PILOT: Policy-Informed Learned Optimization for Adaptive Deep Network Training
Pith reviewed 2026-06-30 14:21 UTC · model grok-4.3
The pith
An optimizer adapts its update rule during training by tracking gradient direction agreement to match shifting stability in the loss landscape.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PILOT uses gradient-direction agreement as a real-time signal of local training stability to condition an online policy that selects among momentum, normalization, and sign-based update components, thereby adjusting its behavior when gradients move between stable, noisy, and inconsistent regimes and attaining the highest accuracies among tested methods on FashionMNIST and CIFAR-10 for both CNN and ResNet-18 models.
What carries the argument
Gradient-direction agreement signal that drives an online policy to select the combination of update components at each step.
If this is right
- PILOT records the highest accuracy of the compared optimizers on both the CNN and ResNet-18 architectures.
- It reaches 94.13 percent on FashionMNIST and 81.94 percent on CIFAR-10 with the CNN model.
- With ResNet-18 the figures rise to 95.71 percent on FashionMNIST and 93.42 percent on CIFAR-10.
- The adaptation occurs inside a standard first-order framework without added complexity.
Where Pith is reading between the lines
- The same agreement signal could be grafted onto existing optimizers such as Adam or momentum SGD to test whether their performance also improves.
- If the signal generalizes, the method may reduce the amount of manual optimizer tuning required when moving to new tasks.
- Direct tests on non-convolutional models would show whether the stability indicator remains useful outside image data.
Load-bearing premise
Gradient direction agreement provides a reliable enough indicator of local training stability to safely condition changes in the update rule without introducing new instabilities or needing dataset-specific tuning.
What would settle it
An ablation that removes the agreement-based conditioning while keeping every other element of PILOT identical, then measures whether the accuracy advantage over fixed optimizers vanishes on the same CNN and ResNet-18 runs.
Figures
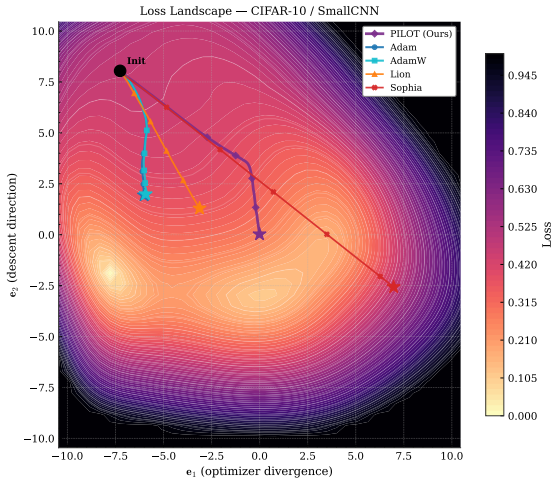
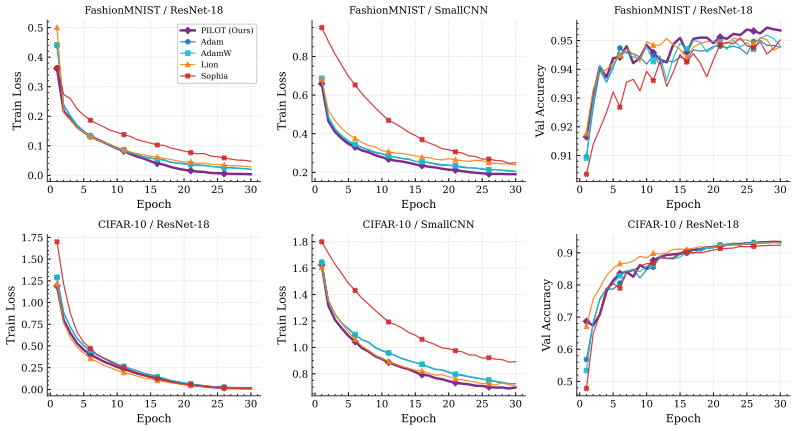
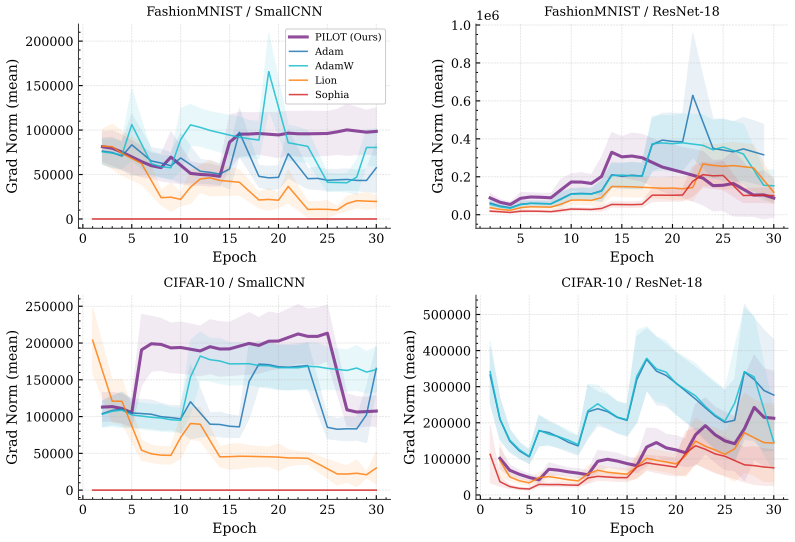
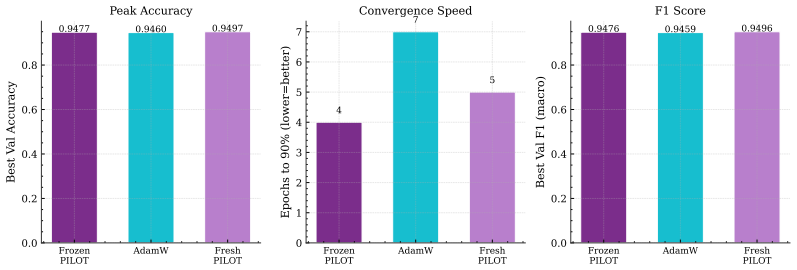
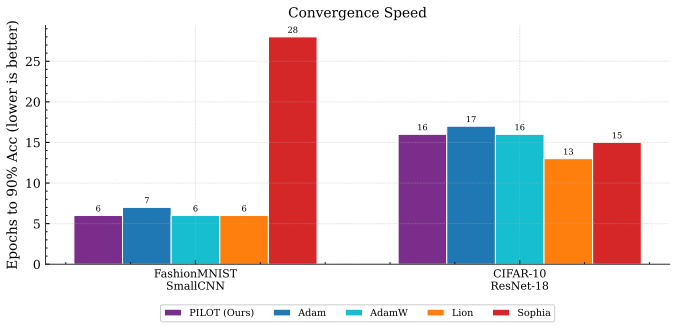
read the original abstract
Despite the central role of optimization in deep learning, most optimizers rely on update structures whose functional form is fixed before training begins. This static design can limit their ability to respond to changing gradient behavior across the loss landscape, where training may shift between stable, noisy, and inconsistent regimes. This study proposes PILOT (Policy-Informed Learned OpTimizer), an online optimizer that adapts its update behavior during training. Rather than using a fixed balance between momentum, normalization, and sign-based updates, PILOT uses gradient-direction agreement as a signal of local training stability. Conditioning the update rule on this agreement signal allows the optimizer to adjust its behavior when gradients become stable, noisy, or inconsistent. Experiments on FashionMNIST and CIFAR-10 show that PILOT consistently achieves the highest accuracy among the evaluated optimizers across convolutional settings. On the CNN architecture, PILOT reaches 94.13% on FashionMNIST and 81.94% on CIFAR-10. On ResNet-18, it further improves performance, reaching 95.71% on FashionMNIST and 93.42% on CIFAR-10. These results suggest that learning how to adapt the update structure during training can improve performance across both compact and deeper convolutional models while preserving a simple first-order optimization framework. The implementation of PILOT is publicly available at https://github.com/SattamAltwaim/PILOT.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PILOT, a first-order optimizer that dynamically adapts its update rule (balancing momentum, normalization, and sign-based steps) during training by conditioning on a gradient-direction agreement signal as a proxy for local stability. Experiments on FashionMNIST and CIFAR-10 with a CNN and ResNet-18 report that PILOT achieves the highest test accuracies among compared optimizers (94.13% and 81.94% on CNN; 95.71% and 93.42% on ResNet-18).
Significance. If the adaptation mechanism proves robust and the performance gains are reproducible, the approach could offer a lightweight way to improve optimizer behavior across training regimes without moving to fully learned or second-order methods.
major comments (2)
- [Abstract] Abstract and reported results: specific accuracy figures are stated without any accompanying experimental details (run counts, random seeds, variance, hyperparameter search protocol, or statistical tests), preventing assessment of whether the numbers support the claim of consistent superiority.
- [Experiments] Experiments section: the central claim that gradient-direction agreement is a reliable and sufficient signal for driving accuracy gains lacks an ablation that disables or replaces this conditioning while holding the rest of the update structure fixed. Without such a control, improvements cannot be attributed to the proposed mechanism rather than other fixed components or tuning choices.
minor comments (2)
- The manuscript should supply the explicit functional form of the conditioned update rule and any learned policy parameters.
- Add error bars or standard deviations to all reported accuracies and include at least one additional baseline (e.g., AdamW or a simple sign-based method) for completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments identify key areas where additional clarity and validation are needed to support the claims. We address each major comment below and will incorporate revisions in the updated version of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract and reported results: specific accuracy figures are stated without any accompanying experimental details (run counts, random seeds, variance, hyperparameter search protocol, or statistical tests), preventing assessment of whether the numbers support the claim of consistent superiority.
Authors: We agree that the abstract would benefit from additional context on the experimental protocol. In the revised manuscript, we will expand the abstract with a brief statement on the number of runs, random seeds, and variance measures. We will also ensure the experiments section provides complete details on the hyperparameter search protocol and any statistical comparisons performed, allowing readers to evaluate the robustness of the reported results. revision: yes
-
Referee: [Experiments] Experiments section: the central claim that gradient-direction agreement is a reliable and sufficient signal for driving accuracy gains lacks an ablation that disables or replaces this conditioning while holding the rest of the update structure fixed. Without such a control, improvements cannot be attributed to the proposed mechanism rather than other fixed components or tuning choices.
Authors: We concur that an ablation isolating the gradient-direction agreement signal is essential to substantiate the central claim. In the revised experiments section, we will include a control experiment in which the conditioning on gradient agreement is disabled or replaced by a fixed or random signal, while holding all other components of the update rule constant. The results will be presented to demonstrate the specific contribution of the proposed adaptation mechanism. revision: yes
Circularity Check
No derivation chain or equations present; empirical proposal only
full rationale
The provided manuscript text consists solely of an abstract describing an empirical optimizer (PILOT) that conditions updates on gradient-direction agreement, followed by accuracy numbers on FashionMNIST and CIFAR-10. No equations, derivation steps, fitted parameters presented as predictions, self-citations, or ansatzes are visible. The central claims rest on experimental comparisons rather than any mathematical reduction that could be inspected for circularity. This is the expected self-contained case for an applied optimizer paper without a claimed first-principles derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Optimizing deep learning models: A review
Abdelkader Belhadri and Ibtissam Benchennane. Optimizing deep learning models: A review. Multiagent and Grid Systems, 21(2):73–95, 2025
2025
-
[2]
Do ˘gay Altınel. Development of deep learning optimizers: Approaches, concepts, and update rules.arXiv preprint arXiv:2509.18396, 2025
-
[3]
Recent advances in optimization methods for machine learning: a systematic review.Mathematics, 13(13):2210, 2025
Xiaodong Liu, Huaizhou Qi, Suisui Jia, Yongjing Guo, and Yang Liu. Recent advances in optimization methods for machine learning: a systematic review.Mathematics, 13(13):2210, 2025
2025
-
[4]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations, 2015
2015
-
[5]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[6]
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Yao Liu, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, and Quoc V . Le. Symbolic discov- ery of optimization algorithms. InAdvances in Neural Information Processing Systems, vol- ume 36, 2023
2023
-
[7]
Sophia: A scalable stochastic second-order optimizer for language model pre-training
Hong Liu, Zhiyuan Li, David Leo Wright Hall, Percy Liang, and Tengyu Ma. Sophia: A scalable stochastic second-order optimizer for language model pre-training. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[8]
Learning to learn by gradient descent by gradient descent.Advances in neural information processing systems, 29, 2016
Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthew W Hoffman, David Pfau, Tom Schaul, Brendan Shillingford, and Nando De Freitas. Learning to learn by gradient descent by gradient descent.Advances in neural information processing systems, 29, 2016
2016
-
[9]
Neural optimizer search with reinforcement learning
Irwan Bello, Barret Zoph, Vijay Vasudevan, and Quoc V Le. Neural optimizer search with reinforcement learning. InInternational Conference on Machine Learning, pages 459–468. PMLR, 2017
2017
-
[10]
Adabelief optimizer: Adapting stepsizes by the belief in observed gradients.Advances in neural information processing systems, 33:18795–18806, 2020
Juntang Zhuang, Tommy Tang, Yifan Ding, Sekhar C Tatikonda, Nicha Dvornek, Xenophon Papademetris, and James Duncan. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients.Advances in neural information processing systems, 33:18795–18806, 2020
2020
-
[11]
signsgd: Compressed optimisation for non-convex problems
Jeremy Bernstein, Yu-Xiang Wang, Kamyar Azizzadenesheli, and Animashree Anandkumar. signsgd: Compressed optimisation for non-convex problems. InInternational conference on machine learning, pages 560–569. PMLR, 2018. 12
2018
-
[12]
Adahessian: An adaptive second order optimizer for machine learning
Zhewei Yao, Amir Gholami, Sheng Shen, Mustafa Mustafa, Kurt Keutzer, and Michael Ma- honey. Adahessian: An adaptive second order optimizer for machine learning. Inproceedings of the AAAI conference on artificial intelligence, volume 35, pages 10665–10673, 2021
2021
-
[13]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for bench- marking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[15]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 770–778, 2016. 13 A Additional Method Details A.1 PILOT Algorithm Algorithm 1 summarizes the training procedure of PILOT. At each iteration, the optimizer computes the...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.