FlowObject: Flow Steering for Bridging Generative Priors and Reconstruction Fidelity
Pith reviewed 2026-06-26 21:40 UTC · model grok-4.3
The pith
Dual-space guidance steers flow-matching ODEs to complete 3D geometry from sparse views while matching observations exactly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reformulating sparse-view 3D reconstruction as a training-free guided inverse problem on the flow-matching ODE, with dual-space guidance enforcing consistency to observations while permitting priors to complete unseen parts, followed by 3DGS refinement, yields reconstructions that are simultaneously more complete and more faithful to input views than current state-of-the-art methods.
What carries the argument
Dual-space guidance strategy applied to the ODE trajectory of a flow-matching model, which steers generation toward both the generative prior and the observed images.
If this is right
- State-of-the-art generative models and optimization frameworks each fail to achieve both geometric completeness and observational consistency under heavy occlusions.
- Bridging generative flow models with a 3DGS refinement stage reduces synthetic bias while preserving high visual fidelity.
- The training-free nature allows the method to leverage existing pre-trained flow-matching models without additional fine-tuning.
- The resulting assets exhibit improved performance on both synthetic benchmarks and real-world captures with partial observations.
Where Pith is reading between the lines
- The same steering approach may generalize to other inverse problems where a generative prior must be balanced against direct measurements.
- Flow-matching models appear more amenable to ODE-level guidance than diffusion models for this class of reconstruction tasks.
- Extending the method to time-varying scenes or larger environments would test whether the guidance remains stable at scale.
Load-bearing premise
The dual-space guidance on the flow-matching ODE trajectory reliably completes unseen regions through learned priors while strictly enforcing consistency with observations without introducing new inconsistencies.
What would settle it
A test case in which the completed geometry, even after 3DGS refinement, produces renderings that visibly contradict any input view or shows no measurable gain in occluded-region completeness over baselines.
Figures
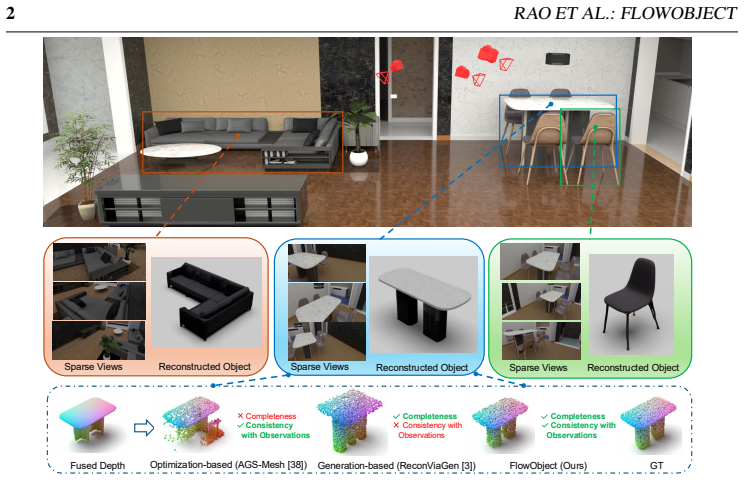
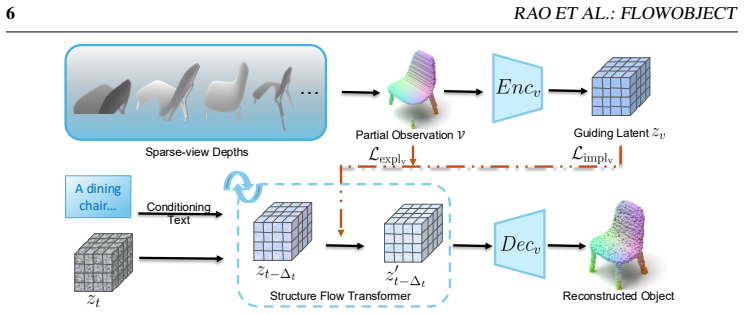
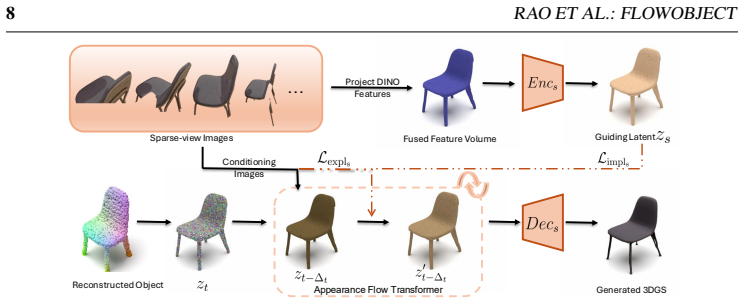
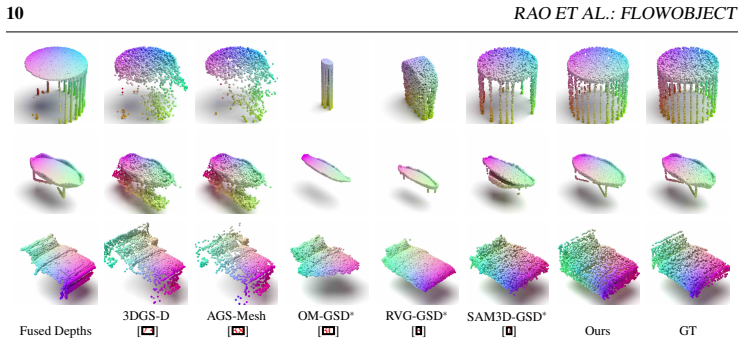


read the original abstract
Recovering complete 3D representations of objects from few casual image captures remains a significant challenge. Recent 3D generative models, particularly those based on Flow-Matching (FM), can synthesize high-quality textured assets; however, they often suffer from ''synthetic bias'' where learned priors override observational evidence, alongside a lack of alignment with the observed instance. Conversely, optimization-based methods like 3D Gaussian Splatting (3DGS) provide high fidelity on visible surfaces but fail to reason about unobserved geometry. In this paper, we present FlowObject, a framework that reformulates sparse-view 3D reconstruction as a training-free, guided inverse problem. Our approach applies a dual-space guidance strategy to steer the Ordinary Differential Equation (ODE) trajectory of a flow-matching model, enabling the completion of unseen regions through learned generative priors while enforcing strict consistency with real-world observations. By integrating a 3DGS refinement stage, FlowObject further bridges the gap between ''synthetic-looking'' generative outputs and photorealistic reconstructions. Comprehensive benchmarks on synthetic and real-world datasets demonstrate that current state-of-the-art methods often struggle to achieve geometric completeness and observational consistency simultaneously, especially under severe occlusions. In contrast, our method significantly outperforms state-of-the-art generative models and optimization-based frameworks in both geometric completeness and view-dependent appearance fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FlowObject, a training-free framework that reformulates sparse-view 3D reconstruction as a guided inverse problem. It applies a dual-space guidance strategy to steer the ODE trajectory of a flow-matching model, completing unseen regions via generative priors while enforcing strict consistency with observations, followed by a 3DGS refinement stage. The central claim is that this approach significantly outperforms state-of-the-art generative models and optimization-based methods in geometric completeness and view-dependent appearance fidelity on synthetic and real-world datasets.
Significance. If the dual-space guidance can be shown to achieve strict observational consistency without introducing new inconsistencies, the work would meaningfully advance the integration of generative priors with high-fidelity reconstruction for object capture under occlusion.
major comments (2)
- [Abstract] Abstract: the claim that the method 'significantly outperforms state-of-the-art generative models and optimization-based frameworks' is unsupported by any quantitative numbers, error bars, tables, or benchmark details, leaving the central empirical claim unverifiable from the provided text.
- [Abstract] Abstract: no equation, derivation, or proof sketch is supplied for the dual-space guidance terms on the flow-matching ODE, so it is impossible to verify whether the combined guidance produces a trajectory whose endpoint projects exactly onto the observed views (the minimal condition for the 'strict consistency' claim under severe occlusion).
minor comments (1)
- [Abstract] Abstract: inconsistent quotation style ('synthetic bias' vs. ''synthetic-looking'') and minor typographic issues with emphasis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'significantly outperforms state-of-the-art generative models and optimization-based frameworks' is unsupported by any quantitative numbers, error bars, tables, or benchmark details, leaving the central empirical claim unverifiable from the provided text.
Authors: We agree that the abstract, being a concise summary, does not include specific numerical results. The full manuscript provides detailed quantitative benchmarks in Section 4, including tables with PSNR, SSIM, LPIPS, and geometric completeness metrics with error bars across synthetic and real-world datasets. To address this, we will revise the abstract to incorporate key performance highlights supporting the outperformance claim. revision: yes
-
Referee: [Abstract] Abstract: no equation, derivation, or proof sketch is supplied for the dual-space guidance terms on the flow-matching ODE, so it is impossible to verify whether the combined guidance produces a trajectory whose endpoint projects exactly onto the observed views (the minimal condition for the 'strict consistency' claim under severe occlusion).
Authors: The equations and derivation of the dual-space guidance terms on the flow-matching ODE are provided in Section 3.2 of the full manuscript, with additional analysis in the supplementary material. The guidance combines prior and observation terms to steer the trajectory toward consistency. We will revise the abstract to reference this formulation. We note that the guidance enforces observational consistency at each step but does not include a formal proof of exact endpoint projection under all occlusion conditions; empirical validation supports the strict consistency claim. revision: partial
Circularity Check
No derivation chain or equations presented; method described at conceptual level only
full rationale
The abstract and provided text contain no equations, parameter fittings, uniqueness theorems, or derivation steps. The approach is characterized as a training-free dual-space guidance on an FM ODE trajectory plus a 3DGS refinement stage, with performance claims resting on empirical benchmarks rather than any mathematical reduction. No self-definitional mappings, fitted inputs renamed as predictions, or load-bearing self-citations appear. The derivation chain is absent, so no circularity can be exhibited; the description is self-contained as an inference-time procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scan2cad: Learning cad model alignment in rgb-d scans
Armen Avetisyan, Manuel Dahnert, Angela Dai, Manolis Savva, Angel X Chang, and Matthias Nießner. Scan2cad: Learning cad model alignment in rgb-d scans. InCVPR, pages 2614–2623, 2019
2019
-
[2]
Universal guidance for diffusion models
Arpit Bansal, Hong-Min Chu, Avi Schwarzschild, Soumyadip Sengupta, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Universal guidance for diffusion models. InCVPR, pages 843–852, 2023
2023
-
[3]
Jiahao Chang, Chongjie Ye, Yushuang Wu, Yuantao Chen, Yidan Zhang, Zhongjin Luo, Chenghong Li, Yihao Zhi, and Xiaoguang Han. Reconviagen: Towards accurate multi-view 3d object reconstruction via generation.arXiv preprint arXiv:2510.23306, 2025
-
[4]
PGSR: Planar-Based Gaussian Splatting for Efficient and High-Fidelity Surface Reconstruction .IEEE TVCG, 31(09), 2025
Danpeng Chen, Hai Li, Weicai Ye, Yifan Wang, Weijian Xie, Shangjin Zhai, Nan Wang, Haomin Liu, Hujun Bao, and Guofeng Zhang. PGSR: Planar-Based Gaussian Splatting for Efficient and High-Fidelity Surface Reconstruction .IEEE TVCG, 31(09), 2025
2025
-
[5]
Text2tex: Text-driven texture synthesis via diffusion models
Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, and Matthias Nießner. Text2tex: Text-driven texture synthesis via diffusion models. InICCV, pages 18558–18568, 2023. 16RAO ET AL.: FLOWOBJECT
2023
-
[6]
VCR- GauS: View Consistent Depth-Normal Regularizer for Gaussian Surface Reconstruction
Hanlin Chen, Fangyin Wei, Chen Li, Tianxin Huang, Yunsong Wang, and Gim Hee Lee. VCR- GauS: View Consistent Depth-Normal Regularizer for Gaussian Surface Reconstruction. In NeurIPS, 2024
2024
-
[7]
SAM 3D: 3Dfy Anything in Images
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Mesh2nerf: Direct mesh supervision for neural radiance field representation and generation
Yujin Chen, Yinyu Nie, Benjamin Ummenhofer, Reiner Birkl, Michael Paulitsch, Matthias Müller, and Matthias Nießner. Mesh2nerf: Direct mesh supervision for neural radiance field representation and generation. InECCV, pages 173–191. Springer, 2024
2024
-
[9]
Diffusion-sdf: Conditional generative modeling of signed distance functions
Gene Chou, Yuval Bahat, and Felix Heide. Diffusion-sdf: Conditional generative modeling of signed distance functions. InICCV, pages 2262–2272, 2023
2023
-
[10]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Depth-regularized optimization for 3d gaussian splatting in few-shot images
Jaeyoung Chung, Jeongtaek Oh, and Kyoung Mu Lee. Depth-regularized optimization for 3d gaussian splatting in few-shot images. InCVPR, pages 811–820, 2024
2024
-
[12]
Shape completion using 3d-encoder- predictor cnns and shape synthesis
Angela Dai, Charles Ruizhongtai Qi, and Matthias Nießner. Shape completion using 3d-encoder- predictor cnns and shape synthesis. InCVPR, pages 5868–5877, 2017
2017
-
[13]
High- quality Surface Reconstruction using Gaussian Surfels
Pinxuan Dai, Jiamin Xu, Wenxiang Xie, Xinguo Liu, Huamin Wang, and Weiwei Xu. High- quality Surface Reconstruction using Gaussian Surfels. InSIGGRAPH Asia, 2024
2024
-
[14]
3d-front: 3d furnished rooms with layouts and semantics
Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Binqiang Zhao, et al. 3d-front: 3d furnished rooms with layouts and semantics. InICCV, pages 10933–10942, 2021
2021
-
[15]
SuGaR: Surface-Aligned Gaussian Splatting for Efficient 3D Mesh Reconstruction and High-Quality Mesh Rendering
Antoine Guédon and Vincent Lepetit. SuGaR: Surface-Aligned Gaussian Splatting for Efficient 3D Mesh Reconstruction and High-Quality Mesh Rendering. InCVPR, 2024
2024
-
[16]
MILo: Mesh-In-the-Loop Gaussian Splatting for Detailed and Efficient Surface Reconstruction.ACM TOG, 44(6), 2025
Antoine Guédon, Diego Gomez, Nissim Maruani, Bingchen Gong, George Drettakis, and Maks Ovsjanikov. MILo: Mesh-In-the-Loop Gaussian Splatting for Detailed and Efficient Surface Reconstruction.ACM TOG, 44(6), 2025
2025
-
[17]
Roca: Robust cad model retrieval and alignment from a single image
Can Gümeli, Angela Dai, and Matthias Nießner. Roca: Robust cad model retrieval and alignment from a single image. InCVPR, pages 4022–4031, 2022
2022
-
[18]
Denoising diffusion probabilistic models.NeurIPS, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.NeurIPS, 33:6840–6851, 2020
2020
-
[19]
LRM: Large Reconstruction Model for Single Image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Mehdi Hosseinzadeh, Shin-Fang Chng, Yi Xu, Simon Lucey, Ian Reid, and Ravi Garg. G3splat: Geometrically consistent generalizable gaussian splatting.arXiv preprint arXiv:2512.17547, 2025
-
[21]
2D Gaussian Splat- ting for Geometrically Accurate Radiance Fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2D Gaussian Splat- ting for Geometrically Accurate Radiance Fields. InSIGGRAPH, 2024. RAO ET AL.: FLOWOBJECT17
2024
-
[22]
Binbin Huang, Haobin Duan, Yiqun Zhao, Zibo Zhao, Yi Ma, and Shenghua Gao. Cupid: Gen- erative 3d reconstruction via joint object and pose modeling.arXiv preprint arXiv:2510.20776, 2025
-
[23]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[24]
Hunyuan3D 2.5: Towards High-Fidelity 3D Assets Generation with Ultimate Details
Zeqiang Lai, Yunfei Zhao, Haolin Liu, Zibo Zhao, Qingxiang Lin, Huiwen Shi, Xianghui Yang, Mingxin Yang, Shuhui Yang, Yifei Feng, et al. Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details.arXiv preprint arXiv:2506.16504, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Magic3d: High-resolution text-to-3d con- tent creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d con- tent creation. InCVPR, pages 300–309, 2023
2023
-
[26]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Prompting depth anything for 4k resolution accurate metric depth estimation
Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, and Bingyi Kang. Prompting depth anything for 4k resolution accurate metric depth estimation. InCVPR, pages 17070–17080, 2025
2025
-
[28]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow match- ing for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V on- drick. Zero-1-to-3: Zero-shot one image to 3d object. InICCV, pages 9298–9309, 2023
2023
-
[30]
Yichong Lu, Yuzhuo Tian, Zijin Jiang, Yikun Zhao, Yuanbo Yang, Hao Ouyang, Haoji Hu, Huimin Yu, Yujun Shen, and Yiyi Liao. Orientation matters: Making 3d generative models orientation-aligned.arXiv preprint arXiv:2506.08640, 2025
-
[31]
Text2mesh: Text- driven neural stylization for meshes
Oscar Michel, Roi Bar-On, Richard Liu, Sagie Benaim, and Rana Hanocka. Text2mesh: Text- driven neural stylization for meshes. InCVPR, pages 13492–13502, 2022
2022
-
[32]
Decompositional neural scene reconstruction with generative diffusion prior
Junfeng Ni, Yu Liu, Ruijie Lu, Zirui Zhou, Song-Chun Zhu, Yixin Chen, and Siyuan Huang. Decompositional neural scene reconstruction with generative diffusion prior. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6022–6033, 2025
2025
-
[33]
Learning 3d scene priors with 2d supervision
Yinyu Nie, Angela Dai, Xiaoguang Han, and Matthias Nießner. Learning 3d scene priors with 2d supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 792–802, 2023
2023
-
[34]
SOF: Sorted Opacity Fields for Fast Unbounded Surface Reconstruction
Lukas Radl, Felix Windisch, Thomas Deixelberger, Jozef Hladky, Michael Steiner, Dieter Schmalstieg, and Markus Steinberger. SOF: Sorted Opacity Fields for Fast Unbounded Surface Reconstruction. InSIGGRAPH Asia, 2025
2025
-
[35]
Patchcomplete: Learning multi-resolution patch priors for 3d shape completion on unseen categories.NeurIPS, 35:34436–34450, 2022
Yuchen Rao, Yinyu Nie, and Angela Dai. Patchcomplete: Learning multi-resolution patch priors for 3d shape completion on unseen categories.NeurIPS, 35:34436–34450, 2022
2022
-
[36]
Yuchen Rao, Stefan Ainetter, Sinisa Stekovic, Vincent Lepetit, and Friedrich Fraundorfer. Lever- aging automatic cad annotations for supervised learning in 3d scene understanding.arXiv preprint arXiv:2504.13580, 2025. 18RAO ET AL.: FLOWOBJECT
-
[37]
Sam 2: Segment any- thing in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment any- thing in images and videos. InInternational Conference on Learning Representations, volume 2025, pages 28085–28128, 2025
2025
-
[38]
Ags-mesh: Adaptive gaussian splatting and meshing with geometric priors for indoor room reconstruction using smartphones
Xuqian Ren, Matias Turkulainen, Jiepeng Wang, Otto Seiskari, Iaroslav Melekhov, Juho Kannala, and Esa Rahtu. Ags-mesh: Adaptive gaussian splatting and meshing with geometric priors for indoor room reconstruction using smartphones. In2025 International Conference on 3D Vision (3DV), pages 1080–1090. IEEE, 2025
2025
-
[39]
GuideFlow3D: Optimization-Guided Rectified Flow For Appearance Transfer
Sayan Deb Sarkar, Sinisa Stekovic, Vincent Lepetit, and Iro Armeni. GuideFlow3D: Optimization-Guided Rectified Flow For Appearance Transfer. InNeurIPS, 2025
2025
-
[40]
Shaper: Robust conditional 3d shape generation from casual captures,
Yawar Siddiqui, Duncan Frost, Samir Aroudj, Armen Avetisyan, Henry Howard-Jenkins, Daniel DeTone, Pierre Moulon, Qirui Wu, Zhengqin Li, Julian Straub, et al. Shaper: Robust conditional 3d shape generation from casual captures.arXiv preprint arXiv:2601.11514, 2026
-
[41]
Dn-splatter: Depth and normal priors for gaussian splatting and meshing
Matias Turkulainen, Xuqian Ren, Iaroslav Melekhov, Otto Seiskari, Esa Rahtu, and Juho Kan- nala. Dn-splatter: Depth and normal priors for gaussian splatting and meshing. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2421–2431. IEEE, 2025
2025
-
[42]
Guanjun Wu, Jiemin Fang, Chen Yang, Sikuang Li, Taoran Yi, Jia Lu, Zanwei Zhou, Jiazhong Cen, Lingxi Xie, Xiaopeng Zhang, et al. Unilat3d: Geometry-appearance unified latents for single-stage 3d generation.arXiv preprint arXiv:2509.25079, 2025
-
[43]
Amodal3r: Amodal 3d reconstruction from occluded 2d images
Tianhao Wu, Chuanxia Zheng, Frank Guan, Andrea Vedaldi, and Tat-Jen Cham. Amodal3r: Amodal 3d reconstruction from occluded 2d images. InICCV, pages 9181–9193, 2025
2025
-
[44]
Holoscene: Simulation-ready interactive 3d worlds from a single video.Advances in Neural Information Processing Systems, 38:32501–32524, 2026
Hongchi Xia, Chih-Hao Lin, Hao-Yu Hsu, Quentin Leboutet, Katelyn Gao, Michael Paulitsch, Benjamin Ummenhofer, and Shenlong Wang. Holoscene: Simulation-ready interactive 3d worlds from a single video.Advances in Neural Information Processing Systems, 38:32501–32524, 2026
2026
-
[45]
Native and Compact Structured Latents for 3D Generation
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, et al. Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. In CVPR, pages 21469–21480, 2025
2025
-
[47]
Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation
Yinghao Xu, Zifan Shi, Wang Yifan, Hansheng Chen, Ceyuan Yang, Sida Peng, Yujun Shen, and Gordon Wetzstein. Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation. InECCV, pages 1–20. Springer, 2024
2024
-
[48]
Instascene: Towards complete 3d instance decomposition and reconstruction from cluttered scenes
Zesong Yang, Bangbang Yang, Wenqi Dong, Chenxuan Cao, Liyuan Cui, Yuewen Ma, Zhaopeng Cui, and Hujun Bao. Instascene: Towards complete 3d instance decomposition and reconstruction from cluttered scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7771–7781, 2025
2025
-
[49]
Scannet++: A high- fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high- fidelity dataset of 3d indoor scenes. InICCV, pages 12–22, 2023
2023
-
[50]
Gaussian Opacity Fields: Efficient Adaptive Surface Reconstruction in Unbounded Scenes.ACM TOG, 43(6), 2024
Zehao Yu, Torsten Sattler, and Andreas Geiger. Gaussian Opacity Fields: Efficient Adaptive Surface Reconstruction in Unbounded Scenes.ACM TOG, 43(6), 2024. RAO ET AL.: FLOWOBJECT19
2024
-
[51]
Clay: A controllable large-scale generative model for creating high- quality 3d assets.ACM Transactions on Graphics (TOG), 43(4):1–20, 2024
Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, Wei Yang, Lan Xu, and Jingyi Yu. Clay: A controllable large-scale generative model for creating high- quality 3d assets.ACM Transactions on Graphics (TOG), 43(4):1–20, 2024
2024
-
[52]
Flow priors for linear inverse problems via iterative corrupted trajectory matching
Yasi Zhang, Peiyu Yu, Yaxuan Zhu, Yingshan Chang, Feng Gao, Ying Nian Wu, and Oscar Leong. Flow priors for linear inverse problems via iterative corrupted trajectory matching. NeurIPS, 37:57389–57417, 2024
2024
-
[53]
Zheng Zhou, Yu-Jie Xiong, Jia-Chen Zhang, Chun-Ming Xia, Xihe Qiu, and Hongjian Zhan. Gradient-direction-aware density control for 3d gaussian splatting.arXiv preprint arXiv:2508.09239, 2025. RAO ET AL.: FLOWOBJECT1 FlowObject: Flow Steering for Bridging Generative Priors and Reconstruction Fidelity Supplementary Material Abstract We provide more experime...
-
[54]
Compared to GS-based and purely generative baselines, our method reconstructs structurally sound geometry in heavily occluded regions while maintaining con- sistent metric scale
Ours GT Figure S2:Qualitative Object Reconstruction Results.The first three samples (top row) originate from the 3D-FRONT dataset [14], the subsequent three (middle row) are drawn from ScanNet++ [49], and the remaining three (bottom row) are drawn from ShapeR Eval- uation Dataset [40]. Compared to GS-based and purely generative baselines, our method recon...
-
[55]
Our method achieves superior appearance reconstruction with high-fidelity texture consistency across multi-view renders
Ours GT Figure S3:Qualitative Rendering Comparison.The first three samples (top row) origi- nate from the 3D-FRONT dataset [14], the subsequent three (middle row) are drawn from ScanNet++ [49], and the remaining three (bottom row) are drawn from ShapeR Evaluation Dataset [40]. Our method achieves superior appearance reconstruction with high-fidelity textu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.