3D-PLOT-LLM: Part-Level Object Tokens for 3D Large Language Models
Pith reviewed 2026-06-26 18:23 UTC · model grok-4.3
The pith
Reorganizing 3D point patches with reserved part tokens lets language models directly address and reason about object components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
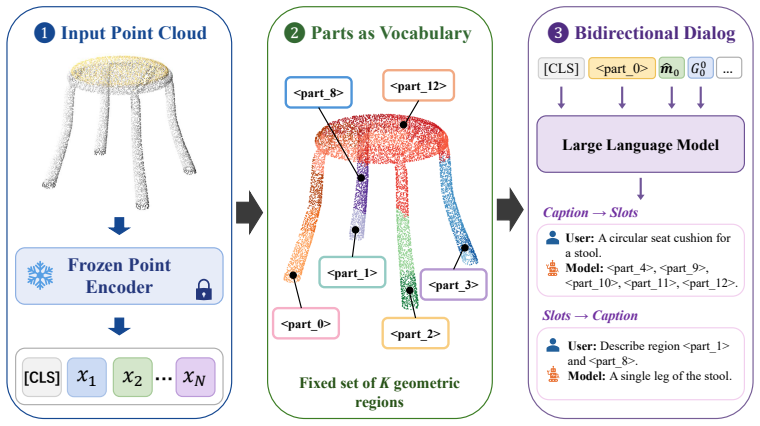
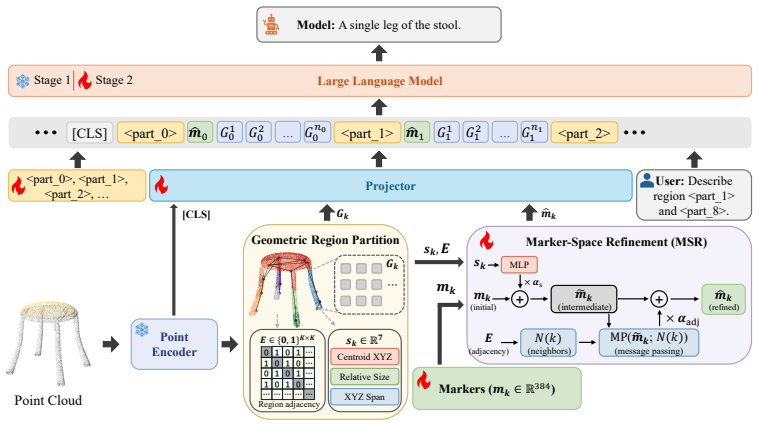
By partitioning the frozen point encoder's patches into K locally coherent regions and inserting, before each region's patch tokens, a learnable per-region marker and a reserved vocabulary token <part_k>, followed by Marker-Space Refinement that conditions each marker on its region's spatial statistics and adjacency neighbors, the model acquires the ability to cite parts in its output and follow prompts that refer to parts by token.
What carries the argument
The part-token insertion scheme that prepends reserved vocabulary tokens <part_k> and learnable markers to each region's patch tokens, refined by the Marker-Space Refinement module.
Load-bearing premise
That partitioning the frozen point encoder's patches into K locally coherent regions and inserting learnable markers plus reserved <part_k> tokens before each region's patches is sufficient for the LLM to acquire part-addressing behavior without further architectural changes.
What would settle it
A test where the model is prompted with a specific <part_k> token on held-out objects and fails to correctly name or describe the corresponding part in its generated text.
Figures



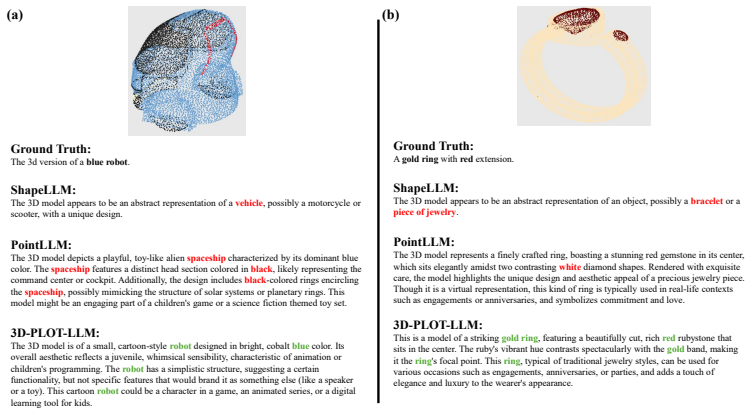

read the original abstract
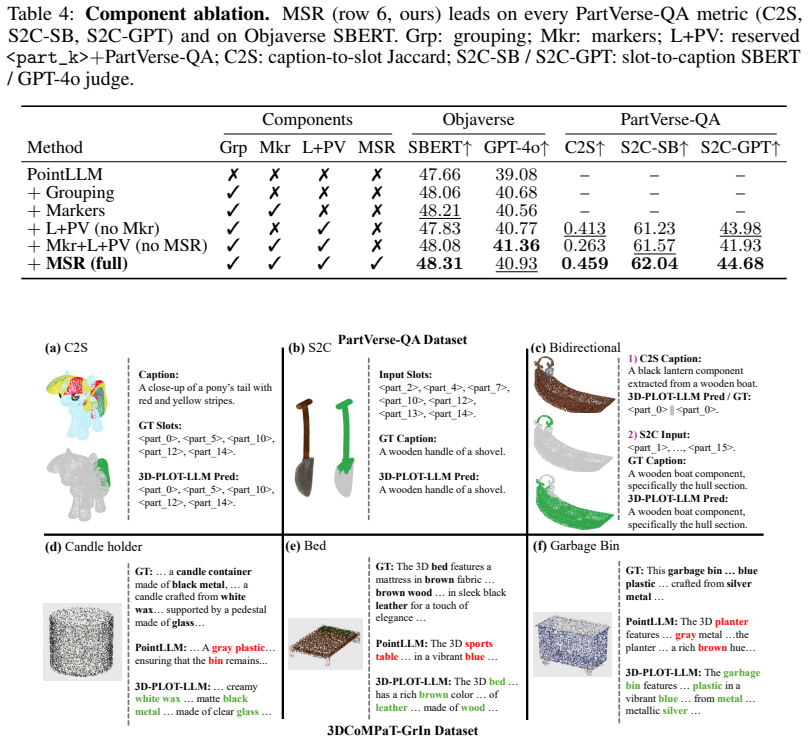
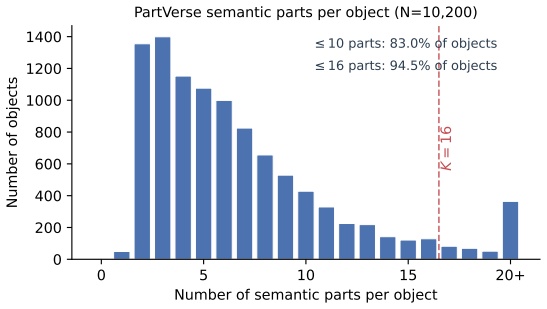
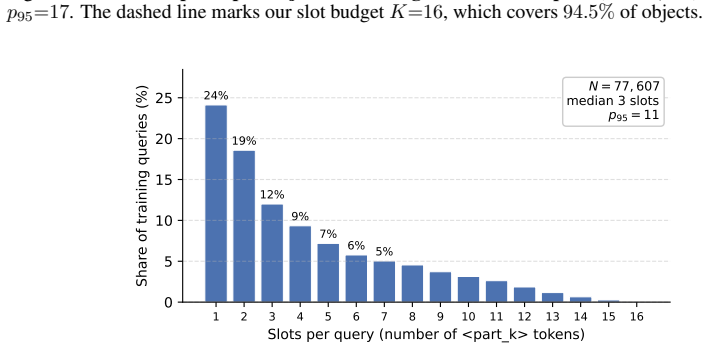
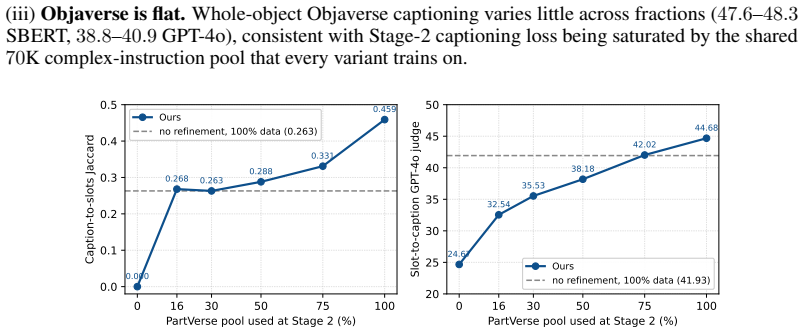
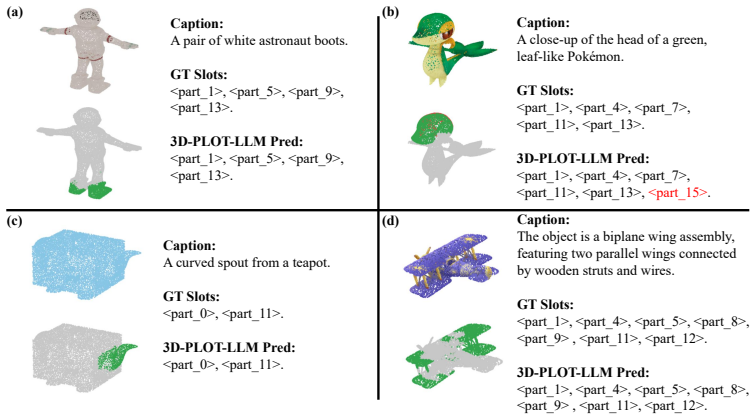
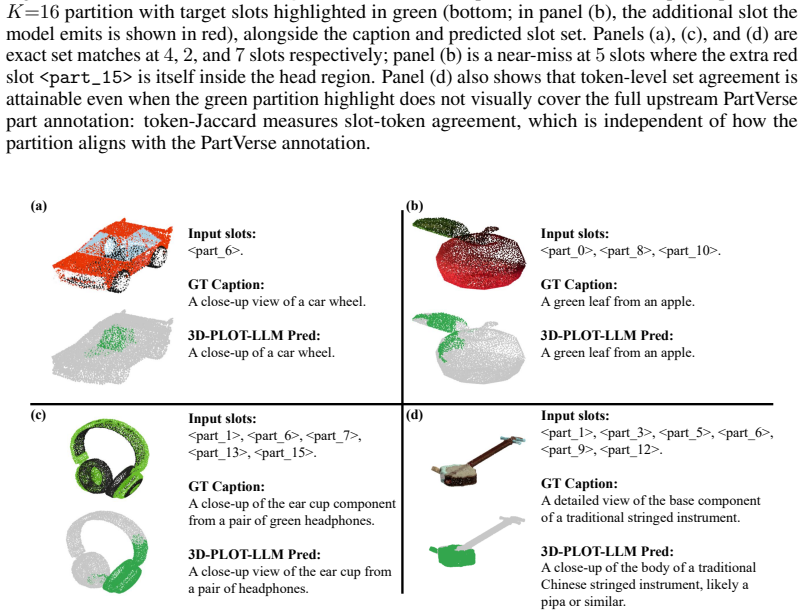
3D multimodal large language models (3D MLLMs) describe a 3D object as a whole but cannot address, name, or reason about its parts. Prior part-aware attempts add segmentation decoders, heavier 3D encoders, or bounding-box grammars at substantial parameter cost. We take a fundamentally different path: we reorganize the input token stream so that parts become directly addressable through the LLM's own vocabulary. Our model, 3D-PLOT-LLM, partitions the frozen point encoder's patches into K locally coherent regions and inserts, before each region's patch tokens, a learnable per-region marker and a reserved vocabulary token <part_k>; a Marker-Space Refinement (MSR) module then conditions each marker on its region's spatial statistics and adjacency neighbors. The model thus cites parts in its output and follows prompts that refer to parts by token, a capability absent from prior object-level 3D MLLMs. To probe this interface, we construct PartVerse-QA, a vocabulary-level part-QA benchmark adapted from PartVerse mesh annotations (77K training pairs and 588 held-out queries on disjoint object splits), on which 3D-PLOT-LLM reaches caption-to-slots Jaccard 0.459 and Exact-match 13.78%, with a slot-to-caption GPT-4o judge of 44.68. On the 3DCoMPaT-GrIn part-aware grounded description benchmark, 3D-PLOT-LLM outperforms PointLLM, Kestrel, PARIS3D, and SegPoint on every text-output metric, and ShapeLLM on 3 of 4, with up to +3.03 GPT-4o judge over PointLLM. On Objaverse whole-object captioning, adding PartVerse-QA at Stage 2 yields +0.65 SBERT and +1.85 GPT-4o over PointLLM, and tops PointLLM-PiSA on 4 of 5 traditional metrics (SBERT, SimCSE, BLEU-1, METEOR) despite targeting a different (part-grounded) objective. All with under 1M new trainable parameters on a frozen point encoder, an order of magnitude below prior part-aware 3D MLLMs, and no segmentation decoder or bounding-box head.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that 3D-PLOT-LLM enables part-level addressing in 3D MLLMs by partitioning frozen point-encoder patches into K spatially coherent regions, prepending learnable markers and reserved <part_k> tokens to each region, and applying a Marker-Space Refinement (MSR) module; this yields part-citing and part-prompt-following behavior with under 1M trainable parameters. On the new PartVerse-QA benchmark (77K train / 588 held-out pairs) it reports Jaccard 0.459, Exact-match 13.78%, and GPT-4o judge 44.68, plus gains on 3DCoMPaT-GrIn and Objaverse captioning relative to PointLLM, Kestrel, PARIS3D, SegPoint, and ShapeLLM.
Significance. If the part-addressing claim holds, the approach supplies a low-parameter route to part-level reasoning in 3D MLLMs that avoids segmentation decoders or bounding-box heads; the introduction of PartVerse-QA as a vocabulary-level part-QA benchmark is a useful addition for the community.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the claim that inserting <part_k> tokens before spatially clustered patches plus MSR is sufficient for the (presumably frozen) LLM to acquire true part-addressing behavior is load-bearing, yet the regions are defined by local coherence rather than the mesh part annotations used to generate the QA pairs; the modest Exact-match of 13.78% is consistent with the tokens acting as generic labels rather than semantic part pointers, and no analysis of token usage or alignment between clusters and ground-truth parts is provided.
- [§4] §4 (experiments): no error bars, no ablation on K or the MSR module, and no description of how the 77K/588 PartVerse-QA split was constructed or how queries were generated from mesh annotations; these omissions make it impossible to assess whether the reported Jaccard 0.459 and GPT-4o 44.68 scores demonstrate part-specific binding or merely marginal gains from the added tokens.
minor comments (2)
- [§3] Clarify in the method section whether the LLM backbone itself is frozen (as implied by the <1M parameter budget) or partially updated.
- [§4] Table or figure showing per-metric comparisons on 3DCoMPaT-GrIn should be referenced explicitly in the text rather than summarized only in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our part-addressing claims and experimental details. We address each major comment below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the claim that inserting <part_k> tokens before spatially clustered patches plus MSR is sufficient for the (presumably frozen) LLM to acquire true part-addressing behavior is load-bearing, yet the regions are defined by local coherence rather than the mesh part annotations used to generate the QA pairs; the modest Exact-match of 13.78% is consistent with the tokens acting as generic labels rather than semantic part pointers, and no analysis of token usage or alignment between clusters and ground-truth parts is provided.
Authors: We acknowledge that regions are formed via spatial coherence rather than direct use of mesh part annotations. This choice enables inference without part labels while allowing the QA training signal (derived from annotations) and MSR to encourage semantic alignment of the <part_k> tokens. The exact-match of 13.78% is modest and may partly reflect generic labeling effects, though the Jaccard of 0.459 and GPT-4o judge of 44.68 suggest gains beyond marginal token addition. We will add an analysis of token usage statistics and quantitative alignment between clusters and ground-truth parts in the revision. revision: yes
-
Referee: [§4] §4 (experiments): no error bars, no ablation on K or the MSR module, and no description of how the 77K/588 PartVerse-QA split was constructed or how queries were generated from mesh annotations; these omissions make it impossible to assess whether the reported Jaccard 0.459 and GPT-4o 44.68 scores demonstrate part-specific binding or merely marginal gains from the added tokens.
Authors: We will add error bars computed over multiple random seeds. Ablations varying K and ablating the MSR module will be included to quantify their impact. A new subsection (or appendix) will detail the PartVerse-QA construction: the 77K/588 split uses disjoint object instances from PartVerse, with queries generated by templated questions over mesh part annotations. These changes will strengthen evidence that improvements reflect part-specific binding. revision: yes
Circularity Check
No significant circularity; empirical results on held-out data
full rationale
The paper describes an input reorganization method (patch partitioning into K regions, insertion of learnable markers and <part_k> tokens, plus MSR) to enable part addressing in 3D MLLMs, then reports performance on the constructed PartVerse-QA benchmark (77K training pairs, 588 held-out queries on disjoint splits) and external benchmarks like 3DCoMPaT-GrIn and Objaverse. No equations, predictions, or derivations are presented that reduce by construction to fitted parameters or self-referential definitions. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the text. The central capability claim is evaluated via standard held-out metrics rather than tautological equivalence to the method's own inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- K (number of regions)
- learnable per-region markers
axioms (1)
- domain assumption Frozen point encoder patches can be partitioned into K locally coherent regions whose spatial statistics are meaningful for part addressing
invented entities (1)
-
<part_k> reserved vocabulary token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
European Conference on Computer Vision , pages=
Pointllm: Empowering large language models to understand point clouds , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[2]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Kestrel: 3D Multimodal LLM for Part-Aware Grounded Description , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[3]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Pisa: A self-augmented data engine and training strategy for 3d understanding with large models , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[4]
arXiv preprint arXiv:2405.10370 , year=
Grounded 3d-llm with referent tokens , author=. arXiv preprint arXiv:2405.10370 , year=
-
[5]
arXiv preprint arXiv:2506.05689 , year=
Pts3D-LLM: Studying the Impact of Token Structure for 3D Scene Understanding With Large Language Models , author=. arXiv preprint arXiv:2506.05689 , year=
-
[6]
arXiv preprint arXiv:2511.13647 , year=
Part-X-MLLM: Part-aware 3D Multimodal Large Language Model , author=. arXiv preprint arXiv:2511.13647 , year=
-
[7]
arXiv preprint arXiv:2506.05573 , year=
Partcrafter: Structured 3d mesh generation via compositional latent diffusion transformers , author=. arXiv preprint arXiv:2506.05573 , year=
-
[8]
Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
Omnipart: Part-aware 3d generation with semantic decoupling and structural cohesion , author=. Proceedings of the SIGGRAPH Asia 2025 Conference Papers , pages=
2025
-
[9]
arXiv preprint arXiv:2509.16768 , year=
MMPart: Harnessing Multi-Modal Large Language Models for Part-Aware 3D Generation , author=. arXiv preprint arXiv:2509.16768 , year=
-
[10]
European Conference on Computer Vision , pages=
Shapellm: Universal 3d object understanding for embodied interaction , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[11]
arXiv preprint arXiv:2310.06773 , year=
Uni3d: Exploring unified 3d representation at scale , author=. arXiv preprint arXiv:2310.06773 , year=
-
[12]
arXiv preprint arXiv:2309.00615 , year=
Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following , author=. arXiv preprint arXiv:2309.00615 , year=
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Gpt4point: A unified framework for point-language understanding and generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[14]
Advances in Neural Information Processing Systems , volume=
3d-llm: Injecting the 3d world into large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
3dgraphllm: Combining semantic graphs and large language models for 3d scene understanding , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[16]
Advances in Neural Information Processing Systems , volume=
Chat-scene: Bridging 3d scene and large language models with object identifiers , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Descrip3D: Enhancing Large Language Model-based 3D Scene Understanding with Object-Level Text Descriptions , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[18]
arXiv preprint arXiv:2506.07491 , year=
Spatiallm: Training large language models for structured indoor modeling , author=. arXiv preprint arXiv:2506.07491 , year=
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
arXiv preprint arXiv:2409.18125 , year=
Llava-3d: A simple yet effective pathway to empowering lmms with 3d-awareness , author=. arXiv preprint arXiv:2409.18125 , year=
-
[21]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
3d-llava: Towards generalist 3d lmms with omni superpoint transformer , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[22]
2025 International Conference on 3D Vision (3DV) , pages=
Reason3d: Searching and reasoning 3d segmentation via large language model , author=. 2025 International Conference on 3D Vision (3DV) , pages=. 2025 , organization=
2025
-
[23]
European Conference on Computer Vision , pages=
Paris3d: Reasoning-based 3d part segmentation using large multimodal model , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[24]
European Conference on Computer Vision , pages=
Segpoint: Segment any point cloud via large language model , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[25]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[26]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Partslip: Low-shot part segmentation for 3d point clouds via pretrained image-language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[27]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Satr: Zero-shot semantic segmentation of 3d shapes , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
From one to more: Contextual part latents for 3d generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[29]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
3dcompat++: An improved large-scale 3d vision dataset for compositional recognition , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Point-bert: Pre-training 3d point cloud transformers with masked point modeling , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Lisa: Reasoning segmentation via large language model , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Glamm: Pixel grounding large multimodal model , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
See https://vicuna
Vicuna: An open-source chatbot impressing gpt-4 with 90\ author=. See https://vicuna. lmsys. org (accessed 14 April 2023) , volume=
2023
-
[34]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Objaverse: A universe of annotated 3d objects , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[35]
Advances in Neural Information Processing Systems , volume=
Scalable 3d captioning with pretrained models , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Ulip-2: Towards scalable multimodal pre-training for 3d understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Imagebind: One embedding space to bind them all , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Mask3d: Mask transformer for 3d semantic instance segmentation , author=. 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2023 , organization=
2023
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Grounded language-image pre-training , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[41]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[42]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Simcse: Simple contrastive learning of sentence embeddings , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[43]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[44]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[45]
Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments , author=. Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization , pages=
-
[46]
International conference on machine learning , pages=
Neural message passing for quantum chemistry , author=. International conference on machine learning , pages=. 2017 , organization=
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.