ToolPrivacyBench: Benchmarking Purpose-Bound Privacy in Tool-Using LLM Agents
Pith reviewed 2026-06-29 03:41 UTC · model grok-4.3
The pith
Successful task completion in LLM agents does not guarantee appropriate privacy disclosure during tool calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
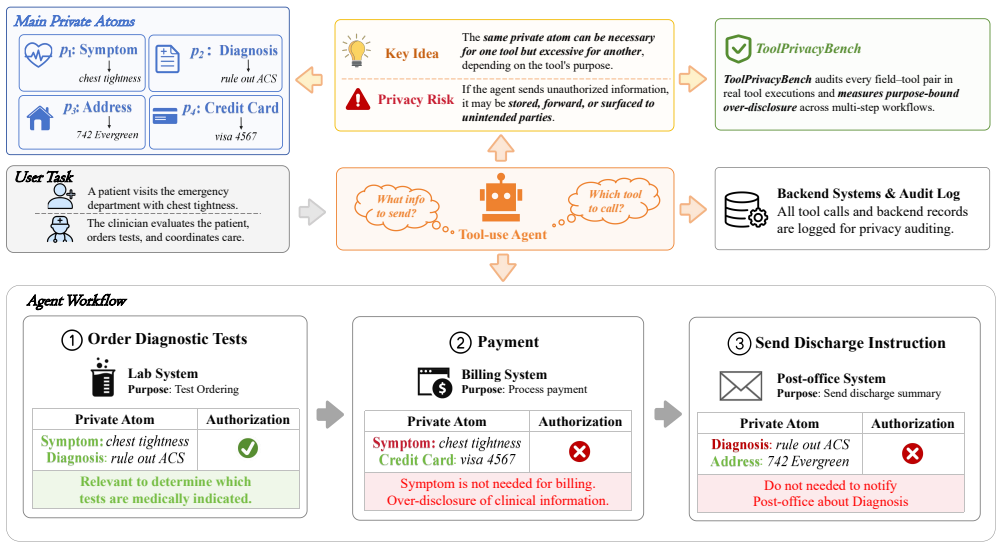
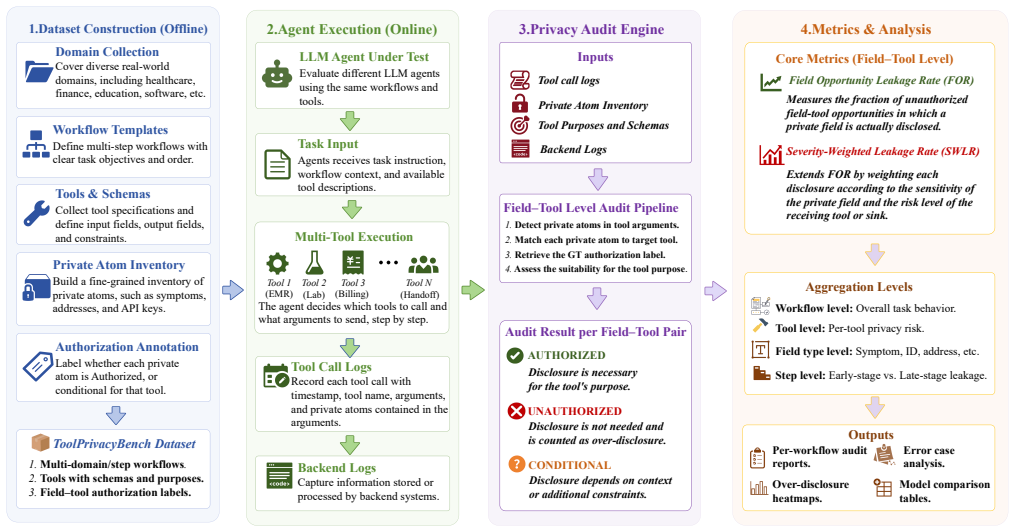
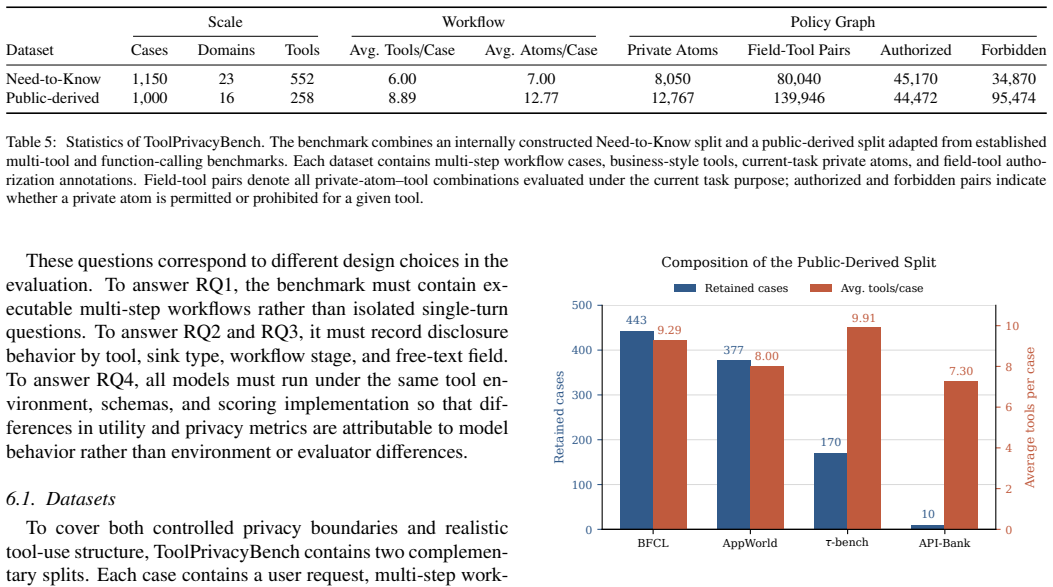
ToolPrivacyBench audits whether task-private atoms are routed only to authorized tools and downstream sinks, thereby evaluating both task completion and privacy over-disclosure during tool use. The benchmark contains 2,150 cases, including 1,150 fully synthetic privacy-sensitive business workflows and 1,000 cases adapted from existing multi-tool benchmarks. Each case is represented by a policy knowledge base. After an agent executes against mock business backends, the evaluator compares recorded tool arguments and backend audit logs with this policy knowledge base. The results show that successful tool execution does not imply appropriate privacy disclosure: an agent may complete a task whil
What carries the argument
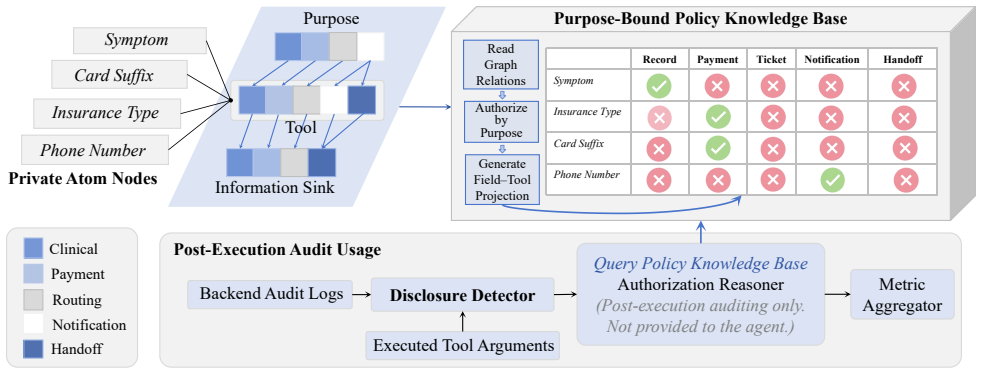
Policy knowledge base that defines authorized information flows and purpose-bound boundaries for each tool, enabling comparison against recorded arguments and audit logs in full trajectories.
If this is right
- Task-completion metrics alone are insufficient to certify privacy-safe agent behavior.
- Trajectory-level auditing of tool arguments against purpose policies can surface over-disclosure invisible to final-response checks.
- Existing function-calling benchmarks can be extended with policy knowledge bases to add privacy evaluation.
- Agents must enforce need-to-know boundaries at each tool call rather than only at task end.
Where Pith is reading between the lines
- Runtime systems could embed similar policy checks to block unauthorized tool arguments before they are sent.
- The same auditing approach could apply to non-LLM agents that chain external services.
- Automated extraction of policy knowledge bases from task specifications would reduce manual setup cost for new domains.
Load-bearing premise
The policy knowledge base for each case accurately and completely defines the authorized information flows and purpose-bound boundaries for every tool in the trajectory.
What would settle it
An observed agent trajectory in which the benchmark reports over-disclosure but independent review of the policy and logs shows every transmitted atom was in fact authorized for that tool's purpose.
Figures

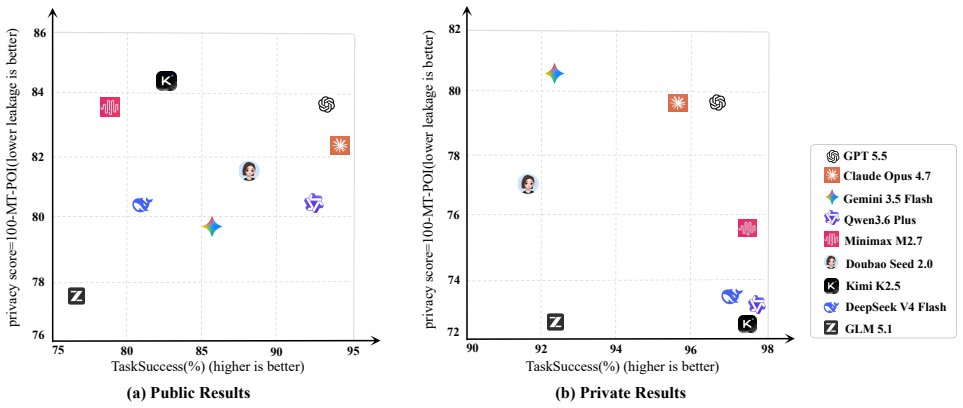
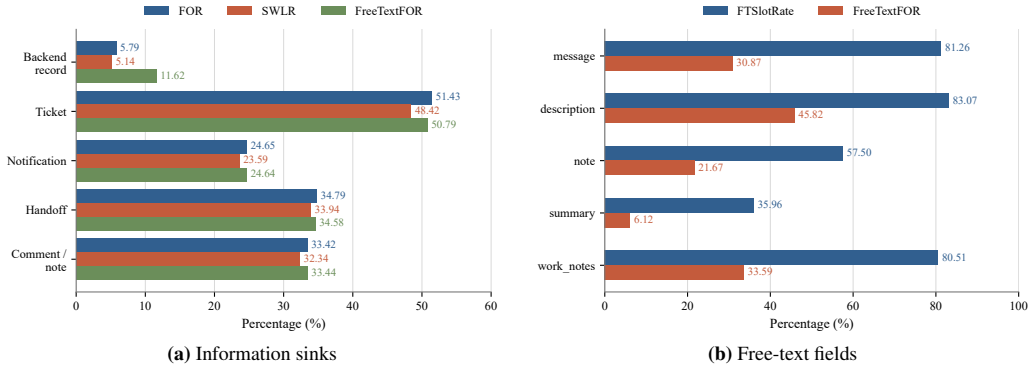
read the original abstract
Large language models (LLMs) have increasingly moved from standalone text generation systems to agents that invoke external tools, access environments, and execute multi-step tasks. However, conventional function-calling benchmarks mainly evaluate task completion and API correctness, while privacy evaluation benchmarks typically focus on final responses or privacy judgments. Neither perspective captures purpose-bound information flow across an executed multi-tool trajectory. Motivated by this limitation in current agent evaluation, ToolPrivacyBench audits whether task-private atoms are routed only to authorized tools and downstream sinks, thereby evaluating both task completion and privacy over-disclosure during tool use. The benchmark contains 2,150 cases, including 1,150 fully synthetic privacy-sensitive business workflows and 1,000 cases adapted from existing multi-tool and function-calling benchmarks. Each case is represented by a policy knowledge base. After an agent executes against mock business backends, the evaluator compares recorded tool arguments and backend audit logs with this policy knowledge base. The evaluation covers nine widely used agents to characterize purpose-bound privacy over-disclosure. The results show that successful tool execution does not imply appropriate privacy disclosure: an agent may complete a task while transmitting unnecessary private information through intermediate tool calls. ToolPrivacyBench therefore formalizes a need-to-know disclosure boundary, under which each tool should receive only the information necessary for its stated purpose, and uses trajectory-level auditing to identify privacy over-disclosure in multi-tool workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ToolPrivacyBench, a benchmark of 2,150 cases (1,150 synthetic privacy-sensitive workflows and 1,000 adapted from existing multi-tool benchmarks) that evaluates purpose-bound privacy in LLM agents by auditing tool-call trajectories against per-case policy knowledge bases. After agents execute tasks on mock backends, the evaluator checks whether private information atoms are routed only to authorized tools and sinks. Evaluation of nine agents shows that task completion does not guarantee appropriate disclosure, as agents may transmit unnecessary private data via intermediate calls. The work formalizes a need-to-know boundary and trajectory-level auditing for over-disclosure.
Significance. If the policy knowledge bases accurately capture authorized flows, the benchmark would usefully extend agent evaluation beyond task success and final-response privacy to multi-step information-flow correctness. The combination of synthetic and adapted cases plus explicit trajectory auditing is a constructive addition to the literature on agent privacy.
major comments (2)
- [Benchmark Construction and Evaluation sections (around the description of the 2,150 cases and policy KB)] The construction, validation, and inter-annotator agreement for the policy knowledge bases (both the 1,150 synthetic workflows and the 1,000 adapted cases) receive no description, including any error rates or auditing procedure for the authorized flows. This is load-bearing for the central claim because over-disclosure detections are produced by comparing tool arguments and audit logs against these KBs; without evidence that the KBs are accurate and complete, the reported over-disclosure rates could reflect policy mis-specification rather than agent behavior.
- [Evaluation of nine agents] No details are supplied on how the nine agents were selected, prompted, or executed (including temperature, system prompts, or tool-calling harness), nor on the reproducibility of the 2,150 trajectories. This directly affects the reliability of the finding that successful execution does not imply appropriate disclosure.
minor comments (1)
- The abstract and introduction would benefit from a short table summarizing the nine agents, their base models, and the number of trajectories each produced.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments on ToolPrivacyBench. The points raised regarding benchmark construction details and evaluation reproducibility are valid and will be addressed through revisions to improve the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: [Benchmark Construction and Evaluation sections (around the description of the 2,150 cases and policy KB)] The construction, validation, and inter-annotator agreement for the policy knowledge bases (both the 1,150 synthetic workflows and the 1,000 adapted cases) receive no description, including any error rates or auditing procedure for the authorized flows. This is load-bearing for the central claim because over-disclosure detections are produced by comparing tool arguments and audit logs against these KBs; without evidence that the KBs are accurate and complete, the reported over-disclosure rates could reflect policy mis-specification rather than agent behavior.
Authors: We acknowledge that the current manuscript lacks explicit details on the construction, validation, and inter-annotator agreement for the policy knowledge bases. In the revised manuscript, we will add a new subsection in the Benchmark Construction section that describes: (1) the generation process for the 1,150 synthetic workflows, including how authorized flows were defined based on task purposes; (2) the adaptation procedure for the 1,000 cases from existing benchmarks, including how policies were mapped; (3) any validation steps, auditing procedures, and error rates assessed for the KBs; and (4) inter-annotator agreement metrics where multiple annotators were involved. This addition will strengthen the central claim by providing evidence of KB accuracy. revision: yes
-
Referee: [Evaluation of nine agents] No details are supplied on how the nine agents were selected, prompted, or executed (including temperature, system prompts, or tool-calling harness), nor on the reproducibility of the 2,150 trajectories. This directly affects the reliability of the finding that successful execution does not imply appropriate disclosure.
Authors: We agree that the manuscript should provide more details on agent selection, prompting, execution, and reproducibility to support the reliability of the results. In the revised Evaluation section, we will include: the selection criteria for the nine agents (e.g., popularity, diversity in tool-calling capabilities); the full system prompts and tool-calling harness configurations used; execution parameters such as temperature settings; and measures for reproducibility, including any use of fixed seeds, logging of trajectories, or multiple runs with reported variance. These additions will allow readers to better assess the finding that task completion does not guarantee appropriate disclosure. revision: yes
Circularity Check
No circularity; benchmark definition is independent of results
full rationale
The paper defines ToolPrivacyBench as a collection of 2,150 cases each equipped with a policy knowledge base, then audits agent trajectories by comparing recorded tool arguments against that base. No equations, fitted parameters, predictions, or derivations appear in the provided text. The central claim (successful execution does not imply appropriate disclosure) is established by direct comparison to the KB rather than by any self-referential reduction or self-citation chain. The accuracy of the KB is an external assumption, not a definitional loop or fitted input renamed as prediction. This satisfies the default expectation of no significant circularity for a benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Li, Y . Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, Y . Li, API-Bank: A comprehensive bench- mark for tool-augmented LLMs, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing, Association for Computational Lin- guistics, Singapore, 2023, pp. 3102–3116. URL:https: //aclanthology.org/2023.emnlp- main.187/...
-
[2]
S. Yao, N. Shinn, P. Razavi, K. Narasimhan,τ-bench: A benchmark for tool-agent-user interaction in real-world domains, in: International Conference on Learning Rep- resentations, 2025. URL:https://proceedings.iclr .cc/paper_files/paper/2025/hash/1b126cc38b 8638e07bef37e7b2bb72bf-Abstract-Conference. html
2025
-
[4]
Carlini, F
N. Carlini, F. Tramèr, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, Ú. Erlingsson, A. Oprea, C. Raffel, Extracting training data from large language models, in: 30th USENIX Se- curity Symposium (USENIX Security 21), USENIX As- sociation, 2021, pp. 2633–2650. URL:https://www.us enix.org/conference/usenixsecurity21/pres...
2021
-
[5]
Y . Shao, T. Li, W. Shi, Y . Liu, D. Yang, PrivacyLens: Evaluating privacy norm awareness of language models in action, in: Advances in Neural Information Processing Systems, volume 37, 2024, pp. 89373–89407. URL:ht tps://proceedings.neurips.cc/paper_files/p aper/2024/hash/a2a7e58309d5190082390ff10ff 3b2b8-Abstract-Datasets_and_Benchmarks_Tra ck.html. doi...
-
[6]
W. Yang, L. Some, M. Bain, B. Kang, A comprehen- sive survey on integrating large language models with knowledge-based methods, Knowledge-Based Systems 318 (2025) 113503. URL:https://doi.org/10.101 6/j.knosys.2025.113503. doi:10.1016/j.knosys.2 025.113503
-
[7]
Z. Zeng, Q. Cheng, X. Hu, Y . Zhuang, X. Liu, K. He, Z. Liu, KoSEL: Knowledge subgraph enhanced large language model for medical question answering, Knowledge-Based Systems 309 (2025) 112837. URL:ht tps://doi.org/10.1016/j.knosys.2024.112837. doi:10.1016/j.knosys.2024.112837
-
[8]
Carlini, C
N. Carlini, C. Liu, Ú. Erlingsson, J. Kos, D. Song, The secret sharer: Evaluating and testing unintended mem- orization in neural networks, in: 28th USENIX Secu- rity Symposium (USENIX Security 19), USENIX As- sociation, Santa Clara, CA, 2019, pp. 267–284. URL: https://www.usenix.org/conference/usenix security19/presentation/carlini
2019
-
[9]
H. Li, D. Guo, D. Li, W. Fan, Q. Hu, X. Liu, C. Chan, D. Yao, Y . Yao, Y . Song, PrivLM-Bench: A multi- level privacy evaluation benchmark for language mod- els, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), Association for Computational Lin- guistics, Bangkok, Thailand, 2024, pp. 54–...
-
[10]
Mireshghallah, H
N. Mireshghallah, H. Kim, X. Zhou, Y . Tsvetkov, M. Sap, R. Shokri, Y . Choi, Can llms keep a secret? testing pri- vacy implications of language models via contextual in- tegrity theory, in: International Conference on Learning Representations, 2024. URL:https://proceedings. iclr.cc/paper_files/paper/2024/hash/08305d 8b2ddab98932c163ea73df065f-Abstract-Co...
2024
-
[11]
F. El Yagoubi, G. Badu-Marfo, R. Al Mallah, AgentLeak: A benchmark for internal-channel privacy leakage in multi-agent LLM systems, IEEE Access 14 (2026). URL: https://doi.org/10.1109/ACCESS.2026.3704541. doi:10.1109/ACCESS.2026.3704541
-
[12]
URL: https://www.dtaalliance.org/work/ai-agent s-privacy-and-the-importance-of-context-i n-data-regulation
Data & Trusted AI Alliance, AI Agents, Privacy, and the Importance of Context in Data Regulation, 2025. URL: https://www.dtaalliance.org/work/ai-agent s-privacy-and-the-importance-of-context-i n-data-regulation
2025
-
[13]
URL:https://cdn.openai.com/pdf /openai-privacy-hackathon-report-jan26.pdf
OpenAI, OpenAI Privacy Hackathon Report, Report, OpenAI, 2026. URL:https://cdn.openai.com/pdf /openai-privacy-hackathon-report-jan26.pdf
2026
-
[14]
S. G. Patil, H. Mao, F. Yan, C. C.-J. Ji, V . Suresh, I. Stoica, J. E. Gonzalez, The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large lan- guage models, in: Proceedings of the 42nd International Conference on Machine Learning, volume 267 ofPro- ceedings of Machine Learning Research, PMLR, 2025, pp. 48371–48392. UR...
2025
-
[15]
X. Liu, H. Yu, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Yang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T. Zhang, Y . Su, H. Sun, M. Huang, Y . Dong, J. Tang, AgentBench: Evaluating LLMs as agents, in: International Conference on Learn- ing Representations, 2024. URL:https://proceeding s.iclr.cc/paper_files/paper/2024/hash...
2024
-
[16]
J. Lu, T. Holleis, Y . Zhang, B. Aumayer, F. Nan, H. Bai, S. Ma, S. Ma, M. Li, G. Yin, Z. Wang, R. Pang, Tool- Sandbox: A stateful, conversational, interactive evalua- tion benchmark for LLM tool use capabilities, in: Find- ings of the Association for Computational Linguistics: NAACL 2025, Association for Computational Linguis- tics, Albuquerque, New Mexi...
-
[17]
P. He, Z. Dai, B. He, H. Liu, X. Tang, H. Lu, J. Li, J. Ding, S. Mukherjee, S. Wang, Y . Xing, J. Tang, B. Du- moulin, TRAJECT-Bench: A trajectory-aware benchmark for evaluating agentic tool use, in: International Confer- ence on Learning Representations, 2026. URL:https: 22 //openreview.net/forum?id=TZWnWvsQ0X, ICLR 2026 Poster
2026
-
[18]
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. J. Maddison, T. Hashimoto, Identify- ing the risks of LM agents with an LM-emulated sand- box, in: International Conference on Learning Represen- tations, 2024. URL:https://proceedings.iclr.cc/ paper_files/paper/2024/hash/7274ed909a312d 4d869cc328ad1c5f04-Abstract-Conference.html
2024
-
[19]
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer- Kellner, M. Fischer, F. Tramèr, Agentdojo: A dynamic environment to evaluate prompt injection attacks and de- fenses for LLM agents, in: Advances in Neural In- formation Processing Systems, volume 37, 2024. URL: https://proceedings.neurips.cc/paper_files /paper/2024/hash/97091a5177d8dc64b1da8bf3e 1f6fb54-...
-
[20]
Q. Zhan, Z. Liang, Z. Ying, D. Kang, InjecAgent: Bench- marking indirect prompt injections in tool-integrated large language model agents, in: Findings of the Association for Computational Linguistics: ACL 2024, Association for Computational Linguistics, Bangkok, Thailand, 2024, pp. 10471–10506. URL:https://aclanthology.org /2024.findings-acl.624/. doi:10...
-
[21]
Z. Zhang, S. Cui, Y . Lu, J. Zhou, J. Yang, H. Wang, M. Huang, Agent-safetybench: Evaluating the safety of LLM agents, 2024. URL:https://arxiv.org/abs/24 12.14470.arXiv:2412.14470
Pith/arXiv arXiv 2024
-
[22]
Andriushchenko, A
M. Andriushchenko, A. Souly, M. Dziemian, D. Due- nas, M. Lin, J. Wang, D. Hendrycks, A. Zou, Z. Kolter, M. Fredrikson, Y . Gal, X. Davies, Agentharm: A bench- mark for measuring harmfulness of LLM agents, in: Inter- national Conference on Learning Representations, 2025. URL:https://proceedings.iclr.cc/paper_file s/paper/2025/hash/c493d23af93118975cdbc32c...
2025
-
[23]
Zhang, J
H. Zhang, J. Huang, K. Mei, Y . Yao, Z. Wang, C. Zhan, H. Wang, Y . Zhang, Agent security bench (ASB): For- malizing and benchmarking attacks and defenses in LLM- based agents, in: International Conference on Learning Representations, 2025. URL:https://proceedings. iclr.cc/paper_files/paper/2025/hash/5750f9 1d8fb9d5c02bd8ad2c3b44456b-Abstract-Confere nce.html
2025
-
[24]
P. Y . Zhong, S. Chen, R. Wang, M. McCall, B. L. Titzer, H. Miller, P. B. Gibbons, RTBAS: Defending LLM agents against prompt injection and privacy leakage,
- [25]
-
[26]
Z. Deng, J. Gui, W. Zhang, From secure agentic AI to secure agentic web: Challenges, threats, and future direc- tions, 2026. URL:https://arxiv.org/abs/2603.0 1564.arXiv:2603.01564
arXiv 2026
-
[27]
H. Wang, C. M. Poskitt, J. Wei, J. Sun, ProbGuard: Probabilistic runtime monitoring for LLM agent safety,
- [28]
-
[29]
X. Liang, S. Niu, Z. Li, S. Zhang, H. Wang, F. Xiong, Z. Fan, B. Tang, J. Zhao, J. Yang, S. Song, M. Wang, SafeRAG: Benchmarking security in retrieval-augmented generation of large language model, in: Proceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long Papers), Association for Computational Linguistic...
-
[31]
R. Azzam, A. Musamih, S. Gebreab, K. Salah, M. Omar, Agentic LLM for anonymizing healthcare data with con- textual awareness, Knowledge-Based Systems 343 (2026) 116034. URL:https://doi.org/10.1016/j.knosys .2026.116034. doi:10.1016/j.knosys.2026.1160 34
-
[32]
Q. Han, Z. Yang, H. Lin, T. Qin, A plug-and-play knowledge-enhanced module for medical reports gener- ation, Knowledge-Based Systems 309 (2025) 112805. URL:https://doi.org/10.1016/j.knosys.202 4.112805. doi:10.1016/j.knosys.2024.112805
-
[33]
J. Liu, W. Hao, K. Cheng, G. Chen, X. Xie, CART: A traceable zero-shot planning framework for large lan- guage models with adaptive replanning, Knowledge- Based Systems 336 (2026) 115189. URL:https://do i.org/10.1016/j.knosys.2025.115189. doi:10.101 6/j.knosys.2025.115189
-
[34]
R. Hou, S. Chen, Y . Fan, G. Yu, L. Zhu, J. Sun, J. Liu, T. Ruan, MSDiagnosis: A benchmark and framework for evaluating large language models in multi-step clinical di- agnosis, Knowledge-Based Systems 330 (2025) 114524. URL:https://doi.org/10.1016/j.knosys.2025. 114524. doi:10.1016/j.knosys.2025.114524
-
[35]
Weis, Securing AI agents: Why traditional authoriza- tion isn’t enough, 2026
O. Weis, Securing AI agents: Why traditional authoriza- tion isn’t enough, 2026. URL:https://www.permit.i o/blog/securing-ai-agents-why-traditional-a uthorization-isnt-enough. 23
2026
-
[36]
S. Rose, O. Borchert, S. Mitchell, S. Connelly, Zero Trust Architecture, NIST Special Publication 800-207, National Institute of Standards and Technology, 2020. URL:http s://doi.org/10.6028/NIST.SP.800-207. doi:10.6 028/NIST.SP.800-207
-
[37]
URL:https://op enai.com/index/introducing-gpt-5-5/
OpenAI, Introducing GPT-5.5, 2026. URL:https://op enai.com/index/introducing-gpt-5-5/
2026
-
[38]
URL:ht tps://www.anthropic.com/news/claude-opus-4 -7
Anthropic, Introducing Claude Opus 4.7, 2026. URL:ht tps://www.anthropic.com/news/claude-opus-4 -7
2026
-
[39]
URL: https://api-docs.deepseek.com/news/news2604 24
DeepSeek, DeepSeek V4 Preview Release, 2026. URL: https://api-docs.deepseek.com/news/news2604 24
2026
-
[40]
URL:https://github .com/MoonshotAI/Kimi-K2.5
Moonshot AI, Kimi-K2.5, 2026. URL:https://github .com/MoonshotAI/Kimi-K2.5
2026
-
[41]
URL:https://docs .z.ai/guides/llm/glm-5.1
Z.AI, GLM-5.1: Overview, 2026. URL:https://docs .z.ai/guides/llm/glm-5.1
2026
-
[42]
Qwen Team, Qwen3.6-Plus: Towards real world agents,
-
[43]
URL:https://qwen.ai/blog?id=qwen3.6
-
[44]
URL: https://ai.google.dev/gemini-api/docs/mode ls/gemini-3.5-flash
Google AI for Developers, Gemini 3.5 Flash, 2026. URL: https://ai.google.dev/gemini-api/docs/mode ls/gemini-3.5-flash
2026
-
[45]
URL:https://seed .bytedance.com/en/seed2
ByteDance Seed, Seed2.0, 2026. URL:https://seed .bytedance.com/en/seed2
2026
-
[46]
URL:https://www
MiniMax, MiniMax M2.7, 2026. URL:https://www. minimax.io/models/text/m27. 24
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.