LANG: Reinforcement Learning for Multilingual Reasoning with Language-Adaptive Hint Guidance
Pith reviewed 2026-05-22 06:16 UTC · model grok-4.3
The pith
LANG uses decaying language hints in reinforcement learning to improve non-English reasoning while preserving language consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LANG addresses the challenge in multilingual reasoning by incorporating language-conditioned hints to guide exploration in non-English reasoning tasks. It prevents dependency on these hints through a progressive decay schedule that gradually withdraws scaffolding and a language-adaptive switch that tailors learning horizons to specific language difficulties. Empirical results on challenging multilingual mathematical benchmarks reveal that LANG substantially enhances reasoning performance without compromising language consistency. Moreover, the framework generalizes beyond mathematics, fostering more consistent language alignment across model layers.
What carries the argument
Language-conditioned hints paired with a progressive decay schedule and a language-adaptive switch that tailors learning horizons to language difficulty.
If this is right
- Reasoning performance improves substantially on challenging multilingual mathematical benchmarks.
- Language consistency is preserved and language drift toward English is avoided.
- The framework generalizes to tasks beyond mathematics.
- More consistent language alignment is achieved across model layers.
Where Pith is reading between the lines
- Similar hint guidance could be tested on multilingual code or science reasoning tasks to check if the same consistency gains appear.
- The decay schedule and adaptive switch might be tuned per language family to handle greater difficulty variation.
- Combining this approach with other alignment techniques could further stabilize output language in very long reasoning chains.
Load-bearing premise
Language-conditioned hints can be progressively decayed and paired with a language-adaptive switch without causing loss of reasoning gains or reintroducing language drift.
What would settle it
If removing the hints after training causes a measurable drop in accuracy on non-English math problems or an increase in language switching on the same benchmarks, the central claim would be falsified.
Figures










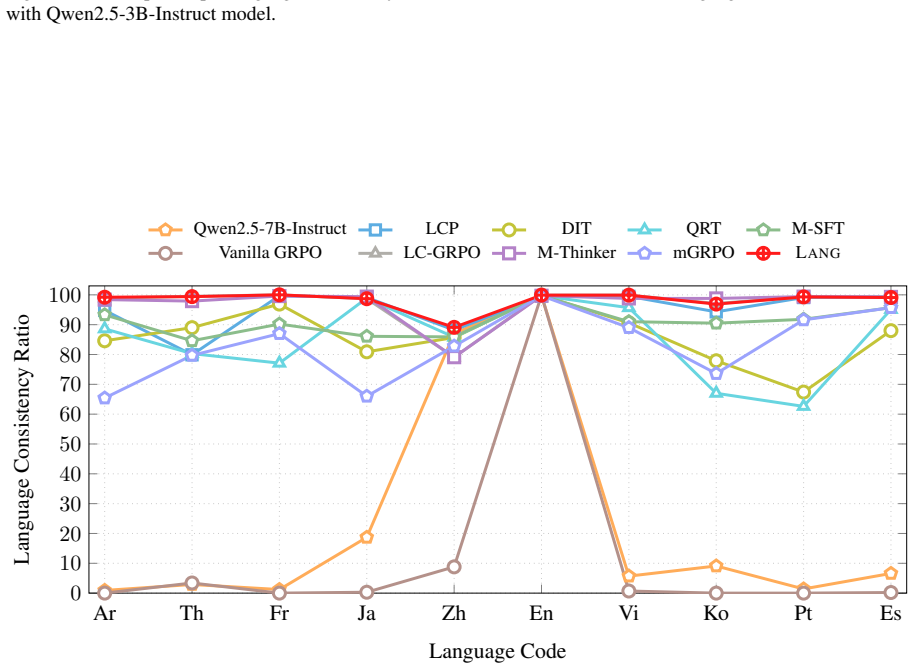
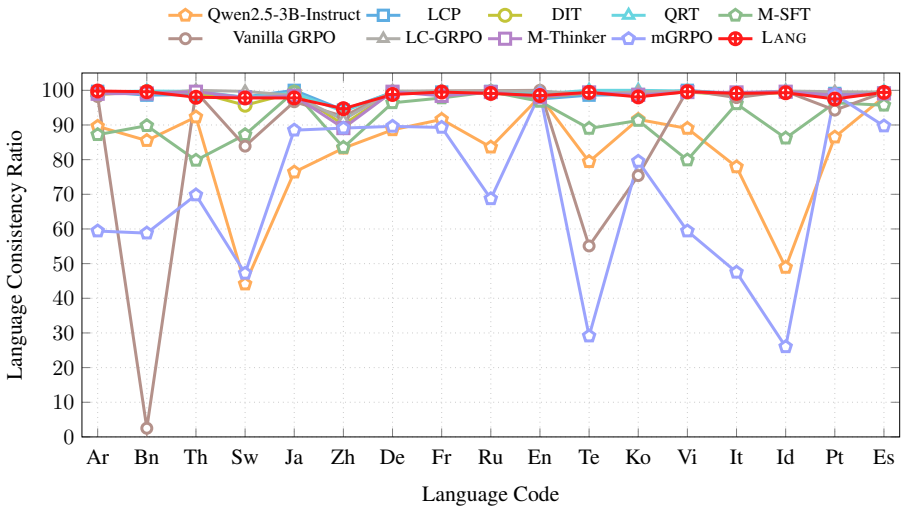
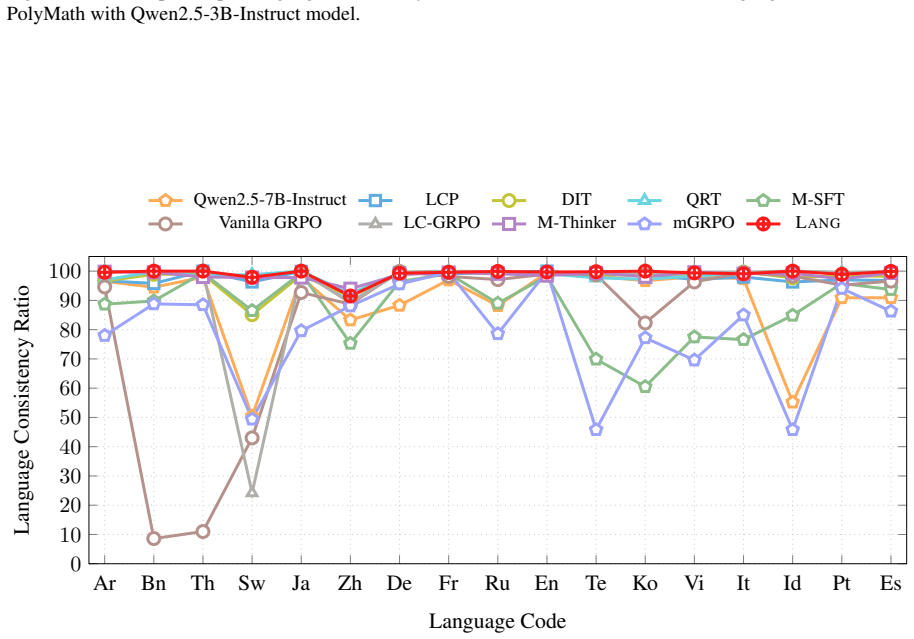
read the original abstract
Reinforcement learning has proven effective for enhancing multi-step reasoning in large language models (LLMs), yet its benefits have not fully translated to multilingual contexts. Existing methods struggle with a fundamental trade-off: prioritizing input-language consistency severely hampers reasoning quality, while prioritizing reasoning often leads to unintended language drift toward English. We address this challenge with LANG, a novel framework that leverages language-conditioned hints to guide exploration in non-English reasoning tasks. Our method incorporates two key mechanisms to prevent dependency on these hints: a progressive decay schedule that gradually withdraws scaffolding, and a language-adaptive switch that tailors learning horizons to specific language difficulties. Empirical results on challenging multilingual mathematical benchmarks reveal that LANG substantially enhances reasoning performance without compromising language consistency. Moreover, we show that our framework generalizes beyond mathematics, fostering more consistent language alignment across model layers
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LANG, a reinforcement learning framework for enhancing multilingual reasoning in LLMs. It uses language-conditioned hints to guide exploration on non-English tasks, incorporating a progressive decay schedule to withdraw scaffolding and a language-adaptive switch to tailor learning horizons to language-specific difficulties. The central empirical claim is that this approach yields substantial gains on multilingual mathematical benchmarks while preserving language consistency, with additional generalization beyond mathematics to consistent language alignment across model layers.
Significance. If the empirical results and ablations hold, the work would be significant for multilingual NLP and RL-based reasoning, as it directly targets the documented trade-off between language consistency and reasoning quality that limits existing methods. The decay and adaptive-switch mechanisms provide a concrete way to scaffold RL without creating permanent inference-time dependence, which could inform broader applications of RL to low-resource languages.
major comments (2)
- [Abstract] Abstract: the claim that LANG 'substantially enhances reasoning performance without compromising language consistency' is presented without any baselines, metrics, statistical tests, or ablation results. This prevents assessment of whether the reported gains are attributable to the progressive decay schedule and language-adaptive switch or simply to the underlying RL objective.
- [Experimental Results] Experimental section (and associated ablations): the central claim requires that language-conditioned hints can be withdrawn via progressive decay and the language-adaptive switch without loss of reasoning gains or reintroduction of drift. No ablation isolating these two mechanisms from the base RL objective is described, leaving open the possibility that the policy either collapses to English-centric reasoning or retains hidden hint dependence at inference time if the decay schedule is too rapid relative to non-English learning rates.
minor comments (2)
- [Introduction] The motivation section would benefit from a short quantitative illustration of the consistency-reasoning trade-off using numbers from prior multilingual RL work.
- [Method] Notation for the language-adaptive switch and decay schedule should be defined more formally (e.g., as explicit functions of language difficulty) rather than described at a high level.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript. We address each major comment in detail below, clarifying the existing evidence in the paper while committing to targeted revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that LANG 'substantially enhances reasoning performance without compromising language consistency' is presented without any baselines, metrics, statistical tests, or ablation results. This prevents assessment of whether the reported gains are attributable to the progressive decay schedule and language-adaptive switch or simply to the underlying RL objective.
Authors: We agree that the abstract, due to length constraints, presents the high-level claim without quantitative anchors. The full manuscript (Section 4 and Appendix) reports concrete results against multiple baselines: standard RL without hints, English-centric RL, and multilingual SFT. On multilingual math benchmarks, LANG yields 12-18% absolute accuracy gains for non-English languages while achieving >94% input-language consistency (measured as the fraction of responses remaining in the prompt language), with significance established via 5 independent seeds and paired t-tests (p<0.01). Ablations in Section 5.2 already isolate the decay schedule and adaptive switch from the base RL objective. To improve immediate readability, we will revise the abstract to include one representative quantitative result and a brief reference to the ablation findings. revision: yes
-
Referee: [Experimental Results] Experimental section (and associated ablations): the central claim requires that language-conditioned hints can be withdrawn via progressive decay and the language-adaptive switch without loss of reasoning gains or reintroduction of drift. No ablation isolating these two mechanisms from the base RL objective is described, leaving open the possibility that the policy either collapses to English-centric reasoning or retains hidden hint dependence at inference time if the decay schedule is too rapid relative to non-English learning rates.
Authors: We share the referee's emphasis on rigorously isolating the withdrawal mechanisms. Our existing ablations (Table 3) compare the full LANG framework to (i) constant-hint RL (no decay) and (ii) fixed-horizon RL (no adaptive switch). These variants exhibit either persistent inference-time hint dependence or measurable language drift on harder languages. To further isolate from the base RL objective, we will add a new row in the ablation table that trains a pure RL policy with no language-conditioned hints at all. We will also report inference-time metrics confirming that hints are fully removed and that performance does not degrade relative to the scaffolded phase. This addition will directly address concerns about collapse to English-centric reasoning or residual hint reliance. revision: yes
Circularity Check
No circularity; empirical claims rest on benchmark results
full rationale
The provided abstract and description contain no equations, derivations, or load-bearing self-citations. LANG is presented as a framework with two mechanisms (progressive decay schedule and language-adaptive switch) whose effectiveness is asserted via empirical results on multilingual math benchmarks. No step reduces a prediction or result to a fitted input or self-referential definition by construction. The central claims are externally falsifiable against reported performance metrics and do not rely on uniqueness theorems or ansatzes imported from prior author work. This is a standard non-circular empirical RL paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
progressive decay schedule that gradually withdraws scaffolding, and a language-adaptive switch that tailors learning horizons to specific language difficulties
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Cosine decay schedule... pl_t = 1/2 (1 + cos(π t / T))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Scheduled sampling for sequence prediction with recurrent neural networks , author=. Advances in neural information processing systems , volume=
-
[2]
Glancing transformer for non-autoregressive neural machine translation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[3]
mGRPO: Unlocking LLM Reasoning through Multilingual Thinking , author = "Linjuan Wu, Hao-Ran Wei, Jialong Tang, Shuang Luo, Baosong Yang, Fei Huang, Yongliang Shen, Weiming Lu", url =
-
[4]
Zhang, Wen and Feng, Yang and Meng, Fandong and You, Di and Liu, Qun. Bridging the Gap between Training and Inference for Neural Machine Translation. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1426
-
[5]
arXiv preprint arXiv:2603.04597 , year=
Bootstrapping Exploration with Group-Level Natural Language Feedback in Reinforcement Learning , author=. arXiv preprint arXiv:2603.04597 , year=
-
[6]
Language-Specific Layer Matters: Efficient Multilingual Enhancement for Large Vision-Language Models
Fan, Yuchun and Wang, Yilin and Mu, Yongyu and Huang, Lei and Li, Bei and Feng, Xiaocheng and Xiao, Tong and Zhu, JingBo. Language-Specific Layer Matters: Efficient Multilingual Enhancement for Large Vision-Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.666
-
[7]
SLAM : Towards Efficient Multilingual Reasoning via Selective Language Alignment
Fan, Yuchun and Mu, Yongyu and Wang, YiLin and Huang, Lei and Ruan, Junhao and Li, Bei and Xiao, Tong and Huang, Shujian and Feng, Xiaocheng and Zhu, Jingbo. SLAM : Towards Efficient Multilingual Reasoning via Selective Language Alignment. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[8]
arXiv preprint arXiv:2603.19097 , year=
DaPT: A Dual-Path Framework for Multilingual Multi-hop Question Answering , author=. arXiv preprint arXiv:2603.19097 , year=
-
[9]
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[10]
First Conference on Language Modeling , year=
Large Language Model is not a (Multilingual) Compositional Relation Reasoner , author=. First Conference on Language Modeling , year=
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Beyond Step Pruning: Information Theory Based Step-level Optimization for Self-Refining Large Language Models , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2026 , month=. doi:10.1609/aaai.v40i41.40798 , number=
-
[12]
Crosslingual Reasoning through Test-Time Scaling , journal =
Zheng. Crosslingual Reasoning through Test-Time Scaling , journal =. 2025 , url =. doi:10.48550/ARXIV.2505.05408 , eprinttype =. 2505.05408 , timestamp =
-
[13]
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning , author=. arXiv preprint arXiv:2502.14768 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Language Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes
Wang, Mingyang and Lange, Lukas and Adel, Heike and Ma, Yunpu and Str. Language Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.132
-
[15]
Lu, Junyu and Ma, Kai and Wang, Kaichun and Xiao, Kelaiti and Lee, Roy Ka-Wei and Xu, Bo and Yang, Liang and Lin, Hongfei. Is LLM an Overconfident Judge? Unveiling the Capabilities of LLM s in Detecting Offensive Language with Annotation Disagreement. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.293
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2501.12948 , eprinttype =. 2501.12948 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[17]
arXiv preprint arXiv:2504.18428 , year=
Polymath: Evaluating mathematical reasoning in multilingual contexts , author=. arXiv preprint arXiv:2504.18428 , year=
-
[18]
MMATH : A Multilingual Benchmark for Mathematical Reasoning
Luo, Wenyang and Zhao, Wayne Xin and Sha, Jing and Wang, Shijin and Wen, Ji-Rong. MMATH : A Multilingual Benchmark for Mathematical Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.598
-
[19]
When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy
Qi, Jirui and Chen, Shan and Xiong, Zidi and Fern \'a ndez, Raquel and Bitterman, Danielle and Bisazza, Arianna. When Models Reason in Your Language: Controlling Thinking Language Comes at the Cost of Accuracy. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1103
-
[20]
arXiv preprint arXiv:2505.15508 , year=
Multilingual Test-Time Scaling via Initial Thought Transfer , author=. arXiv preprint arXiv:2505.15508 , year=
-
[21]
arXiv preprint arXiv:2507.05418 , year=
Learn globally, speak locally: Bridging the gaps in multilingual reasoning , author=. arXiv preprint arXiv:2507.05418 , year=
-
[22]
arXiv preprint arXiv:2506.05850 , year=
Cross-lingual collapse: How language-centric foundation models shape reasoning in large language models , author=. arXiv preprint arXiv:2506.05850 , year=
-
[23]
arXiv preprint arXiv:2510.07300 , year=
Think Natively: Unlocking Multilingual Reasoning with Consistency-Enhanced Reinforcement Learning , author=. arXiv preprint arXiv:2510.07300 , year=
-
[24]
arXiv preprint arXiv:2510.02272 , year=
Parallel Scaling Law: Unveiling Reasoning Generalization through A Cross-Linguistic Perspective , author=. arXiv preprint arXiv:2510.02272 , year=
-
[25]
Efficient reinforcement finetuning via adaptive curriculum learning , author=. arXiv preprint arXiv:2504.05520 , year=
-
[26]
arXiv preprint arXiv:2510.09388 , year=
HINT: Helping Ineffective Rollouts Navigate Towards Effectiveness , author=. arXiv preprint arXiv:2510.09388 , year=
-
[27]
Song, Mingyang and Zheng, Mao and Li, Zheng and Yang, Wenjie and Luo, Xuan. F ast C u RL : Curriculum Reinforcement Learning with Stage-wise Context Scaling for Efficient Training R1-like Reasoning Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.470
-
[28]
arXiv preprint arXiv:2507.13266 , year=
Questa: Expanding reasoning capacity in llms via question augmentation , author=. arXiv preprint arXiv:2507.13266 , year=
-
[29]
Understanding the Repeat Curse in Large Language Models from a Feature Perspective
Yao, Junchi and Yang, Shu and Xu, Jianhua and Hu, Lijie and Li, Mengdi and Wang, Di. Understanding the Repeat Curse in Large Language Models from a Feature Perspective. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.406
-
[30]
StepHint: Multi-level Stepwise Hints Enhance Reinforcement Learning to Reason , author=. ArXiv , year=
-
[31]
Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning , author=. arXiv preprint arXiv:2504.11456 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl , author=. Notion Blog , year=
-
[35]
2025 , month = oct, url =
work page 2025
-
[36]
The Eleventh International Conference on Learning Representations,
Freda Shi and Mirac Suzgun and Markus Freitag and Xuezhi Wang and Suraj Srivats and Soroush Vosoughi and Hyung Won Chung and Yi Tay and Sebastian Ruder and Denny Zhou and Dipanjan Das and Jason Wei , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
work page 2023
- [37]
- [38]
-
[39]
The Twelfth International Conference on Learning Representations,
Hunter Lightman and Vineet Kosaraju and Yuri Burda and Harrison Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
-
[40]
OpenAI , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2303.08774 , eprinttype =. 2303.08774 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
- [41]
-
[42]
arXiv preprint arXiv:2507.02841 , year=
StepHint: Multi-level Stepwise Hints Enhance Reinforcement Learning to Reason , author=. arXiv preprint arXiv:2507.02841 , year=
-
[43]
Learning to Reason under Off-Policy Guidance , author=. 2025 , eprint=
work page 2025
-
[44]
arXiv preprint arXiv:2508.11408 , year=
On-policy rl meets off-policy experts: Harmonizing supervised fine-tuning and reinforcement learning via dynamic weighting , author=. arXiv preprint arXiv:2508.11408 , year=
-
[45]
arXiv preprint arXiv:2507.10628 , year=
Ghpo: Adaptive guidance for stable and efficient llm reinforcement learning , author=. arXiv preprint arXiv:2507.10628 , year=
-
[46]
arXiv preprint arXiv:2505.16984 , year =
Liu, Mingyang and Farina, Gabriele and Ozdaglar, Asuman , title =. arXiv preprint arXiv:2505.16984 , year =
-
[47]
arXiv preprint arXiv:2506.19767 , year=
SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning , author=. arXiv preprint arXiv:2506.19767 , year=
-
[48]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
XCOPA : A Multilingual Dataset for Causal Commonsense Reasoning
Ponti, Edoardo Maria and Glava s , Goran and Majewska, Olga and Liu, Qianchu and Vuli \'c , Ivan and Korhonen, Anna. XCOPA : A Multilingual Dataset for Causal Commonsense Reasoning. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.185
-
[50]
Diab and Veselin Stoyanov and Xian Li , title =
Xi Victoria Lin and Todor Mihaylov and Mikel Artetxe and Tianlu Wang and Shuohui Chen and Daniel Simig and Myle Ott and Naman Goyal and Shruti Bhosale and Jingfei Du and Ramakanth Pasunuru and Sam Shleifer and Punit Singh Koura and Vishrav Chaudhary and Brian O'Horo and Jeff Wang and Luke Zettlemoyer and Zornitsa Kozareva and Mona T. Diab and Veselin Stoy...
-
[51]
OpenCompass: A Universal Evaluation Platform for Foundation Models , author=
-
[52]
Generalized Slow Roll for Tensors
Samyam Rajbhandari and Jeff Rasley and Olatunji Ruwase and Yuxiong He , editor =. ZeRO: memory optimizations toward training trillion parameter models , booktitle =. 2020 , url =. doi:10.1109/SC41405.2020.00024 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00024 2020
-
[53]
arXiv preprint arXiv:2503.10497 , year=
Mmlu-prox: A multilingual benchmark for advanced large language model evaluation , author=. arXiv preprint arXiv:2503.10497 , year=
-
[54]
Crosslingual Generalization through Multitask Finetuning , author=. 2022 , eprint=
work page 2022
-
[55]
It's All in the Heads: Using Attention Heads as a Baseline for Cross-Lingual Transfer in Commonsense Reasoning , author=. 2021 , eprint=
work page 2021
- [56]
-
[57]
Nuo Chen and Ning Wu and Shining Liang and Ming Gong and Linjun Shou and Dongmei Zhang and Jia Li , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2312.04333 , eprinttype =. 2312.04333 , timestamp =
-
[58]
Yiran Zhao and Wenxuan Zhang and Guizhen Chen and Kenji Kawaguchi and Lidong Bing , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.18815 , eprinttype =. 2402.18815 , timestamp =
-
[59]
P - MME val: A Parallel Multilingual Multitask Benchmark for Consistent Evaluation of LLM s
Zhang, Yidan and Wan, Yu and Deng, Boyi and Yang, Baosong and Wei, Hao-Ran and Huang, Fei and Yu, Bowen and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren. P - MME val: A Parallel Multilingual Multitask Benchmark for Consistent Evaluation of LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 202...
-
[60]
Long Phan and Alice Gatti and Ziwen Han and Nathaniel Li and Josephina Hu and Hugh Zhang and Sean Shi and Michael Choi and Anish Agrawal and Arnav Chopra and Adam Khoja and Ryan Kim and Jason Hausenloy and Oliver Zhang and Mantas Mazeika and Daron Anderson and Tung Nguyen and Mobeen Mahmood and Fiona Feng and Steven Y. Feng and Haoran Zhao and Michael Yu ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.14249 2025
-
[61]
Levesque and Ernest Davis and Leora Morgenstern , editor =
Hector J. Levesque and Ernest Davis and Leora Morgenstern , editor =. The Winograd Schema Challenge , booktitle =. 2012 , url =
work page 2012
-
[62]
Melissa Roemmele and Cosmin Adrian Bejan and Andrew S. Gordon , title =. Logical Formalizations of Commonsense Reasoning, Papers from the 2011. 2011 , url =
work page 2011
-
[63]
Few-shot Learning with Multilingual Generative Language Models
Lin, Xi Victoria and Mihaylov, Todor and Artetxe, Mikel and Wang, Tianlu and Chen, Shuohui and Simig, Daniel and Ott, Myle and Goyal, Naman and Bhosale, Shruti and Du, Jingfei and Pasunuru, Ramakanth and Shleifer, Sam and Koura, Punit Singh and Chaudhary, Vishrav and O ' Horo, Brian and Wang, Jeff and Zettlemoyer, Luke and Kozareva, Zornitsa and Diab, Mon...
-
[64]
A Corpus and Cloze Evaluation for Deeper Understanding of Commonsense Stories
Mostafazadeh, Nasrin and Chambers, Nathanael and He, Xiaodong and Parikh, Devi and Batra, Dhruv and Vanderwende, Lucy and Kohli, Pushmeet and Allen, James. A Corpus and Cloze Evaluation for Deeper Understanding of Commonsense Stories. Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human ...
-
[65]
AI@Meta , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[66]
Liang Wen and Yunke Cai and Fenrui Xiao and Xin He and Qi An and Zhenyu Duan and Yimin Du and Junchen Liu and Lifu Tang and Xiaowei Lv and Haosheng Zou and Yongchao Deng and Shousheng Jia and Xiangzheng Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.10460 , eprinttype =. 2503.10460 , timestamp =
-
[67]
Shuaijie She and Wei Zou and Shujian Huang and Wenhao Zhu and Xiang Liu and Xiang Geng and Jiajun Chen , editor =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V1/2024.ACL-LONG.539 , timestamp =
-
[68]
Swaroop Mishra and Arindam Mitra and Neeraj Varshney and Bhavdeep Singh Sachdeva and Peter Clark and Chitta Baral and Ashwin Kalyan , editor =. NumGLUE:. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2022 , url =. doi:10.18653/V1/2022.ACL-LONG.246 , timestamp =
-
[69]
Claude Opus 4.5 , year =
-
[70]
Marta R. Costa. No Language Left Behind: Scaling Human-Centered Machine Translation , journal =. 2022 , url =. doi:10.48550/ARXIV.2207.04672 , eprinttype =. 2207.04672 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.04672 2022
-
[71]
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and YuYue and Weinan Dai and Tiantian Fan and Gaohong Liu and Juncai Liu and LingJun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Ru Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and ...
work page 2025
-
[72]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng and Yuzhen Huang and Qian Liu and Wei Liu and Keqing He and Zejun Ma and Junxian He , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.18892 , eprinttype =. 2503.18892 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.18892 2025
-
[73]
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
Kanishk Gandhi and Ayush Chakravarthy and Anikait Singh and Nathan Lile and Noah D. Goodman , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.01307 , eprinttype =. 2503.01307 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.01307 2025
-
[74]
Lei Huang and Weijiang Yu and Weitao Ma and Weihong Zhong and Zhangyin Feng and Haotian Wang and Qianglong Chen and Weihua Peng and Xiaocheng Feng and Bing Qin and Ting Liu , title =. 2025 , url =. doi:10.1145/3703155 , timestamp =
-
[75]
Learning Fine-Grained Grounded Citations for Attributed Large Language Models , booktitle =
Lei Huang and Xiaocheng Feng and Weitao Ma and Yuxuan Gu and Weihong Zhong and Xiachong Feng and Weijiang Yu and Weihua Peng and Duyu Tang and Dandan Tu and Bing Qin , editor =. Learning Fine-Grained Grounded Citations for Attributed Large Language Models , booktitle =. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-ACL.838 , timestamp =
-
[76]
Lei Huang and Xiaocheng Feng and Weitao Ma and Yuchun Fan and Xiachong Feng and Yangfan Ye and Weihong Zhong and Yuxuan Gu and Baoxin Wang and Dayong Wu and Guoping Hu and Bing Qin , editor =. Improving Contextual Faithfulness of Large Language Models via Retrieval Heads-Induced Optimization , booktitle =. 2025 , url =
work page 2025
-
[77]
Lei Huang and Xiaocheng Feng and Weitao Ma and Yuchun Fan and Xiachong Feng and Yuxuan Gu and Yangfan Ye and Liang Zhao and Weihong Zhong and Baoxin Wang and Dayong Wu and Guoping Hu and Lingpeng Kong and Tong Xiao and Ting Liu and Bing Qin , editor =. Alleviating Hallucinations from Knowledge Misalignment in Large Language Models via Selective Abstention...
work page 2025
-
[78]
Advancing Large Language Model Attribution through Self-Improving , booktitle =
Lei Huang and Xiaocheng Feng and Weitao Ma and Liang Zhao and Yuchun Fan and Weihong Zhong and Dongliang Xu and Qing Yang and Hongtao Liu and Bing Qin , editor =. Advancing Large Language Model Attribution through Self-Improving , booktitle =. 2024 , url =. doi:10.18653/V1/2024.EMNLP-MAIN.223 , timestamp =
-
[79]
Chen, Hao and Yan, Yukun and Mei, Sen and Che, Wanxiang and Liu, Zhenghao and Shi, Qi and Li, Xinze and Fan, Yuchun and Huang, Pengcheng and Xiong, Qiushi and Liu, Zhiyuan and Sun, Maosong. C lue A nchor: Clue-Anchored Knowledge Reasoning Exploration and Optimization for Retrieval-Augmented Generation. Findings of the Association for Computational Linguis...
-
[80]
arXiv preprint arXiv:2602.12996 , year=
Know More, Know Clearer: A Meta-Cognitive Framework for Knowledge Augmentation in Large Language Models , author=. arXiv preprint arXiv:2602.12996 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.