Keypose Exploration: Efficient Automatic Trajectory Labelling and Cross-Embodiment Policy Transfer
Pith reviewed 2026-06-30 09:20 UTC · model grok-4.3
The pith
An automatic pipeline labels keyposes from one demonstration to train policies matching standard baselines and supporting cross-embodiment transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that a hybrid pipeline of VLM-based semantic event detection on a single demonstration combined with classical trajectory analysis produces labels sufficient for training keypose-conditioned diffusion policies that achieve performance equivalent to a standard diffusion policy baseline on robomimic tasks, and that filtering keypose candidates by a reachability map can support zero-shot cross-embodiment transfer on multimodal insertion when valid options are present.
What carries the argument
The automatic trajectory labelling pipeline that uses VLMs for semantic event detection on one demonstration and classical analysis for temporal alignment, paired with a reachability map to filter keypose candidates for cross-embodiment transfer.
If this is right
- Labelled data from the pipeline produces policies that match standard DP baseline performance.
- Reachability-filtered keypose conditioning benefits zero-shot transfer on the multimodal insertion task when feasible candidates are available.
- VLM inference is required only on one demo among repeating demonstrations per task.
- Keypose conditioning intervenes demonstration distributions inside the diffusion policy.
Where Pith is reading between the lines
- The single-demo labelling approach could lower data preparation costs for new manipulation tasks.
- Accurate reachability maps might extend transfer benefits to a broader set of robot morphologies.
- The method may apply to additional task types if VLM detection remains reliable outside grasp-related domains.
Load-bearing premise
The VLM semantic event detection on a single demonstration produces accurate enough labels for policy training, and the reachability map correctly identifies kinematically feasible keyposes for the target embodiment.
What would settle it
Policies trained on the automatically labelled data achieve success rates significantly below the standard diffusion policy baseline on the tested tasks, or reachability-filtered keypose conditioning produces no improvement or lower success rates on the multimodal insertion transfer.
Figures

read the original abstract
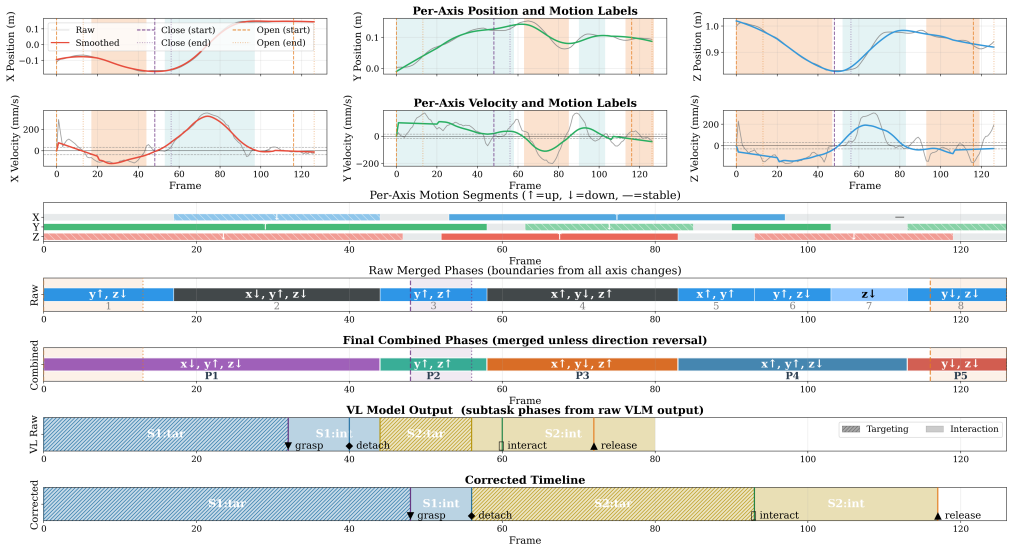
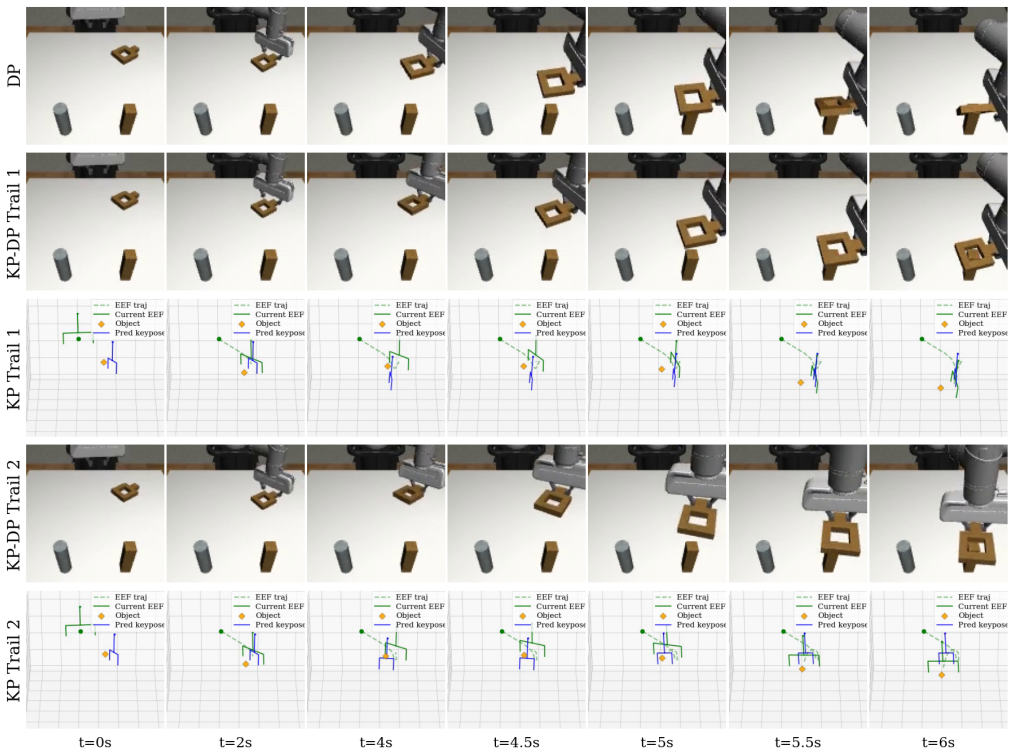
Keypose-based manipulation decomposes tasks into critical waypoints to simplify policy learning for long-horizon tasks, but existing approaches rely on task-specific heuristics or manual annotation to extract keyposes from demonstrations. We present an automatic trajectory labelling pipeline for grasp-related tasks. This pipeline combines vision-language models (VLMs) for semantic event detection with classical trajectory analysis for precise temporal alignment, requiring VLM inference only on one single demo among repeating ones per task. Using the labelled data, we train a keypose-guided Diffusion Policy (DP) that exploits keypose conditioning to intervene demonstration distributions. We explore the possibility to apply this property for cross-embodiment transfer: candidate keyposes are sampled and filtered via a reachability map, steering the policy toward kinematically feasible keyposes for the target robot. As a preliminary feasibility study, experiments on two robomimic tasks show that the labelled data produces policies matching a standard DP baseline, and that reachability-filtered keypose conditioning may benefit zero-shot transfer on the multimodal insertion task when feasible candidates are available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an automatic trajectory labelling pipeline for grasp-related manipulation tasks. It uses vision-language models (VLMs) to detect semantic events on a single demonstration, combined with classical trajectory analysis for precise alignment across multiple demos. The labelled data is used to train a keypose-guided Diffusion Policy (DP), which conditions on keyposes to steer the policy. The approach is explored for cross-embodiment policy transfer by sampling and filtering candidate keyposes using a reachability map to ensure kinematic feasibility for the target robot. As a preliminary study, experiments on two robomimic tasks demonstrate that policies from the labelled data match a standard DP baseline, and reachability-filtered conditioning may improve zero-shot transfer on the multimodal insertion task.
Significance. If the VLM labelling step proves reliable, the pipeline offers an efficiency advantage by requiring VLM inference on only one demo per task and could support more scalable keypose-based policies and cross-embodiment transfer without task-specific heuristics. The preliminary results on standard robomimic tasks provide a starting point for such methods. However, as a feasibility study limited to two tasks without detailed metrics or error bars, the significance remains exploratory.
major comments (2)
- [Abstract / experimental evaluation] The claim that labelled data produces policies matching a standard DP baseline (abstract) rests on the VLM correctly identifying grasp-related semantic events with sufficient temporal precision from a single demo. No quantitative validation of this step (e.g., precision/recall of detected events, temporal offset statistics, or ablation removing VLM labels) is reported against ground-truth annotations. This is load-bearing for the central claim, as systematic detection errors would invalidate the labels while still permitting apparent policy parity if the baseline is weak or tasks are simple.
- [Abstract / results discussion] The cross-embodiment transfer result is described only as 'may benefit' zero-shot transfer 'when feasible candidates are available' (abstract). Without reported quantitative improvements, conditions for candidate availability, or comparison to unfiltered conditioning, it is unclear whether the reachability map provides a meaningful advantage beyond the baseline DP.
minor comments (1)
- [Abstract] The abstract and introduction could more clearly distinguish the preliminary nature of the study (only two tasks) from the main claims to set appropriate expectations.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on this preliminary feasibility study. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract / experimental evaluation] The claim that labelled data produces policies matching a standard DP baseline (abstract) rests on the VLM correctly identifying grasp-related semantic events with sufficient temporal precision from a single demo. No quantitative validation of this step (e.g., precision/recall of detected events, temporal offset statistics, or ablation removing VLM labels) is reported against ground-truth annotations. This is load-bearing for the central claim, as systematic detection errors would invalidate the labels while still permitting apparent policy parity if the baseline is weak or tasks are simple.
Authors: We agree that direct quantitative validation of the VLM labelling (e.g., precision/recall or temporal offsets vs. ground truth) is absent and would strengthen the claims. As this is a preliminary end-to-end feasibility study on standard tasks, such annotations were not collected; policy parity with the baseline serves as indirect evidence of usable labels. We will partially revise the abstract and discussion to explicitly note this limitation and the preliminary scope. revision: partial
-
Referee: [Abstract / results discussion] The cross-embodiment transfer result is described only as 'may benefit' zero-shot transfer 'when feasible candidates are available' (abstract). Without reported quantitative improvements, conditions for candidate availability, or comparison to unfiltered conditioning, it is unclear whether the reachability map provides a meaningful advantage beyond the baseline DP.
Authors: The abstract already employs cautious phrasing ('may benefit'). We will revise to add a brief clarification on the conditions observed for the insertion task and the role of the reachability map in ensuring kinematic feasibility, while reiterating the preliminary nature of the result. revision: yes
- Quantitative validation of VLM event detection (precision/recall, temporal offsets) against ground-truth annotations, as no such annotations were collected in the original study.
Circularity Check
No significant circularity; empirical pipeline with external components
full rationale
The paper describes an empirical pipeline that applies an external VLM for semantic event detection on a single demonstration, followed by classical trajectory alignment to label the rest, then trains a conditioned Diffusion Policy and evaluates it on robomimic tasks. No equations, uniqueness theorems, or derivations are presented that reduce by construction to the inputs; the central claims are empirical performance matches to a baseline and preliminary transfer observations. The method relies on off-the-shelf VLM inference and standard reachability analysis rather than any self-referential fitting or self-citation chain. This is a standard applied robotics contribution whose results stand or fall on the reported experiments, not on tautological re-labeling of its own assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLMs can detect semantic events in robot demonstration videos accurately enough for labelling
- domain assumption Reachability maps can accurately filter kinematically feasible keyposes for target robots
Reference graph
Works this paper leans on
-
[1]
Act3D: 3D Feature Field Transformers for Multi-Task Robotic Manipulation,
T. Gervet, Z. Xian, N. Gkanatsios, and K. Fragkiadaki, “Act3D: 3D Feature Field Transformers for Multi-Task Robotic Manipulation,” in Conference on Robot Learning, 2023
2023
-
[2]
ChainedDiffuser: Unifying Trajectory Diffusion and Keypose Predic- tion for Robotic Manipulation,
Z. Xian, N. Gkanatsios, T. Gervet, T.-W. Ke, and K. Fragkiadaki, “ChainedDiffuser: Unifying Trajectory Diffusion and Keypose Predic- tion for Robotic Manipulation,” inConference on Robot Learning, 2023
2023
-
[3]
Hierarchical Diffusion Policy for Kinematics-Aware Multi-Task Robotic Manipulation,
X. Ma, S. Patidar, I. Haughton, and S. James, “Hierarchical Diffusion Policy for Kinematics-Aware Multi-Task Robotic Manipulation,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 081–18 090
2024
-
[4]
Bikc: Keypose-conditioned consistency policy for bimanual robotic manipulation,
D. Yu, H. Xu, Y . Chen, Y . Ren, and J. Pan, “Bikc: Keypose-conditioned consistency policy for bimanual robotic manipulation,”arXiv preprint arXiv:2406.10093, 2024
-
[5]
Bikc+: Bimanual hierarchical imitation with keypose-conditioned coordination-aware consistency policies,
H. Xu, Y . Chen, D. Yu, Y . Ren, and J. Pan, “Bikc+: Bimanual hierarchical imitation with keypose-conditioned coordination-aware consistency policies,”IEEE Transactions on Automation Science and Engineering, vol. 23, pp. 1064–1079, 2025
2025
-
[6]
Bi-KVIL: Keypoints-based visual imitation learning of bimanual manipulation tasks,
J. Gao, X. Jin, F. Krebs, N. Jaquier, and T. Asfour, “Bi-KVIL: Keypoints-based visual imitation learning of bimanual manipulation tasks,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 16 850–16 857
2024
-
[7]
A Pragmatic VLA Foundation Model
W. Wu, F. Lu, Y . Wang, S. Yang, S. Liu, F. Wang, Q. Zhu, H. Sun, Y . Wang, S. Maet al., “A pragmatic vla foundation model,”arXiv preprint arXiv:2601.18692, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Y . Lu, Y . Ma, and J. Pan, “Richmap: A reachability map balancing precision, efficiency, and flexibility for rich robot manipulation tasks,” arXiv preprint arXiv:2604.06778, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Martín-Martín, “What matters in learning from offline human demonstrations for robot manipulation,” inarXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Modeling human under- standing of complex intentional action with a bayesian nonparametric subgoal model,
R. Nakahashi, C. Baker, and J. Tenenbaum, “Modeling human under- standing of complex intentional action with a bayesian nonparametric subgoal model,” inAAAI Conference on Artificial Intelligence, vol. 30, no. 1, 2016
2016
-
[11]
Humans choose visual subgoals to reduce cognitive cost,
F. J. Binder, M. G. Mattar, D. Kirsh, and J. E. Fan, “Humans choose visual subgoals to reduce cognitive cost,” inAnnual Meeting of the Cognitive Science Society, vol. 45, no. 45, 2023
2023
-
[12]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,
T. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,” inRobotics: Science and Systems, 2023
2023
-
[13]
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots,
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song, “Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots,” inRobotics: Science and Systems, 2024
2024
-
[14]
Body Extension by Using Two Mobile Manipulators,
Y . Hirao, W. Wan, D. Kanoulas, and K. Harada, “Body Extension by Using Two Mobile Manipulators,”Cyborg and Bionic Systems, vol. 4, p. 0014, Jan. 2023
2023
-
[15]
A Novel Robust Imitation Learning Framework for Complex Skills With Limited Demonstrations,
W. Wang, C. Zeng, H. Zhan, and C. Yang, “A Novel Robust Imitation Learning Framework for Complex Skills With Limited Demonstrations,” IEEE Transactions on Automation Science and Engineering, pp. 1–13, 2024
2024
-
[16]
LeTO: Learning Constrained Visuomotor Policy With Differentiable Trajectory Optimization,
Z. Xu and Y . She, “LeTO: Learning Constrained Visuomotor Policy With Differentiable Trajectory Optimization,”IEEE Transactions on Automation Science and Engineering, pp. 1–12, 2024
2024
-
[17]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[18]
ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation,
G. Lu, Z. Gao, T. Chen, W. Dai, Z. Wang, and Y . Tang, “ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation,” 2024
2024
-
[19]
Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation,
A. Prasad, K. Lin, J. Wu, L. Zhou, and J. Bohg, “Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation,” in Robotics: Science and Systems, 2024
2024
-
[20]
Consistency models,
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 32 211–32 252
2023
-
[21]
Improved Techniques for Training Consis- tency Models,
Y . Song and P. Dhariwal, “Improved Techniques for Training Consis- tency Models,” inInternational Conference on Learning Representa- tions, 2024
2024
-
[22]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
On the continuity of rotation representations in neural networks,
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li, “On the continuity of rotation representations in neural networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5745–5753
2019
-
[24]
Mirage: Cross-embodiment zero-shot policy transfer with cross-painting,
L. Y . Chen, K. Hari, K. Dharmarajan, C. Xu, Q. Vuong, and K. Goldberg, “Mirage: Cross-embodiment zero-shot policy transfer with cross-painting,”arXiv preprint arXiv:2402.19249, 2024
-
[25]
Oxe-auge: A large-scale robot augmentation of oxe for scaling cross-embodiment policy learning,
G. Ji, H. Polavaram, L. Y . Chen, S. Bajamahal, Z. Ma, S. Adebola, C. Xu, and K. Goldberg, “Oxe-auge: A large-scale robot augmentation of oxe for scaling cross-embodiment policy learning,”arXiv preprint arXiv:2512.13100, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.