Cheap Code, Costly Judgment: A Case Study on Governable Agentic Software Engineering
Pith reviewed 2026-07-02 08:12 UTC · model grok-4.3
The pith
Engineering judgment converts failures visible only in high-velocity AI agent work into durable governance mechanisms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
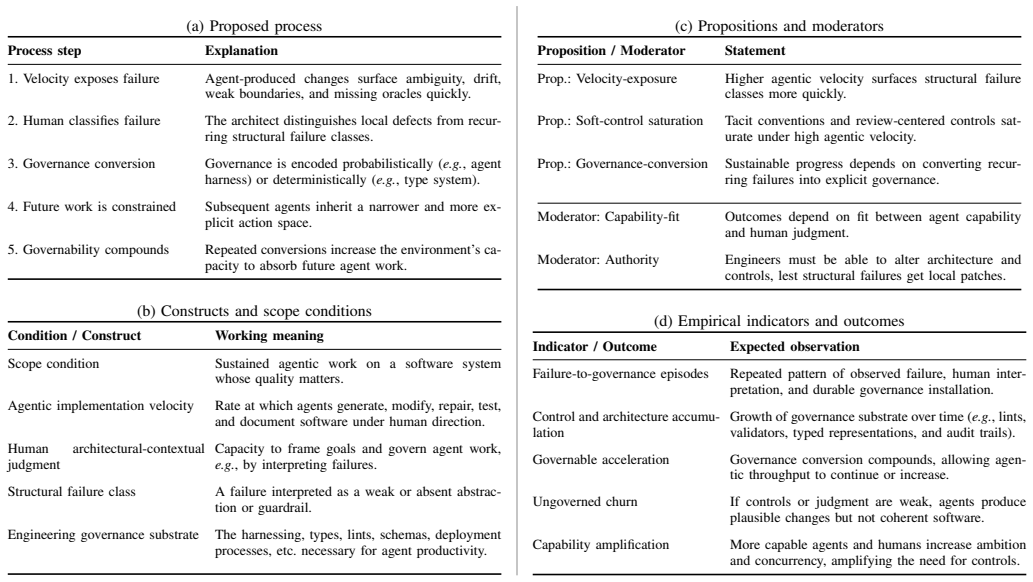
The paper develops governance conversion as a process model explaining how high-velocity agentic implementation surfaces recurring structural failure classes and how engineering judgment sustains velocity by converting those failures into durable governance mechanisms. In contrast to existing governance models that derive controls from known obligations, governance conversion explains how controls are discovered from failures that become visible only during agentic work.
What carries the argument
Governance conversion, the process by which observed structural failures in agentic development are turned into lasting controls on architecture, tooling, evidence, and feedback.
If this is right
- Agentic velocity will repeatedly expose the same classes of structural failures rather than unique ones.
- Engineering judgment functions as the active converter that turns those failures into reusable governance.
- Obligation-derived governance models are incomplete for settings where controls must be discovered in use.
- The model supplies concrete testable predictions about which failure classes will appear and how they convert.
- Teams using AI agents should organize architectures and evidence loops around the conversion process rather than static rules.
Where Pith is reading between the lines
- Training for software engineers in agentic settings should prioritize pattern recognition in failures over memorization of pre-existing rules.
- Replication across multiple engineers and domains would test whether the observed failure classes are general or project-specific.
- The model implies that research focus should move from measuring code-generation quality to measuring how quickly and reliably failures are converted into controls.
- If the conversion process holds, tooling that surfaces failure patterns early could accelerate governance without slowing velocity.
Load-bearing premise
The structural failure classes and conversion process observed in one expert engineer's 12-week project on a single application domain generalize to agentic development more broadly.
What would settle it
A second case study in a different domain or with different agents that does not surface the same recurring structural failure classes or show the same conversion sequence from failure to durable control.
Figures
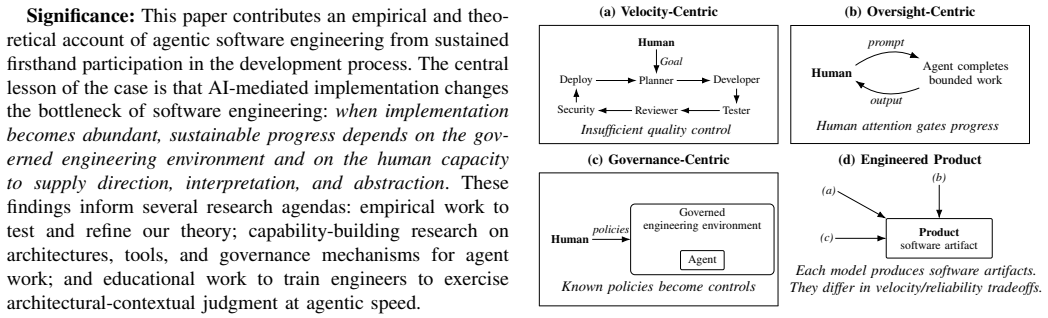

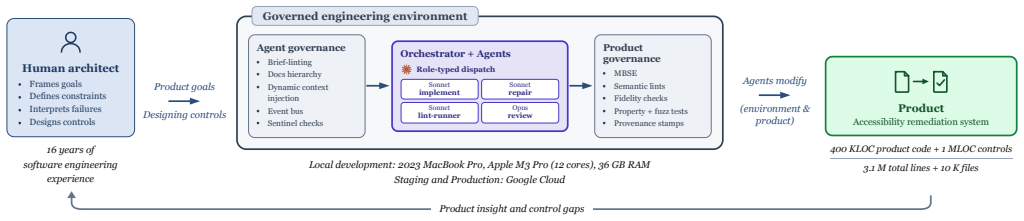
read the original abstract
Generative AI is shifting software engineering from a practice organized around scarce implementation effort toward one organized around abundant, low-cost code production. This shift changes the central engineering problem: not whether AI can generate useful code, but how engineers organize architectures, tools, evidence, and feedback loops so that AI-mediated development remains inspectable, correctable, and maintainable. We study this problem through a first-person case study: a 12-week development effort in which a single expert software engineer used frontier AI coding agents to build a document accessibility remediation system. The empirical record comprises 88 contemporaneous field notes, 420 KLOC of production code, and 1.16 MLOC of tests, lints, supporting documentation, and agent tooling. From this record, we develop a candidate middle-range theory of governance conversion, expressed as a process model explaining how high-velocity agentic implementation becomes governable. The model explains how agentic implementation velocity surfaces recurring structural failure classes, and how engineering judgment sustains velocity by converting those failures into durable governance mechanisms. In contrast to existing governance models that derive controls from known obligations, governance conversion explains how controls are discovered from failures that become visible only during agentic work. We use our model to make testable predictions and to describe implications for software engineering research and practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a 12-week first-person case study in which a single expert engineer used frontier AI coding agents to build a document accessibility remediation system, producing 420 KLOC of production code plus 1.16 MLOC of supporting artifacts from 88 field notes. From this record the authors induce a candidate middle-range theory of 'governance conversion': a process model in which high-velocity agentic implementation surfaces recurring structural failure classes that engineering judgment then converts into durable, inspectable governance mechanisms. The model is positioned as distinct from obligation-derived governance approaches and is accompanied by testable predictions for future work.
Significance. If the governance-conversion process can be shown to recur, the work would supply a concrete, failure-driven account of how abundant AI-generated code can be rendered governable, shifting emphasis from static obligation mapping to dynamic discovery of controls during agentic work. The explicit empirical base (field notes, KLOC counts) and the provision of testable predictions are strengths that would allow subsequent studies to evaluate the model directly.
major comments (2)
- [Abstract] Abstract and the description of the empirical record: the method by which the governance-conversion model was induced from the 88 field notes is not stated. It is therefore impossible to determine what coding or analytic steps were used to identify the structural failure classes, to distinguish them from idiosyncratic observations, or to rule out alternative explanations.
- [Abstract / Discussion] The central claim that governance conversion explains how controls are discovered from failures visible only during agentic work rests entirely on a single 12-week project by one engineer in one domain. No additional cases, replication attempts, or falsification tests against the stated predictions are reported, leaving the scope of the model unexamined.
minor comments (1)
- [Abstract] The abstract states that the model 'explains how agentic implementation velocity surfaces recurring structural failure classes' but does not list the classes or give even one concrete example; a brief enumeration or table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments highlight important issues of methodological transparency and the inherent scope limitations of a single-case study. We address each below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of the empirical record: the method by which the governance-conversion model was induced from the 88 field notes is not stated. It is therefore impossible to determine what coding or analytic steps were used to identify the structural failure classes, to distinguish them from idiosyncratic observations, or to rule out alternative explanations.
Authors: We agree that the abstract (and the corresponding methods description) does not sufficiently detail the inductive analytic process. The manuscript describes the model as developed from the field notes but does not enumerate the specific coding procedures, iteration steps, or criteria used to identify recurring structural failure classes versus idiosyncratic events. We will revise the manuscript to include an explicit subsection on analytic procedures, describing the iterative review of the 88 notes, cross-referencing against code and artifact logs, and the process for surfacing candidate patterns. revision: yes
-
Referee: [Abstract / Discussion] The central claim that governance conversion explains how controls are discovered from failures visible only during agentic work rests entirely on a single 12-week project by one engineer in one domain. No additional cases, replication attempts, or falsification tests against the stated predictions are reported, leaving the scope of the model unexamined.
Authors: The study is intentionally a single first-person case study whose purpose is to induce a candidate middle-range theory from a rich, contemporaneous empirical record rather than to test generalizability. We do not claim the model has been validated across contexts; the paper positions the work as theory-building and supplies explicit testable predictions for subsequent studies. Because the design is a single case, we cannot add replications or falsification tests within the current manuscript. We will expand the Discussion to more explicitly articulate the scope, limitations, and rationale for the single-case approach in theory development. revision: partial
- The absence of additional cases or replication studies, which would require new empirical work outside the scope of the present manuscript.
Circularity Check
No circularity: model derived empirically from case-study record
full rationale
The paper develops its candidate middle-range theory of governance conversion directly from the empirical record (88 field notes, 420 KLOC production code, 1.16 MLOC artifacts) of a single 12-week first-person case study. No equations, fitted parameters, self-referential definitions, or self-citation chains are present that would reduce the process model or its testable predictions to the inputs by construction. The derivation is therefore self-contained against the stated data source.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Policy on the AI exponential,
D. Amodei, “Policy on the AI exponential,” Jun. 2026. [Online]. Available: https://darioamodei.com/post/policy-on-the-ai-exponential
2026
-
[2]
SWE-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “SWE-bench: Can language models resolve real-world github issues?” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[3]
Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead,
J. He, C. Treude, and D. Lo, “Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead,” ACM Trans. Softw. Eng. Methodol., vol. 34, no. 5, May 2025
2025
-
[4]
A Survey on Code Generation with LLM-based Agents
Y . Dong, X. Jiang, J. Qian, T. Wang, K. Zhang, Z. Jin, and G. Li, “A survey on code generation with llm-based agents,” 2025. [Online]. Available: https://arxiv.org/abs/2508.00083
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Exploring llm-based agents for root cause analysis,
D. Roy, X. Zhang, R. Bhave, C. Bansal, P. Las-Casas, R. Fonseca, and S. Rajmohan, “Exploring llm-based agents for root cause analysis,” in Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, 2024
2024
-
[6]
Evaluating agent-based program repair at google,
P. Rondon, R. Wei, J. Cambronero, J. Cito, A. Sun, S. Sanyam, M. Tufano, and S. Chandra, “Evaluating agent-based program repair at google,” in2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), 2025
2025
-
[7]
Building a c compiler with a team of parallel claudes,
N. Carlini, “Building a c compiler with a team of parallel claudes,” February 2026. [Online]. Available: https://www.anthropic. com/engineering/building-c-compiler
2026
-
[8]
How we rebuilt next.js with ai in one week,
S. Faulkner, “How we rebuilt next.js with ai in one week,” February
-
[9]
Available: https://blog.cloudflare.com/vinext/
[Online]. Available: https://blog.cloudflare.com/vinext/
-
[10]
A. Moonka, “Amazon had four Sev-1 outages in a single week; internal memos say AI-assisted code changes were a contributing factor,” Mar. 2026. [Online]. Available: https://x.com/anishmoonka/ status/2031434445102989379
-
[11]
Amazon holds engineering meeting following AI- related outages,
Financial Times, “Amazon holds engineering meeting following AI- related outages,” Mar. 2026. [Online]. Available: https://www.ft.com/ content/7cab4ec7-4712-4137-b602-119a44f771de
2026
-
[12]
Guidelines for conducting and reporting case study research in software engineering,
P. Runeson and M. H ¨ost, “Guidelines for conducting and reporting case study research in software engineering,”Empirical Softw. Engg., vol. 14, no. 2, p. 131–164, Apr. 2009
2009
-
[13]
Runeson, M
P. Runeson, M. Host, A. Rainer, and B. Regnell,Case Study Research in Software Engineering: Guidelines and Examples, 1st ed. Wiley Publishing, 2012
2012
-
[14]
R. K. Merton,Social Theory and Social Structure, 1968th ed. New York, NY , USA: Free Press, 1968
1968
-
[15]
Sysllmatic: Large language models are software system optimizers,
H. Peng, A. Gupte, R. Hasler, N. J. Eliopoulos, C.-C. Ho, R. Mantri, L. Deng, K. L ¨aufer, G. K. Thiruvathukal, and J. C. Davis, “Sysllmatic: Large language models are software system optimizers,”Journal of Systems and Software, vol. 240, p. 112929, 2026
2026
-
[16]
An empirical evaluation of using large language models for automated unit test generation,
M. Sch ¨afer, S. Nadi, A. Eghbali, and F. Tip, “An empirical evaluation of using large language models for automated unit test generation,”IEEE Transactions on Software Engineering, vol. 50, no. 1, pp. 85–105, 2024
2024
-
[17]
Swe-agent: agent-computer interfaces enable automated soft- ware engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: agent-computer interfaces enable automated soft- ware engineering,” inProceedings of the 38th International Conference on Neural Information Processing Systems, 2024
2024
-
[18]
CodeAgent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges,
K. Zhang, J. Li, G. Li, X. Shi, and Z. Jin, “CodeAgent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges,” inProceedings of the 62nd Annual Meeting of the ACL (Volume 1: Long Papers), Aug. 2024, pp. 13 643–13 658
2024
-
[19]
Autocoderover: Autonomous program improvement,
Y . Zhang, H. Ruan, Z. Fan, and A. Roychoudhury, “Autocoderover: Autonomous program improvement,” inProceedings of the 33rd ACM SIGSOFT ISSTA, 2024
2024
-
[20]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
X. Deng, J. Da, E. Pan, Y . Y . He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Rane, K. Sampath, M. Krishnan, S. Kundurthy, S. Hendryx, Z. Wang, V . Bharadwaj, J. Holm, R. Aluri, C. B. C. Zhang, N. Jacobson, B. Liu, and B. Kenstler, “Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?” 2025. [Online]. Available: https://ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Nl2repo-bench: Towards long-horizon repository generation evaluation of coding agents
J. Ding, S. Long, C. Pu, H. Zhou, H. Gao, X. Gao, C. He, Y . Hou, F. Hu, Z. Li, W. Shi, Z. Wang, D. Zan, C. Zhang, X. Zhang, Q. Chen, X. Cheng, B. Deng, Q. Gu, K. Hua, J. Lin, P. Liu, M. Li, X. Pan, Z. Peng, Y . Qin, Y . Shan, Z. Tan, W. Xie, Z. Wang, Y . Yuan, J. Zhang, E. Zhao, Y . Zhao, H. Zhu, L. Zhu, C. Zou, M. Ding, J. Jiao, J. Liu, M. Liu, Q. Liu, ...
-
[22]
Programbench: Can language models rebuild programs from scratch?
J. Yang, K. Lieret, J. Ma, P. Thakkar, D. Pedchenko, S. Sootla, E. McMilin, P. Yin, R. Hou, G. Synnaeve, D. Yang, and O. Press, “Programbench: Can language models rebuild programs from scratch?”
-
[23]
ProgramBench: Can Language Models Rebuild Programs From Scratch?
[Online]. Available: https://arxiv.org/abs/2605.03546
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Context engineering for AI agents in open-source software
S. Mohsenimofidi, M. Galster, C. Treude, and S. Baltes, “Context engineering for AI agents in open-source software.” [Online]. Available: http://arxiv.org/abs/2510.21413
-
[25]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” Transactions of the ACL, vol. 12, pp. 157–173, 2024
2024
-
[26]
ProSA: As- sessing and understanding the prompt sensitivity of LLMs,
J. Zhuo, S. Zhang, X. Fang, H. Duan, D. Lin, and K. Chen, “ProSA: As- sessing and understanding the prompt sensitivity of LLMs,” inFindings of the ACL: EMNLP 2024, Nov. 2024, pp. 1950–1976
2024
-
[27]
What prompts don’t say: Understanding and managing underspecification in LLM prompts,
C. Yang, Y . Shi, Q. Ma, M. X. Liu, C. Kaestner, and T. Wu, “What prompts don’t say: Understanding and managing underspecification in LLM prompts,” inFindings of the ACL: ACL 2026, Jul. 2026, pp. 9072– 9101
2026
-
[28]
Assessing the Impact of Requirement Ambiguity on LLM-based Function-Level Code Generation
D. Yang, X. Xie, X. Yang, M. Hu, Y . Huang, Y . Zhang, W. Miao, T. Su, C. Wan, and G. Pu, “Assessing the impact of requirement ambiguity on llm-based function-level code generation,” 2026. [Online]. Available: https://arxiv.org/abs/2604.21505
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Plans & Pricing — Claude by Anthropic,
Anthropic, “Plans & Pricing — Claude by Anthropic,” 2026. [Online]. Available: https://claude.com/pricing
2026
-
[30]
API Pricing,
OpenAI, “API Pricing,” 2026. [Online]. Available: https://openai.com/ api/pricing/
2026
-
[31]
Welcome to gas town,
S. Yegge, “Welcome to gas town,” Jan. 2026. [Online]. Available: https://steve-yegge.medium.com/welcome-to-gas-town-4f25ee16dd04
2026
-
[32]
ChatDev: Communicative agents for software development,
C. Qian, W. Liu, H. Liu, N. Chen, Y . Dang, J. Li, C. Yang, W. Chen, Y . Su, X. Cong, J. Xu, D. Li, Z. Liu, and M. Sun, “ChatDev: Communicative agents for software development,” inProceedings of the 62nd Annual Meeting of the ACL (Volume 1: Long Papers), Aug. 2024, pp. 15 174–15 186
2024
-
[33]
MetaGPT: Meta programming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber, “MetaGPT: Meta programming for a multi-agent collaborative framework,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[34]
On the dangers of stochastic parrots: Can language models be too big?
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell, “On the dangers of stochastic parrots: Can language models be too big?” in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 2021
2021
-
[35]
Building software by rolling the dice: A qualitative study of vibe coding,
Y .-H. Chou, B. Jiang, Y . W. Chen, M. Weng, V . Jackson, T. Zimmermann, and J. A. Jones, “Building software by rolling the dice: A qualitative study of vibe coding,” 2025. [Online]. Available: http://arxiv.org/abs/2512.22418
-
[36]
A study on developer behaviors for validating and repairing LLM-generated code using eye tracking and IDE actions,
N. Tang, M. Chen, Z. Ning, A. Bansal, Y . Huang, C. McMillan, and T. J.-J. Li, “A study on developer behaviors for validating and repairing LLM-generated code using eye tracking and IDE actions,”
-
[37]
Available: http://arxiv.org/abs/2405.16081
[Online]. Available: http://arxiv.org/abs/2405.16081
-
[38]
Reflexion: Language Agents with Verbal Reinforcement Learning
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” 2023. [Online]. Available: https://arxiv.org/abs/2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Agentrx: Diagnosing ai agent failures from execution trajectories,
S. Barke, A. Goyal, A. Khare, A. Singh, S. Nath, and C. Bansal, “Agentrx: Diagnosing ai agent failures from execution trajectories,”
-
[40]
Available: https://arxiv.org/abs/2602.02475
[Online]. Available: https://arxiv.org/abs/2602.02475
-
[41]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
J. Ni, Y . Liu, X. Liu, Y . Sun, M. Zhou, P. Cheng, D. Wang, E. Zhao, X. Jiang, and G. Jiang, “Trace2skill: Distill trajectory-local lessons into transferable agent skills,” 2026. [Online]. Available: https://arxiv.org/abs/2603.25158
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Agentic harness engineering: Observability-driven automatic evolution of coding-agent harnesses,
J. Lin, S. Liu, C. Pan, L. Lin, S. Dou, Z. Xi, X. Huang, H. Yan, Z. Han, T. Gui, and Y .-G. Jiang, “Agentic harness engineering: Observability-driven automatic evolution of coding-agent harnesses,”
-
[43]
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
[Online]. Available: https://arxiv.org/abs/2604.25850
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
From Failed Trajectories to Reliable LLM Agents: Diagnosing and Repairing Harness Flaws
M. Chen, J. Wang, Z. Liu, Y . Wang, and Q. Wang, “From failed trajectories to reliable llm agents: Diagnosing and repairing harness flaws,” 2026. [Online]. Available: https://arxiv.org/abs/2606.06324
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Agentic and multi-agent systems: A systematic review of tool use, benchmarks, and governance,
A. Rahimi, “Agentic and multi-agent systems: A systematic review of tool use, benchmarks, and governance,” 2026
2026
-
[46]
Runtime governance for ai agents: Policies on paths,
M. Kaptein, V .-J. Khan, and A. Podstavnychy, “Runtime governance for ai agents: Policies on paths,” 2026. [Online]. Available: https: //arxiv.org/abs/2603.16586
-
[47]
C. Koch, “From governance norms to enforceable controls: A layered translation method for runtime guardrails in agentic ai,” 2026. [Online]. Available: https://arxiv.org/abs/2604.05229
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Ai agent governance: A field guide,
J. Kraprayoon, Z. Williams, and R. Fayyaz, “Ai agent governance: A field guide,” 2025. [Online]. Available: https://arxiv.org/abs/2505.21808
-
[49]
Towards automated governance: A dsl for human-agent collaboration in software projects,
A. Ait, G. Jouneaux, J. L. C. Izquierdo, and J. Cabot, “Towards automated governance: A dsl for human-agent collaboration in software projects,” 2025. [Online]. Available: https://arxiv.org/abs/2510.14465
-
[50]
Managing the Development of Large Software Systems: Concepts and Techniques,
W. W. Royce, “Managing the Development of Large Software Systems: Concepts and Techniques,” inProceedings of IEEE WESCON, 1970
1970
-
[51]
Manifesto for Agile Software Development,
K. Beck, M. Beedle, A. van Bennekum, A. Cockburn, W. Cunningham, M. Fowler, J. Grenning, J. Highsmith, A. Hunt, R. Jeffries, J. Kern, B. Marick, R. C. Martin, S. Mellor, K. Schwaber, J. Sutherland, and D. Thomas, “Manifesto for Agile Software Development,” 2001. [Online]. Available: https://agilemanifesto.org/
2001
-
[52]
R. K. Yin,Case Study Research and Applications: Design and Methods, 6th ed. Thousand Oaks, CA: SAGE Publications, 2018
2018
-
[53]
A. L. George and A. Bennett,Case Studies and Theory Development in the Social Sciences. Cambridge, MA: MIT Press, 2005
2005
-
[54]
Building theories from case study research,
K. M. Eisenhardt, “Building theories from case study research,” Academy of Management Review, 1989
1989
-
[55]
Theory building from cases: Opportunities and challenges,
K. M. Eisenhardt and M. E. Graebner, “Theory building from cases: Opportunities and challenges,”Academy of Management Journal, 2007
2007
-
[56]
Qualitative methods in empirical studies of software engineering,
C. Seaman, “Qualitative methods in empirical studies of software engineering,”IEEE Transactions on Software Engineering, vol. 25, no. 4, pp. 557–572, 1999
1999
-
[57]
Cooperative method development,
Y . Dittrich, K. R ¨onkk¨o, J. Eriksson, C. Hansson, and O. Lindeberg, “Cooperative method development,” inProceedings of the 2007 ACM GROUP, 2007
2007
-
[58]
Salda ˜na,The coding manual for qualitative researchers, 2nd ed
J. Salda ˜na,The coding manual for qualitative researchers, 2nd ed. Los Angeles: Sage Publications, Inc, 2013, oCLC: ocn796279115
2013
-
[59]
The critical incident technique,
J. C. Flanagan, “The critical incident technique,”Psychological Bulletin, 1954
1954
-
[60]
Fifty years of the critical incident technique: 1954–2004 and beyond,
L. D. Butterfield, W. A. Borgen, N. E. Amundson, and A.-S. T. Maglio, “Fifty years of the critical incident technique: 1954–2004 and beyond,” Qualitative Research, 2005
1954
-
[61]
The critical incident technique in service research,
D. D. Gremler, “The critical incident technique in service research,” Journal of Service Research, 2004
2004
-
[62]
Negotiating the swamp: The opportunity and challenge of reflexivity in research practice,
L. Finlay, “Negotiating the swamp: The opportunity and challenge of reflexivity in research practice,”Qualitative Research, vol. 2, no. 2, 2002
2002
-
[63]
Qualitative quality: Eight “Big-Tent
S. J. Tracy, “Qualitative quality: Eight “Big-Tent” criteria for excellent qualitative research,”Qualitative Inquiry, vol. 16, no. 10, 2010
2010
-
[64]
Americans with Disabilities Act of 1990, As Amended,
U.S. Department of Justice, Civil Rights Division, “Americans with Disabilities Act of 1990, As Amended,” 2026, aDA.gov; accessed June 17, 2026. [Online]. Available: https://www.ada.gov/law-and-regs/ada/
1990
-
[65]
Nondiscrimination on the Basis of Disabil- ity; Accessibility of Web Information and Services of State and Local Government Entities,
U.S. Department of Justice, “Nondiscrimination on the Basis of Disabil- ity; Accessibility of Web Information and Services of State and Local Government Entities,”Federal Register, 89 FR 31320–31396, Apr. 2024, final rule; Document No. 2024-07758; 28 CFR Part 35; effective June 24, 2024
2024
-
[66]
ADA Requirements: Effective Communication,
U.S. Department of Justice, Civil Rights Division, “ADA Requirements: Effective Communication,” Feb. 2020. [Online]. Available: https: //www.ada.gov/resources/effective-communication/
2020
-
[67]
Web Content Accessibility Guidelines (WCAG) 2.1,
Accessibility Guidelines Working Group, “Web Content Accessibility Guidelines (WCAG) 2.1,” May 2025. [Online]. Available: https: //www.w3.org/TR/WCAG21/
2025
-
[68]
What do we mean by “accessibility research
K. Mack, E. McDonnell, D. Jain, L. Lu Wang, J. E. Froehlich, and L. Findlater, “What do we mean by “accessibility research”? a literature survey of accessibility papers in chi and assets from 1994 to 2019,” in Proceedings of CHI, 2021
1994
-
[69]
veraPDF: Industry supported PDF/A validation,
veraPDF Consortium, “veraPDF: Industry supported PDF/A validation,”
-
[70]
Available: https://verapdf.org/home/
[Online]. Available: https://verapdf.org/home/
-
[71]
Create and verify PDF accessibility,
Adobe, “Create and verify PDF accessibility,”
-
[72]
Available: https://helpx.adobe.com/acrobat/using/ create-verify-pdf-accessibility.html
[Online]. Available: https://helpx.adobe.com/acrobat/using/ create-verify-pdf-accessibility.html
-
[73]
Accessibility in LibreOffice,
The Document Foundation, “Accessibility in LibreOffice,” 2026. [Online]. Available: https://help.libreoffice.org/latest/en-US/text/shared/ guide/accessibility.html
2026
-
[74]
Improve accessibility with the accessibility checker,
Microsoft, “Improve accessibility with the accessibility checker,” 2026. [Online]. Available: https://support.microsoft.com/en-us/accessibility/ office-accessibility/improve-accessibility-with-the-accessibility-checker
2026
-
[75]
Extension of Compliance Dates for Nondis- crimination on the Basis of Disability; Accessibility of Web Information and Services of State and Local Government Entities,
U.S. Department of Justice, “Extension of Compliance Dates for Nondis- crimination on the Basis of Disability; Accessibility of Web Information and Services of State and Local Government Entities,” Federal Register, 91 FR 20902–20912, Apr. 2026
2026
-
[76]
Usage Limit Best Practices,
Anthropic, “Usage Limit Best Practices,” Claude Help Center,
-
[77]
Available: https://support.claude.com/en/articles/ 9797557-usage-limit-best-practices
[Online]. Available: https://support.claude.com/en/articles/ 9797557-usage-limit-best-practices
-
[78]
Max 20x Plan Hitting Daily Limit with Reduced Usage— Limits Appear Silently Tightened (April 28–29, 2026),
tbuckworth, “Max 20x Plan Hitting Daily Limit with Reduced Usage— Limits Appear Silently Tightened (April 28–29, 2026),” Apr. 2026, closed as not planned; accessed June 19, 2026. [Online]. Available: https://github.com/anthropics/claude-code/issues/54714
2026
-
[79]
Frederick P
J. Frederick P. Brooks,The Mythical Man-Month: Essays on Software Engineering, anniversary edition ed. Reading, MA, USA: Addison- Wesley, 1995
1995
-
[80]
How do committees invent?
M. E. Conway, “How do committees invent?”Datamation, vol. 14, no. 4, 1968
1968
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.