MindAU: EEG-Conditioned Facial Action Unit Editing via Dual-Stream Manifold Alignment
Pith reviewed 2026-07-02 15:21 UTC · model grok-4.3
The pith
EEG brain signals can guide precise edits to specific facial action units while preserving a person's identity through manifold alignment in a multimodal space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
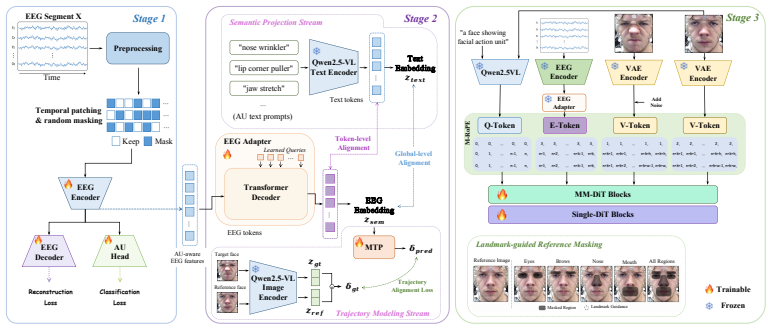
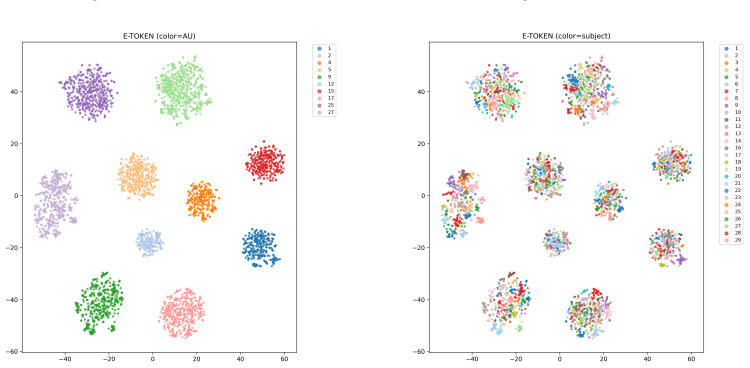
MindAU learns noise-robust and AU-discriminative EEG representations via temporal masked reconstruction and AU classification, then bridges the modality gap with Dual-Stream Manifold Alignment that maps EEG features to AU-level text semantics and identity-reduced visual displacement trajectories inside the multimodal space of Qwen2.5-VL; the aligned representations feed an EEG-aware multimodal diffusion editor equipped with rotary positional embeddings, landmark-guided masking, and region supervision to produce high-fidelity identity-preserving AU edits.
What carries the argument
Dual-Stream Manifold Alignment, which aligns EEG features with AU-level text semantics and identity-reduced visual displacement trajectories in the multimodal space.
If this is right
- High-fidelity identity-preserving facial AU editing conditioned directly on EEG signals becomes feasible.
- A standardized benchmark dataset with paired EEG-face editing samples enables consistent evaluation of such methods.
- The framework points toward assistive expression technologies for individuals with facial neuromuscular disorders.
Where Pith is reading between the lines
- The alignment technique could be tested for robustness when EEG is recorded under varying electrode placements or subject fatigue levels.
- Similar manifold alignment might apply to mapping EEG to other motor outputs, such as hand gestures in prosthetic control.
- Real-time deployment would require measuring whether the diffusion editor and alignment steps can run at interactive speeds on modest hardware.
Load-bearing premise
EEG signals contain identifiable, AU-discriminative patterns that can be robustly extracted and aligned with visual displacement trajectories without significant loss of information or introduction of artifacts from noise or individual variability.
What would settle it
A controlled test in which EEG features yield AU classification accuracy no better than chance after supervised training, or in which the resulting image edits produce measurable identity mismatch on standard face verification metrics.
Figures







read the original abstract
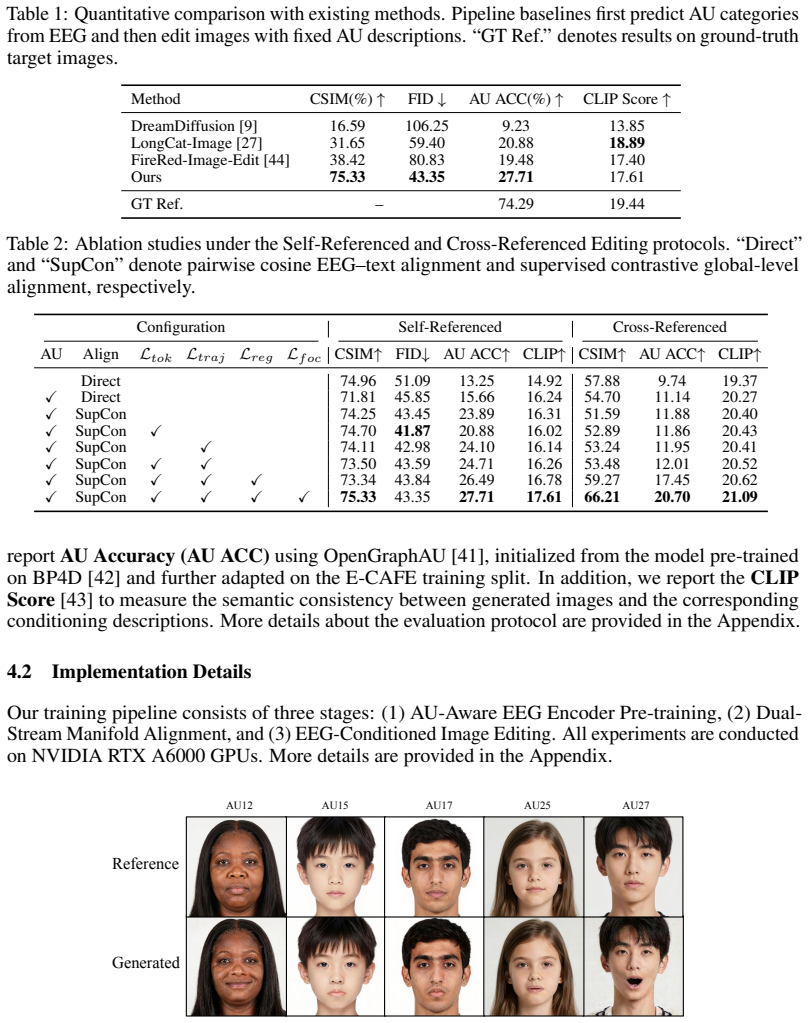
Recent brain decoding studies have made substantial progress in reconstructing externally perceived visual content from neural signals. However, using electroencephalography (EEG) recordings to guide facial expression editing remains largely unexplored and poses a distinct challenge: rather than recovering what a subject sees, it requires identifying facial-action related patterns from noisy EEG signals and grounding them in localized, identity-preserving expression edits. In this paper, we investigate EEG-conditioned facial image editing for fine-grained facial action unit (AU) control and propose MindAU, a unified framework for controlling facial AU edits from EEG signals. MindAU first learns noise-robust and AU-discriminative EEG representations through temporal masked reconstruction and AU classification supervision. It then bridges the modality gap via Dual-Stream Manifold Alignment, aligning EEG features with AU-level text semantics and identity-reduced visual displacement trajectories in the multimodal space of Qwen2.5-VL. Finally, MindAU incorporates EEG-aware Multimodal Rotary Positional Embeddings, landmark-guided reference masking, and AU-aware region supervision into a multimodal diffusion-based editor for high-fidelity identity-preserving editing. We also introduce E-CAFE, a curated benchmark for EEG-Conditioned Action-Unit Facial Editing with paired EEG-face editing samples and standardized evaluation protocols. Extensive experiments demonstrate the effectiveness of MindAU and suggest its potential as a step towards future assistive expression technologies for individuals with facial neuromuscular disorders.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MindAU, a framework for EEG-conditioned facial action unit (AU) editing. It first trains an EEG encoder with temporal masked reconstruction and AU classification supervision to obtain noise-robust, AU-discriminative representations. It then applies Dual-Stream Manifold Alignment to map these EEG features into the multimodal space of Qwen2.5-VL, aligning them with AU-level text semantics and identity-reduced visual displacement trajectories. The aligned features are injected into a multimodal diffusion editor via EEG-aware Multimodal Rotary Positional Embeddings, landmark-guided reference masking, and AU-aware region supervision to produce high-fidelity, identity-preserving edits. The work also introduces the E-CAFE benchmark containing paired EEG-face editing samples together with standardized evaluation protocols, and reports extensive experiments on this benchmark.
Significance. If the empirical claims hold, the work would represent a meaningful step toward assistive expression technologies for individuals with facial neuromuscular disorders by demonstrating that EEG signals can drive fine-grained, identity-preserving AU edits. The release of the E-CAFE benchmark with paired data and protocols is a concrete, reusable contribution that lowers the barrier for future research in this emerging intersection of brain-computer interfaces and generative vision.
major comments (2)
- [Abstract, §3.1] The central claim that Dual-Stream Manifold Alignment produces effective EEG-conditioned edits rests on the unverified premise that the EEG encoder (temporal masked reconstruction + AU classification) isolates AU-specific variance rather than subject identity, artifacts, or unrelated activity. No quantitative results (e.g., AU classification accuracy, confusion matrices, or ablation removing the classification loss) are cited to show that the learned representations are sufficiently AU-discriminative to support the subsequent alignment inside Qwen2.5-VL space.
- [§3.2] The identity-reduced visual displacement trajectories used in the alignment step are described only at a high level; it is unclear how identity reduction is performed and whether the resulting trajectories remain sufficiently informative for AU-level control. If the reduction inadvertently removes AU-relevant motion, the manifold alignment would be aligning EEG features to an impoverished target, undermining the editing performance reported on E-CAFE.
minor comments (2)
- [Abstract] The abstract states that 'extensive experiments demonstrate the effectiveness of MindAU' yet provides no numerical metrics, baseline comparisons, or statistical significance tests; these should be summarized with effect sizes in the abstract or a results table reference.
- [§3.3] Notation for the EEG-aware Multimodal Rotary Positional Embeddings (MRoPE) is introduced without an explicit equation; adding the formulation (even if standard RoPE is extended) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the potential impact of MindAU and the E-CAFE benchmark. We address each major comment below and will revise the manuscript accordingly to improve clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract, §3.1] The central claim that Dual-Stream Manifold Alignment produces effective EEG-conditioned edits rests on the unverified premise that the EEG encoder (temporal masked reconstruction + AU classification) isolates AU-specific variance rather than subject identity, artifacts, or unrelated activity. No quantitative results (e.g., AU classification accuracy, confusion matrices, or ablation removing the classification loss) are cited to show that the learned representations are sufficiently AU-discriminative to support the subsequent alignment inside Qwen2.5-VL space.
Authors: We agree that explicit quantitative validation of the EEG encoder would strengthen the central claim. The current manuscript describes the temporal masked reconstruction and AU classification supervision but does not report the corresponding metrics. In the revised version we will add AU classification accuracy, confusion matrices, and an ablation removing the classification loss (placed in §3.1 and the experiments section) to demonstrate that the representations are AU-discriminative rather than dominated by identity or artifacts. revision: yes
-
Referee: [§3.2] The identity-reduced visual displacement trajectories used in the alignment step are described only at a high level; it is unclear how identity reduction is performed and whether the resulting trajectories remain sufficiently informative for AU-level control. If the reduction inadvertently removes AU-relevant motion, the manifold alignment would be aligning EEG features to an impoverished target, undermining the editing performance reported on E-CAFE.
Authors: We acknowledge that the description of identity reduction in §3.2 is high-level and requires clarification. Identity reduction is performed by subtracting subject-specific mean displacement trajectories (computed across multiple expressions per subject) while retaining per-sample AU-related motion. In the revision we will expand §3.2 with this procedure and add supporting analysis (e.g., correlation of retained trajectories with AU annotations) to confirm that AU-relevant information is preserved. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained with independent components
full rationale
The provided abstract and context describe a new multimodal framework (MindAU) that introduces temporal masked reconstruction + AU classification for EEG features, Dual-Stream Manifold Alignment into Qwen2.5-VL space, EEG-aware MRoPE, and a new benchmark E-CAFE. No equations, fitted parameters presented as predictions, self-citations, or uniqueness theorems are visible that would reduce any claimed result to its own inputs by construction. The central steps rely on external pretrained models and standard supervision signals rather than tautological redefinitions or load-bearing self-references. This matches the default expectation of a non-circular proposal of an architecture and benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yuqin Dai, Zhouheng Yao, Chunfeng Song, Qihao Zheng, Weijian Mai, Kunyu Peng, Shuai Lu, Wanli Ouyang, Jian Yang, and Jiamin Wu. Mindaligner: Explicit brain functional alignment for cross-subject visual decoding from limited fmri data.arXiv preprint arXiv:2502.05034, 2025
-
[2]
Mindbridge: A cross-subject brain decoding framework
Shizun Wang, Songhua Liu, Zhenxiong Tan, and Xinchao Wang. Mindbridge: A cross-subject brain decoding framework. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11333–11342, 2024
2024
-
[3]
Toward generalizing visual brain decoding to unseen subjects.arXiv preprint arXiv:2410.14445, 2024
Xiangtao Kong, Kexin Huang, Ping Li, and Lei Zhang. Toward generalizing visual brain decoding to unseen subjects.arXiv preprint arXiv:2410.14445, 2024
-
[4]
Yizhuo Lu, Changde Du, Chong Wang, Xuanliu Zhu, Liuyun Jiang, Xujin Li, and Huiguang He. Animate your thoughts: Decoupled reconstruction of dynamic natural vision from slow brain activity.arXiv preprint arXiv:2405.03280, 2024
-
[5]
Cinematic mindscapes: High-quality video re- construction from brain activity.Advances in Neural Information Processing Systems, 36:24841– 24858, 2023
Zijiao Chen, Jiaxin Qing, and Juan Helen Zhou. Cinematic mindscapes: High-quality video re- construction from brain activity.Advances in Neural Information Processing Systems, 36:24841– 24858, 2023
2023
-
[6]
Eeg2video: Towards decoding dynamic visual perception from eeg signals.Advances in Neural Information Processing Systems, 37:72245–72273, 2024
Xuan-Hao Liu, Yan-Kai Liu, Yansen Wang, Kan Ren, Hanwen Shi, Zilong Wang, Dongsheng Li, Bao-Liang Lu, and Wei-Long Zheng. Eeg2video: Towards decoding dynamic visual perception from eeg signals.Advances in Neural Information Processing Systems, 37:72245–72273, 2024
2024
-
[7]
Contrast, attend and diffuse to decode high-resolution images from brain activities
Jingyuan Sun, Mingxiao Li, Zijiao Chen, Yunhao Zhang, Shaonan Wang, and Marie-Francine Moens. Contrast, attend and diffuse to decode high-resolution images from brain activities. Advances in Neural Information Processing Systems, 36:12332–12348, 2023
2023
-
[8]
Reconstructing the mind’s eye: fmri-to-image with contrastive learning and diffusion priors.Advances in Neural Information Processing Systems, 36:24705–24728, 2023
Paul Scotti, Atmadeep Banerjee, Jimmie Goode, Stepan Shabalin, Alex Nguyen, Aidan Demp- ster, Nathalie Verlinde, Elad Yundler, David Weisberg, Kenneth Norman, et al. Reconstructing the mind’s eye: fmri-to-image with contrastive learning and diffusion priors.Advances in Neural Information Processing Systems, 36:24705–24728, 2023
2023
-
[9]
Dreamdif- fusion: High-quality eeg-to-image generation with temporal masked signal modeling and clip alignment
Yunpeng Bai, Xintao Wang, Yan-Pei Cao, Yixiao Ge, Chun Yuan, and Ying Shan. Dreamdif- fusion: High-quality eeg-to-image generation with temporal masked signal modeling and clip alignment. InEuropean Conference on Computer Vision, pages 472–488. Springer, 2024
2024
-
[10]
Bell’s palsy: the spontaneous course of 2,500 peripheral facial nerve palsies of different etiologies.Acta oto-laryngologica, 122(7):4–30, 2002
Erik Peitersen. Bell’s palsy: the spontaneous course of 2,500 peripheral facial nerve palsies of different etiologies.Acta oto-laryngologica, 122(7):4–30, 2002
2002
-
[11]
The human face as a dynamic tool for social communi- cation.Current Biology, 25(14):R621–R634, 2015
Rachael E Jack and Philippe G Schyns. The human face as a dynamic tool for social communi- cation.Current Biology, 25(14):R621–R634, 2015
2015
-
[12]
The psychosocial impact of facial palsy: a systematic review.British Journal of Health Psychology, 25(3):695–727, 2020
Matthew Hotton, Esme Huggons, Claire Hamlet, Danielle Shore, David Johnson, Jonathan H Norris, Sarah Kilcoyne, and Louise Dalton. The psychosocial impact of facial palsy: a systematic review.British Journal of Health Psychology, 25(3):695–727, 2020. 10
2020
-
[13]
An eeg- based multi-modal emotion database with both posed and authentic facial actions for emotion analysis
Xiaotian Li, Xiang Zhang, Huiyuan Yang, Wenna Duan, Weiying Dai, and Lijun Yin. An eeg- based multi-modal emotion database with both posed and authentic facial actions for emotion analysis. In2020 15th IEEE international conference on automatic face and gesture recognition (FG 2020), pages 336–343. IEEE, 2020
2020
-
[14]
NeuroRVQ: Multi-Scale Biosignal Tokenization for Generative Foundation Models
Konstantinos Barmpas, Na Lee, Alexandros Koliousis, Yannis Panagakis, Dimitrios A Adamos, Nikolaos Laskaris, and Stefanos Zafeiriou. Neurorvq: Multi-scale eeg tokenization for genera- tive large brainwave models.arXiv preprint arXiv:2510.13068, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Wei-Bang Jiang, Yansen Wang, Bao-Liang Lu, and Dongsheng Li. Neurolm: A universal multi-task foundation model for bridging the gap between language and eeg signals.arXiv preprint arXiv:2409.00101, 2024
-
[16]
arXiv preprint arXiv:2405.18765 , year=
Wei-Bang Jiang, Li-Ming Zhao, and Bao-Liang Lu. Large brain model for learning generic representations with tremendous eeg data in bci.arXiv preprint arXiv:2405.18765, 2024
-
[17]
Decoding natural images from eeg for object recognition.arXiv preprint arXiv:2308.13234, 2023
Yonghao Song, Bingchuan Liu, Xiang Li, Nanlin Shi, Yijun Wang, and Xiaorong Gao. Decoding natural images from eeg for object recognition.arXiv preprint arXiv:2308.13234, 2023
-
[18]
Ling Wang, Chen Wu, and Lin Wang. Braindreamer: Reasoning-coherent and controllable image generation from eeg brain signals via language guidance.arXiv preprint arXiv:2409.14021, 2024
-
[19]
Eeg-clip: Learning eeg representations from natural language descriptions.Frontiers in Robotics and AI, 12:1625731, 2025
Tidiane Camaret Ndir, Robin Tibor Schirrmeister, and Tonio Ball. Eeg-clip: Learning eeg representations from natural language descriptions.Frontiers in Robotics and AI, 12:1625731, 2025
2025
-
[20]
Brainvis: Exploring the bridge between brain and visual signals via image reconstruction
Honghao Fu, Hao Wang, Jing Jih Chin, and Zhiqi Shen. Brainvis: Exploring the bridge between brain and visual signals via image reconstruction. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[21]
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Haoyang Qin, and Quanying Liu. Vi- sual decoding and reconstruction via eeg embeddings with guided diffusion.arXiv preprint arXiv:2403.07721, 2024
-
[22]
Brain2image: Converting brain signals into images
Isaak Kavasidis, Simone Palazzo, Concetto Spampinato, Daniela Giordano, and Mubarak Shah. Brain2image: Converting brain signals into images. InProceedings of the 25th ACM international conference on Multimedia, pages 1809–1817, 2017
2017
-
[23]
Controllable mind visual diffusion model
Bohan Zeng, Shanglin Li, Xuhui Liu, Sicheng Gao, Xiaolong Jiang, Xu Tang, Yao Hu, Jianzhuang Liu, and Baochang Zhang. Controllable mind visual diffusion model. InPro- ceedings of the AAAI conference on artificial intelligence, volume 38, pages 6935–6943, 2024
2024
-
[24]
Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding
Zijiao Chen, Jiaxin Qing, Tiange Xiang, Wan Lin Yue, and Juan Helen Zhou. Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22710–22720, 2023
2023
-
[25]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[26]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[27]
LongCat-Image Technical Report
Meituan LongCat Team, Hanghang Ma, Haoxian Tan, Jiale Huang, Junqiang Wu, Jun-Yan He, Lishuai Gao, Songlin Xiao, Xiaoming Wei, Xiaoqi Ma, et al. Longcat-image technical report. arXiv preprint arXiv:2512.07584, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Shijie Huang, Zhaohui Hou, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
First creating backgrounds then rendering texts: A new paradigm for visual text blending
Zhenhang Li, Yan Shu, Weichao Zeng, Dongbao Yang, and Yu Zhou. First creating backgrounds then rendering texts: A new paradigm for visual text blending. InECAI 2024, pages 346–353. IOS Press, 2024
2024
-
[30]
Brain-supervised image editing
Keith M Davis, Carlos De La Torre-Ortiz, and Tuukka Ruotsalo. Brain-supervised image editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18480–18489, 2022
2022
-
[31]
Mindpainter: Efficient brain- conditioned painting of natural images via cross-modal self-supervised learning
Muzhou Yu, Shuyun Lin, Hongwei Yan, and Kaisheng Ma. Mindpainter: Efficient brain- conditioned painting of natural images via cross-modal self-supervised learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14468–14476, 2025
2025
-
[32]
Mind artist: Creating artistic snapshots with human thought
Jiaxuan Chen, Yu Qi, Yueming Wang, and Gang Pan. Mind artist: Creating artistic snapshots with human thought. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27207–27217, 2024
2024
-
[33]
Mindcustomer: Multi-context image generation blended with brain signal
Muzhou Yu, Shuyun Lin, Lei Ma, Bo Lei, and Kaisheng Ma. Mindcustomer: Multi-context image generation blended with brain signal. InForty-second International Conference on Machine Learning, 2025
2025
-
[34]
Haolin Xiong, Tianwen Fu, Pratusha Bhuvana Prasad, Yunxuan Cai, Haiwei Chen, Wenbin Teng, Hanyuan Xiao, and Yajie Zhao. Mind-to-face: Neural-driven photorealistic avatar synthesis via eeg decoding.arXiv preprint arXiv:2512.04313, 2025
-
[35]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[36]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Gemini 3.1 Flash Image Preview (Nano Banana 2)
Google. Gemini 3.1 Flash Image Preview (Nano Banana 2). https://ai.google.dev/ gemini-api/docs/image-generation, 2026. Accessed: 2026-05-01
2026
-
[38]
How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks)
Adrian Bulat and Georgios Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). InProceedings of the IEEE international conference on computer vision, pages 1021–1030, 2017
2017
-
[39]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[40]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4690–4699, 2019
2019
-
[41]
Cheng Luo, Siyang Song, Weicheng Xie, Linlin Shen, and Hatice Gunes. Learning multi- dimensional edge feature-based au relation graph for facial action unit recognition.arXiv preprint arXiv:2205.01782, 2022
-
[42]
Bp4d-spontaneous: a high-resolution spontaneous 3d dynamic facial expression database.Image and Vision Computing, 32(10):692–706, 2014
Xing Zhang, Lijun Yin, Jeffrey F Cohn, Shaun Canavan, Michael Reale, Andy Horowitz, Peng Liu, and Jeffrey M Girard. Bp4d-spontaneous: a high-resolution spontaneous 3d dynamic facial expression database.Image and Vision Computing, 32(10):692–706, 2014
2014
-
[43]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021
2021
-
[44]
FireRed-Image-Edit-1.0 technical report.arXiv preprint arXiv:2602.13344, 2026
Super Intelligence Team, Changhao Qiao, Chao Hui, Chen Li, Cunzheng Wang, Dejia Song, Jiale Zhang, Jing Li, Qiang Xiang, Runqi Wang, et al. Firered-image-edit-1.0 technical report. arXiv preprint arXiv:2602.13344, 2026. 12 A Landmark-Guided Progressive Masking Strategy A.1 Reference-Image Masking In Stage 3, masking is applied only to the reference image,...
-
[45]
a face showing facial action unit
To mitigate memory bottlenecks, we pre-extract and cache visual features for both reference and ground-truth images using the frozen Qwen2.5-VL vision encoder [36]. This strategy bypasses the need to load the heavy vision backbone during alignment, significantly accelerating training. Stage 3.We initialize the model using pre-trained parameters from LongC...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.