Not All Relations Rotate Alike: Transformation-Aware Decoupling for Viewpoint-Robust 3D Scene Graph Generation
Pith reviewed 2026-06-29 02:18 UTC · model grok-4.3
The pith
Decoupling predicates by transformation behavior under yaw shifts produces viewpoint-robust 3D scene graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
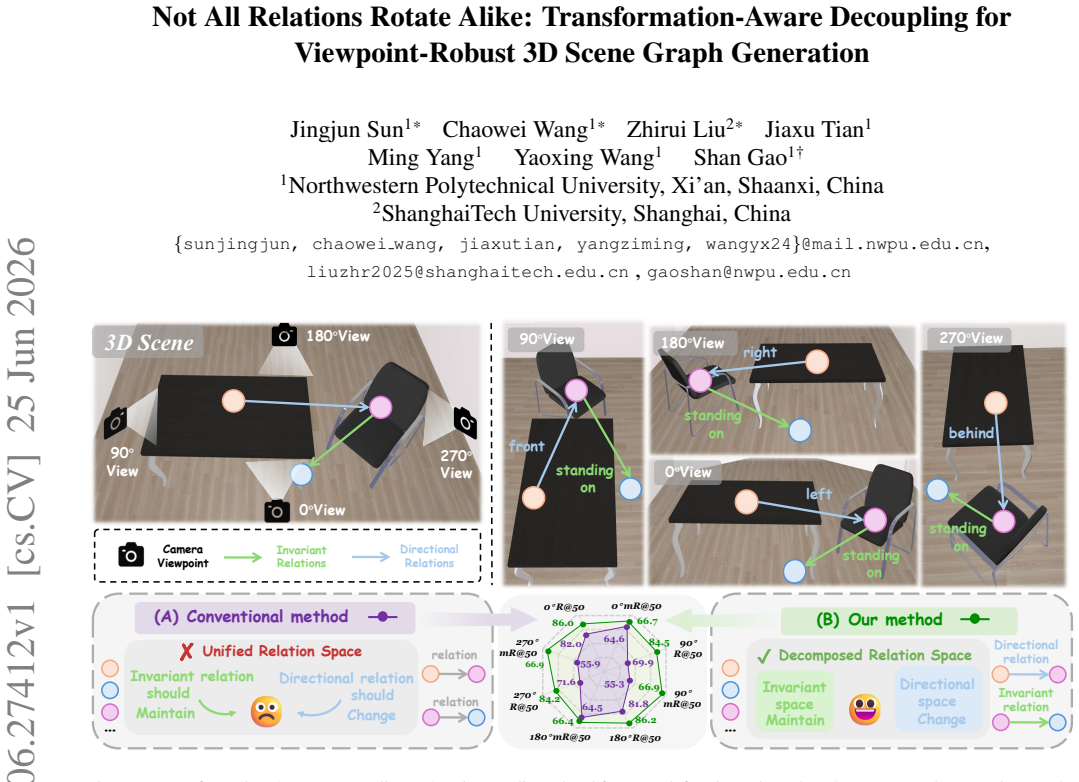
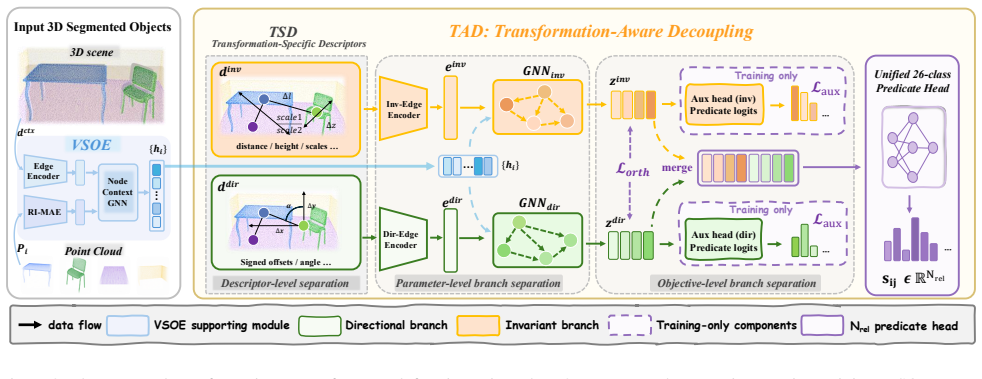
By decomposing relation reasoning into a viewpoint-stable branch and a viewpoint-transforming branch, each guided by transformation-specific descriptors and group-aware auxiliary supervision, the model produces predicate predictions whose behavior under yaw rotation matches the expected semantics of the predicates.
What carries the argument
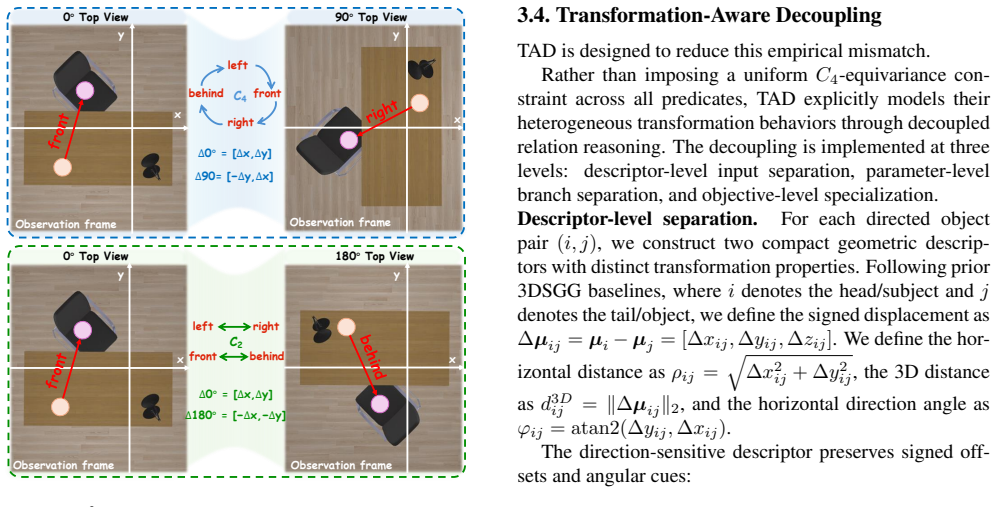
Transformation-Aware Decoupling (TAD), which splits the relation head into stable and directional branches that are trained with complementary supervision and then merged for prediction.
If this is right
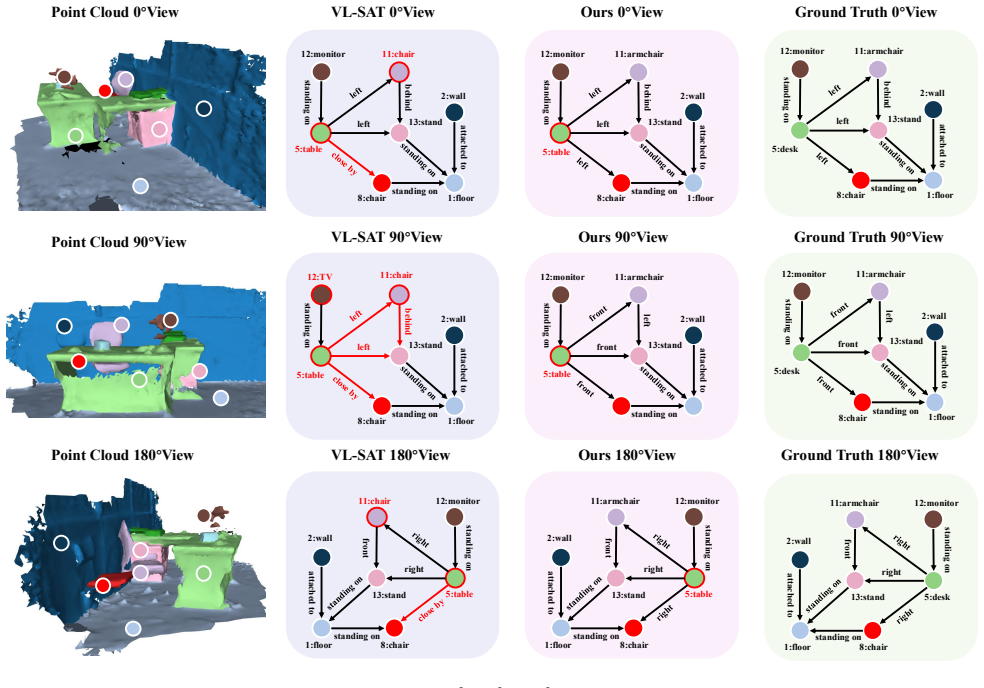
- Directional predicates transform correctly with the observation frame while stable predicates remain unchanged.
- Robustness to yaw viewpoint change is achieved without any rotation augmentation at training time.
- Standard benchmark performance is maintained or improved because the two branches capture complementary cues.
- The same decoupling principle can be applied to other structured prediction tasks that mix frame-dependent and frame-invariant relations.
Where Pith is reading between the lines
- The same split could be applied to other rotations such as pitch or to full 6-DoF viewpoint changes if the descriptors are extended accordingly.
- Embodied agents using these graphs would require fewer explicit rotation-invariant features because the graph itself already encodes the correct transformation rules.
- The auxiliary supervision could be replaced by self-supervised signals derived from known camera motion if labeled groups are unavailable.
Load-bearing premise
Predicates fall into two cleanly separable groups whose required behavior under viewpoint change can be learned by separate network branches.
What would settle it
On the 3DSSG test set with yaw-rotated observations, measure whether directional predicate scores change consistently with the rotation while stable predicate scores remain unchanged; if TAD shows no improvement over a single-branch baseline in this consistency metric, the claim is falsified.
Figures
read the original abstract
3D Scene Graph Generation (3DSGG) represents 3D scenes as structured object-relation-object graphs, providing a compact relational abstraction for spatial understanding. In embodied intelligence settings, the same 3D scene may be observed by agents from viewpoints that differ by yaw rotations. However, current 3DSGG models often fail to produce relation predictions that follow the expected transformation behavior under such viewpoint shifts. This behavior reveals an empirical mismatch related to predicate-level transformation heterogeneity: directional predicates such as left, front, right, and behind should transform with the observation frame, whereas most contact, support, and semantic predicates such as standing on and attached to should remain stable. To reduce this mismatch, we propose Transformation-Aware Decoupling (TAD), a viewpoint-robust 3DSGG framework that decouples relation reasoning according to predicate transformation behavior and is supported by viewpoint-stable object representations. TAD decomposes relation reasoning into two parts: one learns cues that should stay stable across viewpoints, while the other learns directional cues that should change with the observation frame. The two parts are merged for standard multi-label predicate prediction. Transformation-specific descriptors and group-aware auxiliary supervision encourage the two branches to capture complementary relation cues. Extensive experiments on 3DSSG show that TAD achieves state-of-the-art robustness under yaw viewpoint changes without training-time rotation augmentation, while maintaining competitive performance under the standard benchmark. The project page is available at https://tad-predicate.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Transformation-Aware Decoupling (TAD) for 3D Scene Graph Generation (3DSGG). It observes that predicates exhibit heterogeneous transformation behavior under yaw viewpoint changes—directional predicates (left, front, right, behind) should rotate with the observation frame while contact/support/semantic predicates (standing on, attached to) should remain stable—and introduces an architectural split into two relation-reasoning branches. One branch learns stable cues and the other directional cues; the branches are merged for multi-label prediction. Transformation-specific descriptors and group-aware auxiliary supervision are used to encourage complementary learning. Experiments on 3DSSG are reported to yield state-of-the-art robustness to yaw changes without training-time rotation augmentation while remaining competitive on the standard benchmark.
Significance. If the central mechanism holds, the work supplies a principled, augmentation-free route to viewpoint-robust relational reasoning that directly exploits predicate-level transformation heterogeneity. This is relevant for embodied agents that must maintain consistent scene graphs across yaw shifts. The explicit separation of stable versus directional cues, together with the auxiliary supervision, constitutes a concrete architectural contribution beyond generic invariance techniques.
major comments (1)
- [§3] §3 (Method), predicate partitioning paragraph: the a priori split of predicates into directional versus stable groups is load-bearing for the claimed decoupling benefit. No empirical validation is described that confirms this fixed grouping matches the actual yaw-induced transformation statistics in 3DSSG (e.g., measured change in predicate occurrence or model output under controlled yaw). If the grouping is incomplete or context-dependent, the two branches cannot reliably separate cues and the reported robustness gain cannot be attributed to the transformation-aware mechanism.
minor comments (2)
- Ensure that all experimental tables report both standard-benchmark and yaw-robustness metrics side-by-side with the same baselines and ablations so that the trade-off (or lack thereof) is immediately visible.
- Clarify the exact form of the group-aware auxiliary losses (cross-entropy on which labels? weighting scheme?) and whether they are applied only at training time.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point-by-point below.
read point-by-point responses
-
Referee: [§3] §3 (Method), predicate partitioning paragraph: the a priori split of predicates into directional versus stable groups is load-bearing for the claimed decoupling benefit. No empirical validation is described that confirms this fixed grouping matches the actual yaw-induced transformation statistics in 3DSSG (e.g., measured change in predicate occurrence or model output under controlled yaw). If the grouping is incomplete or context-dependent, the two branches cannot reliably separate cues and the reported robustness gain cannot be attributed to the transformation-aware mechanism.
Authors: We agree that the manuscript would benefit from explicit empirical validation of the predicate grouping against yaw-induced statistics in 3DSSG. The split is motivated by the semantic distinction (directional predicates transform with the frame; contact/support/semantic predicates remain stable) and is consistent with observed failures of prior models, but we did not report quantitative measurements such as predicate occurrence shifts or output changes under controlled yaw. In the revision we will add this analysis (e.g., frequency or prediction-change statistics per group) to confirm the grouping aligns with the data and to support attribution of the robustness gains. revision: yes
Circularity Check
No circularity: architectural decoupling rests on empirical predicate grouping and auxiliary losses, not self-referential derivations.
full rationale
The paper presents TAD as an architectural split of relation reasoning into stable and directional branches, using transformation-specific descriptors and group-aware auxiliary supervision. No equations, fitted parameters renamed as predictions, or self-citation chains are described in the provided text that would reduce the claimed robustness gain to a definitional tautology or input fit. The predicate partitioning is an a priori modeling choice justified by observed transformation heterogeneity, not derived from the method itself. The central claim remains an empirical engineering proposal rather than a closed-form derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
3d scene graph: A structure for unified se- mantics, 3d space, and camera.2019 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 5663–5672, 2019
Iro Armeni, Zhi-Yang He, JunYoung Gwak, Amir Zamir, Martin Fischer, Jitendra Malik, and Silvio Savarese. 3d scene graph: A structure for unified se- mantics, 3d space, and camera.2019 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 5663–5672, 2019. 2
2019
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, Nikita Cherni- adev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021. 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Opensga: Efficient 3d scene graph alignment in the open world
Gang Chen, Sebasti ´an Barbas Laina, Stefan Leuteneg- ger, and Javier Alonso-Mora. Opensga: Efficient 3d scene graph alignment in the open world. 2026. 3
2026
-
[5]
Lianggangxu Chen, Xuejiao Wang, Jiale Lu, Shao- hui Lin, Changbo Wang, and Gaoqi He. Clip-driven open-vocabulary 3d scene graph generation via cross- modality contrastive learning.2024 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 27863–27873, 2024. 3
2024
-
[6]
Knowledge-embedded routing network for scene graph generation
Tianshui Chen, Weihao Yu, Riquan Chen, and Liang Lin. Knowledge-embedded routing network for scene graph generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 6163–6171, 2019. 3
2019
-
[7]
Group Equivariant Convolutional Networks
Taco Cohen and Max Welling. Group equivariant con- volutional networks.ArXiv, abs/1602.07576, 2016. 3
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Vector neurons: A general framework for so (3)-equivariant networks
Congyue Deng, Or Litany, Yueqi Duan, Adrien Poulenard, Andrea Tagliasacchi, and Leonidas J Guibas. Vector neurons: A general framework for so (3)-equivariant networks. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 12200–12209, 2021. 3
2021
-
[9]
Se (3)-transformers: 3d roto-translation equivariant attention networks.Advances in neural in- formation processing systems, 33:1970–1981, 2020
Fabian Fuchs, Daniel Worrall, V olker Fischer, and Max Welling. Se (3)-transformers: 3d roto-translation equivariant attention networks.Advances in neural in- formation processing systems, 33:1970–1981, 2020. 3
1970
-
[10]
Conceptgraphs: Open- vocabulary 3d scene graphs for perception and plan- ning
Qiao Gu, Ali Kuwajerwala, Sacha Morin, Kr- ishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty El- lis, Rama Chellappa, et al. Conceptgraphs: Open- vocabulary 3d scene graphs for perception and plan- ning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5021–5028. IEEE, 2024. 2, 3
2024
-
[11]
KunHo Heo, GiHyun Kim, SuYeon Kim, and Myeon- gAh Cho. Object-centric representation learning for enhanced 3d scene graph prediction.arXiv preprint arXiv:2510.04714, 2025. 2, 3, 6, 7
-
[12]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language- action model.arXiv preprint arXiv:2406.09246, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Open3dsg: Open-vocabulary 3d scene graphs from point clouds with queryable objects and open-set relationships
Sebastian Koch, Narunas Vaskevicius, Mirco Colosi, Pedro Hermosilla, and Timo Ropinski. Open3dsg: Open-vocabulary 3d scene graphs from point clouds with queryable objects and open-set relationships. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 14183– 14193, 2024. 2, 3
2024
-
[14]
Bipartite graph network with adaptive message passing for unbiased scene graph generation
Rongjie Li, Songyang Zhang, Bo Wan, and Xuming He. Bipartite graph network with adaptive message passing for unbiased scene graph generation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11109–11119,
-
[15]
Zhirui Liu, Kaiyang Ji, Ke Yang, Yahao Fan, Jingyi Yu, Ye Shi, and Jingya Wang. Commanding hu- manoid by free-form language: A large language ac- tion model with unified motion vocabulary.arXiv preprint arXiv:2511.22963, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Vizor: Viewpoint-invariant zero- shot scene graph generation for 3d scene reasoning
Vivek Madhavaram, Vartika Sengar, Arkadipta De, and Charu Sharma. Vizor: Viewpoint-invariant zero- shot scene graph generation for 3d scene reasoning. arXiv preprint arXiv:2602.00637, 2026. 3
-
[17]
Pointnet++: Deep hierarchical feature learn- ing on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learn- ing on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 7
2017
-
[18]
Spherical fractal convolutional neural networks for point cloud recognition
Yongming Rao, Jiwen Lu, and Jie Zhou. Spherical fractal convolutional neural networks for point cloud recognition. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 452–460, 2019. 3
2019
-
[19]
arXiv preprint arXiv:2002.06289 (2020)
Antoni Rosinol, Arjun Gupta, Marcus Abate, J. Shi, and Luca Carlone. 3d dynamic scene graphs: Action- able spatial perception with places, objects, and hu- mans.ArXiv, abs/2002.06289, 2020. 2
-
[20]
Sgaligner: 3d scene alignment with scene graphs.2023 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 21870–21880, 2023
Sayan Deb Sarkar, Ond ˇrej Mik ˇs´ık, Marc Pollefeys, D´aniel Bar ´ath, and Iro Armeni. Sgaligner: 3d scene alignment with scene graphs.2023 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 21870–21880, 2023. 3
2023
-
[21]
Ri- mae: Rotation-invariant masked autoencoders for self- supervised point cloud representation learning
Kunming Su, Qiuxia Wu, Panpan Cai, Xiaogang Zhu, Xuequan Lu, Zhiyong Wang, and Kun Hu. Ri- mae: Rotation-invariant masked autoencoders for self- supervised point cloud representation learning. In Proceedings of the AAAI Conference on Artificial In- telligence, pages 7015–7023, 2025. 3, 4, 6
2025
-
[22]
Tomu Tahara, Takashi Seno, Gaku Narita, and To- moya Ishikawa. Retargetable ar: Context-aware aug- mented reality in indoor scenes based on 3d scene graph.2020 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), pages 249–255, 2020. 2
2020
-
[23]
Learning to compose dynamic tree structures for visual contexts
Kaihua Tang, Hanwang Zhang, Baoyuan Wu, Wenhan Luo, and Wei Liu. Learning to compose dynamic tree structures for visual contexts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6619–6628, 2019. 2, 3
2019
-
[24]
Unbiased scene graph gener- ation from biased training
Kaihua Tang, Yulei Niu, Jianqiang Huang, Jiaxin Shi, and Hanwang Zhang. Unbiased scene graph gener- ation from biased training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3716–3725, 2020. 3
2020
-
[25]
Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds
Nathaniel Thomas, Tess E. Smidt, Steven M. Kearnes, Lusann Yang, Li Li, Kai Kohlhoff, and Patrick F. Ri- ley. Tensor field networks: Rotation- and translation- equivariant neural networks for 3d point clouds. ArXiv, abs/1802.08219, 2018. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[26]
Rio: 3d ob- ject instance re-localization in changing indoor envi- ronments
Johanna Wald, Armen Avetisyan, Nassir Navab, Fed- erico Tombari, and Matthias Nießner. Rio: 3d ob- ject instance re-localization in changing indoor envi- ronments. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 7658– 7667, 2019. 2, 5
2019
-
[27]
Learning 3d semantic scene graphs from 3d indoor reconstructions
Johanna Wald, Helisa Dhamo, Nassir Navab, and Fed- erico Tombari. Learning 3d semantic scene graphs from 3d indoor reconstructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 3961–3970, 2020. 2, 3, 5
2020
-
[28]
Sgpn: Similarity group proposal network for 3d point cloud instance segmentation
Weiyue Wang, Ronald Yu, Qiangui Huang, and Ulrich Neumann. Sgpn: Similarity group proposal network for 3d point cloud instance segmentation. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 2569–2578, 2018. 6, 7
2018
-
[29]
Xihan Wang, Dianyi Yang, Yu Gao, Yufeng Yue, Yi Yang, and Mengyin Fu. Gaussiangraph: 3d gaussian- based scene graph generation for open-world scene understanding.2025 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS), pages 4091–4098, 2025. 3
2025
-
[30]
Vl-sat: Visual-linguistic semantics assisted training for 3d semantic scene graph prediction in point cloud
Ziqin Wang, Bowen Cheng, Lichen Zhao, Dong Xu, Yang Tang, and Lu Sheng. Vl-sat: Visual-linguistic semantics assisted training for 3d semantic scene graph prediction in point cloud. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21560–21569, 2023. 2, 3, 6, 7
2023
-
[31]
General e(2)- equivariant steerable cnns
Maurice Weiler and Gabriele Cesa. General e(2)- equivariant steerable cnns. InNeural Information Pro- cessing Systems, 2019. 3
2019
-
[32]
Scenegraphfusion: Incremental 3d scene graph prediction from rgb-d se- quences
Shun-Cheng Wu, Johanna Wald, Keisuke Tateno, Nas- sir Navab, and Federico Tombari. Scenegraphfusion: Incremental 3d scene graph prediction from rgb-d se- quences. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7515–7525, 2021. 2, 6, 7
2021
-
[33]
Yaxu Xie, Alain Pagani, and Didier Stricker. Sg- pgm: Partial graph matching network with semantic geometric fusion for 3d scene graph alignment and its downstream tasks.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 28401–28411, 2024. 3
2024
-
[34]
Scene graph generation by iterative message passing
Danfei Xu, Yuke Zhu, Christopher B Choy, and Li Fei-Fei. Scene graph generation by iterative message passing. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5410– 5419, 2017. 2
2017
-
[35]
Pare-net: Position-aware rotation-equivariant networks for robust point cloud registration
Runzhao Yao, Shaoyi Du, Wenting Cui, Canhui Tang, and Chengwu Yang. Pare-net: Position-aware rotation-equivariant networks for robust point cloud registration. InEuropean Conference on Computer Vi- sion, 2024. 3
2024
-
[36]
Qi Xun Yeo, Yanyan Li, and Gim Hee Lee. Statis- tical confidence rescoring for robust 3d scene graph generation from multi-view images.2025 IEEE/CVF International Conference on Computer Vision (ICCV), pages 24999–25008, 2025. 3
2025
-
[37]
Bridging knowledge graphs to generate scene graphs
Alireza Zareian, Svebor Karaman, and Shih-Fu Chang. Bridging knowledge graphs to generate scene graphs. InEuropean conference on computer vision, pages 606–623. Springer, 2020. 3
2020
-
[38]
Neural motifs: Scene graph parsing with global context
Rowan Zellers, Mark Yatskar, Sam Thomson, and Yejin Choi. Neural motifs: Scene graph parsing with global context. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5831–5840, 2018. 2, 3
2018
-
[39]
Exploiting edge-oriented reasoning for 3d point- based scene graph analysis
Chaoyi Zhang, Jianhui Yu, Yang Song, and Weidong Cai. Exploiting edge-oriented reasoning for 3d point- based scene graph analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9705–9715, 2021. 2, 3
2021
-
[40]
Knowledge-inspired 3d scene graph prediction in point cloud.Advances in Neural Information Process- ing Systems, 34:18620–18632, 2021
Shoulong Zhang, Aimin Hao, Hong Qin, et al. Knowledge-inspired 3d scene graph prediction in point cloud.Advances in Neural Information Process- ing Systems, 34:18620–18632, 2021. 2, 6, 7
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.