REVIEW 2 major objections 2 minor 63 references
Member images produce captions that align more tightly with their visual content than non-member images do in vision-language models.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-20 14:02 UTC pith:LESCISH6
load-bearing objection The paper gives a workable single-sample black-box MIA for VLMs by measuring alignment between an image and its model-generated caption, but the evidence that this difference comes from memorization rather than image properties or caption biases is thin. the 2 major comments →
Single-Sample Black-Box Membership Inference Attack against Vision-Language Models via Cross-modal Semantic Alignment
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
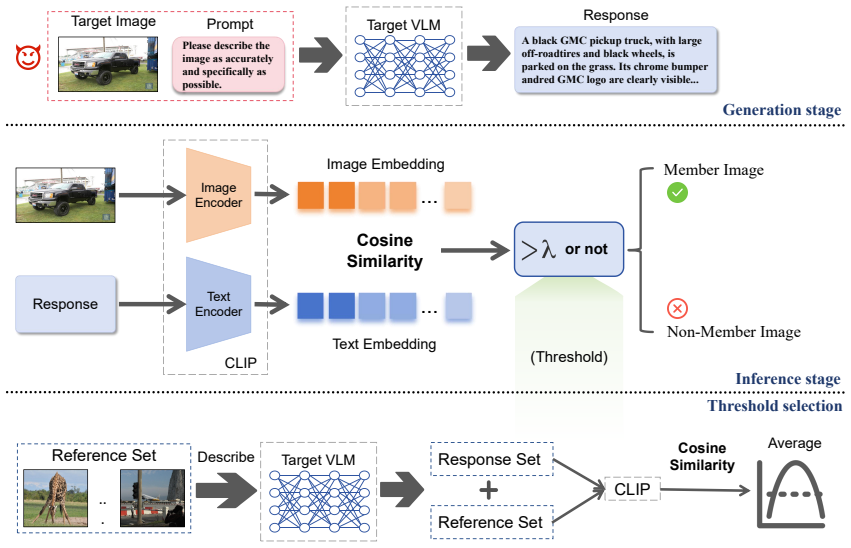
Member images exhibit significantly stronger image-caption alignment due to training memorization, whereas generated captions for non-members may deviate from the original visual content. Quantifying this alignment within a joint embedding space enables membership inference under strict black-box and single-sample constraints.
What carries the argument
Cross-modal semantic alignment score computed between an image and its model-generated caption inside a joint embedding space.
Load-bearing premise
Stronger observed alignment between an image and its generated caption is caused by training-set memorization rather than other image properties or caption-generation biases.
What would settle it
A test set of non-member images that produce equally strong alignment scores as member images under the same caption-generation procedure would disprove the central claim.
If this is right
- A single forward pass through the VLM suffices to produce a membership score.
- The attack applies to closed-source models accessible only through caption-generation APIs.
- Performance holds across image perturbations without retraining the attack.
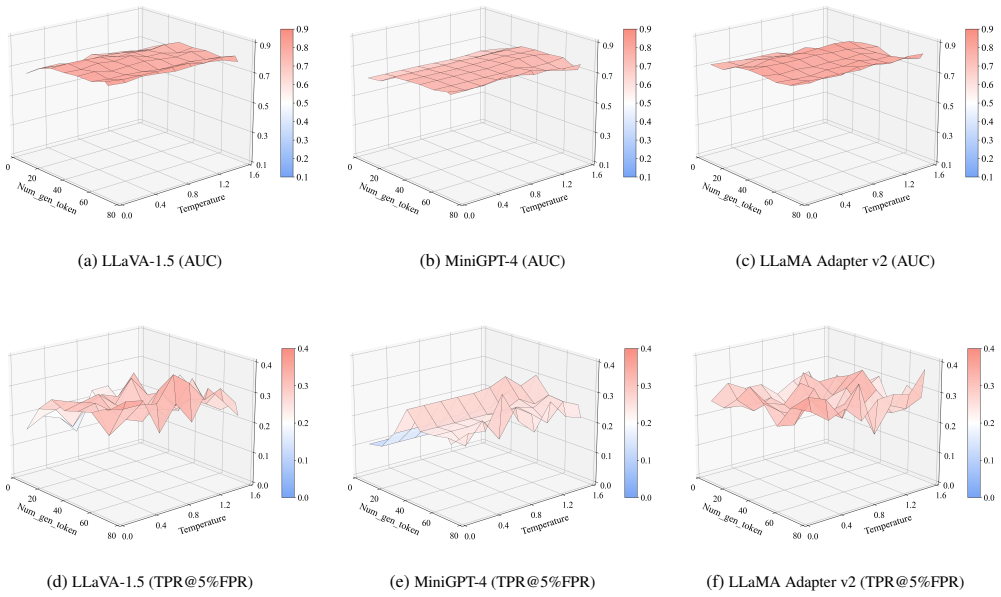
- The method reports an AUC of 0.821 on the VL-MIA/Flickr dataset against LLaVA-1.5.
Where Pith is reading between the lines
- Mitigating caption consistency on training images could reduce leakage of membership information.
- Similar alignment-based signals might appear in other multimodal generation tasks beyond captioning.
- The attack could be combined with existing statistical MIA baselines when more samples become available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel black-box, single-sample membership inference attack (MIA) against vision-language models (VLMs) that exploits differences in cross-modal semantic alignment. It observes that member images exhibit stronger alignment with captions generated by the VLM due to training memorization, while non-member images show greater deviation. The method quantifies this alignment in a joint embedding space and reports an AUC of 0.821 on the VL-MIA/Flicker dataset for LLaVA-1.5, along with robustness to image perturbations. Experiments cover three open-source and two closed-source VLMs.
Significance. If the alignment signal can be isolated as a direct consequence of membership rather than confounding factors, the work would offer a practical auditing tool for data leakage in VLMs under realistic API constraints where internal logits and large reference distributions are unavailable. This addresses a clear gap in existing MIA literature for multimodal models and could inform privacy evaluations if supported by stronger causal evidence.
major comments (2)
- [Abstract] Abstract: The central claim that 'member images exhibit significantly stronger image-caption alignment due to training memorization' is load-bearing for the proposed MIA framework, yet the abstract (and by extension the experimental description) supplies no controls or ablations to isolate membership from alternative explanations such as image statistics, caption-generation biases of the VLM, or properties of the joint embedding space. No mention is made of matching member/non-member pairs on visual features, employing an external captioner, or ablating the embedding metric.
- [Experimental evaluation] Experimental evaluation: The reported AUC of 0.821 against LLaVA-1.5 is presented without details on baseline implementations, statistical significance testing, or explicit controls for confounding factors that could affect the cross-period or cross-model claims. This undermines the assertion that the method 'significantly outperforming existing baselines' in a strict single-sample black-box setting.
minor comments (2)
- [Method] The description of the joint embedding space and alignment quantification would benefit from an explicit equation or pseudocode to clarify how the metric is computed from image and caption embeddings.
- [Experiments] Dataset details for VL-MIA/Flicker (e.g., how member/non-member splits were constructed and balanced) should be expanded to allow reproduction of the single-sample setting.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on isolating the membership signal and strengthening experimental details. We respond to each major comment below and outline the revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'member images exhibit significantly stronger image-caption alignment due to training memorization' is load-bearing for the proposed MIA framework, yet the abstract (and by extension the experimental description) supplies no controls or ablations to isolate membership from alternative explanations such as image statistics, caption-generation biases of the VLM, or properties of the joint embedding space. No mention is made of matching member/non-member pairs on visual features, employing an external captioner, or ablating the embedding metric.
Authors: We agree that stronger isolation of the membership effect from confounders is important for the central claim. The current work provides supporting evidence via robustness to image perturbations and cross-model consistency, but does not include explicit matching of member/non-member pairs on visual features, external captioner comparisons, or embedding metric ablations in the reported experiments. To address this, we will add these controls and ablations in a revised experimental section and update the abstract to briefly note the controls used to support the alignment observation. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: The reported AUC of 0.821 against LLaVA-1.5 is presented without details on baseline implementations, statistical significance testing, or explicit controls for confounding factors that could affect the cross-period or cross-model claims. This undermines the assertion that the method 'significantly outperforming existing baselines' in a strict single-sample black-box setting.
Authors: We acknowledge the need for greater transparency on these points. Baseline implementations follow the original papers with single-sample black-box adaptations detailed in the appendix; we will move key implementation details to the main text. We will add statistical significance testing (e.g., results across multiple random seeds with confidence intervals) and explicit controls for confounding factors, including fixed dataset splits and perturbation analyses, to support cross-model and cross-period comparisons. These additions will better substantiate the performance claims. revision: yes
Circularity Check
No circularity: empirical measurement of alignment differences with independent experimental validation
full rationale
The paper's central contribution is an empirical MIA method that measures cross-modal alignment in a joint embedding space and reports AUC performance from experiments on multiple VLMs. No equations, fitted parameters, or self-citations are presented that reduce the reported attack success to a quantity defined by the inputs themselves. The derivation chain consists of an observation followed by a quantification procedure whose outputs are evaluated externally against ground-truth membership labels, making the result falsifiable and non-tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models maintain a joint embedding space in which semantic alignment between images and text can be quantified.
read the original abstract
Vision-Language Models (VLMs) have achieved remarkable success, yet their reliance on massive datasets and unintended memorization of training data raise significant data security risk. Membership Inference Attacks (MIAs) aim to assess these risks by determining whether a data sample was included in a model's training set. However, existing MIA methods against VLMs face critical bottlenecks: gray-box method relies on internal logits that are typically restricted in real-world Application Programming Interfaces (APIs), while black-box method depends on large-scale statistical distributions, which struggle in single-sample scenarios. To this end, we investigate MIAs from the perspective of cross-modal semantic alignment, and observe that member images exhibit significantly stronger image-caption alignment due to training memorization, whereas generated captions for non-members may deviate from the original visual content. Leveraging this insight, we propose a novel MIA framework designed for strict black-box and single-sample setting that quantifies such alignment within a joint embedding space, thereby bypassing these unrealistic assumptions. We conducted extensive experiments on three open-source and two closed-source VLMs. On the VL-MIA/Flicker dataset, our method achieves an AUC of 0.821 against LLaVA-1.5, significantly outperforming existing baselines. Furthermore, it remains robust under diverse image perturbations, highlighting its practicality.
Figures





Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
quantifies such alignment within a joint embedding space... cosine similarity between the image and text embeddings serves as the membership signal
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
member images exhibit significantly stronger image-caption alignment due to training memorization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
The claude 3 model family: Opus, sonnet, haiku
Anthropic. The claude 3 model family: Opus, sonnet, haiku. Model card, Anthropic,
-
[3]
URL: https://www-cdn.anthropic.com/ de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/ Model_Card_Claude_3.pdf
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christo- pher Hesse, Mark Chen, Eric Sigler, Mateusz Lit...
-
[6]
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramèr. Membership infer- ence attacks from first principles. In43rd IEEE Sympo- sium on Security and Privacy, SP 2022, San Francisco, CA, USA, May 22-26, 2022, pages 1897–1914. IEEE, 2022.doi:10.1109/SP46214.2022.9833649
-
[7]
Extracting training data from diffusion models
Nicholas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramèr, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from diffusion models. In Joseph A. Calandrino and Carmela Troncoso, editors,32nd USENIX Security Symposium, USENIX Security 2023, Anaheim, CA, USA, August 9-11, 2023, pages 5253–5270. USENIX...
work page 2023
-
[8]
The secret sharer: Evalu- ating and testing unintended memorization in neu- ral networks
Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evalu- ating and testing unintended memorization in neu- ral networks. In Nadia Heninger and Patrick Traynor, editors,28th USENIX Security Symposium, USENIX Security 2019, Santa Clara, CA, USA, Au- gust 14-16, 2019, pages 267–284. USENIX Associa- tion, 2019. URL: ...
work page 2019
-
[9]
Brown, Dawn Song, Úlfar Erlings- son, Alina Oprea, and Colin Raffel
Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert-V oss, Katherine Lee, Adam Roberts, Tom B. Brown, Dawn Song, Úlfar Erlings- son, Alina Oprea, and Colin Raffel. Extracting train- ing data from large language models. In Michael D. Bailey and Rachel Greenstadt, editors,30th USENIX Security Symposium, USENIX Security 2021, Aug...
work page 2021
-
[10]
Gan-leaks: A taxonomy of membership inference at- tacks against generative models
Dingfan Chen, Ning Yu, Yang Zhang, and Mario Fritz. Gan-leaks: A taxonomy of membership inference at- tacks against generative models. InProceedings of the 2020 ACM SIGSAC conference on computer and com- munications security, pages 343–362, 2020
work page 2020
-
[11]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023
work page 2023
-
[12]
Choquette-Choo, Florian Tramer, Nicholas Carlini, and Nicolas Papernot
Christopher A. Choquette-Choo, Florian Tramer, Nicholas Carlini, and Nicolas Papernot. Label-only membership inference attacks. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th Interna- tional Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 1964–1974. PMLR, 18–24 Jul 2021. URL: https: //proceedin...
work page 1964
-
[13]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: To- wards general-purpose vision-language models with in- struction tuning, 2023. https://arxiv.org/abs/2305.06500. arXiv:2305.06500. 15
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirec- tional transformers for language understanding. InPro- ceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minnea...
-
[15]
Michael Duan, Anshuman Suri, Niloofar Mireshghal- lah, Sewon Min, Weijia Shi, Luke Zettlemoyer, Yulia Tsvetkov, Yejin Choi, David Evans, and Hannaneh Ha- jishirzi. Do membership inference attacks work on large language models? InFirst Conference on Language Modeling, 2024. URL: https://openreview.net/forum? id=av0D19pSkU
work page 2024
-
[16]
https://doi.org/10.48550/arXiv.2311.06062
Wenjie Fu, Huandong Wang, Chen Gao, Guanghua Liu, Yong Li, and Tao Jiang. Practical membership inference attacks against fine-tuned large language models via self- prompt calibration.arXiv preprint arXiv:2311.06062, 2023
-
[17]
Llama- adapter v2: Parameter-efficient visual instruction model,
Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shi- jie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, Hongsheng Li, and Yu Qiao. Llama- adapter v2: Parameter-efficient visual instruction model,
-
[18]
URL: https://arxiv.org/abs/2304.15010, arXiv: 2304.15010
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Iryna Hartsock and Ghulam Rasool. Vision-language models for medical report generation and visual question answering: a review.Frontiers in Artificial Intelligence, 7, November 2024. http://dx.doi.org/10.3389/frai.2024. 1430984
-
[20]
LOGAN: Membership Inference Attacks Against Generative Models
Jamie Hayes, Luca Melis, George Danezis, and Emil- iano De Cristofaro. Logan: Membership inference attacks against generative models.arXiv preprint arXiv:1705.07663, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Dan Hendrycks and Thomas G. Dietterich. Benchmark- ing neural network robustness to common corruptions and perturbations. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. URL: https://openreview.net/forum?id=HJz6tiCqYm
work page 2019
-
[22]
Benjamin Hilprecht, Martin Härterich, and Daniel Bernau. Monte carlo and reconstruction membership in- ference attacks against generative models.Proceedings on Privacy Enhancing Technologies, 2019
work page 2019
-
[23]
Defenses to membership inference attacks: A survey
Li Hu, Anli Yan, Hongyang Yan, Jin Li, Teng Huang, Yingying Zhang, Changyu Dong, and Chunsheng Yang. Defenses to membership inference attacks: A survey. ACM Comput. Surv., 56(4):92:1–92:34, 2024. doi:10. 1145/3620667
work page 2024
-
[24]
M 4i: Multi-modal models member- ship inference
Pingyi Hu, Zihan Wang, Ruoxi Sun, Hu Wang, and Minhui Xue. M 4i: Multi-modal models member- ship inference. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, Novembe...
work page 2022
-
[25]
Bliva: A simple multimodal llm for better handling of text-rich visual questions
Wenbo Hu, Yifan Xu, Yi Li, Weiyue Li, Zeyuan Chen, and Zhuowen Tu. Bliva: A simple multimodal llm for better handling of text-rich visual questions. In Proceedings of the AAAI Conference on Artificial In- telligence, volume 38, pages 2256–2264, 2024. https: //arxiv.org/abs/2308.09936
-
[26]
Membership inference at- tacks against vision-language models
Yuke Hu, Zheng Li, Zhihao Liu, Yang Zhang, Zhan Qin, Kui Ren, and Chun Chen. Membership inference at- tacks against vision-language models. In Lujo Bauer and Giancarlo Pellegrino, editors,34th USENIX Security Symposium, USENIX Security 2025, Seattle, WA, USA, August 13-15, 2025, pages 1589–1608. USENIX Associ- ation, 2025. URL: https://www.usenix.org/conf...
work page 2025
-
[27]
Scaling language-image pre- training via masking
Yanghao Li, Haoqi Fan, Ronghang Hu, Christoph Feicht- enhofer, and Kaiming He. Scaling language-image pre- training via masking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 23390–23400, June 2023
work page 2023
-
[28]
Membership inference attacks against large vision-language models
Zhan Li, Yongtao Wu, Yihang Chen, Francesco Tonin, Elías Abad-Rocamora, and V olkan Cevher. Membership inference attacks against large vision-language models. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Conference on...
work page 2024
-
[29]
Membership leakage in label- only exposures
Zheng Li and Yang Zhang. Membership leakage in label- only exposures. In Yongdae Kim, Jong Kim, Giovanni Vigna, and Elaine Shi, editors,CCS ’21: 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, Republic of Korea, November 15 16 - 19, 2021, pages 880–895. ACM, 2021. doi:10.1145/ 3460120.3484575
-
[30]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Alice Oh, Tristan Nau- mann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16...
work page 2023
-
[31]
Encodermi: Membership inference against pre-trained encoders in contrastive learning
Hongbin Liu, Jinyuan Jia, Wenjie Qu, and Neil Zhen- qiang Gong. Encodermi: Membership inference against pre-trained encoders in contrastive learning. InProceed- ings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, pages 2081–2095, 2021. https://doi.org/10.1145/3460120.3484749
-
[32]
Yi Liu, Chengjun Cai, Xiaoli Zhang, Xingliang Yuan, and Cong Wang. Arondight: Red teaming large vision language models with auto-generated multi-modal jail- break prompts, 2024. URL: https://arxiv.org/abs/2407. 15050,arXiv:2407.15050
-
[33]
Membership inference attacks by exploiting loss trajectory, 2022
Yiyong Liu, Zhengyu Zhao, Michael Backes, and Yang Zhang. Membership inference attacks by exploiting loss trajectory, 2022. URL: https://arxiv.org/abs/2208.14933, arXiv:2208.14933
-
[34]
Understanding Membership Inferences on Well-Generalized Learning Models
Yunhui Long, Vincent Bindschaedler, Lei Wang, Diyue Bu, Xiaofeng Wang, Haixu Tang, Carl A. Gunter, and Kai Chen. Understanding membership infer- ences on well-generalized learning models.CoRR, abs/1802.04889, 2018. URL: http://arxiv.org/abs/1802. 04889,arXiv:1802.04889
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Membership in- ference on word embedding and beyond.arXiv preprint arXiv:2106.11384, 2021
Saeed Mahloujifar, Huseyin A Inan, Melissa Chase, Esha Ghosh, and Marcello Hasegawa. Membership in- ference on word embedding and beyond.arXiv preprint arXiv:2106.11384, 2021
-
[36]
Membership Inference Attacks against Language Models via Neighbourhood Comparison
Justus Mattern, Fatemehsadat Mireshghallah, Zhijing Jin, Bernhard Schölkopf, Mrinmaya Sachan, and Tay- lor Berg-Kirkpatrick. Membership inference attacks against language models via neighbourhood compar- ison. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Asso- ciation for Computational Linguistics: ACL 2023, Toronto, ...
-
[37]
Germany: Berlin, Greece: Athens, ..., Japan: ____
Justus Mattern, Fatemehsadat Mireshghallah, Zhijing Jin, Bernhard Schölkopf, Mrinmaya Sachan, and Tay- lor Berg-Kirkpatrick. Membership inference attacks against language models via neighbourhood compar- ison. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Association for Computational Linguistics: ACL 2023, pages 11330– 1...
-
[38]
An empirical analysis of memorization in fine-tuned autore- gressive language models
Fatemehsadat Mireshghallah, Archit Uniyal, Tianhao Wang, David K Evans, and Taylor Berg-Kirkpatrick. An empirical analysis of memorization in fine-tuned autore- gressive language models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1816–1826, 2022
work page 2022
-
[39]
Niloofar Mireshghallah, Hyunwoo Kim, Xuhui Zhou, Yulia Tsvetkov, Maarten Sap, Reza Shokri, and Yejin Choi. Can llms keep a secret? testing privacy im- plications of language models via contextual integrity theory. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL: http...
work page 2024
-
[40]
Norman Mu, Alexander Kirillov, David A. Wagner, and Saining Xie. SLIP: self-supervision meets language- image pre-training. InComputer Vision - ECCV 2022, Proceedings, Part XXVI, volume 13686 ofLecture Notes in Computer Science, pages 529–544. Springer, 2022. doi:10.1007/978-3-031-19809-0_30
-
[41]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agar- wal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Be...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
arXiv preprint arXiv:2306.13213 , year =
Xiangyu Qi, Kaixuan Huang, Ashwinee Panda, Peter Henderson, Mengdi Wang, and Prateek Mittal. Visual adversarial examples jailbreak aligned large language models, 2023. URL: https://arxiv.org/abs/2306.13213, arXiv:2306.13213
-
[43]
Learning transferable vi- sual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable vi- sual models from natural language supervision. InPro- ceedings of the 38th International Conference on Ma- chine Learning, volume 139 ofProceedin...
work page 2021
-
[44]
Self- comparison for dataset-level membership inference in large (vision-)language model
Jie Ren, Kangrui Chen, Chen Chen, Vikash Sehwag, Yue Xing, Jiliang Tang, and Lingjuan Lyu. Self- comparison for dataset-level membership inference in large (vision-)language model. In Guodong Long, Michale Blumestein, Yi Chang, Liane Lewin-Eytan, Zi Helen Huang, and Elad Yom-Tov, editors,Proceed- ings of the ACM on Web Conference 2025, WWW 2025, Sydney, N...
-
[45]
White-box vs black-box: Bayes optimal strategies for member- ship inference
Alexandre Sablayrolles, Matthijs Douze, Cordelia Schmid, Yann Ollivier, and Herve Jegou. White-box vs black-box: Bayes optimal strategies for member- ship inference. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th Inter- national Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 555...
work page 2019
-
[46]
Improved zero-shot classification by adapting vlms with text descriptions
Oindrila Saha, Grant Van Horn, and Subhransu Maji. Improved zero-shot classification by adapting vlms with text descriptions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17542–17552, 2024. https://openaccess.thecvf. com/content/CVPR2024/papers/Saha_Improved_ Zero-Shot_Classification_by_Adapting_VLMs_with_ Tex...
work page 2024
-
[47]
Ahmed Salem, Yang Zhang, Mathias Humbert, Pas- cal Berrang, Mario Fritz, and Michael Backes. Ml- leaks: Model and data independent membership infer- ence attacks and defenses on machine learning models,
-
[48]
URL: https://arxiv.org/abs/1806.01246, arXiv: 1806.01246
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Detecting pretraining data from large language models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models. InThe Twelfth International Confer- ence on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL: https://openreview.net/forum?id=zWqr3MQuNs
work page 2024
-
[50]
In: 2017 IEEE Symposium on Security and Pri- vacy
Reza Shokri, Marco Stronati, Congzheng Song, and Vi- taly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017. https://doi.org/10.1109/SP.2017.41
-
[51]
Informa- tion leakage in embedding models
Congzheng Song and Ananth Raghunathan. Informa- tion leakage in embedding models. InProceedings of the 2020 ACM SIGSAC conference on computer and communications security, pages 377–390, 2020
work page 2020
-
[52]
Liwei Song, Reza Shokri, and Prateek Mittal. Mem- bership inference attacks against adversarially robust deep learning models. In2019 IEEE Security and Pri- vacy Workshops, SP Workshops 2019, San Francisco, CA, USA, May 19-23, 2019, pages 50–56. IEEE, 2019. doi:10.1109/SPW.2019.00021
-
[53]
Data augmentation using random image crop- ping and patching for deep cnns.IEEE Trans
Ryo Takahashi, Takashi Matsubara, and Kuniaki Ue- hara. Data augmentation using random image crop- ping and patching for deep cnns.IEEE Trans. Cir- cuits Syst. Video Technol., 30(9):2917–2931, 2020.doi: 10.1109/TCSVT.2019.2935128
-
[54]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Bap- tiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foun- dation language models, 2023. URL: https://arxiv.org/ abs/2302.13971,arXiv:2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Junjie Wang, Bin Chen, Yulin Li, Bin Kang, Yichi Chen, and Zhuotao Tian. Declip: Decoupled learning for open-vocabulary dense perception. InIEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, CVPR 2025, pages 14824–14834, 2025. URL: https://openaccess.thecvf.com/content/CVPR2025/ html/Wang_DeCLIP_Decoupled_Learning_for_ Open-V ocabulary_Dens...
-
[56]
CogVLM: Visual Expert for Pretrained Language Models
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, Jiazheng Xu, Bin Xu, Juanzi Li, Yuxiao Dong, Ming Ding, and Jie Tang. Cogvlm: Visual expert for pretrained language models, 2024. https://arxiv.org/ abs/2311.03079.arXiv:2311.03079
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
On the importance of diffi- culty calibration in membership inference attacks
Lauren Watson, Chuan Guo, Graham Cormode, and Alexandre Sablayrolles. On the importance of diffi- culty calibration in membership inference attacks. In The Tenth International Conference on Learning Repre- sentations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL: https://openreview.net/ forum?id=3eIrli0TwQ
work page 2022
-
[58]
Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V . Le. Self-training with noisy student im- proves imagenet classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020. https: //openaccess.thecvf.com/content_CVPR_2020/html/ Xie_Self-Training_With_Noisy_Student_Improves_ ImageNet_Classification_...
work page 2020
-
[59]
Shadowcast: Stealthy data poisoning attacks against vision-language models
Yuancheng Xu, Jiarui Yao, Manli Shu, Yanchao Sun, Zichu Wu, Ning Yu, Tom Goldstein, and Furong Huang. Shadowcast: Stealthy data poisoning attacks against vision-language models, 2024. URL: https://arxiv.org/ abs/2402.06659,arXiv:2402.06659
-
[60]
Privacy risk in machine learning: Analyz- ing the connection to overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyz- ing the connection to overfitting. In2018 IEEE 31st computer security foundations symposium (CSF), pages 268–282. IEEE, 2018
work page 2018
-
[61]
Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao (Frank) Yang, and Hai Li
Jingyang Zhang, Jingwei Sun, Eric C. Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao (Frank) Yang, and Hai Li. Min-k%++: Improved baseline for pre- training data detection from large language models. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
work page 2025
-
[62]
OpenReview.net, 2025. URL: https://openreview. net/forum?id=ZGkfoufDaU
work page 2025
-
[63]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2025. URL: https://arxiv.org/abs/2303.182...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Minigpt-4: Enhancing vision- language understanding with advanced large language 19 models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision- language understanding with advanced large language 19 models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL: https: //openreview.net/forum?id=1tZbq88f27. 20 Appendix ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.