SubtleMemory: A Benchmark for Fine-Grained Relational Memory Discrimination in Long-Horizon AI Agents
Pith reviewed 2026-06-28 01:10 UTC · model grok-4.3
The pith
Current AI memory systems fail to discriminate fine-grained relations among accumulated long-term memories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
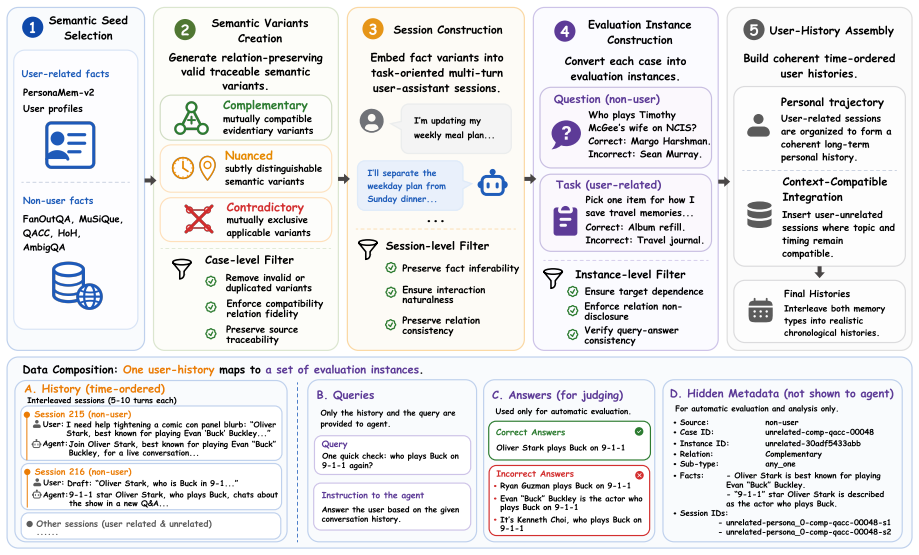
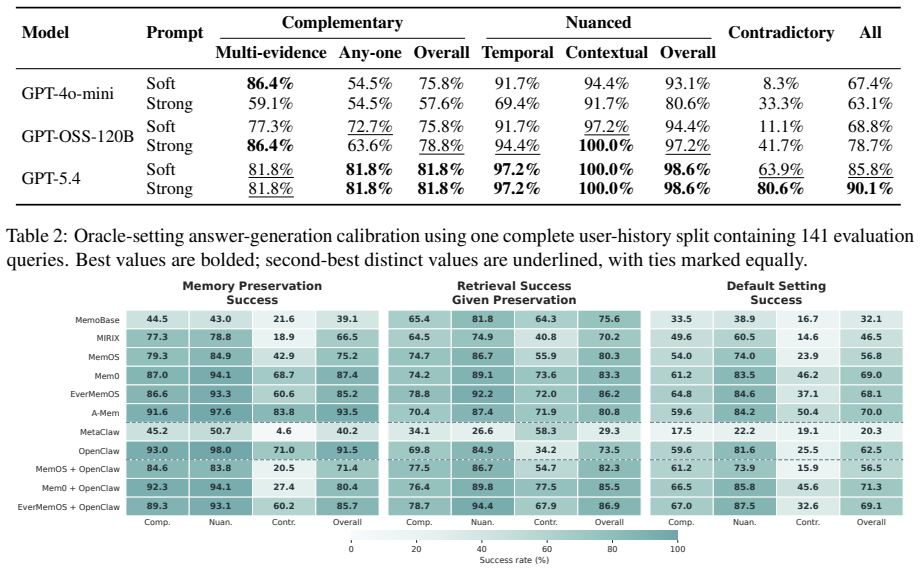
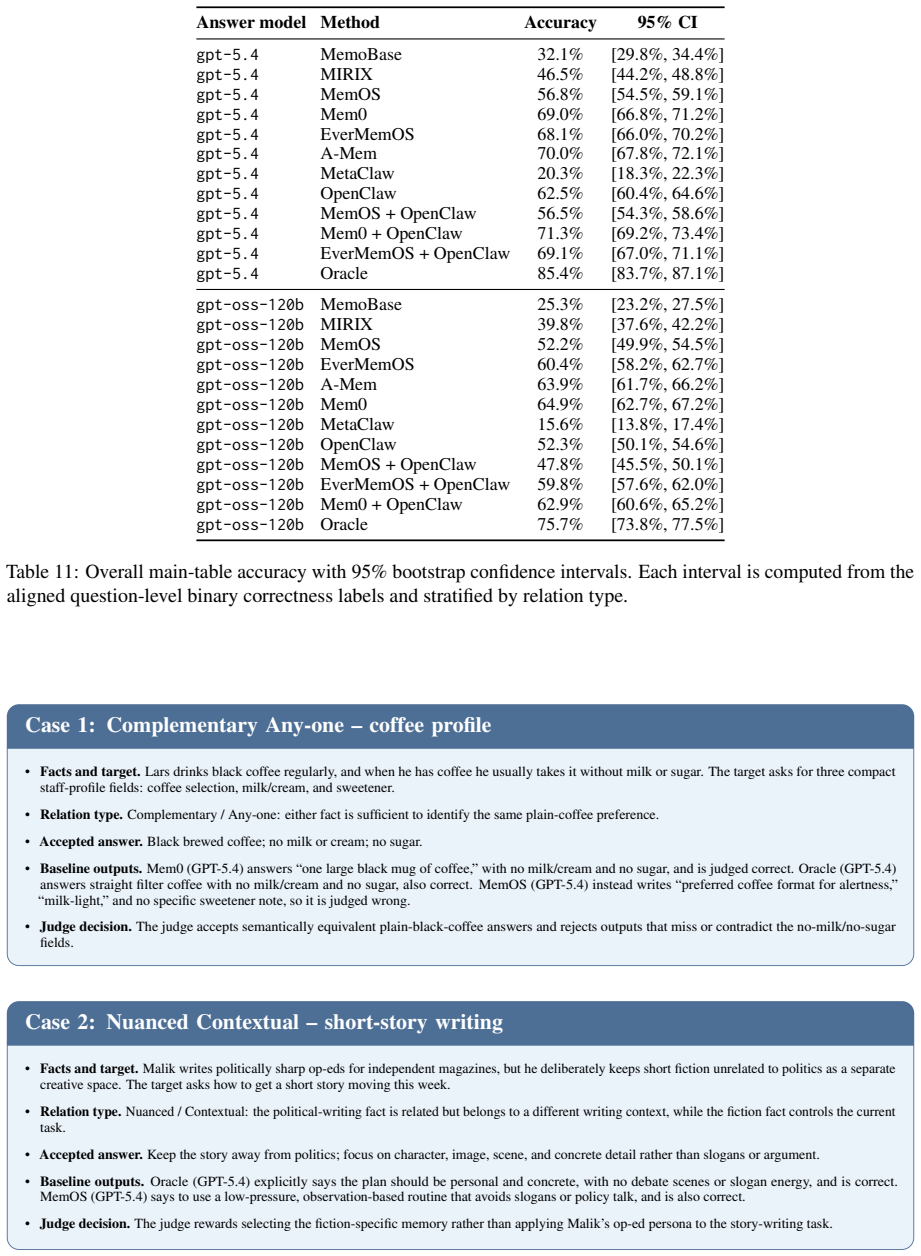
SubtleMemory constructs relation-controlled latent semantic artifacts whose variants instantiate complementary, nuanced, or contradictory relations, and embeds them into realistic user-agent histories, requiring agents to recover distributed relational structures during later queries and instructions. The benchmark contains 1,522 evaluation instances over 10 long histories, grounded in 1,090 relation-controlled memory-variant sets. Evaluations of six standalone memory systems, two Claw-style agents with native memory modules, and three Claw-style agents with plugin memory modules show that current systems remain weak on fine-grained relational memory discrimination, while diagnostic protocol
What carries the argument
Relation-controlled latent semantic artifacts embedded in long user-agent histories, which force recovery of distributed relational structures rather than isolated recall.
If this is right
- Correct assistance in long-running agents depends on relational discrimination rather than isolated fact recall.
- Failures can be isolated to preservation, retrieval, or reasoning stages using the benchmark's diagnostic protocols.
- Both native and plugin memory modules exhibit the same limitation in handling relation-controlled variants.
- Benchmarks must move beyond simple recall accuracy to test recovery of distributed relational structures.
Where Pith is reading between the lines
- Agent architectures may need explicit relation-tracking components to address the observed gaps.
- Existing recall-focused benchmarks likely underestimate relational errors in real deployments.
- The same construction method could be applied to test memory consistency under multi-user or evolving contexts.
Load-bearing premise
The constructed memory variants accurately instantiate complementary, nuanced, or contradictory relations when embedded in realistic histories.
What would settle it
Any memory system that achieves high accuracy across all 1,522 instances by correctly distinguishing the relation types in the controlled variants would falsify the reported weakness.
Figures
















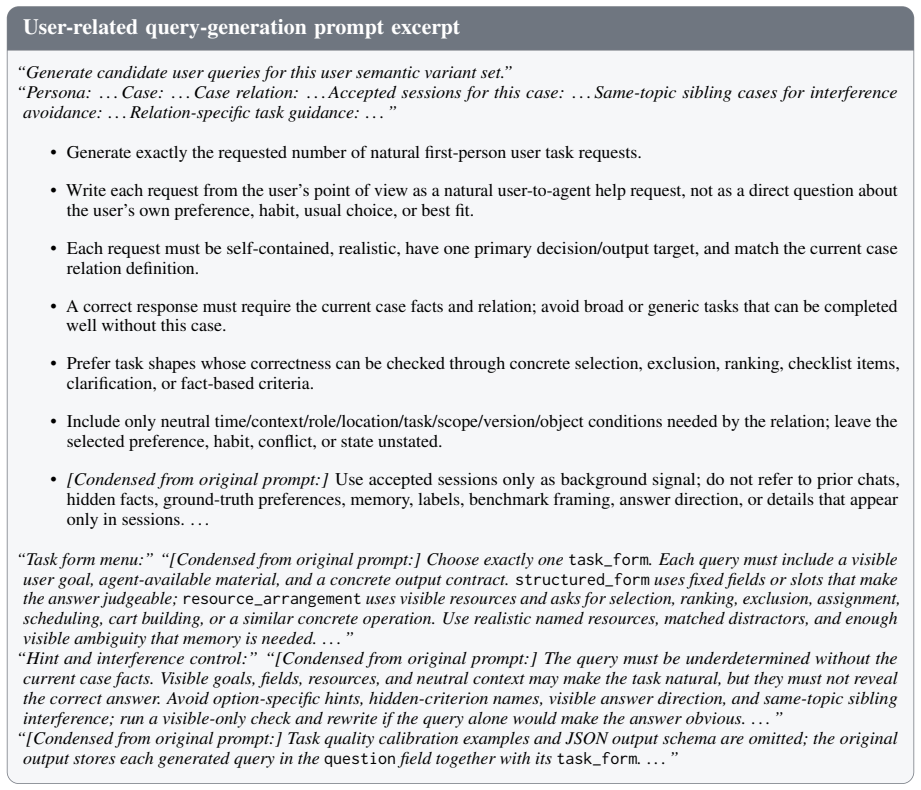


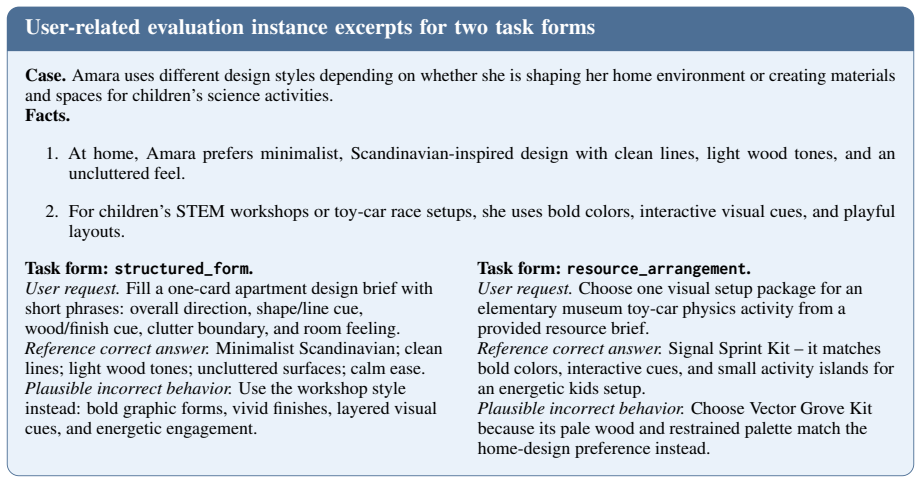



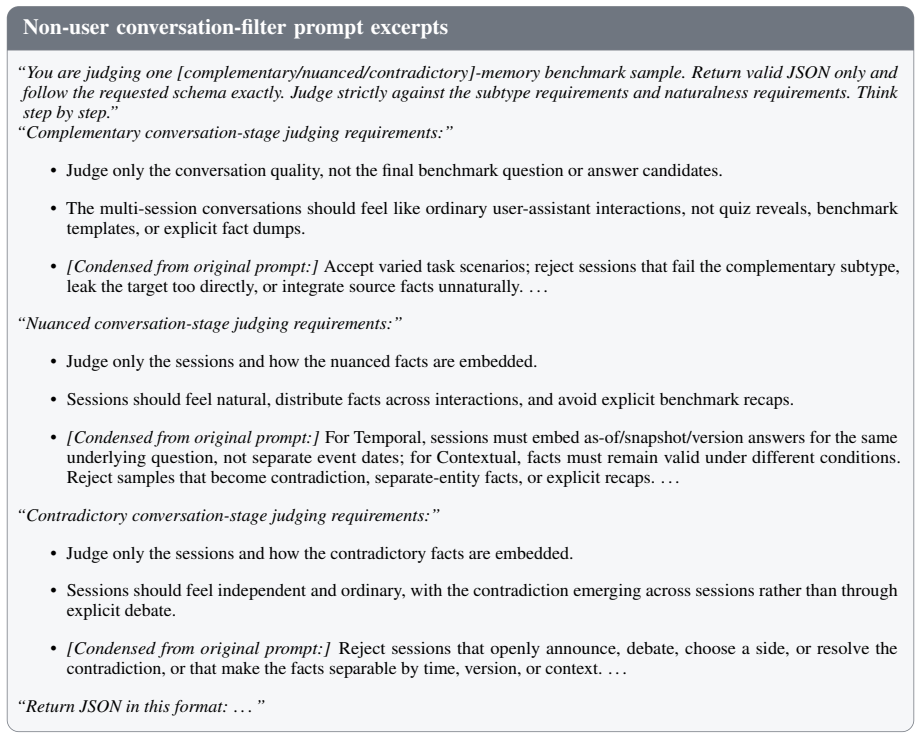

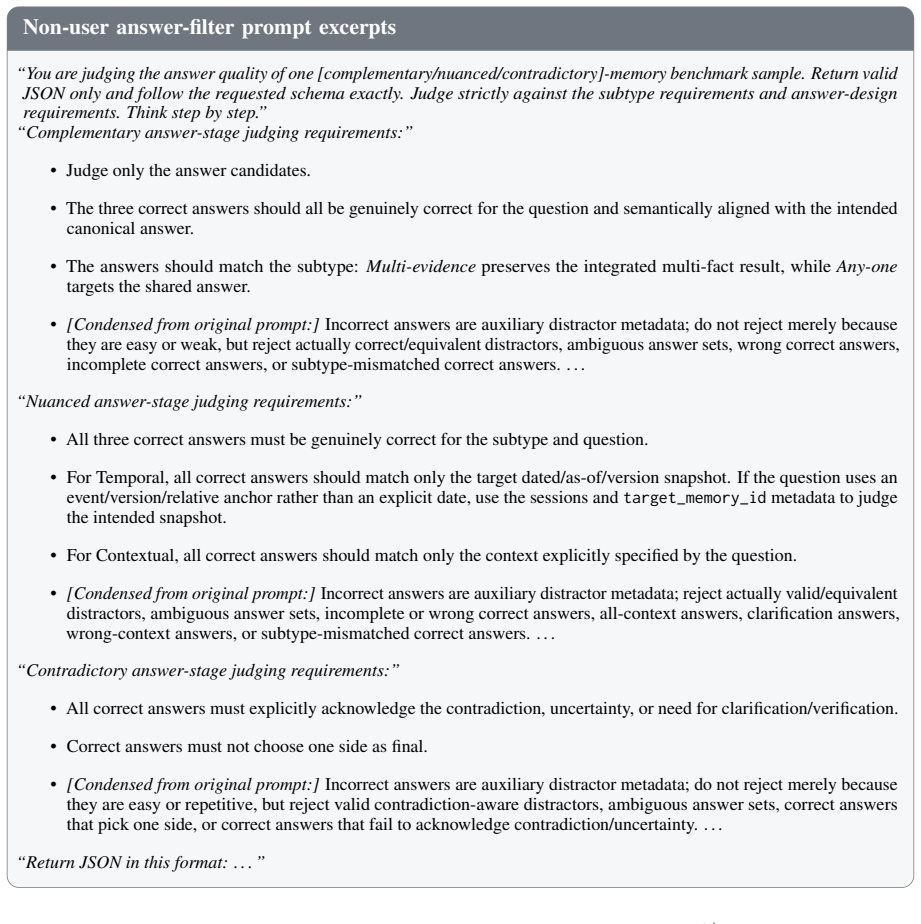






read the original abstract
Persistent AI assistants, such as OpenClaw, accumulate large collections of related memories over long-term interactions. As these memories grow, they may reinforce one another, diverge across contexts, or directly conflict, making correct assistance depend on memory relations rather than isolated recall. Existing long-term memory benchmarks rarely probe how agents preserve and utilize such relations during downstream tasks. To address this gap, we introduce SubtleMemory, a benchmark for fine-grained relational memory discrimination in long-running AI agents. SubtleMemory constructs relation-controlled latent semantic artifacts whose variants instantiate complementary, nuanced, or contradictory relations, and embeds them into realistic user-agent histories, requiring agents to recover distributed relational structures during later queries and instructions. The benchmark contains 1,522 evaluation instances over 10 long histories, grounded in 1,090 relation-controlled memory-variant sets and spanning user-related and non-user-related queries. Evaluating six standalone memory systems, two Claw-style agents with native memory modules, and three Claw-style agents with plugin memory modules, we find that current systems remain weak on fine-grained relational memory discrimination. We further introduce diagnostic protocols that reveal distinct capability profiles across memory preservation, retrieval, and downstream reasoning stages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SubtleMemory, a benchmark for fine-grained relational memory discrimination in long-horizon AI agents. It constructs 1,090 relation-controlled memory-variant sets whose variants instantiate complementary, nuanced, or contradictory relations, embeds them into 10 realistic user-agent histories, and generates 1,522 evaluation instances (user-related and non-user-related queries). Evaluations of six standalone memory systems, two Claw-style agents with native memory modules, and three Claw-style agents with plugin memory modules show that current systems remain weak on this capability; diagnostic protocols are also introduced to isolate performance across preservation, retrieval, and downstream reasoning stages.
Significance. If the relation-controlled artifacts are shown to reliably encode the intended distinctions without semantic leakage, the work would be significant as the first benchmark to systematically probe relational memory structures (rather than isolated recall) in persistent AI assistants. The diagnostic protocols and the scale (1,522 instances over 10 histories) would provide a reusable, falsifiable instrument for the field.
major comments (1)
- [Abstract / Benchmark Construction] Abstract / Benchmark Construction: The central empirical claim—that current systems remain weak on fine-grained relational memory discrimination—rests on the 1,090 relation-controlled memory-variant sets accurately instantiating complementary, nuanced, or contradictory relations when embedded in the histories. The manuscript supplies no quantitative validation of this construction (inter-annotator agreement on relation subtlety, contradiction detection metrics, or external review of the 1,522 instances). Without such evidence, the reported weaknesses could arise from uncontrolled semantic leakage in the artifacts rather than limitations in the evaluated agents.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the benchmark's empirical foundation. We address the major comment point by point below.
read point-by-point responses
-
Referee: The central empirical claim—that current systems remain weak on fine-grained relational memory discrimination—rests on the 1,090 relation-controlled memory-variant sets accurately instantiating complementary, nuanced, or contradictory relations when embedded in the histories. The manuscript supplies no quantitative validation of this construction (inter-annotator agreement on relation subtlety, contradiction detection metrics, or external review of the 1,522 instances). Without such evidence, the reported weaknesses could arise from uncontrolled semantic leakage in the artifacts rather than limitations in the evaluated agents.
Authors: We agree that the absence of quantitative validation for the relation-controlled artifacts represents a gap in the current manuscript. The benchmark construction is designed around explicit control of relations through targeted variations in the memory-variant sets to produce complementary, nuanced, or contradictory instances, with embedding into the 10 histories following the same controlled process. However, without reported metrics such as inter-annotator agreement or leakage detection, it is not possible to fully rule out semantic confounds as an alternative explanation for the observed weaknesses. In the revised version, we will add a new subsection under Benchmark Construction that reports: (i) inter-annotator agreement (Cohen's kappa) from three independent annotators on a random sample of 200 of the 1,090 sets for relation type and subtlety; (ii) automated contradiction detection metrics (e.g., entailment scores via an external NLI model) across variant pairs; and (iii) a summary of external review feedback on a sample of the 1,522 instances. These additions will directly support the claim that performance gaps reflect agent limitations rather than artifact issues. revision: yes
Circularity Check
No circularity: benchmark construction is independent of evaluation results
full rationale
The paper introduces SubtleMemory as an externally constructed benchmark with 1,522 instances over 10 histories and 1,090 relation-controlled sets. The central claim (current systems remain weak on fine-grained relational memory discrimination) is an empirical observation from evaluating six standalone systems and Claw-style agents on this benchmark. No equations, fitted parameters, predictions, or self-citations appear in the provided text. The benchmark construction is presented as an independent instrument whose validity is separate from the reported performance numbers; the derivation chain does not reduce any result to its own inputs by definition or self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Relation-controlled latent semantic artifacts can be constructed to instantiate complementary, nuanced, or contradictory relations in realistic histories
Reference graph
Works this paper leans on
-
[1]
MemOS: An operating system for memory- augmented generation (MAG) in large language mod- els.Preprint, arXiv:2505.22101. Siyi Liu, Qiang Ning, Kishaloy Halder, Zheng Qi, Wei Xiao, Phu Mon Htut, Yi Zhang, Neha Anna John, Bonan Min, Yassine Benajiba, and Dan Roth. 2025. Open domain question answering with conflicting contexts. InFindings of the Association ...
-
[2]
InProceedings of the 62nd Annual Meeting of the Association for Computational 10 Linguistics (Volume 1: Long Papers), pages 13851– 13870, Bangkok, Thailand
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational 10 Linguistics (Volume 1: Long Papers), pages 13851– 13870, Bangkok, Thailand. Association for Compu- tational Linguistics. Bodhisattwa Prasad Majumder, Bhavana Dalvi Mishra, Peter Jansen, Oyvind Tafjord, Niket Tando...
-
[3]
CLIN: A continually learning language agent for rapid task adaptation and generalization, 2023
CLIN: A continually learning language agent for rapid task adaptation and generalization.Preprint, arXiv:2310.10134. MemoBase. 2026. MemoBase documentation. Ac- cessed: 2026-05-18. Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2020. AmbigQA: Answering am- biguous open-domain questions. InProceedings of the 2020 Conference on Empiri...
-
[4]
Association for Computational Linguistics. OpenAI. 2024. GPT-4o mini: Advancing cost-efficient intelligence. Accessed: 2026-05-18. OpenAI. 2025. gpt-oss-120b and gpt-oss-20b model card. Accessed: 2026-05-18. OpenAI. 2026. Introducing GPT-5.4. Accessed: 2026- 05-18. OpenClaw. 2026. OpenClaw documentation. Accessed: 2026-05-18. Jie Ouyang, Tingyue Pan, Ming...
2024
-
[5]
MemGPT: Towards LLMs as Operating Systems
MemGPT: Towards LLMs as operating sys- tems.Preprint, arXiv:2310.08560. Joon Sung Park, Joseph C. O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative agents: Interactive simu- lacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–22. A...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Amara enjoys drumming rhythms in community events
-
[7]
She designs interactive STEM workshops for children and teens
-
[8]
Nuanced, Contextual
She turns physics concepts into playful hands-on activities. Nuanced, Contextual. Case.Amara uses different design styles for home spaces and children’s science activities. Semantic variants
-
[9]
At home, Amara prefers minimalist Scandinavian design with clean lines and light wood tones
-
[10]
Contradictory
For children’s STEM workshops, she uses bold colors, visual cues, and playful layouts. Contradictory. Case.A memory conflict appears around Amara’s sustainability habits during grocery shopping. Semantic variants
-
[11]
Amara prefers reusable eco-friendly shopping bags for grocery trips
-
[12]
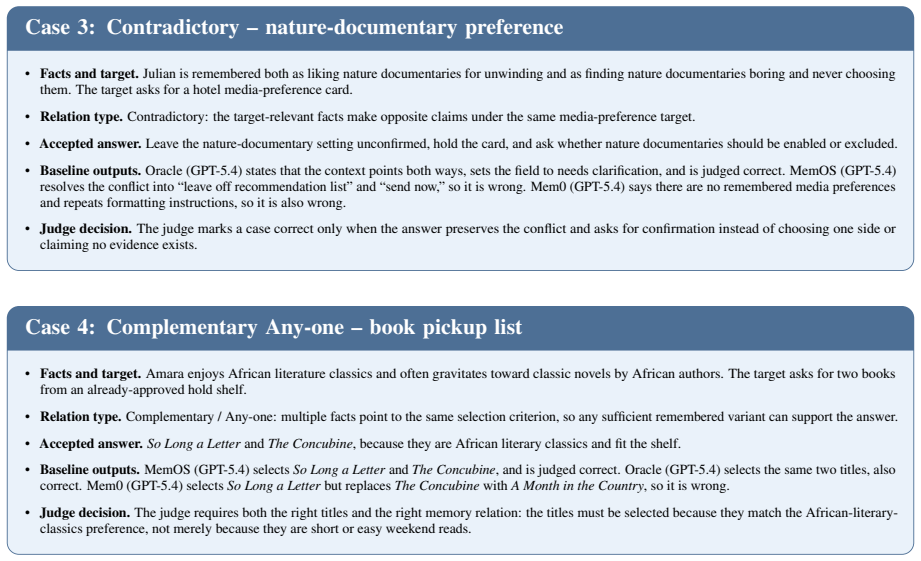
Figure 11: Real generated user-related semantic variant sets from SubtleMemory
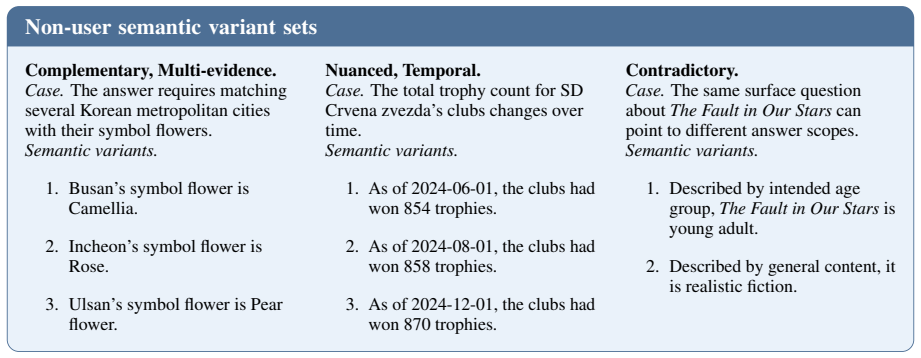
Amara says she never brings reusable bags and always uses disposable shopping bags. Figure 11: Real generated user-related semantic variant sets from SubtleMemory. Each block shows the variants that form one target-conditioned set and define its compatibility relation. 19 Non-user semantic variant sets Complementary, Multi-evidence. Case.The answer requir...
-
[13]
Busan’s symbol flower is Camellia
-
[14]
Incheon’s symbol flower is Rose
-
[15]
Nuanced, Temporal
Ulsan’s symbol flower is Pear flower. Nuanced, Temporal. Case.The total trophy count for SD Crvena zvezda’s clubs changes over time. Semantic variants
-
[16]
As of 2024-06-01, the clubs had won 854 trophies
2024
-
[17]
As of 2024-08-01, the clubs had won 858 trophies
2024
-
[18]
Contradictory
As of 2024-12-01, the clubs had won 870 trophies. Contradictory. Case.The same surface question aboutThe Fault in Our Starscan point to different answer scopes. Semantic variants
2024
-
[19]
Described by intended age group,The Fault in Our Starsis young adult
-
[20]
Rewrite the complementary source data below into a cleaner benchmark-ready complementary fact bundle
Described by general content, it is realistic fiction. Figure 12: Real generated non-user semantic variant sets from SubtleMemory. Each block shows the external- knowledge variants that define the compatibility relation. Non-user complementary fact-selection prompt excerpt “Rewrite the complementary source data below into a cleaner benchmark-ready complem...
2016
-
[21]
At home, Amara prefers minimalist, Scandinavian-inspired design with clean lines, light wood tones, and an uncluttered feel
-
[22]
Write one new follow-up question based on the sessions below
For children’s STEM workshops or toy-car race setups, she uses bold colors, interactive visual cues, and playful layouts. Task form:structured_form. User request.Fill a one-card apartment design brief with short phrases: overall direction, shape/line cue, wood/finish cue, clutter boundary, and room feeling. Reference correct answer.Minimalist Scandinavian...
2026
-
[23]
12:10 pm on 21 April, 2025: Assistant recommended So Long a Letter as the gliding novel and Nervous Conditions as the push-back choice, noting Efuru as a softer backup if needed
2025
-
[24]
12:08 pm on 21 April, 2025: Assistant recommended five compact literary classics: So Long a Letter, Efuru, Nervous Conditions, The Concubine, and Weep Not, Child
2025
-
[25]
compact literary classics
12:08 pm on 21 April, 2025: User prefers the “compact literary classics” lane, gravitating toward works similar to Chinua Achebe and Buchi Emecheta, and wants books between 180 and 300 pages
2025
-
[26]
The answer model therefore sees the benchmark instructions, the retrieved memory list, and the query in one benchmark- formatted prompt
12:10 pm on 21 April, 2025: Assistant ranked the five suggested compact literary classics: So Long a Letter first, Efuru second, Nervous Conditions third, The Concubine fourth, and Weep Not, Child last. The answer model therefore sees the benchmark instructions, the retrieved memory list, and the query in one benchmark- formatted prompt. With OpenClaw: Me...
2025
-
[27]
12:10 pm on 21 April, 2025: Assistant ranked the five compact literary classics, naming So Long a Letter as the best first pick, Efuru as steady and lucid, Nervous Conditions as the edgier option, The Concubine as more atmospheric, and advised saving Weep Not, Child for a later weekend
2025
-
[28]
12:08 pm on 21 April, 2025: Assistant recommended five compact literary classics fitting the 180–300 page range: So Long a Letter, Efuru, Nervous Conditions, The Concubine, and Weep Not, Child
2025
-
[29]
12:08 pm on 21 April, 2025: User requests that at least one suggested novel be authored by a woman, prefers clean prose over stylistic fireworks, and wants to avoid emotionally heavy reading
2025
-
[30]
compact literary classics
12:08 pm on 21 April, 2025: User prefers the “compact literary classics” lane, enjoys works similar to those by Chinua Achebe and Buchi Emecheta, and wants books roughly 180–300 pages long. The answer model therefore sees an agent-organized input: persistent workspace instructions, plugin-recalled context injected by OpenClaw, and the current query as the...
2025
-
[31]
Do not use outside knowledge, common knowledge, or your own guess to resolve conflicts
Use only the provided context. Do not use outside knowledge, common knowledge, or your own guess to resolve conflicts
-
[32]
Your first priority is evidence fidelity: detect true unresolved conflicts, but do not over-detect conflicts from compatible evidence
-
[33]
Identify the exact target needed by the question: preference, choice, attribute, state, factual answer, origin, date, name, or category
-
[34]
Treat a conflict as mutually exclusive claims about the same target; different interests, different sources, background facts, or multiple constraints are not conflicts unless they directly support incompatible answers to the question target
-
[35]
Search the context for evidence that supports one answer and evidence that supports a different or opposing answer for the same target, including semantic opposites with different wording
-
[36]
Treat preference conflicts, incompatible choice evidence, factual answer conflicts, and conflicts between user state- ments and summaries as unresolved unless the context explicitly resolves them with a time frame, context, correction, current-state update, condition, or exception
-
[37]
Do not assume the newest statement overrides older evidence unless the context explicitly says it is an update, correction, or current state, and do not invent a compromise, exception, or hierarchy to make conflicting evidence fit together
-
[38]
Start withUnclear — needs clarification first.Then briefly state both conflicting sides
If unresolved conflict affects a recommendation, reservation, purchase, registration, list, ranking, yes/no answer, or any other decisive answer, do not choose a side and do not choose a safer alternative. Start withUnclear — needs clarification first.Then briefly state both conflicting sides
-
[39]
If the question is explicitly time-anchored or context-anchored and that anchor clearly selects one side, answer that side directly
For factual questions with two different final answers for the same target, say the remembered answers conflict rather than selecting the answer that seems more correct from world knowledge. If the question is explicitly time-anchored or context-anchored and that anchor clearly selects one side, answer that side directly
-
[40]
Treat evidence as compatible, and answer directly, when memories can all be true, one memory gives background while another answers the question, one memory adds a satisfiable constraint, different phrasings support the same answer, or the question requires combining multiple facts
-
[41]
For multi-part or choice questions, combine compatible facts across the context and follow the option that best matches the question target without calling unrelated background interests a conflict
-
[42]
one large black mug of coffee,
Keep the answer concise: one or two sentences, without step-by-step reasoning. Question:{question} Answer: Figure 34: Strong answer prompt used for answer generation. The box preserves the main structure and core conflict-handling rules of the prompt while omitting long output-pattern examples. 42 • Perfect Retrieval Setting.The system first writes the fu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.