HiLSVA: Design and Evaluation of a Human-in-the-Loop Agentic System for Scientific Visualization
Pith reviewed 2026-06-26 03:48 UTC · model grok-4.3
The pith
HiLSVA combines LLM agents with explicit human oversight to support mixed-initiative scientific visualization workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
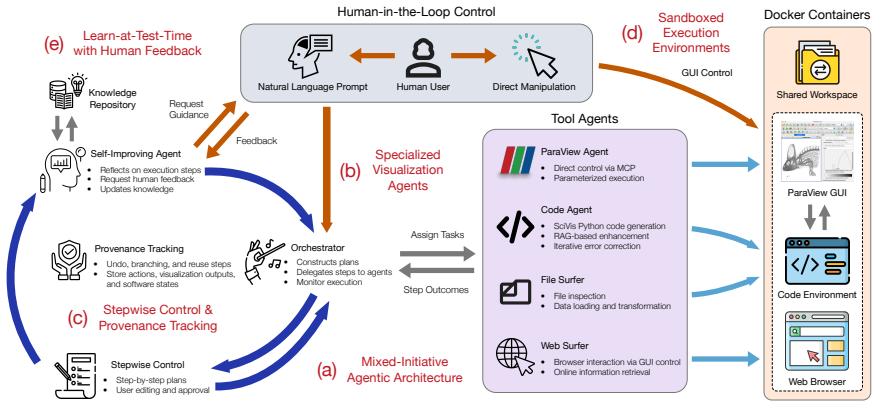
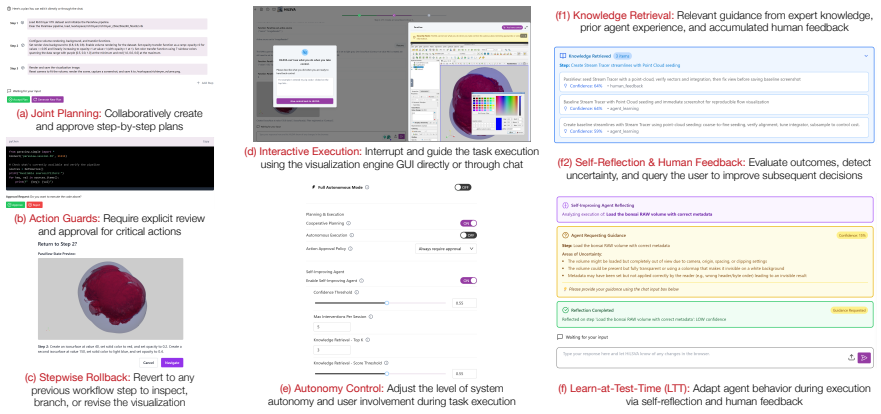
HiLSVA integrates a plan-first multi-agent architecture with explicit human oversight, stepwise provenance tracking, and learn-at-test-time adaptation from user feedback to enable mixed-initiative SciVis workflows that support natural language and direct manipulation handoffs while maintaining sandboxed, reproducible execution.
What carries the argument
Plan-first multi-agent architecture with explicit human oversight and stepwise provenance tracking that enables fluid handoff between humans and agents.
If this is right
- Mixed-initiative interaction raises task completion rates across novice, intermediate, and expert users.
- Explicit oversight and provenance tracking increase perceived user control and workflow transparency.
- Execution efficiency decreases as human oversight increases, creating a measurable tradeoff.
- Sandboxing and feedback-driven adaptation keep workflows safe and reproducible.
Where Pith is reading between the lines
- The same oversight mechanisms could apply to agentic systems outside scientific visualization, such as data analysis or design tools.
- Direct manipulation handoffs may reduce reliance on natural language prompts in time-sensitive tasks.
- Learn-at-test-time adaptation suggests future systems could personalize agent behavior without retraining.
Load-bearing premise
A controlled study with twelve participants of varying expertise is enough to show that mixed-initiative interaction improves control and transparency for the wider scientific visualization community.
What would settle it
A follow-up study with more participants or different visualization tasks that finds no measurable gain in user control or workflow transparency under mixed-initiative settings.
Figures





read the original abstract
Large language model (LLM) agents enable natural language interaction for scientific visualization (SciVis). Still, prior systems have essentially prioritized autonomy over human analytical control, thereby limiting transparency and human oversight. We present HiLSVA, a human-in-the-loop agentic system that supports mixed-initiative SciVis workflows. HiLSVA integrates a plan-first multi-agent architecture with explicit human oversight, stepwise provenance tracking, and learn-at-test-time adaptation from user feedback. The system supports fluid handoff between humans and agents through both natural language and direct manipulation of visualizations, while sandboxed execution ensures safe, reproducible workflows. In doing so, HiLSVA reframes agentic SciVis as a collaborative process that augments, rather than replaces, human analytical reasoning. We evaluate HiLSVA through representative case studies and a controlled user study with twelve participants of varying expertise across multiple autonomy settings. Results show that mixed-initiative interaction improves task completion, user control, and workflow transparency across different levels of user expertise, while revealing a tradeoff between execution efficiency and human oversight. These findings highlight the importance of human-centered design in agentic SciVis and guide the development of future collaborative visualization systems. We encourage readers to explore our demo video, case studies, and source code at https://hilsva.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HiLSVA, a human-in-the-loop agentic system for scientific visualization that employs a plan-first multi-agent architecture with explicit human oversight, stepwise provenance tracking, learn-at-test-time adaptation, natural language/direct manipulation handoffs, and sandboxed execution. It evaluates the system via representative case studies and a controlled user study with 12 participants of varying expertise across autonomy settings, claiming that mixed-initiative interaction improves task completion, user control, and workflow transparency while revealing an efficiency-oversight tradeoff.
Significance. If the evaluation holds after addressing statistical reporting, the work contributes to HCI and visualization by providing evidence-based guidance on collaborative agentic SciVis designs that augment rather than replace human reasoning. The open-source code, demo video, and case studies are explicit strengths supporting reproducibility and extension by the community.
major comments (2)
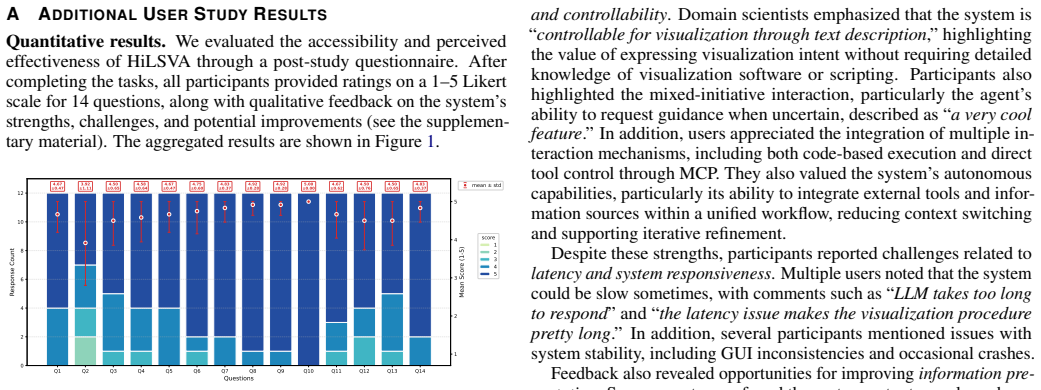
- [User Study] User Study section: The central claim that mixed-initiative interaction improves task completion, control, and transparency across expertise levels rests on results from n=12 participants. No effect sizes, p-values, confidence intervals, or power analysis are referenced, and the small sample precludes reliable subgroup analysis by expertise; this directly weakens support for the generalization statements in the abstract and conclusion.
- [Evaluation] Evaluation section: The study design description does not include details on task metrics, counterbalancing of autonomy conditions, or how expertise levels were operationalized and analyzed, making it impossible to verify whether the reported improvements are robust or attributable to the mixed-initiative features rather than other factors.
minor comments (1)
- The abstract and introduction could more clearly distinguish quantitative results from qualitative observations in the user study to aid readers in assessing evidence strength.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights opportunities to strengthen the statistical reporting and methodological transparency of our user study. We address each major comment below and commit to revisions that improve the rigor of the Evaluation section without altering the core claims or study design.
read point-by-point responses
-
Referee: [User Study] User Study section: The central claim that mixed-initiative interaction improves task completion, control, and transparency across expertise levels rests on results from n=12 participants. No effect sizes, p-values, confidence intervals, or power analysis are referenced, and the small sample precludes reliable subgroup analysis by expertise; this directly weakens support for the generalization statements in the abstract and conclusion.
Authors: We acknowledge the validity of this observation. The study was designed as an exploratory evaluation combining quantitative metrics with qualitative feedback rather than a confirmatory experiment powered for subgroup inference. In the revision we will add effect sizes and confidence intervals for all reported quantitative measures, include a post-hoc power discussion, and revise the abstract and conclusion to qualify generalization statements (e.g., “suggestive evidence across the sampled expertise range”). We will not fabricate p-values where the data do not support them. revision: yes
-
Referee: [Evaluation] Evaluation section: The study design description does not include details on task metrics, counterbalancing of autonomy conditions, or how expertise levels were operationalized and analyzed, making it impossible to verify whether the reported improvements are robust or attributable to the mixed-initiative features rather than other factors.
Authors: We agree that these details are necessary for reproducibility and causal attribution. The revised Evaluation section will explicitly define task metrics (completion time, error rate, NASA-TLX, and custom control/transparency scales), describe the counterbalancing procedure (Latin-square ordering of autonomy conditions), and specify how expertise was operationalized (self-reported years of visualization experience plus a short pre-study questionnaire) and analyzed (descriptive stratification rather than formal subgroup tests). revision: yes
Circularity Check
No significant circularity: system design and user-study evaluation paper contains no derivation chain or fitted predictions
full rationale
The paper describes a human-in-the-loop agentic system (HiLSVA) and reports results from case studies plus a controlled user study with twelve participants. No equations, parameter fitting, or first-principles derivations appear in the provided text. Claims about mixed-initiative improvements rest directly on the described architecture and empirical feedback rather than reducing to self-definitions, renamed inputs, or self-citation chains. The evaluation is externally falsifiable via the linked demo, code, and study protocol, satisfying the criteria for non-circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Explicit human oversight and provenance tracking improve analytical control and transparency in LLM-driven visualization workflows
invented entities (1)
-
HiLSVA system (plan-first multi-agent architecture with learn-at-test-time adaptation)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. P. Ahrens, B. Geveci, and C. C. Law. ParaView: An end-user tool for large-data visualization. In C. D. Hansen and C. R. Johnson, eds.,The Visualization Handbook, chap. 36, pp. 717–731. Academic Press, 2004. doi:10.1016/B978-012387582-2/50038-14
-
[2]
K. Ai, H. Miao, Z. Li, C. Wang, and S. Liu. An evaluation-centric paradigm for scientific visualization agents. InProc. IEEE VIS & GenAI, 2025. doi: 10.48550/arXiv.2509.151601, 3
-
[4]
K. Ai, H. Miao, K. Tang, S. Liu, and C. Wang. SciVisAgentSkills: Design and evaluation of agent skills for scientific data analysis and visualization. arXiv preprint arXiv:2606.05525, 2026. doi:10.48550/arXiv.2606.055252
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.055252 2026
-
[5]
K. Ai, K. Tang, and C. Wang. NLI4V olVis: Natural language interaction for volume visualization via multi-LLM agents and editable 3D Gaussian splatting.IEEE Trans. Vis. Comput. Graph., 32(1):46–56, 2026. doi: 10. 1109/TVCG.2025.36338881, 2, 3
arXiv 2026
-
[6]
Introducing computer use, a new Claude 3.5 Son- net, and Claude 3.5 Haiku
Anthropic. Introducing computer use, a new Claude 3.5 Son- net, and Claude 3.5 Haiku. https://www.anthropic.com/news/ 3-5-models-and-computer-use. 1, 2
-
[7]
G. Bansal, B. Nushi, E. Kamar, D. S. Weld, W. S. Lasecki, and E. Horvitz. Updates in human-AI teams: Understanding and addressing the perfor- mance/compatibility tradeoff. InProc. AAAI, pp. 2429–2437, 2019. doi: 10.1609/aaai.v33i01.330124292, 9
-
[8]
G. Bansal, J. W. Vaughan, S. Amershi, E. Horvitz, A. Fourney, H. Mozan- nar et al. Challenges in human-agent communication.arXiv preprint arXiv:2412.10380, 2024. doi:10.48550/arXiv.2412.103802, 9
- [9]
-
[10]
L. Bavoil, S. Callahan, P. Crossno, J. Freire, C. Scheidegger, C. Silva et al. VisTrails: enabling interactive multiple-view visualizations. InProc. IEEE VIS, pp. 135–142, 2005. doi:10.1109/VISUAL.2005.15327884
-
[11]
A. Biswas, T. L. Turton, N. R. Ranasinghe, S. Jones, B. Love, W. Jones et al. VizGenie: Toward self-refining, domain-aware workflows for next- generation scientific visualization.IEEE Trans. Vis. Comput. Graph., 32(1):1021–1031, 2026. doi:10.1109/TVCG.2025.36346551, 2, 3
-
[12]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal et al. Language models are few-shot learners. InProc. NeurIPS, pp. 1877–1901,
1901
-
[13]
Z. Chen, J. Chen, S. Ö. Arik, M. Sra, T. Pfister, and J. Yoon. CoDA: Agentic systems for collaborative data visualization.arXiv preprint arXiv:2510.03194, 2025. doi:10.48550/arXiv.2510.031942
-
[14]
N. Cliff. Dominance statistics: Ordinal analyses to answer ordinal ques- tions.Psychological Bulletin, 114(3):494–509, 1993. doi: 10.1037/0033 -2909.114.3.4949
- [15]
-
[16]
V . Dibia. LIDA: A tool for automatic generation of grammar-agnostic visualizations and infographics using large language models. InProc. ACL: System Demonstrations, pp. 113–126, 2023. doi: 10.18653/v1/2023. acl-demo.112
-
[17]
P. P. Do, K. Tang, K. Ai, and C. Wang. SVLAT: Scientific visualization literacy assessment test.arXiv preprint arXiv:2603.19000, 2026. doi: 10. 48550/arXiv.2603.190003
arXiv 2026
-
[19]
GMX-VMD-MCP: MCP service for GROMACS and VMD molec- ular dynamics simulations and visualization
EgT. GMX-VMD-MCP: MCP service for GROMACS and VMD molec- ular dynamics simulations and visualization. https://github.com/ egtai/gmx-vmd-mcp, 2025. 4
2025
-
[20]
J. Fang, Y . Peng, X. Zhang, Y . Wang, X. Yi, G. Zhang et al. A com- prehensive survey of self-evolving AI agents: A new paradigm bridg- ing foundation models and lifelong agentic systems.arXiv preprint arXiv:2508.07407, 2025. doi:10.48550/arXiv.2508.074072, 5
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.074072 2025
-
[21]
K. Feng, K. Pu, M. Latzke, T. August, P. Siangliulue, J. Bragg et al. Cocoa: Co-planning and co-execution with AI agents.arXiv preprint arXiv:2412.10999, 2024. doi:10.48550/arXiv.2412.109992, 3, 4
-
[22]
G. Fragiadakis, C. Diou, G. Kousiouris, and M. Nikolaidou. Evaluating human-AI collaboration: A review and methodological framework.arXiv preprint arXiv:2407.19098, 2024. doi:10.48550/arXiv.2407.190983
-
[23]
J. Freire, D. Koop, E. Santos, and C. T. Silva. Provenance for computa- tional tasks: A survey.IEEE Comput. Sci. Eng., 10(3):11–21, 2008. doi: 10.1109/MCSE.2008.794
-
[24]
N. Gorski, S. Liu, and B. Wang. TopoPilot: Reliable conversational workflow automation for topological data analysis and visualization.arXiv preprint arXiv:2603.25063, 2026. doi:10.48550/arXiv.2603.250632, 4
-
[25]
T. Guo, X. Chen, Y . Wang, R. Chang, S. Pei, N. V . Chawla et al. Large language model based multi-agents: A survey of progress and challenges. InProc. IJCAI, pp. 8048–8057, 2024. doi:10.24963/ijcai.2024/8902
-
[26]
Y . He, R. Li, A. Chen, Y . Liu, Y . Chen, Y . Sui et al. Enabling self- improving agents to learn at test time with human-in-the-loop guidance. InProc. EMNLP: Industry Track, pp. 1625–1653, 2025. doi: 10.18653/v1/ 2025.emnlp-industry.1155
-
[27]
E. Horvitz. Principles of mixed-initiative user interfaces. InProc. ACM CHI, pp. 159–166, 1999. doi:10.1145/302979.3030301, 2
-
[28]
S. Hu, C. Lu, and J. Clune. Automated design of agentic systems. InProc. ICLR, vol. 2025, pp. 21344–21377, 2025. doi: 10.48550/arXiv.2408.08435 9
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.08435 2025
-
[29]
X. Hu, T. Xiong, B. Yi, Z. Wei, R. Xiao, Y . Chen et al. OS Agents: A survey on MLLM-based agents for computer, phone and browser use. In Proc. ACL, pp. 7436–7465, 2025. doi:10.18653/v1/2025.acl-long.3691
-
[30]
J. Hübotter, S. Bongni, I. Hakimi, and A. Krause. Efficiently learning at test-time: Active fine-tuning of LLMs.arXiv preprint arXiv:2410.08020,
-
[31]
doi:10.48550/arXiv.2410.080205
-
[32]
VMD: Visual molecular dynamics , journal =
W. Humphrey, A. Dalke, and K. Schulten. VMD: Visual molecular dynam- ics.J. Mol. Graph., 14:33–38, 1996. doi: 10.1016/0263-7855(96)00018-5 4
-
[33]
F. Huq, Z. Z. Wang, F. F. Xu, T. Ou, S. Zhou, J. P. Bigham et al. CowPilot: A framework for autonomous and human-agent collaborative web naviga- tion. InProc. ACL: System Demonstrations, pp. 163–172, 2025. doi: 10. 18653/v1/2025.naacl-demo.172, 3, 4
2025
-
[34]
H. Jin, L. Huang, H. Cai, J. Yan, B. Li, and H. Chen. From LLMs to LLM- based agents for software engineering: A survey of current, challenges and future.arXiv preprint arXiv:2408.02479, 2024. doi: 10.48550/arXiv. 2408.024791
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[35]
M. G. Kendall and B. Babington Smith. The problem of m rankings. The Annals of Mathematical Statistics, 10(3):275–287, 1939. doi: 10. 1214/aoms/11777321869
arXiv 1939
-
[36]
J. Y . Koh, S. McAleer, D. Fried, and R. Salakhutdinov. Tree search for language model agents.arXiv preprint arXiv:2407.01476, 2024. doi: 10. 48550/arXiv.2407.014762
arXiv 2024
-
[37]
H. Lai, X. Liu, I. L. Iong, S. Yao, Y . Chen, P. Shen et al. AutoWebGLM: A large language model-based web navigating agent. InProc. ACM KDD, pp. 5295–5306, 2024. doi:10.1145/3637528.36716201
-
[38]
Y . Lee, R. Nair, Q. Zhang, K. Lee, O. Khattab, and C. Finn. Meta- harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052, 2026. doi:10.48550/arXiv.2603.280529
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.280529 2026
-
[39]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proc. NeurIPS, pp. 9459–9474, 2020. 5
2020
-
[40]
T. Li, G. Li, J. Zheng, P. Wang, and Y . Li. MUG: Interactive multimodal grounding on user interfaces. InProc. ACL Findings, pp. 231–251, 2024. doi:10.18653/v1/2024.findings-eacl.179
-
[41]
J. Liu, J. Hao, C. Zhang, and Z. Hu. WEPO: Web element preference optimization for LLM-based web navigation. InProc. AAAI, pp. 26614– 26622, 2025. doi:10.1609/aaai.v39i25.348631
-
[42]
J. Liu, K. Wang, Y . Chen, X. Peng, Z. Chen, L. Zhang et al. Large language model-based agents for software engineering: A survey.arXiv preprint arXiv:2409.02977, 2024. doi:10.48550/arXiv.2409.029771
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.029771 2024
-
[43]
S. Liu, H. Miao, and P.-T. Bremer. ParaView-MCP: An autonomous visualization agent with direct tool use. InProc. IEEE VIS (Short Papers), pp. 61–65, 2025. doi:10.48550/arXiv.2505.070641, 2, 4
-
[44]
S. Liu, H. Miao, Z. Li, M. Olson, V . Pascucci, and P.-T. Bremer. A V A: towards autonomous visualization agents through visual perception-driven decision-making.Comput. Graph. Forum, 43(3):e15093, 2024. doi: 10. 1111/cgf.150931, 2
2024
-
[45]
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
T. Masterman, S. Besen, M. Sawtell, and A. Chao. The landscape of emerging AI agent architectures for reasoning, planning, and tool calling: A survey.arXiv preprint arXiv:2404.11584, 2024. doi: 10.48550/arXiv.2404 .115842
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404 2024
-
[46]
M. Mathai, M. Han, J. Knowles, V . A. Mateevitsi, S. Rizzi, and H. Childs. NL2SciVis: A benchmark for natural language to scientific visualization. InProc. EuroVis (Short Papers), 2026. doi:10.2312/evs.202610173
-
[47]
H. Miao, Z. Li, K. Ai, K. Tang, C. Wang, P.-T. Bremer et al. Toward AI VIS co-scientists: A general and end-to-end agent harness for solving complex data visualization tasks.arXiv preprint arXiv:2605.21825, 2026. doi:10.48550/arXiv.2605.218252, 3
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.218252 2026
-
[48]
Miao and S
H. Miao and S. Liu. BioImage-Agent. https://github.com/LLNL/ bioimage-agent. 2, 4
-
[49]
H. Mozannar, G. Bansal, C. Tan, A. Fourney, V . Dibia, J. Chen et al. Magentic-UI: Towards human-in-the-loop agentic systems.arXiv preprint arXiv:2507.22358, 2025. doi:10.48550/arXiv.2507.223581, 2, 3, 4
-
[50]
Narechania, S
A. Narechania, S. Guo, E. Koh, A. Endert, and J. Hoffswell. Utilizing provenance as an attribute for visual data analysis: A design probe with provenancelens.IEEE Trans. Vis. Comput. Graph., 31(10):8452–8465,
-
[51]
doi:10.1109/TVCG.2025.35717084
-
[52]
J. Pan, Y . Zhang, N. Tomlin, Y . Zhou, S. Levine, and A. Suhr. Au- tonomous evaluation and refinement of digital agents.arXiv preprint arXiv:2404.06474, 2024. doi:10.48550/arXiv.2404.064742
-
[53]
S. Peng, E. Kalliamvakou, P. Cihon, and M. Demirer. The impact of AI on developer productivity: Evidence from GitHub Copilot.arXiv preprint arXiv:2302.06590, 2023. doi:10.48550/arXiv.2302.065902
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.065902 2023
-
[54]
T. Peterka, T. Mallick, O. Yildiz, D. Lenz, C. Quammen, and B. Geveci. ChatVis: Large language model agent for generating scientific visualiza- tions. InProc. IEEE LDAV, pp. 22–32, 2025. doi: 10.1109/LDAV68558.2025 .000071, 2, 4
-
[55]
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu et al. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InProc. ICLR,
-
[56]
doi:10.48550/arXiv.2307.167892
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.167892
-
[58]
T. Schick, J. Dwivedi-Yu, R. Dessi, R. Raileanu, M. Lomeli, E. Hambro et al. Toolformer: Language models can teach themselves to use tools. In Proc. NeurIPS, pp. 68539–68551, 2023. doi:10.5555/3666122.36691192
-
[59]
J. Senoner, S. Schallmoser, B. Kratzwald, S. Feuerriegel, and T. Netland. Explainable AI improves task performance in human–AI collaboration. Sci. Rep., 14(1):31150, 2024. doi:10.1038/s41598-024-82501-91, 2
-
[60]
Y . Shao, V . Samuel, Y . Jiang, J. Yang, and D. Yang. Collaborative Gym: A framework for enabling and evaluating human-agent collaboration.arXiv preprint arXiv:2412.15701, 2024. doi:10.48550/arXiv.2412.157013
-
[61]
B. Shneiderman and P. Maes. Direct manipulation vs. interface agents. Interactions, 4(6):42–61, 1997. doi:10.1145/267505.2675141, 2
-
[62]
Sofroniew, T
N. Sofroniew, T. Lambert, G. Bokota, J. Nunez-Iglesias, P. Sobolewski, A. Sweet et al. napari: A multi-dimensional image viewer for Python,
-
[63]
doi:10.5281/zenodo.35556204
-
[64]
P. Stone and M. Veloso. Multiagent systems: A survey from a machine learning perspective.Auton. Robots, 8(3):345–383, 2000. doi: 10.1023/A: 10089420122992
work page doi:10.1023/a: 2000
-
[65]
J. Sun, D. Lenz, T. Peterka, and H. Yu. SASA V: Self-directed agent for scientific analysis and visualization.arXiv preprint arXiv:2604.03406,
-
[66]
doi:10.48550/arXiv.2604.034062, 3
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.034062
-
[67]
Z. Sun, Z. Liu, Y . Zang, Y . Cao, X. Dong, T. Wu et al. SEAgent: Self- evolving computer use agent with autonomous learning from experience. arXiv preprint arXiv:2508.04700, 2025. doi: 10.48550/arXiv.2508.04700 2, 5
-
[68]
W. Takerngsaksiri, J. Pasuksmit, P. Thongtanunam, C. Tantithamtha- vorn, R. Zhang, F. Jiang et al. Human-in-the-loop software development agents. InProc. IEEE/ACM ICSE: SEIP, pp. 342–352, 2025. doi: 10. 1109/MSR66628.2025.001121, 3
arXiv 2025
-
[69]
Multi-Agent Collaboration: Harnessing the Power of Intelligent LLM Agents
Y . Talebirad and A. Nadiri. Multi-Agent Collaboration: Harnessing the power of intelligent LLM agents.arXiv preprint arXiv:2306.03314, 2023. doi:10.48550/arXiv.2306.033142
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.033142 2023
-
[70]
J. Z. Tam, P. Grosset, D. Banesh, N. Ramachandra, T. L. Turton, and J. Ahrens. InferA: A smart assistant for cosmological ensemble data. In Proc. ACM/IEEE SC Workshops, pp. 20–28, 2025. doi:10.1145/3731599. 37673422, 3
-
[71]
M. Tambe. Implementing agent teams in dynamic multiagent envi- ronments.Appl. Artif. Intell., 12(2-3):189–210, 1998. doi: 10.1080/ 0883951981178202
1998
-
[72]
K. Tang, K. Ai, J. Han, and C. Wang. TexGS-V olVis: Expressive scene editing for volume visualization via textured Gaussian splatting.IEEE Trans. Vis. Comput. Graph., 32(1):933–943, 2026. doi: 10.1109/TVCG.2025. 36346433
-
[73]
K. Tang, S. Yao, and C. Wang. iVR-GS: Inverse volume rendering for ex- plorable visualization via editable 3D Gaussian splatting.IEEE Trans. Vis. Comput. Graph., 31(6):3783–3795, 2025. doi: 10.1109/TVCG.2025.3567121 1
-
[74]
J. Tierny, G. Favelier, J. A. Levine, C. Gueunet, and M. Michaux. The topology toolkit.IEEE Trans. Vis. Comput. Graph., 24(1):832–842, 2017. doi:10.1109/TVCG.2017.27439384
-
[75]
Exploring Interaction Paradigms for LLM Agents in Scientific Visualization
J. V onderhorst, K. Ai, H. Miao, S. Liu, and C. Wang. Exploring LLM agent designs and interaction modalities for scientific visualization.arXiv preprint arXiv:2604.27996, 2026. doi:10.48550/arXiv.2604.279962
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.279962 2026
-
[76]
C. Wang and J. Han. DL4SciVis: A state-of-the-art survey on deep learning for scientific visualization.IEEE Trans. Vis. Comput. Graph., 29(8):3714–3733, 2023. doi:10.1109/TVCG.2022.31678961
-
[77]
Y . Wang, B. Pan, K. Wang, H. Liu, J. Mao, Y . Liu et al. IntuiTF: MLLM- guided transfer function optimization for direct volume rendering.arXiv preprint arXiv:2506.18407, 2025. doi:10.48550/arXiv.2506.184072
-
[78]
K. Werder, B. Ramesh, and R. S. Zhang. Establishing data provenance for responsible artificial intelligence systems.ACM Trans. Manag. Inf. Syst., 13(2):22:1–22:33, 2022. doi:10.1145/35034884
-
[79]
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu et al. AutoGen: Enabling next-gen LLM applications via multi-agent conversations.arXiv preprint arXiv:2308.08155, 2023. doi:10.48550/arXiv.2308.081552
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.081552 2023
-
[80]
Z. Wu, C. Han, Z. Ding, Z. Weng, Z. Liu, S. Yao et al. OS-Copilot: Towards generalist computer agents with self-improvement.arXiv preprint arXiv:2402.07456, 2024. doi:10.48550/arXiv.2402.074561, 2
-
[81]
Z. Xi, W. Chen, X. Guo, W. He, Y . Ding, B. Hong et al. The rise and potential of large language model based agents: A survey.Sci. China Inf. Sci., 68(2):121101, 2025. doi:10.1007/s11432-024-4222-02
-
[82]
Y . Yang, A. G. Zhang, S. Oney, and A. Y . Wang. SPARK: Real-time mon- itoring of multi-faceted programming exercises. InProc. IEEE VL/HCC, pp. 81–92, 2025. doi:10.1109/VL-HCC65237.2025.000189
-
[83]
Z. Yang, Z. Zhou, S. Wang, X. Cong, X. Han, Y . Yan et al. MatPlotAgent: Method and evaluation for LLM-based agentic scientific data visualization. InProc. ACL Findings, pp. 11789–11804, 2024. doi: 10.18653/v1/2024. findings-acl.7012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.