Hybrid Retriever Evolution for Multimodal Document Reasoning Agents
Pith reviewed 2026-06-30 06:56 UTC · model grok-4.3
The pith
A meta-agent evolves task-agent instructions so retrieval becomes an adaptive step-wise decision rather than a fixed pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
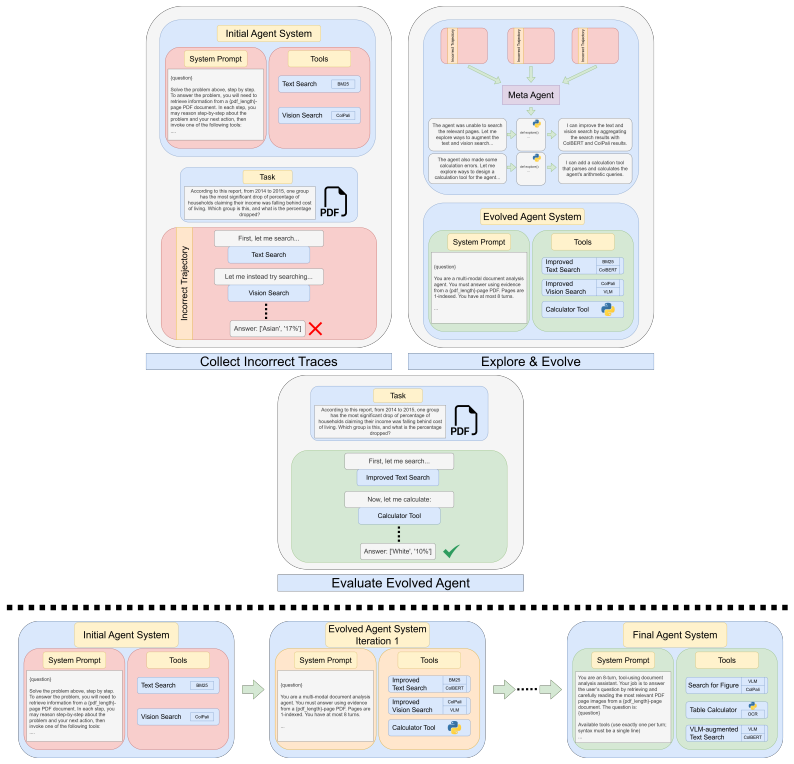
The failure-driven evolution framework lets a meta-agent autonomously diagnose root causes of incorrect trajectories by probing the tool environment and iteratively rewrite the task agent's instructions, converting retrieval from a static front-end stage into an adaptive reasoning decision. The resulting agent learns when to invoke each retriever, how to combine them, and how to compose evidence across modalities and pages.
What carries the argument
The failure-driven evolution framework, where a meta-agent examines failures, probes tools, and rewrites instructions to produce adaptive retriever routing.
If this is right
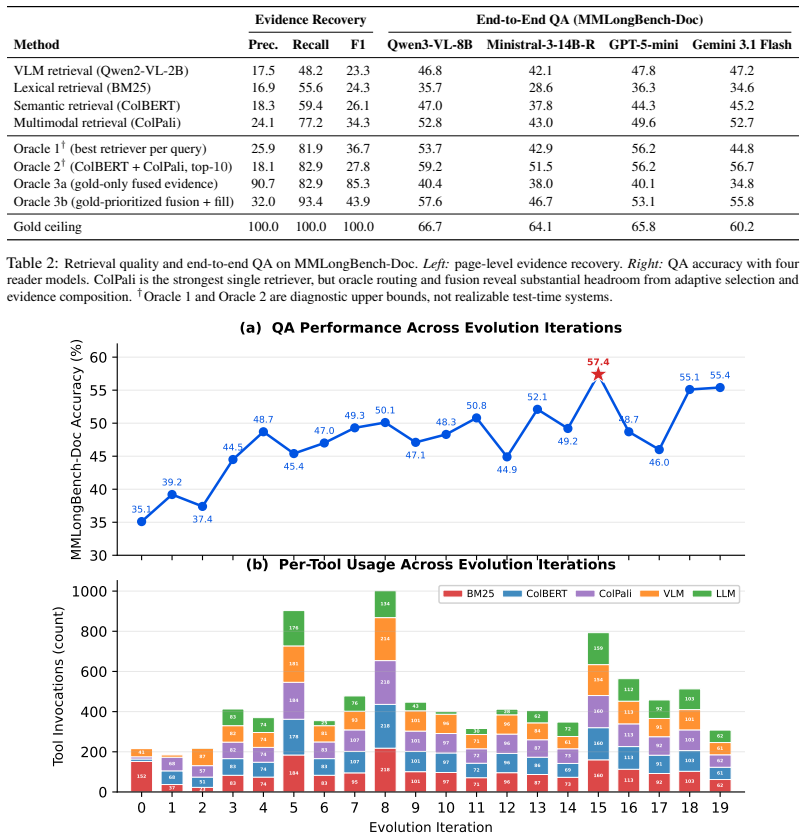
- The evolved agent records gains of up to 19.6 points on MMLongBench-Doc and DocBench over the unevolved baseline.
- It outperforms recent systems including MACT, MDocAgent, and SimpleDoc on the same benchmarks.
- Performance improvements trace to adaptive routing and evidence composition rather than reliance on any fixed retrieval mode.
- Retrieval behavior shifts over evolution from narrow lexical use toward coordinated multi-tool patterns.
Where Pith is reading between the lines
- The same failure-driven rewrite process could be tested on agents that use other kinds of tools beyond document retrievers.
- Running the evolved agent on document collections outside the two reported benchmarks would test whether the learned coordination transfers.
- If the approach scales, it could reduce reliance on hand-crafted prompts for deciding tool order in multi-step agents.
Load-bearing premise
The meta-agent can diagnose root causes of failures by probing the tool environment and produce instruction rewrites that generalize to new queries.
What would settle it
Apply the evolved instructions to a fresh set of multimodal document questions and check whether performance gains vanish or retrieval logs show no increase in step-wise multi-tool coordination.
Figures
read the original abstract
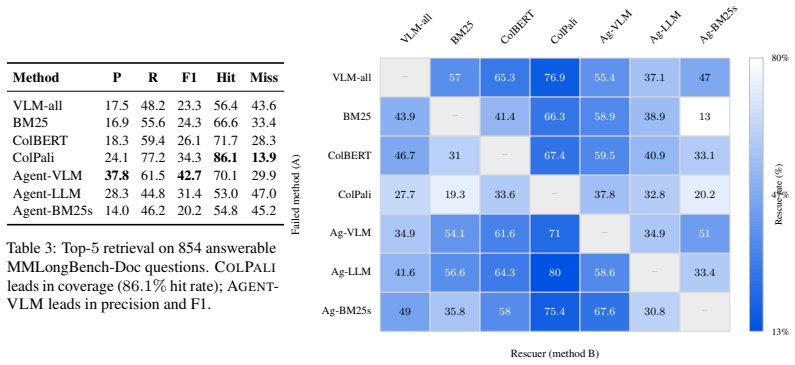
Different retrievers, including lexical, semantic, and multimodal approaches, provide highly complementary strengths for multimodal document understanding, yet most systems combine them through fixed pipelines that cannot adapt to the demands of individual reasoning steps. In this work, we ask whether retrieval orchestration itself can be learned as part of the reasoning process. We introduce a failure-driven evolution framework in which a meta-agent autonomously discovers how a tool-using task agent should coordinate diverse retrievers during multi-step document question answering. The meta-agent analyzes incorrect reasoning trajectories, actively probes the same tool environment to diagnose root causes, and iteratively rewrites the task agent's instructions, turning retrieval from a fixed front-end stage into an adaptive, step-wise reasoning decision. The evolved agent learns when to invoke each retriever, how to combine them, and how to compose evidence across modalities and pages. On MMLongBench-Doc and DocBench, the evolved agent achieves gains of up to +19.6 points over the unevolved baseline and consistently outperforms recent systems including MACT, MDocAgent, and SimpleDoc. Detailed retrieval analyses confirm that these improvements arise from adaptive routing and evidence composition rather than reliance on any hard coded retrieval mode, and evolution dynamics reveal a progressive shift from narrow lexical behavior to rich multi-tool coordination. These findings establish autonomous multi-agent coordination as a promising paradigm for multimodal document reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a failure-driven evolution framework in which a meta-agent analyzes incorrect reasoning trajectories of a tool-using task agent, probes the tool environment to diagnose root causes, and iteratively rewrites the task agent's instructions to enable adaptive, step-wise coordination of hybrid retrievers (lexical, semantic, multimodal) for multimodal document QA. On MMLongBench-Doc and DocBench the evolved agent reports gains of up to +19.6 points over the unevolved baseline and outperforms systems such as MACT, MDocAgent, and SimpleDoc; retrieval analyses are said to attribute gains to learned adaptive routing and evidence composition rather than fixed modes.
Significance. If the meta-agent's diagnoses and rewrites produce retrieval policies that generalize beyond the trajectories used for evolution, the work would demonstrate a concrete advance in autonomous multi-agent coordination for retrieval orchestration, moving beyond static pipelines in multimodal document reasoning.
major comments (2)
- [Abstract, §3] Abstract and §3 (evolution framework): the central claim that improvements arise from 'adaptive routing and evidence composition' rather than case-specific tuning rests on the unshown assumption that meta-agent diagnoses and instruction rewrites generalize to new queries. No information is supplied on the query split between evolution/probing and final evaluation, the number of distinct trajectories used, or any held-out validation set, making it impossible to rule out that measured gains reflect optimization on (or leakage from) the reported test distribution.
- [§4] §4 (experiments and analyses): the attribution of gains to 'progressive shift from narrow lexical behavior to rich multi-tool coordination' requires explicit controls (e.g., ablation of the meta-agent, comparison against random or oracle rewrites, or cross-benchmark transfer) that are not described; without them the +19.6 point figure cannot be confidently linked to the claimed mechanism.
minor comments (2)
- [§3] Notation for the meta-agent and task agent should be introduced with explicit pseudocode or a diagram early in §3 to clarify the iterative loop.
- [§4] Table or figure captions for retrieval analyses should state the exact metric (e.g., retriever invocation frequency per step) and the number of queries sampled.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. The comments highlight important aspects of experimental transparency and attribution that we address below. We indicate where revisions to the manuscript will be made.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (evolution framework): the central claim that improvements arise from 'adaptive routing and evidence composition' rather than case-specific tuning rests on the unshown assumption that meta-agent diagnoses and instruction rewrites generalize to new queries. No information is supplied on the query split between evolution/probing and final evaluation, the number of distinct trajectories used, or any held-out validation set, making it impossible to rule out that measured gains reflect optimization on (or leakage from) the reported test distribution.
Authors: We agree that explicit details on the data splits are necessary to support the generalization claim. The evolution process used trajectories sampled from development portions of each benchmark (distinct from the official test splits on which results are reported), with approximately 180-250 trajectories per benchmark and an internal 20% validation subset to track policy improvement. We will revise §3 to document these quantities, the split procedure, and confirmation of no test-query overlap. This addition will directly address the concern and strengthen the evidence that the learned routing policies are not limited to the evolution trajectories. revision: yes
-
Referee: [§4] §4 (experiments and analyses): the attribution of gains to 'progressive shift from narrow lexical behavior to rich multi-tool coordination' requires explicit controls (e.g., ablation of the meta-agent, comparison against random or oracle rewrites, or cross-benchmark transfer) that are not described; without them the +19.6 point figure cannot be confidently linked to the claimed mechanism.
Authors: The manuscript's §4 retrieval analyses already quantify the shift in tool-usage distributions and evidence composition across evolution iterations, and the gains are consistent across two independent benchmarks. We will revise §4 to more explicitly connect these metrics to the claimed mechanism and to note the unevolved baseline as a control for the underlying task agent. However, we did not conduct meta-agent ablations, random/oracle rewrite comparisons, or additional cross-benchmark transfer experiments; these would require new runs and are not described because they were outside the original scope. We therefore partially agree that further controls would be beneficial but maintain that the existing analyses and cross-benchmark results provide substantive support for the attribution. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical failure-driven evolution process in which a meta-agent rewrites task-agent instructions after probing trajectories, then reports benchmark gains on MMLongBench-Doc and DocBench. No equations, self-citations, or fitted parameters are presented that reduce the central claim (adaptive multi-retriever coordination) to its own inputs by construction. The abstract and description treat the evolution as an autonomous discovery step whose outputs are evaluated on the stated benchmarks, with no load-bearing reduction of the form 'prediction equals fit' or 'result equals self-citation chain'. The derivation chain from method description to reported improvements is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
meta-agent
no independent evidence
-
evolved agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2407.01523 , year =
MMLongBench-Doc: Benchmarking Long-Context Document Understanding with Visualizations , author =. arXiv preprint arXiv:2407.01523 , year =
-
[2]
arXiv preprint arXiv:2407.10701 , year =
DocBench: A Benchmark for Evaluating LLM-Based Document Reading Systems , author =. arXiv preprint arXiv:2407.10701 , year =
-
[3]
arXiv preprint arXiv:2503.13964 , year =
MDocAgent: A Multi-Modal Multi-Agent Framework for Document Understanding , author =. arXiv preprint arXiv:2503.13964 , year =
-
[4]
arXiv preprint arXiv:2506.14035 , year =
SimpleDoc: Multi-Modal Document Understanding with Dual-Cue Page Retrieval and Iterative Refinement , author =. arXiv preprint arXiv:2506.14035 , year =
-
[5]
arXiv preprint arXiv:2508.03404 , year =
Visual Document Understanding and Question Answering: A Multi-Agent Collaboration Framework with Test-Time Scaling , author =. arXiv preprint arXiv:2508.03404 , year =
-
[6]
Foundations and Trends in Information Retrieval , volume =
The Probabilistic Relevance Framework: BM25 and Beyond , author =. Foundations and Trends in Information Retrieval , volume =
-
[7]
Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , year =
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT , author =. Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval , year =
-
[8]
Proceedings of the Conference on Empirical Methods in Natural Language Processing , year =
ColPali: Efficient Document Retrieval with Vision Language Models , author =. Proceedings of the Conference on Empirical Methods in Natural Language Processing , year =
-
[9]
Advances in Neural Information Processing Systems , volume =
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author =. Advances in Neural Information Processing Systems , volume =
-
[10]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages =
DocVQA: A Dataset for VQA on Document Images , author =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages =
-
[11]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages =
InfographicVQA , author =. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages =
-
[12]
Findings of the Association for Computational Linguistics: ACL 2022 , pages =
ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning , author =. Findings of the Association for Computational Linguistics: ACL 2022 , pages =
2022
-
[13]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author =. arXiv preprint arXiv:2308.08155 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors , author =. arXiv preprint arXiv:2308.10848 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines , author =. arXiv preprint arXiv:2310.03714 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Large Language Models as Optimizers
Large Language Models as Optimizers , author =. arXiv preprint arXiv:2309.03409 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.