Learning What to Say to Your VLA: Mostly Harmless Vision Language Action Model Steering
Pith reviewed 2026-06-27 10:00 UTC · model grok-4.3
The pith
A framework searches for language sequences to steer frozen VLAs, distills them into a feedback policy, and conformalizes an improvement head to block harmful interventions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that interactively searching for language sequences that raise closed-loop VLA success, distilling those sequences into a language feedback policy, and training a conformalized improvement head yields both higher performance on seen conditions and strong guarantees against performance-degrading interventions on visual or semantic perturbations, all while leaving the underlying VLA frozen.
What carries the argument
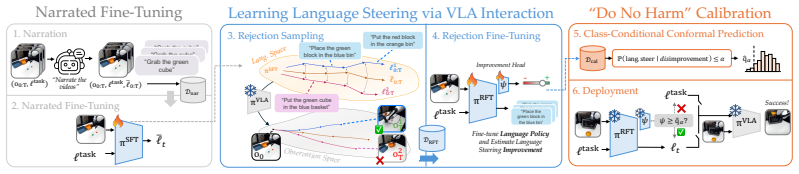
The conformalized improvement head attached to a distilled language feedback policy (LFP) that predicts when language steering will raise task success and withholds interventions otherwise.
If this is right
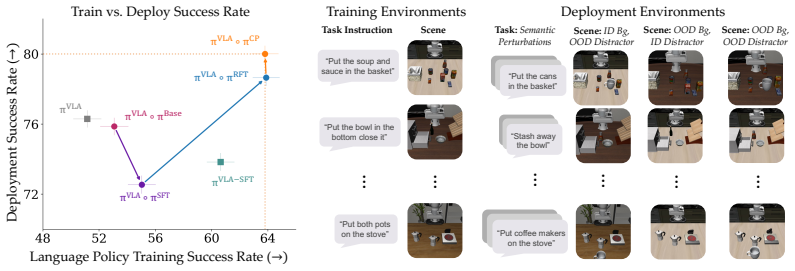
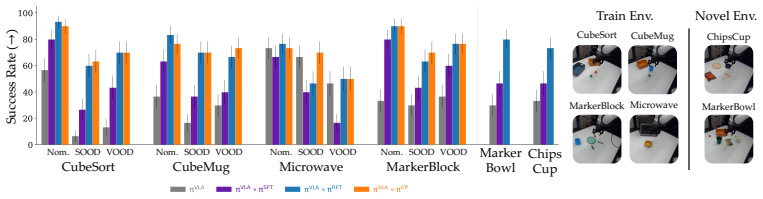
- On seen environments the conformalized LFP raises base VLA success by 24.7 percent in simulation and 65.0 percent on hardware.
- On visual and semantic perturbations the method supplies recovery behaviors absent from open-loop prompting while preserving strong harmlessness guarantees.
- The entire pipeline requires neither the original training distribution nor any fine-tuning of the underlying VLA.
- The improvement head can be calibrated once and then applied at test time to decide whether to invoke the distilled feedback policy.
Where Pith is reading between the lines
- The same search-plus-distillation pattern could be used to generate corrective language for other multimodal robot policies beyond VLAs.
- Because the search runs interactively, the approach may require offline computation before deployment in time-critical settings.
- Conformal calibration could be re-run periodically on new robot hardware to maintain the harmlessness property as sensor characteristics drift.
Load-bearing premise
The interactive search must reliably find language sequences whose distilled policy generalizes to new visual and semantic conditions, and the conformalized improvement head must correctly withhold any intervention that would lower performance.
What would settle it
A test set of visual or semantic perturbations on which the conformalized LFP produces lower task success than the base VLA instruction on more than a negligible fraction of trials.
Figures










read the original abstract
Vision-Language-Action (VLA) models provide a natural language interface to robot control, but the mapping from language to behavior is often brittle and unintuitive: semantically similar instructions can induce drastically different behaviors, while some capabilities may not be elicitable through prompting alone. As a result, both human instructions and zero-shot language models can fail to reliably steer VLAs toward successful task execution. In this work, we propose a framework that interactively searches for language sequences that improve closed-loop VLA task performance, distills these sequences into a test-time language feedback policy (LFP), and learns an improvement head that predicts when language steering will improve performance. We conformalize this improvement head to prevent harmful steering interventions, where the LFP decreases task performance relative to the original instruction on out-of-distribution scenarios. Crucially, our approach operates on arbitrary frozen pre-trained VLAs, requiring neither access to the original training distribution nor fine-tuning of the underlying model. On seen environments, our conformalized LFP improves base VLA performance by 24.7% in simulation and 65.0% in hardware. On visual and semantic perturbations, our conformalized LFP has strong harmlessness guarantees, and produces recovery behaviors not observed with open-loop prompting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for improving frozen pre-trained Vision-Language-Action (VLA) models at test time: an interactive search discovers language sequences that boost closed-loop performance, which are distilled into a Language Feedback Policy (LFP); an improvement head is then trained to predict when steering helps and is conformalized to withhold interventions that would degrade performance. The central claims are a 24.7% performance gain in simulation and 65.0% in hardware on seen environments, plus “strong harmlessness guarantees” on visual and semantic perturbations that produce recovery behaviors absent from open-loop prompting. The method requires no access to the VLA training distribution or fine-tuning.
Significance. If the numerical results and conformal coverage claims are substantiated, the work would be significant: it supplies a practical, model-agnostic route to elicit better VLA behavior via language while providing distribution-free safety against harmful steering on OOD inputs. The absence of any experimental protocol, dataset description, baseline comparisons, or verification that the conformal procedure was applied correctly in the supplied text, however, prevents assessment of whether these benefits are realized.
major comments (1)
- [Abstract] Abstract: the claim that conformalization of the improvement head yields “strong harmlessness guarantees” on visual and semantic perturbations rests on an unstated assumption of exchangeability between the (presumably in-distribution) calibration set and the OOD test regime. Standard conformal prediction theory requires this exchangeability for marginal coverage; the manuscript provides no argument or construction that restores it when perturbations are explicitly out-of-distribution and the interactive search occurs only on seen environments. This directly undermines the central harmlessness guarantee.
minor comments (1)
- [Abstract] Abstract: performance numbers (24.7 %, 65.0 %) are stated without any accompanying description of tasks, environments, number of trials, or statistical significance; even a high-level summary of the experimental protocol belongs in the abstract.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for highlighting this important theoretical point about the conformal prediction guarantees. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that conformalization of the improvement head yields “strong harmlessness guarantees” on visual and semantic perturbations rests on an unstated assumption of exchangeability between the (presumably in-distribution) calibration set and the OOD test regime. Standard conformal prediction theory requires this exchangeability for marginal coverage; the manuscript provides no argument or construction that restores it when perturbations are explicitly out-of-distribution and the interactive search occurs only on seen environments. This directly undermines the central harmlessness guarantee.
Authors: We agree that the manuscript does not supply an explicit argument or construction restoring exchangeability between the calibration set (drawn from seen environments where the interactive search occurs) and the explicitly perturbed OOD test regime. Standard conformal prediction coverage guarantees are marginal and require exchangeability; without it, the theoretical guarantee does not automatically transfer. The current text therefore overstates the strength of the claim for perturbations. We will revise the abstract to replace “strong harmlessness guarantees” with a more precise statement that the conformalized improvement head provides distribution-free coverage on the calibration distribution, with empirical results reported separately on perturbations. We will also add a short discussion of the exchangeability assumption and its limitations for OOD inputs. This change directly addresses the concern while preserving the empirical findings. revision: yes
Circularity Check
No circularity: claims rest on external conformal prediction and interactive search without self-referential reduction
full rationale
The paper describes an interactive search for language sequences, distillation into an LFP, and conformalization of an improvement head to yield performance gains and harmlessness guarantees on perturbations. No equations, fitted parameters, or self-citations appear in the abstract or method description that would make the reported 24.7%/65.0% improvements or coverage guarantees equivalent to the inputs by construction. Conformal prediction is invoked as a standard external technique rather than derived from the paper's own data or prior self-work; the OOD guarantee claim is an application of that method, not a renaming or self-definition. The derivation chain is therefore self-contained against external statistical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Useful language sequences for improving closed-loop VLA performance can be discovered by interactive search and distilled into a policy that generalizes without fine-tuning the base model.
invented entities (2)
-
Language Feedback Policy (LFP)
no independent evidence
-
Improvement head
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wanna, A
S. Wanna, A. Luhtaru, J. Salfity, R. Barron, J. Moore, C. Matuszek, and M. Pryor. Limited linguistic diversity in embodied ai datasets, 2026. URLhttps://arxiv.org/abs/2601. 03136
2026
-
[2]
Q. Li. Vlas are confined yet capable of generalizing to novel instructions, 2026. URLhttps: //arxiv.org/abs/2505.03500
Pith/arXiv arXiv 2026
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model, 2024. URL https://arxiv.org/abs/2406.09246
Pith/arXiv arXiv 2024
-
[4]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
Pith/arXiv arXiv 2025
-
[5]
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokin- sky, S. Cao, T. Charbonnier, V . Choudhary, F. Collins, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, M. Dhaka, J. DiCarlo, D. Driess, M. Equi, A. Esmail, Y . Fang, C. Finn, C. Glos- sop, T. Godden, I. Goryachev, L. Groom, H. Habeeb, H. Hancock, K. Hausman, G. H...
Pith/arXiv arXiv 2026
-
[6]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, A. Handa, M.-Y . Liu, D. Xiang, G. Wetzstein, and T.-Y . Lin. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models, 2025. URLhttps://arxiv.org/abs/2503.22020. 10
Pith/arXiv arXiv 2025
-
[7]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, W. Han, W. Pumacay, A. Wu, R. Hendrix, K. Farley, E. VanderBilt, A. Farhadi, D. Fox, and R. Krishna. Molmoact: Action reasoning models that can reason in space, 2025. URLhttps: //arxiv.org/abs/2508.07917
Pith/arXiv arXiv 2025
-
[8]
H. Fang, J. Duan, D. Clay, S. Wang, S. Liu, W. Huang, X. Fan, W.-C. Tsai, S. Chen, Y . R. Wang, S. Xing, J. Cho, J. S. Park, A. Eftekhar, P. Sushko, K. Farley, A. Wadhwa, C. Harrison, W. Han, Y .-C. Lee, E. VanderBilt, R. Hendrix, S. Ellawela, L. Ngoo, J. Chai, Z. Ren, A. Farhadi, D. Fox, and R. Krishna. Molmoact2: Action reasoning models for real-world d...
Pith/arXiv arXiv 2026
-
[9]
Y . Wu, A. Li, T. Hermans, F. Ramos, A. Bajcsy, and C. P ´erez-D’Arpino. Do what you say: Steering vision-language-action models via runtime reasoning-action alignment verification,
-
[10]
URLhttps://arxiv.org/abs/2510.16281
-
[11]
A. K. Jain, V . Mohta, S. Kim, A. Bhardwaj, J. Ren, Y . Feng, S. Choudhury, and G. Swamy. A smooth sea never made a skilled sailor: Robust imitation via learning to search, 2025. URL https://arxiv.org/abs/2506.05294
arXiv 2025
-
[12]
W. Xiao, H. Lin, A. Peng, H. Xue, T. He, Y . Xie, F. Hu, J. Wu, Z. Luo, L. J. Fan, G. Shi, and Y . Zhu. Self-improving vision-language-action models with data generation via residual rl, 2025. URLhttps://arxiv.org/abs/2511.00091
arXiv 2025
-
[13]
T. Kollar, S. Tellex, D. Roy, and N. Roy. Toward understanding natural language directions. In2010 5th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages 259–266, 2010. doi:10.1109/HRI.2010.5453186
-
[14]
Tellex, T
S. Tellex, T. Kollar, S. Dickerson, M. Walter, A. Banerjee, S. Teller, and N. Roy. Understanding natural language commands for robotic navigation and mobile manipulation.Proceedings of the AAAI Conference on Artificial Intelligence, 25(1):1507–1514, Aug. 2011. doi:10.1609/ aaai.v25i1.7979. URLhttps://ojs.aaai.org/index.php/AAAI/article/view/7979
2011
-
[15]
A. Z. Ren, A. Dixit, A. Bodrova, S. Singh, S. Tu, N. Brown, P. Xu, L. Takayama, F. Xia, J. Varley, Z. Xu, D. Sadigh, A. Zeng, and A. Majumdar. Robots that ask for help: Uncertainty alignment for large language model planners, 2023. URLhttps://arxiv.org/abs/2307. 01928
2023
-
[16]
L. X. Shi, Z. Hu, T. Z. Zhao, A. Sharma, K. Pertsch, J. Luo, S. Levine, and C. Finn. Yell at your robot: Improving on-the-fly from language corrections, 2024. URLhttps://arxiv. org/abs/2403.12910
arXiv 2024
-
[17]
W. Chen, J. S. Bhatia, C. Glossop, N. Mathihalli, R. Doshi, A. Tang, D. Driess, K. Pertsch, and S. Levine. Steerable vision-language-action policies for embodied reasoning and hierarchical control, 2026. URLhttps://arxiv.org/abs/2602.13193
Pith/arXiv arXiv 2026
- [18]
-
[19]
J. Kwok, X. Zhang, M. Xu, Y . Liu, A. Mirhoseini, C. Finn, and M. Pavone. Scaling verification can be more effective than scaling policy learning for vision-language-action alignment, 2026. URLhttps://arxiv.org/abs/2602.12281
arXiv 2026
-
[20]
S. Huang, J. Shao, K. Wang, Q. Chen, J. Sun, Y . Guo, M. Schwager, and J. Bohg. Break- ing lock-in: Preserving steerability under low-data vla post-training, 2026. URLhttps: //arxiv.org/abs/2604.23121. 11
Pith/arXiv arXiv 2026
-
[21]
Z. Chen, A. Tian, L. Wang, B. Joffe, Y . C. Lin, Y . Chen, S. Karamcheti, and D. Xu. Resteer: Quantifying and refining the steerability of multitask robot policies, 2026. URLhttps:// arxiv.org/abs/2603.17300
arXiv 2026
-
[22]
Z. Lin, J. Duan, H. Fang, D. Fox, R. Krishna, C. Tan, and B. Wen. Failsafe: Reasoning and recovery from failures in vision-language-action models, 2025. URLhttps://arxiv.org/ abs/2510.01642
arXiv 2025
-
[23]
B. Zhang, Y . Zhang, J. Ji, Y . Lei, Y . Cai, J. Dai, Y . Chen, and Y . Yang. Safevla: Towards safety alignment of vision-language-action model via constrained learning, 2026. URLhttps:// arxiv.org/abs/2503.03480
Pith/arXiv arXiv 2026
- [24]
- [25]
-
[26]
H. Buurmeijer, C. A. Alonso, A. Swann, and M. Pavone. Observing and controlling features in vision-language-action models, 2026. URLhttps://arxiv.org/abs/2603.05487
arXiv 2026
-
[27]
A. Swann, L. McGranahan, H. Buurmeijer, M. K. III, and M. Schwager. Sparse autoencoders reveal interpretable and steerable features in vla models, 2026. URLhttps://arxiv.org/ abs/2603.19183
Pith/arXiv arXiv 2026
-
[28]
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti. Safe: Multitask failure detection for vision-language-action models, 2025. URLhttps://arxiv.org/abs/ 2506.09937
arXiv 2025
-
[29]
V ovk, A
V . V ovk, A. Gammerman, and G. Shafer.Algorithmic learning in a random world. Springer, 2005
2005
-
[30]
Anthony, Z
T. Anthony, Z. Tian, and D. Barber. Thinking fast and slow with deep learning and tree search. Advances in neural information processing systems, 30, 2017
2017
-
[31]
W. Sun, G. J. Gordon, B. Boots, and J. Bagnell. Dual policy iteration.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[32]
Levine and V
S. Levine and V . Koltun. Guided policy search. InInternational conference on machine learning, pages 1–9. PMLR, 2013
2013
-
[33]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning, 2023. URLhttps://arxiv.org/abs/2306. 03310
2023
-
[34]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
Pith/arXiv arXiv 2025
-
[35]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
Pith/arXiv arXiv 2025
-
[36]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. Lora: Low- rank adaptation of large language models, 2021. URLhttps://arxiv.org/abs/2106. 09685
2021
-
[37]
C. Clark, J. Zhang, Z. Ma, J. S. Park, M. Salehi, R. Tripathi, S. Lee, Z. Ren, C. D. Kim, Y . Yang, V . Shao, Y . Yang, W. Huang, Z. Gao, T. Anderson, J. Zhang, J. Jain, G. Stoica, W. Han, A. Farhadi, and R. Krishna. Molmo2: Open weights and data for vision-language models with video understanding and grounding, 2026. URLhttps://arxiv.org/abs/2601.10611
Pith/arXiv arXiv 2026
-
[38]
Gpt-5.4 thinking system card
OpenAI. Gpt-5.4 thinking system card. Technical report, OpenAI, Mar. 2026. URLhttps: //deploymentsafety.openai.com/gpt-5-4-thinking/gpt-5-4-thinking.pdf. Ac- cessed: 2026-05-12
2026
-
[39]
A. J. Hancock, A. Z. Ren, and A. Majumdar. Run-time observation interventions make vision- language-action models more visually robust, 2024. URLhttps://arxiv.org/abs/2410. 01971
2024
-
[40]
A. Wagenmaker, M. Nakamoto, Y . Zhang, S. Park, W. Yagoub, A. Nagabandi, A. Gupta, and S. Levine. Steering your diffusion policy with latent space reinforcement learning, 2025. URL https://arxiv.org/abs/2506.15799
Pith/arXiv arXiv 2025
-
[41]
Nakamura, A
K. Nakamura, A. L. Bishop, S. Man, A. M. Johnson, Z. Manchester, and A. Bajcsy. How to train your latent control barrier function: Smooth safety filtering under hard-to-model con- straints.8th Annual Learning for Dynamics & Control Conference, 2026
2026
-
[42]
X. L. Li, N. Chowdhury, D. D. Johnson, T. Hashimoto, P. Liang, S. Schwettmann, and J. Steinhardt. Eliciting language model behaviors with investigator agents, 2025. URL https://arxiv.org/abs/2502.01236. 13 7 Appendix 7.1 Method and Implementation Details Narrated Fine-tuning.To generate the narration prior forπ SFT, we leverage the video understand- ing c...
arXiv 2025
-
[43]
However, it is not able to steer on task 15, whileπ VLA andπ VLA-SFT are able to perform better. Note that figure 13 includes the first 6 tasks from the novel task composition suite, as tasks 16-22 are zero for all baselines. Hardware results are broken down by task and perturbation condition in Table 12.π RFT sub- stantially improves over the base VLA on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.