Multimodal Image Colorization: Quantifying the Impact of Text-Conditioned Guidance on Grayscale-to-Color Translation
Pith reviewed 2026-06-26 21:30 UTC · model grok-4.3
The pith
Text conditioning on U-Net and Stable Diffusion models improves grayscale-to-color translation on multiple metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
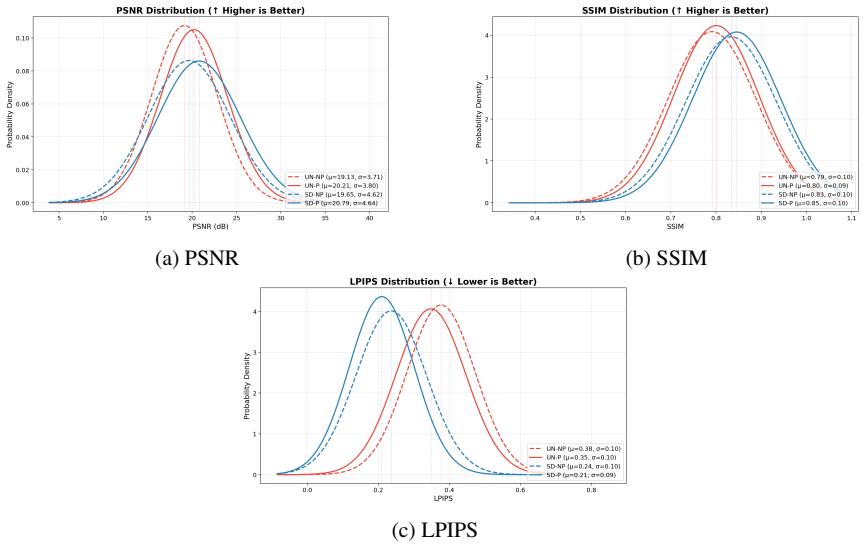
The authors establish that text conditioning provides consistent, measurable improvements to colorization quality across both architecture scales, with the listed percentage gains in PSNR, SSIM, colorfulness, and LPIPS reduction.
What carries the argument
Ablation study comparing models with and without CLIP text conditioning while holding all other variables constant, using standard image quality metrics.
Load-bearing premise
That the chosen metrics accurately reflect overall colorization quality and that adding text conditioning does not introduce any uncontrolled changes to the model or training process.
What would settle it
A human evaluation study where raters show no difference or prefer the unconditioned colorizations despite the metric gains.
Figures




read the original abstract
Grayscale images are commonly found in historical photography restoration, medical imaging, and artistic media. However, automatically applying color to these images remains a significant challenge in computer vision because many plausible colorizations can correspond to the same grayscale input. In this work, we quantify the effect of text conditioning on pixel-level and perceptual metrics for grayscale-to-color image models. Specifically, we compare two architectures, a U-Net and Stable Diffusion 1.5, each tested with and without CLIP text conditioning while holding all other variables constant. Our results show that text conditioning improves PSNR by 5.6%, SSIM by 1.2%, and colorfulness by 36.6%, while reducing LPIPS by 7.6% in the U-Net tier. In the Stable Diffusion tier, text conditioning improves PSNR by 5.8%, SSIM by 1.5%, and colorfulness by 0.6%, while reducing LPIPS by 11.3%. These results indicate that text conditioning provides consistent, measurable improvements to colorization quality across both architecture scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically compares U-Net and Stable Diffusion 1.5 models for grayscale-to-color translation, each run with and without CLIP text conditioning while asserting that all other variables are held constant. It reports that text conditioning yields PSNR gains of 5.6% (U-Net) and 5.8% (SD), SSIM gains of 1.2% and 1.5%, colorfulness gains of 36.6% and 0.6%, and LPIPS reductions of 7.6% and 11.3%.
Significance. If the paired runs are truly isolated to the addition of text conditioning, the work supplies concrete quantitative evidence on the value of multimodal guidance for colorization quality across model scales, using both pixel-level (PSNR/SSIM) and perceptual (LPIPS/colorfulness) metrics. This could inform design choices in restoration and generative pipelines.
major comments (2)
- [Abstract] Abstract: the headline claim that text conditioning alone produces the listed metric deltas requires explicit confirmation that the 'with' and 'without' models share identical architectures, parameter counts, training schedules, loss functions, and inference settings. No hyper-parameter table, model diagram, or description of how the CLIP cross-attention path is isolated (e.g., removed vs. zeroed) is supplied, so the 5.6 % PSNR improvement cannot yet be attributed solely to conditioning.
- [Methods/Results] Methods/Results: the reported percentages are given without dataset identity or size, number of test images, error bars, or statistical tests. This prevents assessment of whether the observed differences exceed run-to-run variance and directly undermines verification of the controlled-ablation premise.
minor comments (1)
- [Abstract] Abstract: the colorfulness metric improvement of 36.6 % in the U-Net tier is an order of magnitude larger than the other deltas; a brief note on the colorfulness formula or reference would aid interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the clarity and reproducibility of our controlled ablation study. We address each major comment below and will incorporate revisions to provide the requested details on experimental controls and statistical reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that text conditioning alone produces the listed metric deltas requires explicit confirmation that the 'with' and 'without' models share identical architectures, parameter counts, training schedules, loss functions, and inference settings. No hyper-parameter table, model diagram, or description of how the CLIP cross-attention path is isolated (e.g., removed vs. zeroed) is supplied, so the 5.6 % PSNR improvement cannot yet be attributed solely to conditioning.
Authors: The manuscript states that comparisons were performed 'while holding all other variables constant,' but we acknowledge that the initial version did not include an explicit hyper-parameter table or a description of the conditioning isolation procedure. In the revised manuscript we will add a configuration table and a methods subsection detailing identical architectures, parameter counts, training schedules, loss functions, and inference settings for both conditions, along with the precise mechanism used to disable CLIP cross-attention (zeroing the conditioning input). revision: yes
-
Referee: [Methods/Results] Methods/Results: the reported percentages are given without dataset identity or size, number of test images, error bars, or statistical tests. This prevents assessment of whether the observed differences exceed run-to-run variance and directly undermines verification of the controlled-ablation premise.
Authors: We agree that dataset identity, test-set size, error bars, and statistical tests are required to verify that differences exceed variance. The revised Methods and Results sections will specify the dataset(s) and sizes used, the number of test images, report error bars from repeated runs, and include statistical significance tests (e.g., paired t-tests) to support the reported metric improvements. revision: yes
Circularity Check
No derivation chain or self-referential structure present; purely empirical ablation study
full rationale
The paper reports metric deltas from controlled comparisons of U-Net and Stable Diffusion models run with versus without CLIP text conditioning. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The central claim rests on experimental isolation of one variable rather than any mathematical reduction to its own inputs. This matches the default expectation of no circularity for empirical work that does not invoke uniqueness theorems or ansatzes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Open image preferences v1
Data Is Better Together Community. Open image preferences v1. https://huggingface.co/datasets/data-is-better-together/ open-image-preferences-v1-binarized, 2024. HuggingFace dataset. Licensed under Apache-2.0
2024
-
[2]
OshenGeenathandY.H.P.P.Priyadarshana. Fromshadestovibrance: Acomprehen- sivereviewofmodernimagecolorizationtechniques.Frontiers in Computer Science, 7:1626641, 2025. doi: 10.3389/fcomp.2025.1626641
-
[3]
Tic: Text-guided image colorization, 2022
Subhankar Ghosh, Prasun Roy, Saumik Bhattacharya, Umapada Pal, and Michael Blumenstein. Tic: Text-guided image colorization, 2022. URLhttps://arxiv. org/abs/2208.02843. 14
arXiv 2022
-
[4]
Efficient diffusion training via min-snr weighting strategy, 2024
Tiankai Hang, Shuyang Gu, Chen Li, Jianmin Bao, Dong Chen, Han Hu, Xin Geng, and Baining Guo. Efficient diffusion training via min-snr weighting strategy, 2024. URLhttps://arxiv.org/abs/2303.09556
arXiv 2024
-
[5]
Measuring colourfulness in natural images
David Hasler and Sabine Suesstrunk. Measuring colourfulness in natural images. Proceedings of SPIE - The International Society for Optical Engineering, 5007:87– 95, 06 2003. doi: 10.1117/12.477378
-
[6]
Classifier-free diffusion guidance, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. URL https://arxiv.org/abs/2207.12598
Pith/arXiv arXiv 2022
-
[7]
Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Col- orization with Simultaneous Classification.ACM Transactions on Graphics (Proc. of SIGGRAPH 2016), 35(4):110:1–110:11, 2016
2016
-
[8]
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translationwithconditionaladversarialnetworks.CoRR,abs/1611.07004,2016. URL http://arxiv.org/abs/1611.07004
Pith/arXiv arXiv 2016
-
[9]
Perceptual losses for real-time style transfer and super-resolution.CoRR, abs/1603.08155, 2016
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution.CoRR, abs/1603.08155, 2016. URLhttp://arxiv. org/abs/1603.08155
Pith/arXiv arXiv 2016
-
[10]
Diffcolor: Towardhighfidelitytext-guidedimagecolorizationwithdiffusionmodels,2023
JianxinLin,PengXiao,YijunWang,RongjuZhang,andXiangxiangZeng. Diffcolor: Towardhighfidelitytext-guidedimagecolorizationwithdiffusionmodels,2023. URL https://arxiv.org/abs/2308.01655
arXiv 2023
-
[11]
Learning transferable visual models from natural lan- guage supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural lan- guage supervision, 2021. URLhttps://arxiv.org/abs/2103.00020
Pith/arXiv arXiv 2021
-
[12]
High-resolution image synthesis with latent diffusion models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2022. URL https://arxiv.org/abs/2112.10752
Pith/arXiv arXiv 2022
-
[13]
Lee, Jonathan Ho, Tim Salimans,DavidJ.Fleet,andMohammadNorouzi
Chitwan Saharia, William Chan, Huiwen Chang, Chris A. Lee, Jonathan Ho, Tim Salimans,DavidJ.Fleet,andMohammadNorouzi. Palette: Image-to-imagediffusion models, 2022. URLhttps://arxiv.org/abs/2111.05826
arXiv 2022
-
[14]
Gomez, Lukasz Kaiser, and Illia Polosukhin
AshishVaswani,NoamShazeer,NikiParmar,JakobUszkoreit,LlionJones,AidanN. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URL https://arxiv.org/abs/1706.03762
Pith/arXiv arXiv 2023
-
[15]
IEEE Transactions on Image Processing 13(4), 600–612 (Apr 2004)
Zhou Wang, Alan Bovik, Hamid Sheikh, and Eero Simoncelli. Image quality as- sessment: From error visibility to structural similarity.Image Processing, IEEE Transactions on, 13:600 – 612, 05 2004. doi: 10.1109/TIP.2003.819861. 15
-
[16]
Diffusing colors: Image colorization with text guided diffusion, 2023
NirZabari,AharonAzulay,AlexeyGorkor,TaviHalperin,andOhadFried. Diffusing colors: Image colorization with text guided diffusion, 2023. URLhttps://arxiv. org/abs/2312.04145
arXiv 2023
-
[17]
Colorfulimagecolorization.CoRR, abs/1603.08511, 2016
RichardZhang,PhillipIsola,andAlexeiA.Efros. Colorfulimagecolorization.CoRR, abs/1603.08511, 2016. URLhttp://arxiv.org/abs/1603.08511
Pith/arXiv arXiv 2016
-
[18]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric, 2018. URL https://arxiv.org/abs/1801.03924. 16
Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.