Verifiable Rewards for Calibrated Probabilistic Forecasting
Pith reviewed 2026-07-02 19:43 UTC · model grok-4.3
The pith
A 7B model trained solely on a verifiable empirical win rate reward matches betting market calibration for NFL forecasts without labels or supervised fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
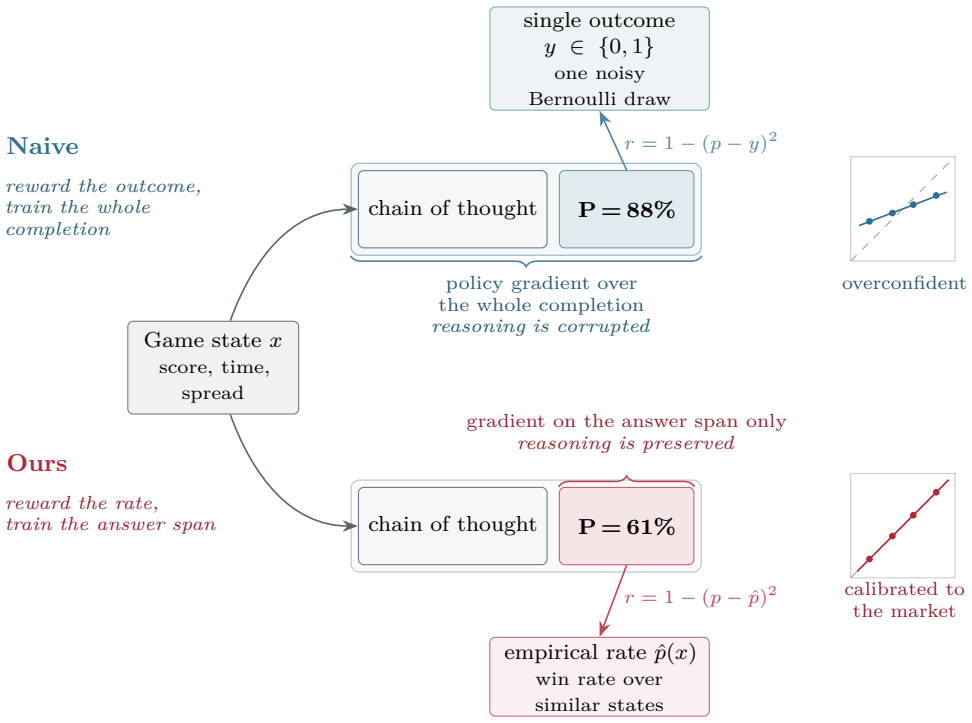
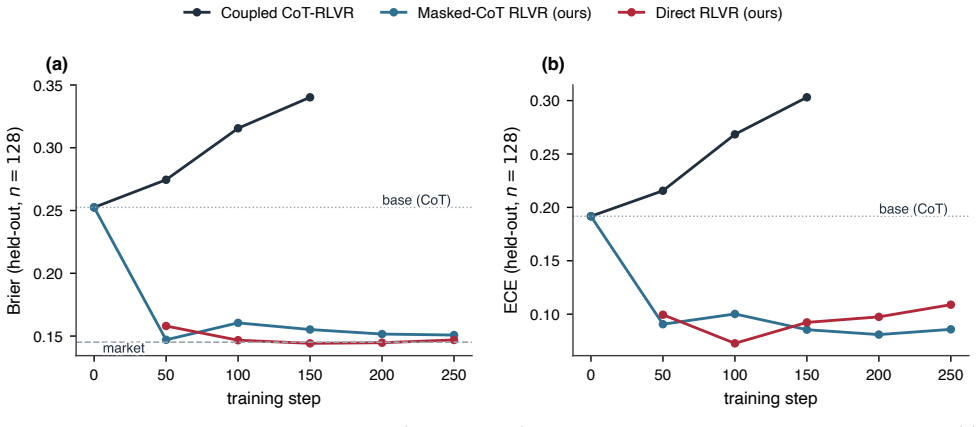
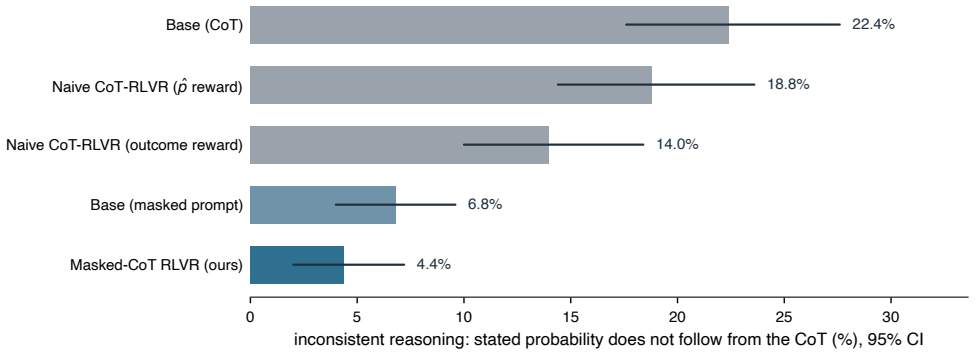
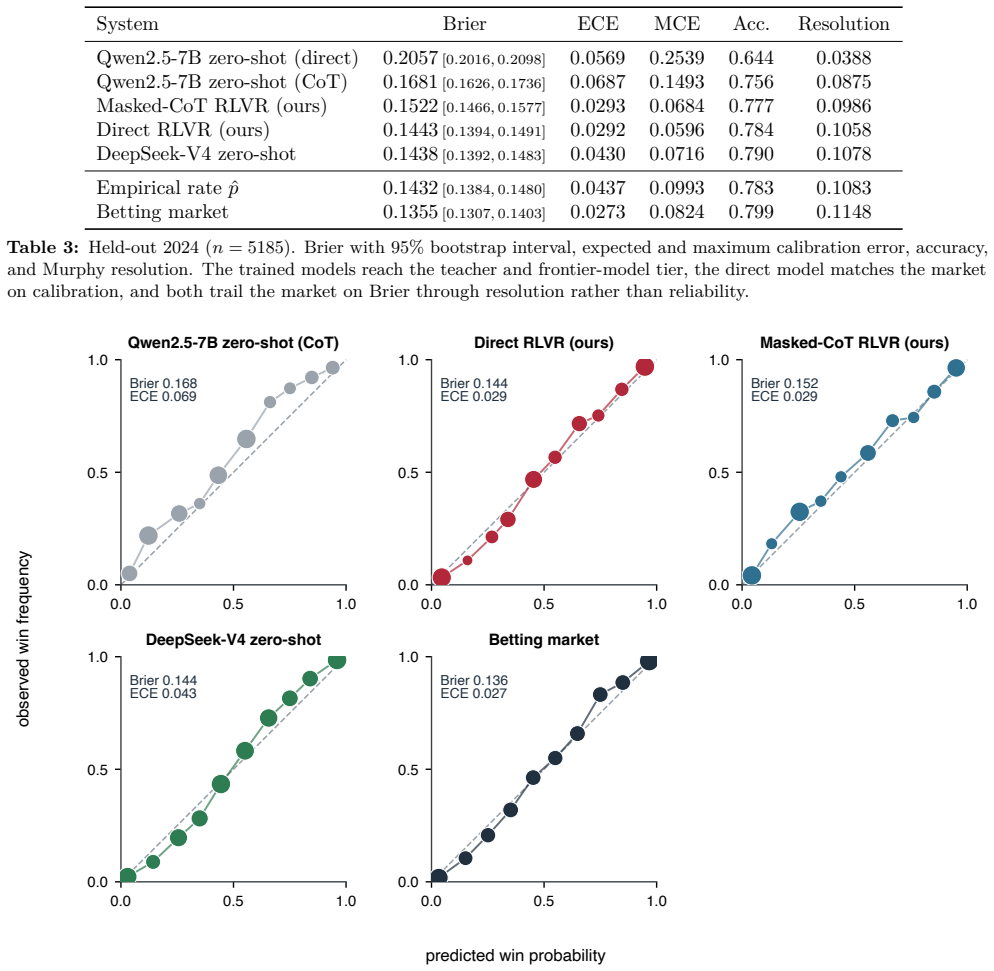
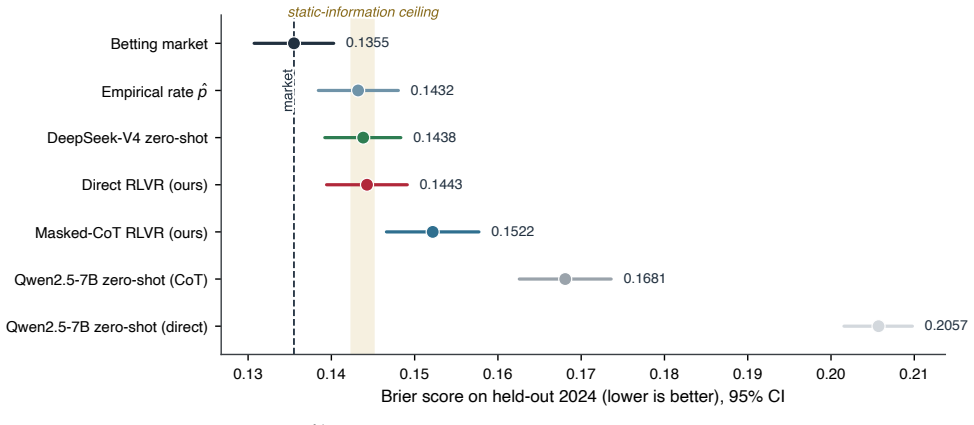
Reinforcement learning with verifiable rewards can in principle train calibrated probabilistic forecasters because a proper scoring rule such as the Brier score is minimized in expectation by the true probability. For aleatoric forecasting where the label is one stochastic outcome, rewarding the realized per-play outcome fails due to noise and policy gradient corruption of the chain of thought. A verifiable label-free reward given by the state-conditioned empirical win rate estimated from past outcomes removes the label noise. Keeping the gradient off the reasoning by direct prediction or a gradient mask lets a 7B model trained with this reward alone reach the calibration of the betting mark
What carries the argument
State-conditioned empirical win rate estimated from past outcomes, used as verifiable reward with direct prediction or gradient mask to isolate it from reasoning.
If this is right
- Models reach betting-market calibration on aleatoric tasks using only outcome-derived rewards without human labels.
- Gradient masking preserves reasoning chains that ordinary chain-of-thought training corrupts.
- The betting market's remaining edge arises from live in-game information beyond the inputs shared with the model and tabular estimator.
- The same Brier score achieved by the frontier model, tabular estimator, and this trained model shows their shared inputs limit further improvement.
Where Pith is reading between the lines
- The reward construction could extend to other domains with frequent verifiable outcomes such as election or weather forecasting.
- Separating reward computation from reasoning steps may be necessary for RL to succeed on any probabilistic output task.
- This approach reduces dependence on supervised fine-tuning when historical outcome data is abundant.
Load-bearing premise
The state-conditioned empirical win rate estimated from past outcomes serves as an unbiased, noise-free proxy for the true conditional probability that aligns with the Brier score optimum.
What would settle it
Retraining the 7B model with the same reward on a fresh set of NFL seasons and finding its Brier score worse than the betting market on those seasons would falsify the central claim.
Figures

read the original abstract
Reinforcement learning with verifiable rewards can in principle train calibrated probabilistic forecasters, since a proper scoring rule such as the Brier score is computed from outcomes alone and is minimized in expectation by the true probability. In practice it degrades calibration, and existing remedies address epistemic uncertainty, where a model's confidence accompanies a verifiably correct or incorrect answer. We study aleatoric forecasting, where the forecast itself is the output and the label is one stochastic outcome, taking NFL in-game win probability as a testbed with the betting market as a reference. Rewarding the realized per-play outcome fails, because the single outcome is a noisy target and the policy gradient corrupts the chain of thought. We introduce a verifiable, label-free reward, a state-conditioned empirical win rate estimated from past outcomes, that removes the label noise, and we keep the gradient off the reasoning, by direct prediction or a gradient mask, so it cannot be corrupted. Trained with this reward alone, without human labels or supervised fine-tuning, a 7B model reaches the calibration of the betting market by direct prediction and is better calibrated than a zero-shot frontier model. That frontier model and a tabular estimator reach the same Brier score as this model, identifying the market's small remaining edge as live in-game information beyond their shared inputs. Masking the gradient, rather than dropping the chain of thought, preserves reasoning from which the forecast follows, which ordinary chain-of-thought training corrupts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a verifiable reward for RL-based training of calibrated probabilistic forecasters in aleatoric settings, using a state-conditioned empirical win rate r(s) estimated from historical NFL outcomes instead of single noisy play results. It claims that a 7B model trained solely with this reward (via direct prediction or gradient masking) achieves calibration matching the betting market and exceeding zero-shot frontier models, while identifying the market's residual edge as arising from live in-game information beyond shared inputs; gradient masking is shown to preserve reasoning chains that ordinary CoT training corrupts.
Significance. If the central empirical claims hold after addressing verification gaps, the work demonstrates a label-free route to calibrated probabilistic forecasting via proper scoring rules on historical aggregates, with direct applicability to other aleatoric domains. The explicit separation of direct prediction versus masked-gradient training, and the identification that tabular estimators and frontier models match the trained model's Brier score, provides a concrete baseline for when additional live information matters.
major comments (2)
- [§4] §4 (empirical results) and the definition of r(s): the central claim that the 7B model reaches betting-market calibration rests on r(s) serving as an unbiased proxy for E[outcome|s]; however, the manuscript provides no quantitative details on state binning (clock, score differential, down, yard line), historical sample sizes per bin, variance of r(s) in sparse states, or handling of non-stationarity across rule changes and roster turnover. Without these, it is impossible to verify that gradient steps on the Brier objective converge to the true conditional probability rather than finite-sample historical averages.
- [Abstract, §5] Abstract and §5 (comparisons): the claim that the trained model 'reaches the calibration of the betting market' and is 'better calibrated than a zero-shot frontier model' is stated without reported Brier scores, ECE values, sample sizes, statistical significance tests, or calibration plots with confidence intervals. This leaves the strongest empirical assertion without verifiable support and prevents assessment of whether the result is load-bearing or sensitive to implementation choices in the empirical estimator.
minor comments (2)
- [§3] Notation for the reward r(s) and the gradient mask should be introduced with an explicit equation early in §3 to avoid ambiguity when comparing direct-prediction versus masked variants.
- [Appendix] The manuscript should include a table or appendix listing the exact state variables and binning thresholds used to construct the empirical win rates.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond point-by-point to the major comments below and indicate revisions that will be incorporated to strengthen the verifiability of the empirical results.
read point-by-point responses
-
Referee: [§4] §4 (empirical results) and the definition of r(s): the central claim that the 7B model reaches betting-market calibration rests on r(s) serving as an unbiased proxy for E[outcome|s]; however, the manuscript provides no quantitative details on state binning (clock, score differential, down, yard line), historical sample sizes per bin, variance of r(s) in sparse states, or handling of non-stationarity across rule changes and roster turnover. Without these, it is impossible to verify that gradient steps on the Brier objective converge to the true conditional probability rather than finite-sample historical averages.
Authors: We agree that the manuscript omits these quantitative details on r(s) construction. In revision we will add a new subsection to §4 specifying the exact binning rules for clock, score differential, down, and yard line; reporting minimum and average historical sample sizes per bin; providing variance estimates for sparse bins; and describing our handling of non-stationarity via season-restricted data windows. These additions will allow readers to assess how closely r(s) approximates the conditional expectation. We note that the Brier objective remains proper even with finite-sample r(s), and the empirical results show the trained model matches the market's calibration, but the requested details will make this convergence verifiable. revision: yes
-
Referee: [Abstract, §5] Abstract and §5 (comparisons): the claim that the trained model 'reaches the calibration of the betting market' and is 'better calibrated than a zero-shot frontier model' is stated without reported Brier scores, ECE values, sample sizes, statistical significance tests, or calibration plots with confidence intervals. This leaves the strongest empirical assertion without verifiable support and prevents assessment of whether the result is load-bearing or sensitive to implementation choices in the empirical estimator.
Authors: The referee is correct that specific numerical values, statistical tests, and plots with intervals are not reported in the abstract or §5. We will revise both sections to include the Brier scores and ECE for the 7B model, betting market, tabular estimator, and zero-shot frontier models; the evaluation sample size; results of paired significance tests; and calibration plots with bootstrap confidence intervals. These additions will directly support the calibration claims and allow assessment of robustness. The underlying argument that the verifiable reward enables label-free calibration to market levels remains unchanged. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation uses an external historical dataset to compute state-conditioned empirical win rates as the verifiable reward target, then applies a proper scoring rule (Brier) to train the model against that fixed target. This is independent of the model's own outputs or any fitted parameters from the current run. The final calibration claim is benchmarked against an external betting market and a tabular estimator on the same data, with no load-bearing self-citation, no renaming of known results as new derivations, and no step where a prediction is definitionally equivalent to its input. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math A proper scoring rule such as the Brier score is minimized in expectation by the true conditional probability.
Reference graph
Works this paper leans on
-
[1]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeek- Math: Pushing the limits of mathematical rea- soning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645 (8081):633–638, 2025. arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Glenn W. Brier. Verification of forecasts expressed in terms of probability.Monthly Weather Review, 78(1):1–3, 1950
1950
-
[4]
Tilmann Gneiting and Adrian E. Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102 (477):359–378, 2007
2007
-
[5]
Taming overconfidence in LLMs: Reward calibration in RLHF.arXiv preprint arXiv:2410.09724, 2024
Jixuan Leng, Chengsong Huang, Banghua Zhu, and Jiaxin Huang. Taming overconfidence in LLMs: Reward calibration in RLHF.arXiv preprint arXiv:2410.09724, 2024
-
[6]
Zhengzhao Ma, Xueru Wen, Boxi Cao, Yaojie Lu, Hongyu Lin, Jinglin Yang, Min He, Xianpei Han, and Le Sun. Decoupling reasoning and confidence: Resurrecting calibration in reinforcement learning from verifiable rewards. InProceedings of the 43rd International Conference on Machine Learning (ICML), 2026. arXiv:2603.09117
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Michael Bereket and Jure Leskovec. Uncal- ibrated reasoning: GRPO induces overconfi- dence for stochastic outcomes.arXiv preprint arXiv:2508.11800, 2025
-
[8]
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Mehul Damani, Isha Puri, Stewart Slocum, Idan Shenfeld, Leshem Choshen, Yoon Kim, and Jacob Andreas. Beyond binary rewards: Training LMs to reason about their uncertainty.arXiv preprint arXiv:2507.16806, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
arXiv preprint arXiv:2503.02623 , year=
David Bani-Harouni, Chantal Pellegrini, Paul Stan- gel, Ege Özsoy, Kamilia Zaripova, Nassir Navab, and Matthias Keicher. Rewarding doubt: A re- inforcement learning approach to calibrated confi- dence expression of large language models.arXiv preprint arXiv:2503.02623, 2025
-
[10]
Linguistic calibration of long-form gen- erations
Neil Band, Xuechen Li, Tengyu Ma, and Tatsunori Hashimoto. Linguistic calibration of long-form gen- erations. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024. arXiv:2404.00474
-
[11]
Approaching human-level fore- casting with language models
Danny Halawi, Fred Zhang, Chen Yueh-Han, and Jacob Steinhardt. Approaching human-level fore- casting with language models. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[12]
Can language models use forecasting strategies?arXiv preprint arXiv:2406.04446, 2024
Sarah Pratt, Seth Blumberg, Pietro Kreitlon Car- olino, and Meredith Ringel Morris. Can language models use forecasting strategies?arXiv preprint arXiv:2406.04446, 2024
-
[13]
Outcome- based reinforcement learning to predict the future
Benjamin Turtel, Danny Franklin, Kris Skotheim, Luke Hewitt, and Philipp Schoenegger. Outcome- based reinforcement learning to predict the future. arXiv preprint arXiv:2505.17989, 2025. 9
-
[14]
LLMs can teach themselves to better predict the future.arXiv preprint arXiv:2502.05253, 2025
Benjamin Turtel, Danny Franklin, and Philipp Schoenegger. LLMs can teach themselves to better predict the future.arXiv preprint arXiv:2502.05253, 2025
-
[15]
Pitfalls in evaluating language model forecasters.arXiv preprint arXiv:2506.00723, 2025
Daniel Paleka, Shashwat Goel, Jonas Geiping, and Florian Tramèr. Pitfalls in evaluating language model forecasters.arXiv preprint arXiv:2506.00723, 2025
-
[16]
Ezra Karger, Houtan Bastani, Chen Yueh-Han, Zachary Jacobs, Danny Halawi, Fred Zhang, and PhilipE.Tetlock. ForecastBench: Adynamicbench- mark of AI forecasting capabilities.arXiv preprint arXiv:2409.19839, 2024
-
[17]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, et al. DAPO: An open- source LLM reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
GPG: A simple and strong reinforcement learning baseline for model reasoning
Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, and Yong Wang. GPG: A simple and strong reinforcement learning baseline for model reasoning. InInternational Conference on Learning Represen- tations (ICLR), 2026. arXiv:2504.02546
-
[19]
On the design of KL-regularized policy gradient algo- rithms for LLM reasoning
YifanZhang, YifengLiu, HuizhuoYuan, YangYuan, Quanquan Gu, and Andrew Chi-Chih Yao. On the design of KL-regularized policy gradient algo- rithms for LLM reasoning. InInternational Con- ference on Learning Representations (ICLR), 2026. arXiv:2505.17508
-
[20]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, JianxinYang, ZhenruZhang, YuqiongLiu, AnYang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. InAd- vances in Neural Information P...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Stabilizing Knowledge, Promoting Reasoning: Dual-Token Constraints for RLVR
Jiakang Wang, Runze Liu, Fuzheng Zhang, Xiu Li, Guorui Zhou, and Ling Pan. Stabilizing knowledge, promoting reasoning: Dual-token constraints for RLVR.arXiv preprint arXiv:2507.15778, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
arXiv preprint arXiv:2508.04349 , year=
Hongze Tan, Zihan Wang, Jianfei Pan, Jinghao Lin, Hao Wang, Yifan Wu, Tao Chen, Zhihang Zheng, Zhihao Tang, and Haihua Yang. GTPO and GRPO- S: Token and sequence-level reward shaping with policy entropy.arXiv preprint arXiv:2508.04349, 2025
-
[23]
Using random forests to estimate win probability before each play of an NFL game.Journal of Quantitative Analysis in Sports, 10(2):197–205, 2014
Dennis Lock and Dan Nettleton. Using random forests to estimate win probability before each play of an NFL game.Journal of Quantitative Analysis in Sports, 10(2):197–205, 2014
2014
-
[24]
nflWAR: A Reproducible Method for Offensive Player Evaluation in Football
Ronald Yurko, Samuel Ventura, and Maksim Horowitz. nflWAR: A reproducible method for offensive player evaluation in football.Journal of Quantitative Analysis in Sports, 15(3), 2019. arXiv:1802.00998
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Sebastian Carl and Ben Baldwin.nflfastR: Func- tions to Efficiently Access NFL Play by Play Data,
-
[26]
R pack- age
URL https://www.nflfastr.com/. R pack- age
-
[27]
Brill, Ronald Yurko, and Abraham J
Ryan S. Brill, Ronald Yurko, and Abraham J. Wyner. Exploring the difficulty of estimating win probability: A simulation study.Journal of Quan- titative Analysis in Sports, 2025. arXiv:2406.16171
-
[28]
Polson and Hal S
Nicholas G. Polson and Hal S. Stern. The implied volatility of a sports game.Journal of Quantitative Analysis in Sports, 11(3):145–153, 2015
2015
-
[29]
Boulier and H
Bryan L. Boulier and H. O. Stekler. Predicting the outcomes of national football league games.In- ternational Journal of Forecasting, 19(2):257–270, 2003
2003
-
[30]
Steven D. Levitt. Why are gambling markets or- ganised so differently from financial markets?The Economic Journal, 114(495):223–246, 2004
2004
-
[31]
Prediction accuracy of different market structures: Bookmakers versus a betting exchange.Interna- tional Journal of Forecasting, 26(3):448–459, 2010
Egon Franck, Erwin Verbeek, and Stephan Nüesch. Prediction accuracy of different market structures: Bookmakers versus a betting exchange.Interna- tional Journal of Forecasting, 26(3):448–459, 2010
2010
-
[32]
Schwartz, Bonnie F
Justin Cox, Adam L. Schwartz, Bonnie F. Van Ness, and Robert A. Van Ness. The predictive power of college football spreads: Regular season versus bowl games.Journal of Sports Economics, 22(3):251–273, 2021
2021
-
[33]
On determining probability fore- casts from betting odds.International Journal of Forecasting, 30(4):934–943, 2014
Erik Štrumbelj. On determining probability fore- casts from betting odds.International Journal of Forecasting, 30(4):934–943, 2014
2014
-
[34]
Allan H. Murphy. A new vector partition of the probability score.Journal of Applied Meteorology, 12(4):595–600, 1973
1973
-
[35]
On Calibration of Modern Neural Networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural net- works. InProceedings of the 34th International Conference on Machine Learning (ICML), 2017. arXiv:1706.04599
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Jochen Bröcker and Leonard A. Smith. Increasing the reliability of reliability diagrams.Weather and Forecasting, 22(3):651–661, 2007. 10
2007
-
[37]
Timo Dimitriadis, Tilmann Gneiting, and Alexan- der I. Jordan. Stable reliability diagrams for prob- abilistic classifiers.Proceedings of the National Academy of Sciences, 118(8):e2016191118, 2021
2021
-
[38]
Bootstrap methods: Another look at the jackknife.The Annals of Statistics, 7(1):1–26, 1979
Bradley Efron. Bootstrap methods: Another look at the jackknife.The Annals of Statistics, 7(1):1–26, 1979
1979
-
[39]
Data analysis using Stein’s estimator and its generalizations.Journal of the American Statistical Association, 70(350): 311–319, 1975
Bradley Efron and Carl Morris. Data analysis using Stein’s estimator and its generalizations.Journal of the American Statistical Association, 70(350): 311–319, 1975. 11 A The empirical-rate target The reward targetˆp(x)is a state-conditioned empirical win rate estimated from training-season outcomes. Each play is placed in a bucket defined by three game-l...
1975
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.