Pro-DG: Procedural Diffusion Guidance for Architectural Facade Generation
Pith reviewed 2026-05-22 22:09 UTC · model grok-4.3
The pith
Hierarchical procedural rules embedded in diffusion control maps allow structural edits to facades while preserving local appearance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating hierarchical alignment directly into control maps derived from procedural rules, the diffusion process can be guided to perform extensive structural modifications on facade imagery while maintaining local appearance fidelity.
What carries the argument
Hierarchical procedural control maps generated by an inverse procedural module and supplied to a ControlNet pipeline
If this is right
- Floor duplication and window rearrangement become feasible while local textures remain consistent.
- The generated images preserve architectural identity better than inpainting-based methods.
- Quantitative benchmarks and user feedback demonstrate accurate, controllable edits.
- The same pipeline supports multiple types of structural changes guided by the recovered hierarchy.
Where Pith is reading between the lines
- Design software could expose these procedural controls to let non-experts create varied yet coherent building variants from one reference photo.
- The approach might transfer to other image domains that contain repeating hierarchical structures, such as city blocks or patterned textiles.
- If the inverse recovery step is made more robust to partial occlusions, the method could handle photographs taken under less ideal conditions.
Load-bearing premise
The inverse procedural module can reliably recover an accurate hierarchical layout and structural features from a single input image and its segmentation.
What would settle it
If blind user tests or quantitative metrics on a set of facades with varied hierarchies show no measurable improvement over inpainting baselines in structural accuracy or appearance consistency, the central claim would be falsified.
Figures









read the original abstract
We use hierarchical procedural rules for the generation of control maps within the stable diffusion framework to produce photo-realistic architectural facade images. Starting from a single input image and its segmentation, we apply an inverse procedural module to identify the facade's hierarchical layout. Leveraging this hierarchy and structural features, we introduce a novel ControlNet pipeline that generates new facade imagery guided by procedural transformations. Our method enables various structural edits, including floor duplication and window rearrangement, by integrating hierarchical alignment directly into control maps. This precisely guides the diffusion-based generative process, ensuring local appearance fidelity alongside extensive structural modifications. Comprehensive evaluations, including comparisons with inpainting-based approaches and synthetic benchmarks, confirm our approach's superior capability in preserving architectural identity and achieving accurate, controllable edits. Quantitative results and user feedback validate our method's effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Pro-DG, a framework that combines inverse procedural modeling with a ControlNet-augmented Stable Diffusion pipeline to generate and structurally edit architectural facade images. From a single input image and its segmentation, an inverse procedural module extracts a hierarchical layout, which is then transformed procedurally and used to condition the diffusion process via aligned control maps. The authors claim this enables edits such as floor duplication and window rearrangement while preserving local appearance, and that it outperforms inpainting baselines and synthetic benchmarks in quantitative and user studies.
Significance. If the inverse procedural recovery step proves accurate and generalizable, the method could offer a significant advance in controllable generation for architectural imagery by allowing procedural structural changes that go beyond pixel-level inpainting. This would be valuable for design exploration and visualization tasks. The integration of procedural hierarchies into diffusion control maps is a promising direction, though its impact depends on the reliability of the front-end recovery module, which is not quantitatively validated in the provided text.
major comments (2)
- [Abstract] The abstract states that 'comprehensive evaluations... confirm our approach's superior capability', yet no quantitative tables, metrics, error bars, or specific comparison details are included, preventing verification of the performance claims.
- [Method (Inverse Procedural Module)] The method's ability to perform structural edits like floor duplication relies on the inverse procedural module accurately recovering the hierarchical layout from a single image and segmentation. No evaluation metrics for this module's accuracy (such as IoU for floor/window detection or success rates on test cases) are referenced, which is a load-bearing assumption for the central claims.
minor comments (1)
- [Abstract] The term 'hierarchical alignment directly into control maps' is used without a brief definition or reference to the specific mechanism in the ControlNet pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where the manuscript's claims require stronger supporting evidence. We address each major comment below and commit to revisions that will improve the clarity and verifiability of the results.
read point-by-point responses
-
Referee: [Abstract] The abstract states that 'comprehensive evaluations... confirm our approach's superior capability', yet no quantitative tables, metrics, error bars, or specific comparison details are included, preventing verification of the performance claims.
Authors: We agree that the abstract's summary claim would benefit from more concrete support to enable immediate verification. The current version does not embed specific metrics or tables within the abstract itself. We will revise the abstract to include brief references to key quantitative outcomes (e.g., reported improvements in perceptual metrics and user preference rates) and will ensure the Results section contains full tables with metrics, baselines, and error bars. revision: yes
-
Referee: [Method (Inverse Procedural Module)] The method's ability to perform structural edits like floor duplication relies on the inverse procedural module accurately recovering the hierarchical layout from a single image and segmentation. No evaluation metrics for this module's accuracy (such as IoU for floor/window detection or success rates on test cases) are referenced, which is a load-bearing assumption for the central claims.
Authors: This observation is correct and highlights a gap in the current presentation. While the end-to-end edit quality provides indirect evidence, direct quantitative validation of the inverse procedural recovery step is absent. We will add a dedicated evaluation subsection reporting accuracy metrics, including IoU scores for floor and window detection as well as success rates on a test set of facade images, to substantiate the module's reliability. revision: yes
Circularity Check
No circularity: pipeline described without self-referential equations or fitted predictions
full rationale
The abstract and description present a sequential pipeline: input image + segmentation -> inverse procedural module for hierarchy -> ControlNet with procedural transformations for edits. No equations, fitted parameters, or predictions are mentioned that reduce by construction to inputs. No self-citations, uniqueness theorems, or ansatzes are invoked. The central claims rest on the integration of hierarchical alignment into control maps, which is presented as an independent methodological step rather than a renaming or self-definition. This is the common case of a self-contained description against external benchmarks such as inpainting comparisons.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adobe firefly: Generative ai for creative content,
Adobe Inc. Adobe firefly: Generative ai for creative content,
-
[2]
More details available at https://www
Adobe Firefly powers features such as Generative Fill in Photoshop. More details available at https://www. adobe.com/sensei/generative- ai/firefly. html. 5
-
[3]
Adobe Inc. Adobe photoshop 2025, 2025. Accessed: 2025-03-08. Available at https://www.adobe.com/ products/photoshop.html. 5
work page 2025
-
[4]
Daniel G. Aliaga, Paul A. Rosen, and David R. Bekins. Style grammars for interactive visualization of architecture. IEEE Transactions on Visualization and Computer Graphics , 13 (4):546–558, 2007. 2
work page 2007
-
[5]
Blended diffusion for text-driven editing of natural images
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18208–18218, 2022. 2
work page 2022
-
[6]
Spatext: Spatio-textual representation for con- trollable image generation
Omri Avrahami, Thomas Hayes, Oran Gafni, Sonal Gupta, Yaniv Taigman, Devi Parikh, Dani Lischinski, Ohad Fried, and Xi Yin. Spatext: Spatio-textual representation for con- trollable image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ,
-
[7]
Multidiffusion: Fusing diffusion paths for controlled image generation
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. Multidiffusion: Fusing diffusion paths for controlled image generation. In Proceedings of the International Conference on Machine Learning, 2023. 2 8
work page 2023
-
[8]
Sliced wasserstein distances for comparing proba- bility distributions
Nicolas Bonneel, Justin Rabin, Gabriel Peyr ´e, and Marco Cuturi. Sliced wasserstein distances for comparing proba- bility distributions. In Advances in Neural Information Pro- cessing Systems, pages 1124–1132, 2015. 6
work page 2015
-
[9]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. In- structPix2Pix: Learning to follow image editing instructions. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2
work page 2023
-
[10]
Training-free layout control with cross-attention guidance
Minghao Chen, Iro Laina, and Andrea Vedaldi. Training-free layout control with cross-attention guidance. In Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 5343–5352, 2024. 2
work page 2024
-
[11]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. In Advances in Neural Infor- mation Processing Systems (NeurIPS) 33, pages 6840–6851,
-
[12]
Zero-1-to- 3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to- 3: Zero-shot one image to 3d object. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 2
work page 2023
-
[13]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection, 2023
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection, 2023. 2
work page 2023
-
[14]
Facade parsing using HOG, LBP, and structural constraints
Markus Mathias, Aleksandar Martinovic, Jonah Weis- senberg, and Luc Van Gool. Facade parsing using HOG, LBP, and structural constraints. In 2011 IEEE International Conference on Computer Vision Workshops (ICCV Work- shops), pages 6–13, 2011. 2
work page 2011
-
[15]
Object 3dit: language-guided 3d-aware image editing
Oscar Michel, Anand Bhattad, Eli VanderBilt, Ranjay Kr- ishna, Aniruddha Kembhavi, and Tanmay Gupta. Object 3dit: language-guided 3d-aware image editing. In Proceed- ings of the 37th International Conference on Neural Infor- mation Processing Systems, Red Hook, NY , USA, 2023. Cur- ran Associates Inc. 2
work page 2023
-
[16]
Diffusion handles enabling 3d edits for diffusion models by lifting ac- tivations to 3d
Oscar Michel, Anand Bhattad, Eli VanderBilt, Ranjay Kr- ishna, Aniruddha Kembhavi, and Tanmay Gupta. Diffusion handles enabling 3d edits for diffusion models by lifting ac- tivations to 3d. arXiv preprint arXiv:2307.11073, 2023. 2, 3, 5, 7
-
[17]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. In 2023 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) , pages 6038–6047, 2023. 3, 5
work page 2023
-
[18]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i- adapter: Learning adapters to dig out more controllable abil- ity for text-to-image diffusion models, 2023. 2
work page 2023
-
[19]
Procedural modeling of buildings
Pascal M ¨uller, Peter Wonka, Simon Haegler, Andreas Ulmer, and Luc Van Gool. Procedural modeling of buildings. ACM Transactions on Graphics (TOG), 25(3):614–623, 2006. 2
work page 2006
-
[20]
Interactive coherence-based facade modeling
Przemyslaw Musialski, Michael Wimmer, and Peter Wonka. Interactive coherence-based facade modeling. Computer Graphics Forum, 31:661–670, 2012. 3
work page 2012
-
[21]
A survey of urban reconstruction
Przemyslaw Musialski, Michael Wimmer, Luc Van Gool, Scott Irwin, Michael Waechter, and Werner Purgathofer. A survey of urban reconstruction. Computer Graphics Forum, 32(6):146–177, 2013. 2
work page 2013
-
[22]
Drag your gan: Interactive point-based manipulation on the generative image manifold
Xingang Pan, Ayush Tewari, Thomas Leimk ¨uhler, Lingjie Liu, Abhimitra Meka, and Christian Theobalt. Drag your gan: Interactive point-based manipulation on the generative image manifold. ACM Transactions on Graphics (Proceed- ings of SIGGRAPH 2023), 42(4):1–12, 2023. 2
work page 2023
-
[23]
Yoav I. H. Parish and Pascal M ¨uller. Procedural modeling of cities. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques (SIG- GRAPH), pages 301–308, New York, NY , USA, 2001. ACM. 2
work page 2001
-
[24]
Fac ¸aid: A transformer model for neuro-symbolic facade reconstruction
Aleksander Plocharski, Jan Swidzinski, Joanna Porter- Sobieraj, and Przemyslaw Musialski. Fac ¸aid: A transformer model for neuro-symbolic facade reconstruction. In SIG- GRAPH Asia 2024 Conference Papers, New York, NY , USA,
work page 2024
-
[25]
Association for Computing Machinery. 1, 2, 3
-
[26]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gen- eration with clip latents. arXiv preprint arXiv:2204.06125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Nathanael Ripperda and Claus Brenner. Application of a for- mal grammar to facade reconstruction in semiautomatic and automatic environments. In Photogrammetric Image Analy- sis (PIA), pages 29–38. Springer, 2009. 2
work page 2009
-
[28]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 2
work page 2022
-
[29]
Photorealistic text-to-image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. In Advances in Neural Information Processing Systems (NeurIPS) 35, 2022. 2
work page 2022
-
[30]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 6
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[31]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the 32nd International Conference on Machine Learning (ICML) , pages 2256–2265. PMLR, 2015. 2
work page 2015
-
[32]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. In 8th International Confer- ence on Learning Representations (ICLR), 2020. 1, 2
work page 2020
-
[33]
Object- stitch: Object compositing with diffusion model
Yizhi Song, Zhifei Zhang, Zhe Lin, Scott Cohen, Brian Price, Jianming Zhang, Soo Ye Kim, and Daniel Aliaga. Object- stitch: Object compositing with diffusion model. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18310–18319, 2023. 2
work page 2023
-
[34]
Inverse procedural modeling by automatic generation of l-systems
Ond ˇrej St’ava, Jiˇr´ı Vanek, Bedrich Benes, Ross Mead, and Nathan Miller. Inverse procedural modeling by automatic generation of l-systems. Computer Graphics Forum, 29(2): 665–674, 2010. 2
work page 2010
-
[35]
Pictorial and formal aspects of shape and shape grammars
George Stiny. Pictorial and formal aspects of shape and shape grammars. Technical report, Environmental Design 9 and Research Center, Massachusetts Institute of Technology,
-
[36]
Automated facade interpretation using im- age parsing
Olivier Teboul, Lo ¨ıc Simon, Panagiotis Koutsourakis, and Nikos Paragios. Automated facade interpretation using im- age parsing. In 2011 International Conference on 3D Imag- ing, Modeling, Processing, Visualization and Transmission , pages 50–57, 2011. 2
work page 2011
-
[37]
Shape grammar parsing via reinforcement learning
Olivier Teboul, Panagiotis Koutsourakis, Lo ¨ıc Simon, Nikos Paragios, and Andrea Torsello. Shape grammar parsing via reinforcement learning. Computer Vision and Image Under- standing, 117(1):1–11, 2013. 1, 2
work page 2013
-
[38]
Peter Wonka, Michael Wimmer, Franc ¸ois Sillion, and William Ribarsky. Instant architecture. ACM Transactions on Graphics (TOG), 22(3):669–677, 2003. 1, 2, 3
work page 2003
-
[39]
Pars- ing fac ¸ade with rank-one approximation
Chao Yang, Tian Han, Long Quan, and Chiew-Lan Tai. Pars- ing fac ¸ade with rank-one approximation. In2012 IEEE Con- ference on Computer Vision and Pattern Recognition, pages 1720–1727, 2012. 4
work page 2012
-
[40]
Adding Conditional Control to Text-to-Image Diffusion Models
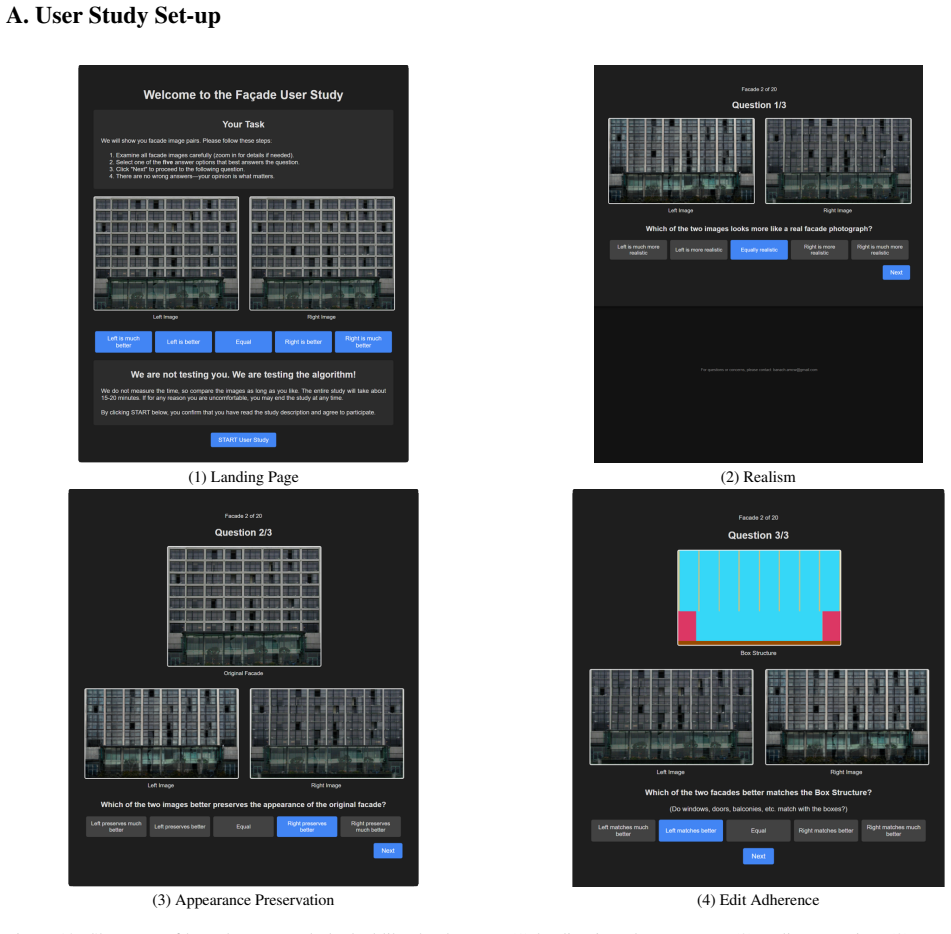
Lvmin Zhang and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. arXiv preprint arXiv:2302.05543, 2023. 2 10 A. User Study Set-up (1) Landing Page (2) Realism (3) Appearance Preservation (4) Edit Adherence Figure 12. Showcase of how the user study looked like the the user: (1) landing introductory page; (2) realism question;...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.