Why Prompt Optimization Works, and Why It Sometimes Doesn't: A Causal-Inspired Edit-Level Analysis
Pith reviewed 2026-06-29 18:24 UTC · model grok-4.3
The pith
Prompt optimization succeeds or fails based on how edit types align with task demands rather than randomly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that prompt optimization failures arise from systematic interactions between edit families and task characteristics rather than random optimization artifacts. Complexity-increasing and meta-instructional edits are negatively associated with mathematical and multi-hop reasoning performance, whereas step-by-step and meta-cognitive edits improve logical and sequential reasoning tasks. These effects prove robust across cognitive-load annotations, surface-level text features, and edit-motif analyses, and generalize across optimization frameworks.
What carries the argument
Propensity-adjusted associational analysis with multiple complementary representations of prompt edits to identify consistent task-conditioned edit patterns.
If this is right
- Complexity-increasing edits reduce performance on mathematical and multi-hop reasoning tasks.
- Step-by-step edits improve performance on logical and sequential reasoning tasks.
- The observed edit patterns remain stable across different optimization frameworks and LLM backbones.
- Task-conditioned optimizer designs can reduce performance heterogeneity.
Where Pith is reading between the lines
- Optimizers could first classify a task's reasoning demands before selecting edit strategies.
- The same edit-level lens might uncover patterns in related techniques such as chain-of-thought generation.
- Task-specific edit rules might lower the number of trials needed for effective optimization.
Load-bearing premise
The observational analysis can separate systematic edit-task interactions from random performance variation.
What would settle it
Finding no consistent association between specific edit families and performance differences when controlling for task type across multiple benchmarks.
Figures
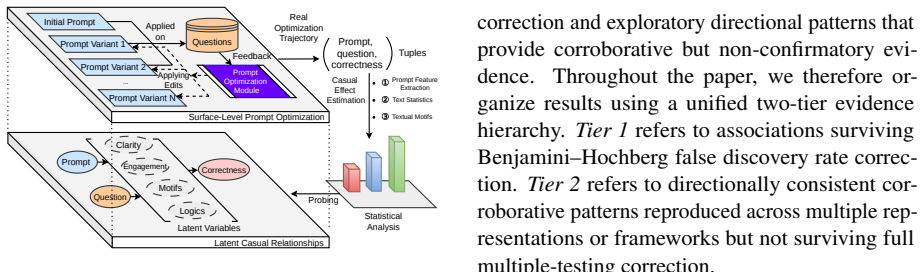
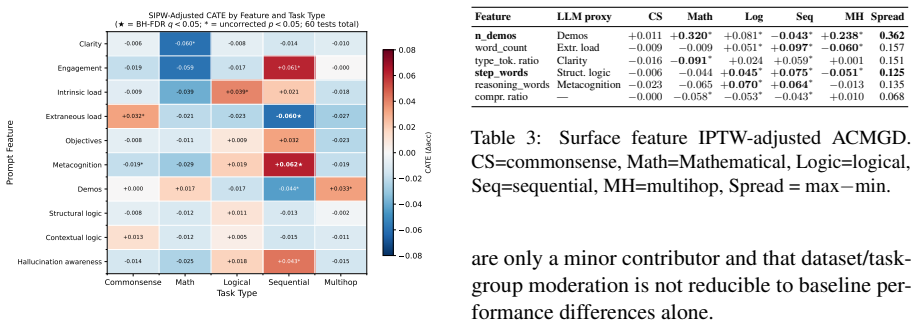
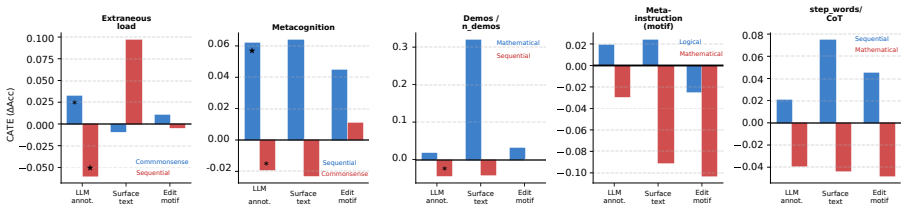
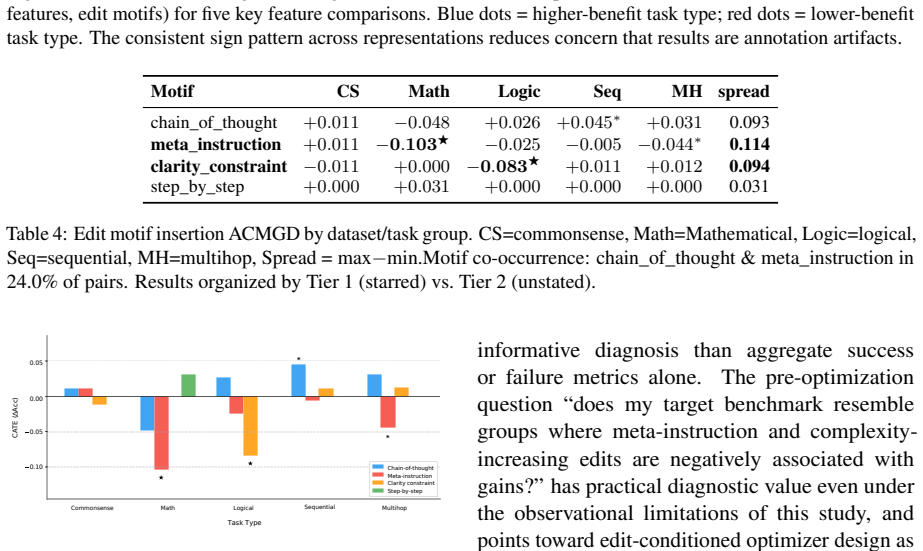
read the original abstract
Automated prompt optimization methods (e.g., DSpy, TextGrad) can substantially improve the performance of large language model (LLM), however, their generalization ability across different tasks remains underperformed. In practice, the superiority of the optimized prompt on one benchmark often fails to transfer to another, and this limitation persists even when switching across different LLM backbones. To investigate the underexplored sources of heterogeneity in prompt performance, we conduct a causal inference-inspired observational analysis of optimized prompts across a diverse set of optimization frameworks, LLM backbones, and NLP benchmarks. To achieve the goal, we build upon the propensity-adjusted associational analysis together with multiple complementary representations of prompt edits, where the consistent task-conditioned edits patterns are identified. We find that complexity-increasing and meta-instructional edits are negatively associated with mathematical and multi-hop reasoning performance, whereas step-by-step and meta-cognitive edits improve logical and sequential reasoning tasks. These effects are robust across cognitive-load annotations, surface-level text features, and edit-motif analyses, and can generalize across optimization frameworks. Overall, these results indicate that prompt optimization failures arise from systematic interactions between edit families and task characteristics rather than random optimization artifacts, providing feature-level characterization of optimizer behavior and motivating future task-conditioned optimizer design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript performs an observational analysis of prompt edits produced by automated optimizers (e.g., DSPy, TextGrad) across multiple LLM backbones and NLP benchmarks. Using propensity-adjusted associational methods together with several complementary representations of edits (cognitive-load annotations, surface features, edit motifs), the authors identify task-conditioned patterns: complexity-increasing and meta-instructional edits correlate negatively with mathematical and multi-hop reasoning performance, while step-by-step and meta-cognitive edits correlate positively with logical and sequential reasoning tasks. They conclude that optimization failures arise from these systematic edit-task interactions rather than random artifacts, and that the patterns generalize across frameworks.
Significance. If the reported associations prove robust, the work supplies a concrete, feature-level characterization of optimizer behavior that directly motivates task-conditioned prompt optimization. The explicit use of multiple edit representations and cross-framework robustness checks is a methodological strength that goes beyond single-benchmark case studies.
major comments (2)
- [Abstract] Abstract: the headline claim that 'prompt optimization failures arise from systematic interactions between edit families and task characteristics rather than random optimization artifacts' is not licensed by the stated method (propensity-adjusted associational analysis). The analysis can document correlations but cannot distinguish causation from confounding by task difficulty, optimizer heuristics, or unmeasured prompt-generation biases; this interpretive gap is load-bearing for the central conclusion.
- [Abstract / §3] Abstract / §3 (method description): the manuscript does not report the covariate set used for propensity-score estimation or any sensitivity analysis for unmeasured confounding. Without these details it is impossible to evaluate whether the adjustment addresses the reverse-causation and selection-bias concerns raised by the associational design.
minor comments (2)
- [Abstract] The abstract would be clearer if it stated the exact number of optimization frameworks, LLM backbones, and benchmarks examined.
- [§4] Notation for edit families (e.g., 'complexity-increasing', 'meta-instructional') should be defined once in a table or appendix so that later motif analyses can be directly mapped to them.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract's interpretive language exceeds what the associational design supports and that key methodological details were omitted. Both points will be addressed through revisions. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'prompt optimization failures arise from systematic interactions between edit families and task characteristics rather than random optimization artifacts' is not licensed by the stated method (propensity-adjusted associational analysis). The analysis can document correlations but cannot distinguish causation from confounding by task difficulty, optimizer heuristics, or unmeasured prompt-generation biases; this interpretive gap is load-bearing for the central conclusion.
Authors: We agree that the analysis is observational and uses propensity-adjusted associational methods rather than causal identification. The phrasing 'arise from' in the abstract and conclusion overstates the evidence. In the revision we will replace this with 'are consistent with' or 'point toward' systematic edit-task interactions, while retaining the 'causal-inspired' framing only as a description of the analytical approach. This directly addresses the interpretive gap. revision: yes
-
Referee: [Abstract / §3] Abstract / §3 (method description): the manuscript does not report the covariate set used for propensity-score estimation or any sensitivity analysis for unmeasured confounding. Without these details it is impossible to evaluate whether the adjustment addresses the reverse-causation and selection-bias concerns raised by the associational design.
Authors: This is a valid criticism. The revised manuscript will explicitly list the covariate set (task difficulty proxies, optimizer identity, LLM backbone, benchmark category, and surface prompt features) and add a sensitivity analysis section reporting e-values and Rosenbaum bounds for the key associations. These additions will allow readers to assess residual confounding. revision: yes
Circularity Check
No significant circularity; analysis is observational on external data
full rationale
The paper conducts an observational study using propensity-adjusted associational analysis and edit representations on diverse external benchmarks, frameworks, and LLMs. No equations, fitted parameters presented as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described method. The central claim rests on identified patterns from independent data sources rather than reducing to its own inputs by construction, satisfying the default expectation of a non-circular empirical analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Propensity-adjusted associational analysis can identify consistent task-conditioned edit patterns from observational prompt data
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, and 1 others. 2026. Gepa: Reflective prompt evolution can outperform reinforcement learning. International Conference on Learning Representations
2026
-
[5]
Yoav Benjamini and Yosef Hochberg. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal statistical society: series B (Methodological), 57(1):289--300
1995
-
[6]
Arthur C \^a mara, Vincent Slot, and Jakub Zavrel. 2026. Self-optimizing multi-agent systems for deep research. arXiv preprint arXiv:2604.02988
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [7]
-
[8]
Yuefei Chen, Vivek K Singh, Jing Ma, and Ruixiang Tang. 2026 b . Counterbench: Evaluating and improving counterfactual reasoning in large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 30350--30358
2026
-
[9]
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. 2018. Double/debiased machine learning for treatment and structural parameters
2018
-
[10]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and 1 others. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [11]
-
[12]
Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric Xing, and Zhiting Hu. 2022. Rlprompt: Optimizing discrete text prompts with reinforcement learning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3369--3391
2022
-
[13]
Nikita Dhawan, Leonardo Cotta, Karen Ullrich, Rahul G Krishnan, and Chris J Maddison. 2024. End-to-end causal effect estimation from unstructured natural language data. Advances in Neural Information Processing Systems, 37:77165--77199
2024
-
[14]
Amir Feder, Katherine A Keith, Emaad Manzoor, Reid Pryzant, Dhanya Sridhar, Zach Wood-Doughty, Jacob Eisenstein, Justin Grimmer, Roi Reichart, Margaret E Roberts, and 1 others. 2022. Causal inference in natural language processing: Estimation, prediction, interpretation and beyond. Transactions of the Association for Computational Linguistics, 10:1138--1158
2022
-
[15]
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rockt \"a schel. 2023. Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Lucheng Fu, Ye Yu, Yiyang Wang, Yiqiao Jin, Haibo Jin, B Aditya Prakash, and Haohan Wang. 2026. Textreg: Mitigating prompt distributional overfitting via regularized text-space optimization. arXiv preprint arXiv:2605.21318
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making pre-trained language models better few-shot learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3816--3830
2021
- [18]
- [19]
-
[20]
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. 2021. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9:346--361
2021
- [21]
-
[22]
Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, and Yujiu Yang. 2024. Connecting large language models with evolutionary algorithms yields powerful prompt optimizers. In International Conference on Learning Representations, volume 2024, pages 34133--34156
2024
-
[23]
Ari Holtzman, Peter West, Vered Shwartz, Yejin Choi, and Luke Zettlemoyer. 2021. Surface form competition: Why the highest probability answer isn’t always right. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7038--7051
2021
-
[24]
Zhijing Jin, Jiarui Liu, Zhiheng Lyu, Mrinmaya Sachan, Rada Mihalcea, Mona Diab, David Ha, and 1 others. 2024. Can large language models infer causation from correlation? In International Conference on Learning Representations, volume 2024, pages 28663--28679
2024
-
[25]
Daniel Keysers, Nathanael Sch \"a rli, Nathan Scales, Hylke Buisman, Daniel Furrer, Sergii Kashubin, Nikola Momchev, Danila Sinopalnikov, Lukasz Stafiniak, Tibor Tihon, and 1 others. 2019. Measuring compositional generalization: A comprehensive method on realistic data. arXiv preprint arXiv:1912.09713
-
[26]
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Saiful Haq, Ashutosh Sharma, Thomas Joshi, Hanna Moazam, Heather Miller, and 1 others. 2024. Dspy: compiling declarative language model calls into state-of-the-art pipelines. In International Conference on Learning Representations, volume 2024, pages 54928--54958
2024
-
[27]
Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 conference on empirical methods in natural language processing, pages 3045--3059
2021
-
[28]
Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582--4597
2021
-
[29]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others. 2024. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Xiaoyu Liu, Paiheng Xu, Junda Wu, Jiaxin Yuan, Yifan Yang, Yuhang Zhou, Fuxiao Liu, Tianrui Guan, Haoliang Wang, Tong Yu, and 1 others. 2025. Large language models and causal inference in collaboration: A comprehensive survey. Findings of the Association for Computational Linguistics: NAACL 2025, pages 7668--7684
2025
-
[31]
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086--8098
2022
-
[32]
Jing Ma. 2025. Causal inference with large language model: A survey. Findings of the Association for Computational Linguistics: NAACL 2025, pages 5886--5898
2025
- [33]
-
[34]
Automatic prompt optimization for knowledge graph construction: Insights from an empirical study
Nandana Mihindukulasooriya, Niharika S D’Souza, Faisal Chowdhury, and Horst Samulowitz. Automatic prompt optimization for knowledge graph construction: Insights from an empirical study. Proceedings of the VLDB Endowment. ISSN, 2150:8097
-
[35]
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. Rethinking the role of demonstrations: What makes in-context learning work? In Proceedings of the 2022 conference on empirical methods in natural language processing, pages 11048--11064
2022
-
[36]
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. 2024 a . Optimizing instructions and demonstrations for multi-stage language model programs. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9340--9366
2024
-
[37]
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. 2024 b . Optimizing instructions and demonstrations for multi-stage language model programs. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9340--9366
2024
-
[38]
Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. 2023. Grips: Gradient-free, edit-based instruction search for prompting large language models. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 3845--3864
2023
-
[39]
gradient descent
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. 2023. Automatic prompt optimization with “gradient descent” and beam search. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 7957--7968
2023
-
[40]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 3982--3992
2019
-
[41]
James M Robins, Miguel Angel Hernan, and Babette Brumback. 2000. Marginal structural models and causal inference in epidemiology
2000
-
[42]
Paul R Rosenbaum and Donald B Rubin. 1983. The central role of the propensity score in observational studies for causal effects. Biometrika, 70(1):41--55
1983
-
[43]
Subhro Roy and Dan Roth. 2015. Solving general arithmetic word problems. In Proceedings of the 2015 conference on empirical methods in natural language processing, pages 1743--1752
2015
-
[44]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2024. Quantifying language models' sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. In International Conference on Learning Representations, volume 2024, pages 25055--25083
2024
-
[45]
Taylor Shin, Yasaman Razeghi, Robert L Logan Iv, Eric Wallace, and Sameer Singh. 2020. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 4222--4235
2020
- [46]
-
[47]
Teo Susnjak. 2026. A reproducible optimisation protocol for calibrating prompt-based large language model workflows in evidence synthesis. arXiv preprint arXiv:2605.06937
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Mirac Suzgun, Nathan Scales, Nathanael Sch \"a rli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, and 1 others. 2023. Challenging big-bench tasks and whether chain-of-thought can solve them. In Findings of the Association for Computational Linguistics: ACL 2023, pages 13003--13051
2023
-
[49]
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. Commonsenseqa: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149--4158
2019
-
[50]
Stefan Wager and Susan Athey. 2018. Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association, 113(523):1228--1242
2018
-
[51]
Xingchen Wan, Ruoxi Sun, Hootan Nakhost, and Sercan \"O Ar k. 2024. Teach better or show smarter? on instructions and exemplars in automatic prompt optimization. Advances in Neural Information Processing Systems, 37:58174--58244
2024
-
[52]
Ziao Wang, Xiaofeng Zhang, and Hongwei Du. 2024. Beyond what if: Advancing counterfactual text generation with structural causal modeling. In IJCAI, pages 6522--6530
2024
-
[53]
Albert Webson and Ellie Pavlick. 2022. Do prompt-based models really understand the meaning of their prompts? In Proceedings of the 2022 conference of the north american chapter of the association for computational linguistics: Human language technologies, pages 2300--2344
2022
-
[54]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
-
[55]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. 2024. Large language models as optimizers. In International Conference on Learning Representations, volume 2024, pages 12028--12068
2024
-
[57]
TextGrad: Automatic "Differentiation" via Text
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. 2024. Textgrad: Automatic" differentiation" via text. arXiv preprint arXiv:2406.07496
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [58]
-
[59]
Xing Zhang, Guanghui Wang, Yanwei Cui, Wei Qiu, Ziyuan Li, Bing Zhu, and Peiyang He. 2026. Prompt optimization is a coin flip: Diagnosing when it helps in compound ai systems. arXiv preprint arXiv:2604.14585
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improving few-shot performance of language models. In International conference on machine learning, pages 12697--12706. Pmlr
2021
-
[61]
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2022. Large language models are human-level prompt engineers. In The eleventh international conference on learning representations
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.