Predicting Performance of Symbolic and Prompt Programs with Examples
Pith reviewed 2026-05-22 01:05 UTC · model grok-4.3
The pith
Symbolic programs show all-or-nothing performance while prompt programs show gradual success rates, so a few passing tests certify one but not the other.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
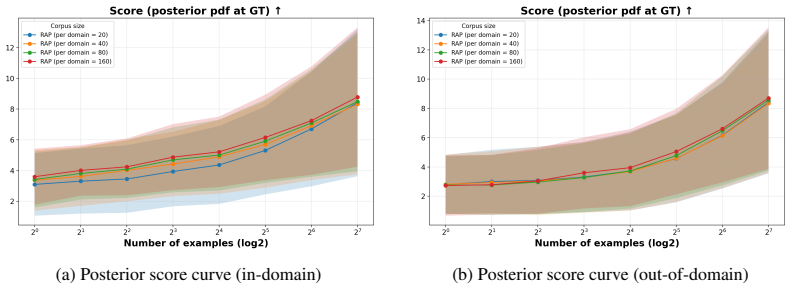
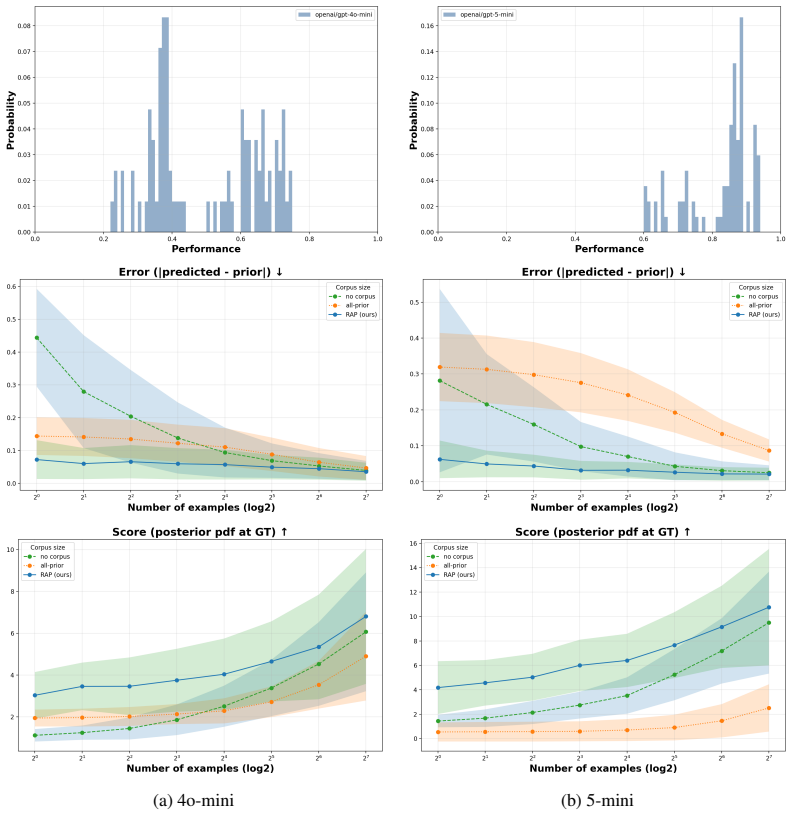
By compiling empirical performance priors from a corpus of diverse programs and tasks, the authors find that performance for symbolic programs (e.g., Python) are all or nothing, while prompt programs have a diffuse prior with many nearly-correct programs. This difference explains why a few passing tests can certify symbolic programs but not prompt programs. Building on this insight, they develop RAP (Retrieved Approximate Prior), which retrieves similar tasks and prompt programs from an existing corpus to construct a proxy prior, which is then used to predict performance. They show RAP achieves solid performances.
What carries the argument
RAP (Retrieved Approximate Prior), a retrieval method that pulls similar tasks and prompt programs from a corpus to build a proxy prior over performance values for predicting results on unseen tasks.
If this is right
- A small number of passing tests can reliably indicate that a symbolic program will perform well on unseen tasks.
- Prompt programs require either more tests or additional prior information before their overall performance can be predicted confidently.
- Constructing a task-specific prior via retrieval improves prediction accuracy compared with using a uniform or overall corpus prior.
- Limited in-domain examples plus corpus retrieval suffice to estimate deployment performance without exhaustive testing.
Where Pith is reading between the lines
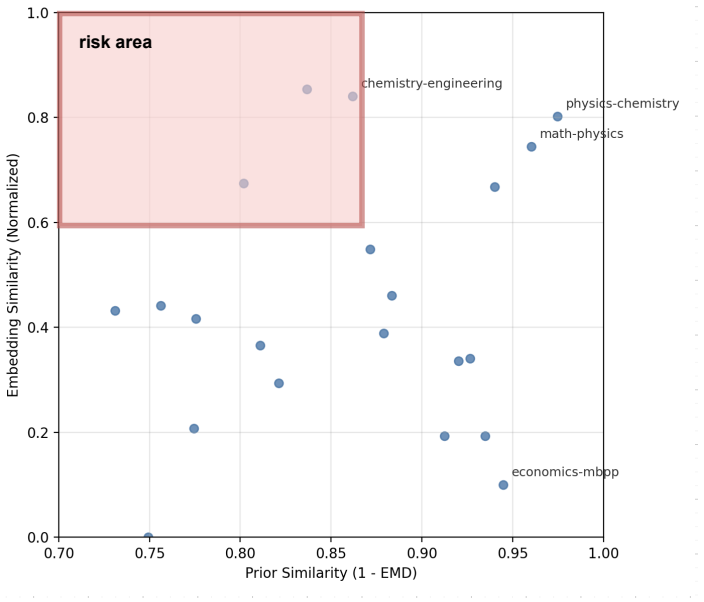
- Curating larger or more varied corpora would likely strengthen the quality of retrieved priors and extend RAP to entirely new task domains.
- The same Bernoulli-plus-retrieval approach could be tested for predicting reliability in other generative settings such as data synthesis or model outputs.
- Direct comparison of RAP predictions against real-world deployment outcomes on a new corpus would test how well the proxy prior generalizes.
Load-bearing premise
A corpus of diverse programs and tasks supplies representative empirical performance priors that can be usefully approximated by retrieving similar items for a new domain and task set.
What would settle it
If applying RAP to a fresh domain yields predictions no more accurate than a generic corpus-wide prior, or if the retrieved proxy prior fails to match the actual distribution of successes observed on held-out tasks.
Figures









read the original abstract
LLM prompting is widely used for naturally stated tasks, yet it is unreliable it may succeed on a few test cases but fail at deployment time. We study performance prediction: given a program, either symbolic (e.g. Python) or a prompt executed on an LLM, and a few in-domain examples, predict its performance on unseen tasks from the same domain. We use a simple coin-flip model, treating each pass/fail program execution as a Bernoulli random variable, whose success probability is the programs unknown performance. In this model, performance depends entirely on: 1) the observed execution outcomes on test cases, and 2) a prior over performances. We compile empirical performance priors from a corpus of diverse programs and tasks, and find that performance for symbolic programs (e.g., Python) are all or nothing, while prompt programs have a diffuse prior with many nearly-correct programs. This difference explains why a few passing tests can certify symbolic programs but not prompt programs. Building on this insight, we develop RAP (Retrieved Approximate Prior), which retrieves similar tasks and prompt programs from an existing corpus to construct a proxy prior, which is then used to predict performance. We show RAP achieves solid performances.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Bernoulli model for predicting the performance of symbolic programs (e.g., Python) and prompt programs executed on LLMs, given a few in-domain test cases. Performance is modeled as depending on observed pass/fail outcomes and a prior over success probabilities. The authors compile empirical performance priors from a corpus of diverse programs and tasks, observing that symbolic programs exhibit concentrated (all-or-nothing) distributions while prompt programs exhibit diffuse priors. Building on this, they introduce RAP (Retrieved Approximate Prior), which retrieves similar tasks and prompt programs from the corpus to construct a proxy prior for prediction, and claim that RAP achieves solid performances.
Significance. If the results hold, the work provides a principled probabilistic framing for performance prediction that highlights a key distinction between symbolic and prompt-based approaches, with potential implications for reliable deployment of LLM-generated code. The use of retrieved empirical priors is a novel direction for approximating task-specific distributions without exhaustive testing. The simple coin-flip model is a strength for interpretability, but overall significance depends on rigorous validation of the retrieval mechanism and quantitative evidence that the proxy prior improves predictions.
major comments (3)
- [Abstract] Abstract: The central claim that 'RAP achieves solid performances' is presented without any quantitative results, error bars, dataset details, ablation studies, or comparisons to a global prior or random retrieval baseline. This is load-bearing for the paper's main empirical contribution.
- [RAP description] RAP description: The proxy prior construction assumes that similarity (via task/prompt retrieval from the corpus) selects items whose observed performance distributions closely match the target; however, no correlation analysis, validation experiment, or check that retrieval outperforms a non-retrieved empirical prior is provided to support this assumption, which is load-bearing for the method's validity.
- [Empirical priors] Empirical priors compilation: If test tasks overlap with the corpus used to build the prior, the prediction risks reducing to in-sample fitting; the manuscript should specify the corpus construction, any held-out splits, or retrieval protocol to rule out circularity.
minor comments (1)
- [Abstract] Abstract: The sentence 'yet it is unreliable it may succeed on a few test cases but fail at deployment time' is missing punctuation or a connecting phrase, which reduces readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for strengthening the empirical presentation and methodological validation in our work on performance prediction for symbolic and prompt programs. We address each major comment below and have revised the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'RAP achieves solid performances' is presented without any quantitative results, error bars, dataset details, ablation studies, or comparisons to a global prior or random retrieval baseline. This is load-bearing for the paper's main empirical contribution.
Authors: We agree that the abstract would benefit from greater specificity to better convey the empirical contributions. In the revised manuscript, we have updated the abstract to include key quantitative results such as average prediction accuracy with error bars, dataset characteristics (number of tasks and programs), and explicit comparisons to a global prior and random retrieval baseline. These details are drawn directly from the experiments reported in the main body. revision: yes
-
Referee: [RAP description] RAP description: The proxy prior construction assumes that similarity (via task/prompt retrieval from the corpus) selects items whose observed performance distributions closely match the target; however, no correlation analysis, validation experiment, or check that retrieval outperforms a non-retrieved empirical prior is provided to support this assumption, which is load-bearing for the method's validity.
Authors: This assumption is central to RAP, and we acknowledge the need for explicit validation. We have added new analysis in the revised manuscript, including a correlation study between retrieval similarity scores and alignment of performance distributions, plus an ablation experiment comparing RAP against a non-retrieved global empirical prior. The results demonstrate that retrieval yields improved predictive performance, supporting the proxy prior approach. revision: yes
-
Referee: [Empirical priors] Empirical priors compilation: If test tasks overlap with the corpus used to build the prior, the prediction risks reducing to in-sample fitting; the manuscript should specify the corpus construction, any held-out splits, or retrieval protocol to rule out circularity.
Authors: We appreciate this concern regarding potential overlap. The revised manuscript now provides a detailed description of corpus construction, explicitly noting the use of held-out splits where test tasks are excluded from prior compilation. We also clarify the retrieval protocol, which relies on similarity metrics designed to prevent direct task or program overlap with the evaluation set, thereby avoiding in-sample fitting. revision: yes
Circularity Check
No circularity: empirical priors and retrieval form an independent approximation
full rationale
The paper's chain begins with a standard Bernoulli model for pass/fail outcomes, compiles observed performance distributions directly from a held-out corpus of programs and tasks, and then applies retrieval to select a proxy prior for a new target. This retrieval step does not reduce the final performance prediction to the input observations by construction; the proxy is an external approximation whose quality is checked against unseen tasks. No equations equate the output to a fitted parameter, no self-citation supplies a uniqueness theorem, and the symbolic-versus-prompt distinction is an empirical observation rather than a definitional loop. The method therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- empirical performance prior
axioms (1)
- domain assumption Each pass/fail outcome on a test case is an independent Bernoulli trial whose success probability equals the program's unknown fixed performance on the domain.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use a simple coin-flip model, treating each pass/fail program execution as a Bernoulli random variable, whose success probability θ is the programs unknown performance... We compile empirical performance priors from a corpus of diverse programs and tasks, and find that performance for symbolic programs (e.g., Python) are all or nothing, while prompt programs have a diffuse prior with many nearly-correct programs.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RAP (Retrieved Approximate Prior), which retrieves similar tasks and prompt programs from an existing corpus to construct a proxy prior
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Agrawal, L. A., Tan, S., Soylu, D., Ziems, N., Khare, R., Opsahl-Ong, K., Singhvi, A., Shandilya, H., Ryan, M. J., Jiang, M., et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., C...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
On the Measure of Intelligence
Chollet, F. On the measure of intelligence.arXiv preprint arXiv:1911.01547,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[4]
Holistic Evaluation of Language Models
Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y ., Narayanan, D., Wu, Y ., Kumar, A., et al. Holistic evaluation of language models.arXiv preprint arXiv:2211.09110,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URLhttps://arxiv.org/abs/2401.00595. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744,
-
[6]
Predictaboard: Benchmarking llm score predictability.arXiv preprint arXiv:2502.14445,
Pacchiardi, L., V oudouris, K., Slater, B., Mart ´ınez-Plumed, F., Hern´andez-Orallo, J., Zhou, L., and Schellaert, W. Predictaboard: Benchmarking llm score predictability.arXiv preprint arXiv:2502.14445,
-
[7]
Rethinking llm evaluation: Can we evaluate llms with 200x less data?arXiv preprint arXiv:2510.10457,
Wang, S., Wang, C., Fu, W., Min, Y ., Feng, M., Guan, I., Hu, X., He, C., Wang, C., Yang, K., et al. Rethinking llm evaluation: Can we evaluate llms with 200x less data?arXiv preprint arXiv:2510.10457,
-
[8]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
10 Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
How predictable are large language model capabilities? a case study on big-bench
Ye, Q., Fu, H., Ren, X., and Jia, R. How predictable are large language model capabilities? a case study on big-bench. InFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 7493–7517,
work page 2023
-
[10]
URLhttps://arxiv.org/abs/2005.00663. Zhou, L., Schellaert, W., Mart´ınez-Plumed, F., Moros-Daval, Y ., Ferri, C., and Hern´andez-Orallo, J. Larger and more instructable language models become less reliable.Nature, 634(8032):61– 68,
-
[11]
URL https://www.nature.com/articles/ s41586-024-07930-y
doi: 10.1038/s41586-024-07930-y. URL https://www.nature.com/articles/ s41586-024-07930-y. Zhou, L., Moreno-Casares, P. A., Martnez-Plumed, F., Burden, J., Burnell, R., Cheke, L., Ferri, C., Marcoci, A., Mehrbakhsh, B., Moros-Daval, Y ., heigeartaigh, S. ., Rutar, D., Schellaert, W., V oudouris, K., and Hernndez-Orallo, J. Predictable artificial intelligence,
-
[12]
URL https: //arxiv.org/abs/2310.06167. 11 A Experiments Details A.1 Hyperparameters Setting RAP involves three hyperparameters in our experiments: the number of retrieved tasks, set ton= 100 ; the number of retrieved prompt programs, set to K= 5 ; and the maximum prior concentration, set to cmax =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.