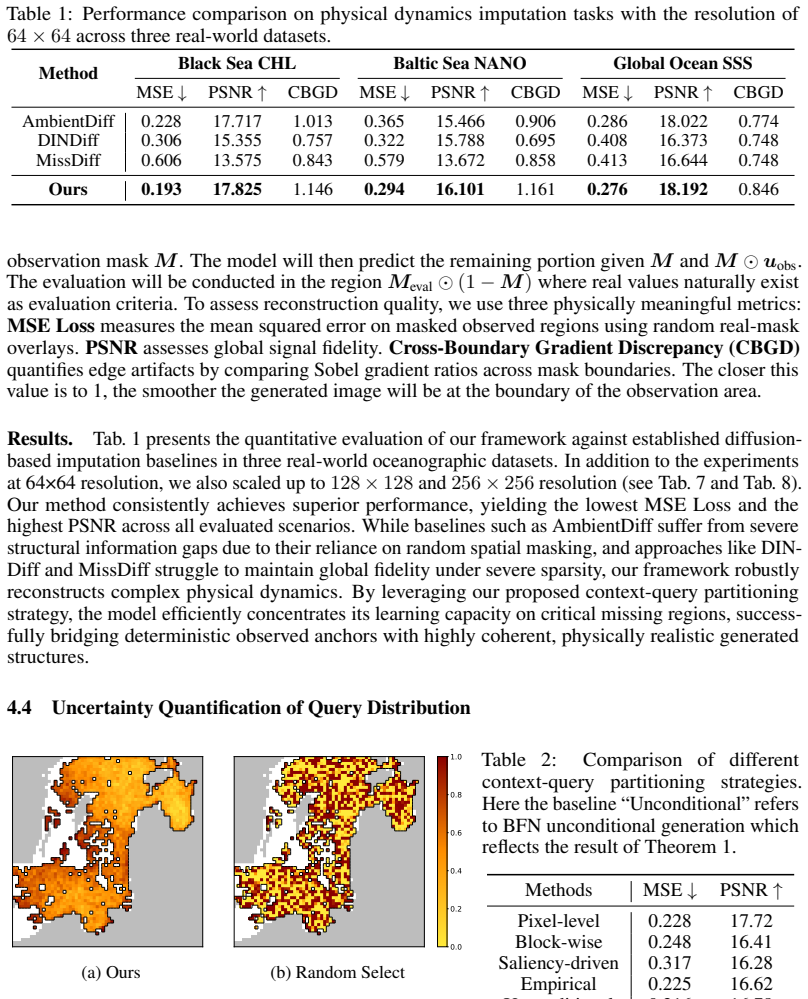
- [§5, Table 1] Table 1 and §5 report MSE/PSNR improvements on three oceanographic datasets, yet no implementation details for the diffusion baselines, no statistical significance tests, and no ablation isolating the guidance objective are provided. Without these, the attribution of gains specifically to the observation-aligned priors remains only partially supported.
- [§4.2] The method assumes the BFN pretrained on binary masks from the target datasets accurately represents the true distribution of authentic occlusions and that guidance introduces no systematic bias in the resulting context-query splits (§4.2). No quantitative validation (e.g., mask-distribution statistics or sensitivity to guidance temperature) is reported to substantiate this assumption.
minor comments (2)
- [§3] Notation for the guided mask G, observed mask O, and their intersection should be introduced with explicit equations early in §3 to avoid ambiguity when discussing probability support.
- [Figure 3] Figure 3 captions would benefit from explicit mention of the spatial resolution and the fraction of observed pixels shown for each example.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address each of the major comments below, providing clarifications and indicating where revisions will be made to strengthen the presentation and support for our claims.
read point-by-point responses
-
Referee: [§3] The assertion that intersection-based partitioning guarantees strictly positive query probability for every observed dimension (abstract and §3) rests on the claim that the guided BFN never drives any marginal probability on the observed mask to exactly zero. No derivation or support analysis is supplied showing that the globally normalized cross-entropy objective preserves full support; the intersection definition alone does not preclude zero-probability exclusions under strong guidance correlation.
Authors: We acknowledge that the manuscript would benefit from a more explicit derivation or analysis supporting the full support property under the guided sampling. The globally normalized cross-entropy objective is designed to encourage alignment while maintaining positive probabilities for all dimensions in the observed mask, as the normalization is over the entire mask and the BFN prior has full support on binary masks. However, to rigorously address this, we will include a brief theoretical analysis in the revised §3 demonstrating that the guidance temperature and normalization ensure strictly positive marginals for observed dimensions, preventing exact zeros. revision: yes
-
Referee: [§5, Table 1] Table 1 and §5 report MSE/PSNR improvements on three oceanographic datasets, yet no implementation details for the diffusion baselines, no statistical significance tests, and no ablation isolating the guidance objective are provided. Without these, the attribution of gains specifically to the observation-aligned priors remains only partially supported.
Authors: We agree that additional details and analyses are necessary to fully support the reported gains. In the revision, we will expand §5 to include implementation details for all baselines (e.g., hyperparameters, training procedures), conduct statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values), and add an ablation study isolating the effect of the guidance objective versus standard masking. These additions will clarify the contribution of the observation-aligned priors. revision: yes
-
Referee: [§4.2] The method assumes the BFN pretrained on binary masks from the target datasets accurately represents the true distribution of authentic occlusions and that guidance introduces no systematic bias in the resulting context-query splits (§4.2). No quantitative validation (e.g., mask-distribution statistics or sensitivity to guidance temperature) is reported to substantiate this assumption.
Authors: The assumption is central to the method, and we recognize the need for empirical validation. We will revise §4.2 to include quantitative comparisons of the pretrained BFN-generated masks against the empirical distribution of authentic occlusions (e.g., via KL divergence or visual statistics on mask topologies). Additionally, we will report sensitivity analyses varying the guidance temperature and show its impact on the context-query splits and downstream performance. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper's central claim that intersection-based partitioning (guided mask ∩ observed mask) assigns every valid observed dimension a strictly positive query probability follows directly from the probabilistic nature of BFN sampling under the globally normalized cross-entropy guidance and the explicit definition of context versus query sets. This is not equivalent to any input by construction, nor does it rely on fitted parameters renamed as predictions or self-citation chains. The method depends on external pretraining of the BFN on authentic masks from the target datasets, with experiments providing independent validation on real oceanographic data. No load-bearing steps reduce to self-definition or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bayesian Flow Networks can faithfully capture the distribution of binary observation masks from satellite data
invented entities (1)
-
Observation-Aligned Mask Priors
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Strict Positivity of Query Probabilities via Mask Intersection). Let M1, M2 ∈ {0,1}^d be independently sampled binary masks... P((Mqry)i=1 | Mctx=m) > 0.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We pretrain a Bayesian Flow Network (BFN) on binary observation masks to capture real occlusion topologies, then guide BFN sampling with a globally normalized cross-entropy objective.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alexander Barth, Julien Brajard, Aida Alvera-Azcárate, Bayoumy Mohamed, Charles Troupin, and Jean-Marie Beckers. Ensemble reconstruction of missing satellite data using a denoising diffusion model: application to chlorophyll a concentration in the black sea.Ocean Science, 20 (6):1567–1584, 2024
work page 2024
-
[2]
Scott A Martin, Georgy E Manucharyan, and Patrice Klein. Generative data assimilation for surface ocean state estimation from multi-modal satellite observations.Journal of Advances in Modeling Earth Systems, 17(8):e2025MS005063, 2025
work page 2025
-
[3]
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Accurate medium-range global weather forecasting with 3d neural networks.Nature, 619(7970):533–538, 2023
work page 2023
-
[4]
Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, Peter Wirnsberger, Meire Fortunato, Ferran Alet, Suman Ravuri, Timo Ewalds, Zach Eaton-Rosen, Weihua Hu, et al. Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023
work page 2023
-
[5]
Wan-Lu Hsu, Ying-Lei Lin, Jung-Pin Lai, Yu-Hui Liu, and Ping-Feng Pai. Forecasting corporate financial performance using deep learning with environmental, social, and governance data. Electronics, 14(3):417, 2025
work page 2025
-
[6]
Muhammad Ashfaq, Imran Khan, Dilawar Shah, Shujaat Ali, and Muhammad Tahir. Predicting wheat yield using deep learning and multi-source environmental data.Scientific Reports, 15(1): 26446, 2025
work page 2025
-
[7]
Yuluo Chen, Qiang Chen, Han Ma, Shuailong Chen, and Qingguo Fei. Transfer machine learning framework for efficient full-field temperature response reconstruction of thermal protection structures with limited measurement data.International Journal of Heat and Mass Transfer, 242:126785, 2025
work page 2025
-
[8]
Py Letraon, A. Ali, E. Alvarez Fanjul, L. Aouf, L. Axell, R. Aznar, M. Ballarotta, A. Behrens, M. Benkiran, A. Bentamy, L. Bertino, P. Bowyer, V . Brando, L. A. Breivik, B. Buongiorno Nardelli, S. Cailleau, S. A. Ciliberti, S. Colella, N. Mc Connell, G. Coppini, G. Cossarini, T. Dabrowski, M. de Alfonso Alonsomuñoyerro, E. O’dea, C. Desportes, F. Dinessen...
-
[9]
URLhttps://hal.univ-grenoble-alpes.fr/hal-03405376
-
[10]
Incomplete Data, Complete Dynamics: A Diffusion Approach
Zihan Zhou, Chenguang Wang, Hongyi Ye, Yongtao Guan, and Tianshu Yu. Incomplete data, complete dynamics: A diffusion approach.arXiv preprint arXiv:2509.20098, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Giannis Daras, Kulin Shah, Yuval Dagan, Aravind Gollakota, Alexandros G. Dimakis, and Adam Klivans. Ambient diffusion: Learning clean distributions from corrupted data, 2023. URLhttps://arxiv.org/abs/2305.19256
-
[12]
Ambient physics: Training neural pde solvers with partial observations, 2026
Harris Abdul Majid, Giannis Daras, Francesco Tudisco, and Steven McDonagh. Ambient physics: Training neural pde solvers with partial observations, 2026. URL https://arxiv. org/abs/2602.13873. 10
-
[13]
Bayesian flow networks.arXiv preprint arXiv:2308.07037, 2023
Alex Graves, Rupesh Kumar Srivastava, Timothy Atkinson, and Faustino Gomez. Bayesian flow networks, 2025. URLhttps://arxiv.org/abs/2308.07037
-
[14]
Generating physical dynamics under priors.arXiv preprint arXiv:2409.00730, 2024
Zihan Zhou, Xiaoxue Wang, and Tianshu Yu. Generating physical dynamics under priors.arXiv preprint arXiv:2409.00730, 2024
-
[15]
Improved techniques for maximum likelihood estimation for diffusion odes
Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. Improved techniques for maximum likelihood estimation for diffusion odes. InInternational Conference on Machine Learning, pages 42363–42389. PMLR, 2023
work page 2023
-
[16]
Missdiff: Training diffusion models on tabular data with missing values, 2023
Yidong Ouyang, Liyan Xie, Chongxuan Li, and Guang Cheng. Missdiff: Training diffusion models on tabular data with missing values, 2023. URL https://arxiv.org/abs/2307. 00467
work page 2023
-
[17]
arXiv preprint arXiv:2406.05136 , year=
Huseyin Tuna Erdinc, Rafael Orozco, and Felix J. Herrmann. Generative geostatistical modeling from incomplete well and imaged seismic observations with diffusion models, 2024. URL https://arxiv.org/abs/2406.05136
-
[18]
Impute-macfm: Imputation based on mask-aware flow matching, 2025
Dengyi Liu, Honggang Wang, and Hua Fang. Impute-macfm: Imputation based on mask-aware flow matching, 2025. URLhttps://arxiv.org/abs/2509.23126
-
[19]
Missing data imputation by reducing mutual information with rectified flows, 2025
Jiahao Yu, Qizhen Ying, Leyang Wang, Ziyue Jiang, and Song Liu. Missing data imputation by reducing mutual information with rectified flows, 2025. URL https://arxiv.org/abs/ 2505.11749
-
[20]
Latent space score-based diffusion model for probabilistic multivariate time series imputation, 2024
Guojun Liang, Najmeh Abiri, Atiye Sadat Hashemi, Jens Lundström, Stefan Byttner, and Prayag Tiwari. Latent space score-based diffusion model for probabilistic multivariate time series imputation, 2024. URLhttps://arxiv.org/abs/2409.08917
-
[21]
Argmax flows and multinomial diffusion: Learning categorical distributions, 2021
Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions, 2021. URL https:// arxiv.org/abs/2102.05379
-
[22]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces, 2023. URL https://arxiv. org/abs/2107.03006
-
[23]
Itai Gat, Tal Remez, Neta Shaul, Felix Kreuk, Ricky T. Q. Chen, Gabriel Synnaeve, Yossi Adi, and Yaron Lipman. Discrete flow matching, 2024. URL https://arxiv.org/abs/2407. 15595
work page 2024
-
[24]
Kaiwen Xue, Yuhao Zhou, Shen Nie, Xu Min, Xiaolu Zhang, Jun Zhou, and Chongxuan Li. Unifying bayesian flow networks and diffusion models through stochastic differential equations. arXiv preprint arXiv:2404.15766, 2024
-
[25]
Keyue Qiu, Yuxuan Song, Jie Yu, Hongbo Ma, Ziyao Cao, Zhilong Zhang, Yushuai Wu, Mingyue Zheng, Hao Zhou, and Wei-Ying Ma. Empower structure-based molecule optimization with gradient guided bayesian flow networks.arXiv preprint arXiv:2411.13280, 2024
-
[26]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations, 2021. URLhttps://arxiv.org/abs/2010.08895
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Dyffusion: A dynamics-informed diffusion model for spatiotemporal forecasting, 2023
Salva Rühling Cachay, Bo Zhao, Hailey Joren, and Rose Yu. Dyffusion: A dynamics-informed diffusion model for spatiotemporal forecasting, 2023. URL https://arxiv.org/abs/2306. 01984
work page 2023
-
[28]
Veeling, Paris Perdikaris, Richard E
Phillip Lippe, Bastiaan S. Veeling, Paris Perdikaris, Richard E. Turner, and Johannes Brand- stetter. Pde-refiner: Achieving accurate long rollouts with neural pde solvers, 2023. URL https://arxiv.org/abs/2308.05732
-
[29]
Chen, W., Jia, H., Lai, S., Wu, K., Xiao, H., Hu, L., and Yue, Y
Jan-Hendrik Bastek, WaiChing Sun, and Dennis M. Kochmann. Physics-informed diffusion models, 2025. URLhttps://arxiv.org/abs/2403.14404. 11
-
[30]
Diffusionpde: Generative pde-solving under partial observation, 2024
Jiahe Huang, Guandao Yang, Zichen Wang, and Jeong Joon Park. Diffusionpde: Generative pde-solving under partial observation, 2024. URLhttps://arxiv.org/abs/2406.17763
-
[31]
Aliaksandra Shysheya, Cristiana Diaconu, Federico Bergamin, Paris Perdikaris, José Miguel Hernández-Lobato, Richard E. Turner, and Emile Mathieu. On conditional diffusion models for pde simulations, 2024. URLhttps://arxiv.org/abs/2410.16415
-
[32]
Ashish Bora, Eric Price, and Alexandros G. Dimakis. Ambientgan: Generative models from lossy measurements. InInternational Conference on Learning Representations, 2018. URL https://api.semanticscholar.org/CorpusID:3481010
work page 2018
-
[33]
Park, Shirin Shoushtari, Hongyu An, and Ulugbek S
Chicago Y . Park, Shirin Shoushtari, Hongyu An, and Ulugbek S. Kamilov. Measurement score-based diffusion model, 2025. URLhttps://arxiv.org/abs/2505.11853
-
[34]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. URLhttps://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
Analyzing and improving the training dynamics of diffusion models
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models, 2024. URL https: //arxiv.org/abs/2312.02696
-
[36]
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022. A Related Work A.1 Learning from Incomplete Data Recent generative approaches for inco...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.