Towards Resolving Optimization Conflicts Between Image- and Text-Based Person Re-Identification
Pith reviewed 2026-06-28 15:33 UTC · model grok-4.3
The pith
A decoupled two-stage pipeline with one vision encoder trains image-based and text-based person re-identification without cross-task interference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
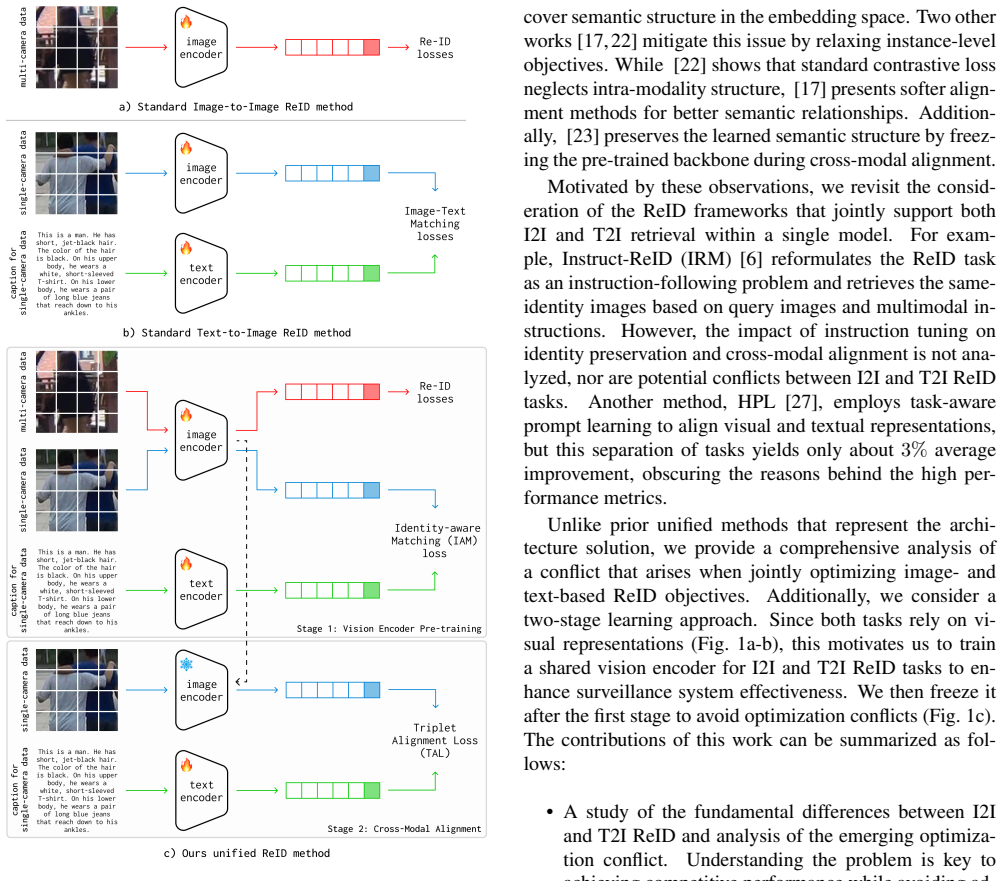
The central claim is that modality discrepancies and conflicting objectives hinder joint I2I-T2I training, and that a decoupled two-stage pipeline built on a single vision encoder supports both retrieval settings while avoiding interference; I2I pre-training aids T2I generalization and textual supervision during encoder training improves results on both.
What carries the argument
The decoupled two-stage training pipeline based on a single vision encoder that separates I2I pre-training from later text supervision.
If this is right
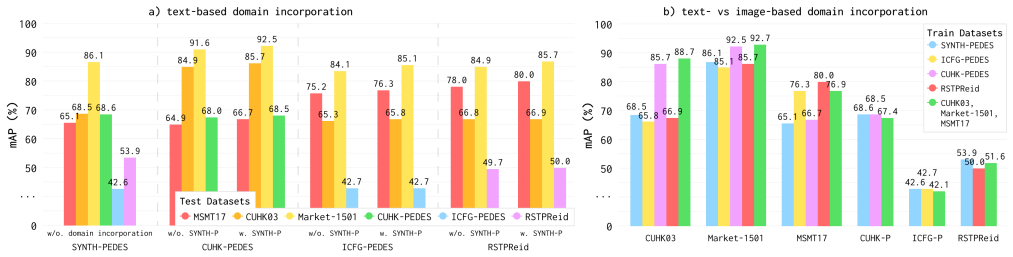
- I2I ReID pre-training improves generalization to T2I retrieval data.
- Adding textual supervision while training the vision encoder raises accuracy for both I2I and T2I tasks.
- The two-stage pipeline prevents the negative transfer that occurs when I2I and T2I losses are optimized together.
- Varying domain mixing, learning strategies, and task objectives confirms the pipeline works across multiple configurations.
Where Pith is reading between the lines
- The same staged separation could be tested on other cross-modal retrieval problems where identity-level and instance-level objectives compete.
- If the pattern holds, unified ReID systems might routinely adopt pre-training on the easier modality before introducing the harder one.
- The findings imply that future encoder designs should expose separate optimization phases rather than relying on a single joint loss.
Load-bearing premise
Modality discrepancies and conflicting objectives are the primary causes of suboptimal shared representations, and separating the training stages resolves them without losing benefits that simultaneous optimization might provide.
What would settle it
A controlled experiment in which simultaneous joint optimization of I2I and T2I objectives on the same encoder yields equal or higher accuracy on both retrieval tasks than the proposed two-stage pipeline.
Figures
read the original abstract
The joint optimization of image-based (I2I) and text-based (T2I) person re-identification (ReID) is hindered by modality discrepancies and conflicting training objectives, leading to suboptimal shared representations. While I2I ReID focuses on identity-level invariance across images of the same person, T2I ReID is driven by instance-specific textual descriptions tied to unique visual traits. This paper explores the fundamental difference between two ReID tasks and their optimization processes for effective training. Since I2I and T2I ReID are often studied separately, the loss functions optimized for one retrieval setting may negatively affect the representation quality required by the other. Motivated by these findings, we propose a decoupled two-stage training pipeline for learning a shared representation across image and text modalities. The pipeline is based on a single vision encoder that supports both I2I and T2I retrieval while avoiding cross-task interference during training. We provide extensive experiments across multiple configurations, varying domain mixing procedures, learning strategies, and task objectives. We observed that I2I ReID pre-training positively impacts the generalization ability to T2I data. Besides, we find that incorporating textual supervision during the vision encoder training stage enhances both I2I and T2I performance. We believe our insights provide a meaningful step toward unified ReID systems and cross-modal retrieval overall.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that joint optimization of image-based (I2I) and text-based (T2I) person re-identification is hindered by modality discrepancies and conflicting training objectives, leading to suboptimal shared representations. It proposes a decoupled two-stage training pipeline using a single vision encoder to support both I2I and T2I retrieval while avoiding cross-task interference. Experiments across multiple configurations (varying domain mixing, learning strategies, and task objectives) show that I2I ReID pre-training improves generalization to T2I data and that textual supervision during vision encoder training enhances performance on both tasks.
Significance. If the central claims hold after addressing the experimental gaps, the work would provide useful empirical insights into training unified ReID systems by separating optimization stages, with the specific observations on I2I pre-training benefits and textual supervision effects offering practical guidance for cross-modal retrieval. The paper receives credit for exploring the fundamental differences between the two ReID tasks and for conducting experiments that vary multiple training factors.
major comments (2)
- [Experiments (as described)] The central claim that the decoupled two-stage pipeline resolves optimization conflicts by avoiding cross-task interference requires a direct comparator, but no joint-optimization baseline using the identical single vision encoder and the same I2I + T2I loss combination is reported. Without this controlled run, gains from I2I pre-training or textual supervision cannot be confidently attributed to removal of interference rather than staged optimization dynamics, data ordering, or hyper-parameter effects.
- [Abstract] The abstract states experimental observations and performance improvements but provides no details on datasets, metrics, baselines, error bars, or exclusion criteria. This omission prevents assessment of whether the data supports the claims as stated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Experiments (as described)] The central claim that the decoupled two-stage pipeline resolves optimization conflicts by avoiding cross-task interference requires a direct comparator, but no joint-optimization baseline using the identical single vision encoder and the same I2I + T2I loss combination is reported. Without this controlled run, gains from I2I pre-training or textual supervision cannot be confidently attributed to removal of interference rather than staged optimization dynamics, data ordering, or hyper-parameter effects.
Authors: We agree that a direct joint-optimization baseline with the identical single vision encoder and the combined I2I + T2I loss would provide a stronger control experiment. Our reported results vary domain mixing, learning strategies, and task objectives, but do not include this exact joint-training comparator. We will add the requested baseline in the revision to better isolate the effect of decoupling. revision: yes
-
Referee: [Abstract] The abstract states experimental observations and performance improvements but provides no details on datasets, metrics, baselines, error bars, or exclusion criteria. This omission prevents assessment of whether the data supports the claims as stated.
Authors: We will revise the abstract to include the primary datasets, metrics, key baselines, and a brief note on error bars or statistical reporting while preserving conciseness. revision: yes
Circularity Check
No circularity; purely empirical claims without derivations or self-referential reductions
full rationale
The paper contains no equations, loss derivations, fitted parameters presented as predictions, or uniqueness theorems. All central claims (decoupled two-stage pipeline benefits, I2I pre-training impact, textual supervision gains) rest on experimental observations across configurations. No self-citation chains or ansatzes are invoked to justify the method; the pipeline is introduced as a proposal and evaluated directly. The absence of a joint-optimization baseline is a methodological gap but does not constitute circularity, as no derivation reduces to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yang Bai, Min Cao, Daming Gao, Ziqiang Cao, Chen Chen, Zhenfeng Fan, Liqiang Nie, and Min Zhang. Rasa: Relation and sensitivity aware representation learning for text-based person search.arXiv preprint arXiv:2305.13653, 2023
-
[2]
Semantically self-aligned network for text-to-image part-aware person re-identification
Zefeng Ding, Changxing Ding, Zhiyin Shao, and Dacheng Tao. Semantically self-aligned network for text-to-image part-aware person re-identification. arxiv 2021.arXiv preprint arXiv:2107.12666, 2021
-
[3]
Mars: Paying more attention to visual attributes for text-based person search.ACM Transac- tions on Multimedia Computing, Communications and Ap- plications, 21(10):1–22, 2025
Alex Ergasti, Tomaso Fontanini, Claudio Ferrari, Massimo Bertozzi, and Andrea Prati. Mars: Paying more attention to visual attributes for text-based person search.ACM Transac- tions on Multimedia Computing, Communications and Ap- plications, 21(10):1–22, 2025
2025
-
[4]
Large-scale pre-training for person re-identification with noisy labels
Dengpan Fu, Dongdong Chen, Hao Yang, Jianmin Bao, Lu Yuan, Lei Zhang, Houqiang Li, Fang Wen, and Dong Chen. Large-scale pre-training for person re-identification with noisy labels. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 2476–2486, 2022
2022
-
[5]
Transreid: Transformer-based object re- identification
Shuting He, Hao Luo, Pichao Wang, Fan Wang, Hao Li, and Wei Jiang. Transreid: Transformer-based object re- identification. InProceedings of the IEEE/CVF international conference on computer vision, pages 15013–15022, 2021
2021
-
[6]
Instruct-reid: A multi-purpose person re-identification task with instructions
Weizhen He, Yiheng Deng, Shixiang Tang, Qihao Chen, Qingsong Xie, Yizhou Wang, Lei Bai, Feng Zhu, Rui Zhao, Wanli Ouyang, et al. Instruct-reid: A multi-purpose person re-identification task with instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17521–17531, 2024
2024
-
[7]
Cross-modal implicit relation rea- soning and aligning for text-to-image person retrieval
Ding Jiang and Mang Ye. Cross-modal implicit relation rea- soning and aligning for text-to-image person retrieval. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 2787–2797, 2023
2023
-
[8]
Clip-reid: exploiting vision-language model for image re-identification without concrete text labels
Siyuan Li, Li Sun, and Qingli Li. Clip-reid: exploiting vision-language model for image re-identification without concrete text labels. InProceedings of the AAAI confer- ence on artificial intelligence, volume 37, pages 1405–1413, 2023
2023
-
[9]
Person search with natural lan- guage description
Shuang Li, Tong Xiao, Hongsheng Li, Bolei Zhou, Dayu Yue, and Xiaogang Wang. Person search with natural lan- guage description. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1970–1979, 2017
1970
-
[10]
Deep- reid: Deep filter pairing neural network for person re- identification
Wei Li, Rui Zhao, Tong Xiao, and Xiaogang Wang. Deep- reid: Deep filter pairing neural network for person re- identification. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 152–159, 2014
2014
-
[11]
Dynamix: Generalizable person re-identification via dy- namic relabeling and mixed data sampling.Neurocomputing, page 132446, 2025
Timur Mamedov, Anton Konushin, and Vadim Konushin. Dynamix: Generalizable person re-identification via dy- namic relabeling and mixed data sampling.Neurocomputing, page 132446, 2025
2025
-
[12]
Remix: Training generalized person re-identification on a mixture of data
Timur Mamedov, Anton Konushin, and Vadim Konushin. Remix: Training generalized person re-identification on a mixture of data. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 8186–8196. IEEE Computer Society, 2025
2025
-
[13]
Retext: Text boosts generalization in image-based person re-identification.arXiv:2602.05785, 2026
Timur Mamedov, Karina Kvanchiani, Anton Konushin, and Vadim Konushin. Retext: Text boosts generalization in image-based person re-identification.arXiv:2602.05785, 2026
-
[14]
A culturally-aware benchmark for person re-identification in modest attire.Engineering Ap- plications of Artificial Intelligence, 158:111494, 2025
Alireza Sedighi Moghaddam, Fatemeh Anvari, Mohammad- javad Mirshekari Haghighi, Mohammadali Fakhari, and Mo- hammad Reza Mohammadi. A culturally-aware benchmark for person re-identification in modest attire.Engineering Ap- plications of Artificial Intelligence, 158:111494, 2025
2025
-
[15]
Noisy-correspondence learning for text-to-image person re-identification
Yang Qin, Yingke Chen, Dezhong Peng, Xi Peng, Joey Tianyi Zhou, and Peng Hu. Noisy-correspondence learning for text-to-image person re-identification. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27197–27206, 2024
2024
-
[16]
Learnable pillar-based re- ranking for image-text retrieval
Leigang Qu, Meng Liu, Wenjie Wang, Zhedong Zheng, Liqiang Nie, and Tat-Seng Chua. Learnable pillar-based re- ranking for image-text retrieval. InProceedings of the 46th international ACM SIGIR conference on research and devel- opment in information retrieval, pages 1252–1261, 2023
2023
-
[17]
Soft contrastive cross-modal re- trieval.Applied Sciences, 14(5):1944, 2024
Jiayu Song, Yuxuan Hu, Lei Zhu, Chengyuan Zhang, Jian Zhang, and Shichao Zhang. Soft contrastive cross-modal re- trieval.Applied Sciences, 14(5):1944, 2024
1944
-
[18]
Panda: A gigapixel- level human-centric video dataset
Xueyang Wang, Xiya Zhang, Yinheng Zhu, Yuchen Guo, Xiaoyun Yuan, Liuyu Xiang, Zerun Wang, Guiguang Ding, David Brady, Qionghai Dai, et al. Panda: A gigapixel- level human-centric video dataset. InProceedings of 7 the IEEE/CVF conference on computer vision and pattern recognition, pages 3268–3278, 2020
2020
-
[19]
Person transfer gan to bridge domain gap for person re- identification
Longhui Wei, Shiliang Zhang, Wen Gao, and Qi Tian. Person transfer gan to bridge domain gap for person re- identification. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 79–88, 2018
2018
-
[20]
Joint detection and identification feature learn- ing for person search
Tong Xiao, Shuang Li, Bochao Wang, Liang Lin, and Xiao- gang Wang. Joint detection and identification feature learn- ing for person search. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3415– 3424, 2017
2017
-
[21]
Entire-id: An exten- sive and diverse dataset for person re-identification
Serdar Yıldız and Ahmet Nezih Kasım. Entire-id: An exten- sive and diverse dataset for person re-identification. In2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG), pages 1–5. IEEE, 2024
2024
-
[22]
Image–text cross-modal retrieval with instance con- trastive embedding.Electronics, 13(2):300, 2024
Ruigeng Zeng, Wentao Ma, Xiaoqian Wu, Wei Liu, and Jie Liu. Image–text cross-modal retrieval with instance con- trastive embedding.Electronics, 13(2):300, 2024
2024
-
[23]
An efficient cross-modal privacy-preserving image–text re- trieval scheme.Symmetry, 16(8):1084, 2024
Kejun Zhang, Shaofei Xu, Yutuo Song, Yuwei Xu, Pengcheng Li, Xiang Yang, Bing Zou, and Wenbin Wang. An efficient cross-modal privacy-preserving image–text re- trieval scheme.Symmetry, 16(8):1084, 2024
2024
-
[24]
An open-world, diverse, cross-spatial-temporal bench- mark for dynamic wild person re-identification.Interna- tional Journal of Computer Vision, 132(9):3823–3846, 2024
Lei Zhang, Xiaowei Fu, Fuxiang Huang, Yi Yang, and Xinbo Gao. An open-world, diverse, cross-spatial-temporal bench- mark for dynamic wild person re-identification.Interna- tional Journal of Computer Vision, 132(9):3823–3846, 2024
2024
-
[25]
Image-text retrieval via contrastive learning with auxiliary generative features and support-set regularization
Lei Zhang, Min Yang, Chengming Li, and Ruifeng Xu. Image-text retrieval via contrastive learning with auxiliary generative features and support-set regularization. InPro- ceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1938–1943, 2022
1938
-
[26]
Scalable person re-identification: A benchmark
Liang Zheng, Liyue Shen, Lu Tian, Shengjin Wang, Jing- dong Wang, and Qi Tian. Scalable person re-identification: A benchmark. InProceedings of the IEEE international con- ference on computer vision, pages 1116–1124, 2015
2015
-
[27]
Linhan Zhou, Shuang Li, Neng Dong, Yonghang Tai, Yafei Zhang, and Huafeng Li. Hierarchical prompt learning for image-and text-based person re-identification.arXiv preprint arXiv:2511.13575, 2025
-
[28]
Dssl: Deep surroundings-person separation learning for text-based per- son retrieval
Aichun Zhu, Zijie Wang, Yifeng Li, Xili Wan, Jing Jin, Tian Wang, Fangqiang Hu, and Gang Hua. Dssl: Deep surroundings-person separation learning for text-based per- son retrieval. InProceedings of the 29th ACM international conference on multimedia, pages 209–217, 2021
2021
-
[29]
Pass: Part-aware self-supervised pre- training for person re-identification
Kuan Zhu, Haiyun Guo, Tianyi Yan, Yousong Zhu, Jinqiao Wang, and Ming Tang. Pass: Part-aware self-supervised pre- training for person re-identification. InEuropean conference on computer vision, pages 198–214. Springer, 2022
2022
-
[30]
Plip: Language-image pre-training for person rep- resentation learning.Advances in Neural Information Pro- cessing Systems, 37:45666–45702, 2024
Jialong Zuo, Jiahao Hong, Feng Zhang, Changqian Yu, Hanyu Zhou, Changxin Gao, Nong Sang, and Jingdong Wang. Plip: Language-image pre-training for person rep- resentation learning.Advances in Neural Information Pro- cessing Systems, 37:45666–45702, 2024
2024
-
[31]
Ufinebench: Towards text-based person retrieval with ultra- fine granularity
Jialong Zuo, Hanyu Zhou, Ying Nie, Feng Zhang, Tianyu Guo, Nong Sang, Yunhe Wang, and Changxin Gao. Ufinebench: Towards text-based person retrieval with ultra- fine granularity. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 22010–22019, 2024. 8
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.