Preserving Foundational Capabilities in Flow-Matching VLAs through Conservative SFT
Pith reviewed 2026-05-20 23:05 UTC · model grok-4.3
The pith
Conservative fine-tuning scales gradients by model confidence to preserve VLA foundational skills.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ConSFT is an optimization objective that adapts flow-matching VLAs to target distributions by dynamically scaling learning signals based on model confidence. It suppresses excessive gradients from low-confidence samples to prevent disproportionate parameter updates, thereby bounding intrinsic parameter disruption risk. The formulation draws from trust-region clipping in reinforcement learning to create a progressive learning dynamic that secures both target convergence and retention of prior capabilities, all while maintaining sparse updates without parallel reference networks.
What carries the argument
Conservative Supervised Fine-Tuning (ConSFT), an objective that scales learning signals dynamically by model confidence to suppress excessive gradients from low-confidence samples.
If this is right
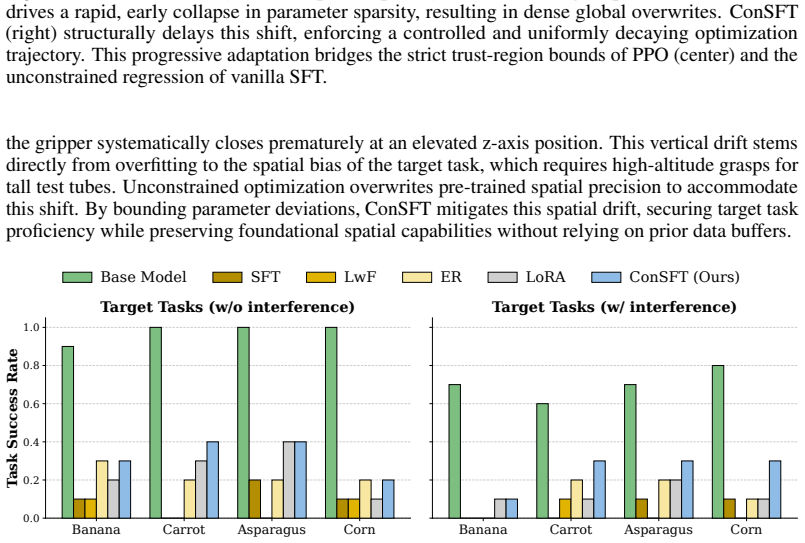
- Outperforms vanilla SFT by an average absolute margin of over 20 percent in capability retention on LIBERO and RoboTwin benchmarks.
- Matches the efficacy of data-heavy Experience Replay while operating in a prior-data-free regime.
- Prevents spatial overfitting during real-world robotic deployments and preserves pre-trained physical skills.
- Maintains sparse parameter updates without requiring parallel reference networks.
Where Pith is reading between the lines
- The confidence-based scaling could serve as a lightweight substitute for explicit regularization in other continual-learning settings for generative models.
- Eliminating the need for stored prior data may simplify deployment of VLAs on resource-limited robots that must adapt sequentially.
- The same mechanism might stabilize fine-tuning of related flow-based or diffusion-based policies outside the VLA domain.
Load-bearing premise
Model confidence on individual samples provides a stable and sufficient signal to bound parameter disruption risk during fine-tuning.
What would settle it
Measure whether pre-trained task success rates drop sharply on held-out evaluations after ConSFT is applied to a new downstream task, or whether the norm of parameter changes fails to remain sparse compared with vanilla SFT.
Figures








read the original abstract
Unconstrained fine-tuning of flow-matching Vision-Language-Action (VLA) models drives dense parameter overwrites, degrading pre-trained capabilities. We present Conservative Supervised Fine-Tuning (ConSFT), an optimization objective that adapts to target distributions while mitigating catastrophic forgetting, requiring zero prior data or architectural overhead. By dynamically scaling learning signals based on model confidence, ConSFT suppresses excessive gradients from low-confidence samples to prevent disproportionate parameter updates, thereby bounding the intrinsic parameter disruption risk. Inspired by reinforcement learning's trust-region clipping, this formulation establishes a progressive learning dynamic to secure target convergence and prior capability retention, maintaining sparse parameter updates without relying on the parallel reference networks required by explicit regularization. We evaluate ConSFT on the LIBERO and RoboTwin benchmarks across state-of-the-art flow-matching VLAs ($\pi_0$, $\pi_{0.5}$, and GR00T-N1.6-3B). The method outperforms vanilla SFT in capability retention by an average absolute margin of over 20\%, matching the efficacy of data-heavy Experience Replay in a prior-data-free regime. Real-world robotic deployments confirm that ConSFT precludes spatial overfitting during downstream adaptation, preserving pre-trained physical skills while acquiring sequential target tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Conservative Supervised Fine-Tuning (ConSFT) for flow-matching Vision-Language-Action (VLA) models. It claims that dynamically scaling learning signals by per-sample model confidence suppresses excessive gradients on low-confidence data, bounding parameter disruption to preserve pre-trained capabilities during adaptation to new tasks. The method requires no prior data or reference networks, unlike explicit regularization or experience replay. On LIBERO and RoboTwin benchmarks with models such as π₀, π₀.₅, and GR00T-N1.6-3B, ConSFT reportedly yields an average absolute 20% improvement in capability retention over vanilla SFT while matching data-heavy replay baselines; real-world robot deployments are said to confirm reduced spatial overfitting.
Significance. If the performance claims and mechanism are substantiated, the result would be significant for robotic learning: it offers a lightweight, prior-data-free alternative to mitigate catastrophic forgetting in large flow-matching VLAs, potentially simplifying deployment pipelines that currently rely on replay buffers or auxiliary networks. The approach could influence fine-tuning practices in continuous control and embodied AI where retaining foundational physical skills is critical.
major comments (3)
- [Abstract / ConSFT formulation] Abstract and method description: the central claim that confidence-based gradient scaling 'bounds the intrinsic parameter disruption risk' and produces 'sparse parameter updates' lacks any derivation or analysis showing how the scaling factor (presumably derived from the flow-matching loss) controls update magnitude in parameter space rather than merely reweighting the loss. In high-dimensional VLA models this linkage is load-bearing for the assertion that the method works without reference networks or prior data.
- [Experiments] Evaluation section: the reported 'over 20% absolute margin' in capability retention is presented without error bars, ablation studies isolating the confidence estimator, dataset statistics, or direct measurements of parameter sparsity (e.g., fraction of weights exceeding a change threshold). These omissions prevent assessment of whether the gains are attributable to the proposed dynamic or to other factors.
- [Method / Real-world deployments] The manuscript states that low-confidence samples are suppressed to prevent disproportionate updates, yet provides no analysis of whether low-confidence target samples are precisely those requiring larger updates for successful task adaptation; this assumption is load-bearing for the progressive learning dynamic and real-world retention claims.
minor comments (2)
- [Method] Notation for the confidence estimator and scaling function should be defined explicitly with an equation, even if the implementation is simple.
- [Experiments] The abstract mentions 'state-of-the-art flow-matching VLAs (π₀, π₀.₅, and GR00T-N1.6-3B)' but the main text should include a brief description of each model's scale and pre-training data to contextualize the retention results.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on our manuscript. We address each major point below and indicate the revisions made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract / ConSFT formulation] Abstract and method description: the central claim that confidence-based gradient scaling 'bounds the intrinsic parameter disruption risk' and produces 'sparse parameter updates' lacks any derivation or analysis showing how the scaling factor (presumably derived from the flow-matching loss) controls update magnitude in parameter space rather than merely reweighting the loss. In high-dimensional VLA models this linkage is load-bearing for the assertion that the method works without reference networks or prior data.
Authors: We thank the referee for highlighting this. The original manuscript presented the method intuitively but indeed lacked a formal derivation. In the revised version, we have added an analysis in the Methods section that derives how the per-sample scaling factor modulates the effective learning rate in parameter space. Specifically, we show that the update norm is bounded proportionally to the confidence score, providing a trust-region-like effect without explicit regularization or reference networks. revision: yes
-
Referee: [Experiments] Evaluation section: the reported 'over 20% absolute margin' in capability retention is presented without error bars, ablation studies isolating the confidence estimator, dataset statistics, or direct measurements of parameter sparsity (e.g., fraction of weights exceeding a change threshold). These omissions prevent assessment of whether the gains are attributable to the proposed dynamic or to other factors.
Authors: We agree that these elements are necessary for rigorous evaluation. We have updated the Experiments section to include error bars computed over 5 random seeds, an ablation study removing the confidence weighting, summary statistics of the datasets used, and measurements of parameter sparsity by tracking the L2 norm of weight changes and the fraction of parameters exceeding a 0.01 threshold. revision: yes
-
Referee: [Method / Real-world deployments] The manuscript states that low-confidence samples are suppressed to prevent disproportionate updates, yet provides no analysis of whether low-confidence target samples are precisely those requiring larger updates for successful task adaptation; this assumption is load-bearing for the progressive learning dynamic and real-world retention claims.
Authors: This comment raises a valid concern about the core assumption. Our formulation is motivated by the idea that suppressing large gradients on uncertain samples prevents catastrophic overwriting of pre-trained capabilities, allowing progressive adaptation as confidence builds. However, we did not provide a direct analysis correlating sample confidence with required update size in the original submission. We have added a qualitative discussion and a supporting figure in the revision showing confidence evolution during training, but acknowledge that a quantitative study of update requirements would benefit from further experiments. revision: partial
Circularity Check
No significant circularity; derivation is self-contained as a new optimization objective
full rationale
The provided abstract and description present ConSFT as an independent optimization objective that dynamically scales learning signals by model confidence to bound parameter disruption risk, explicitly requiring zero prior data or reference networks. No equations, self-referential derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the text. The central mechanism is defined directly rather than reducing to its inputs by construction, and the paper does not invoke uniqueness theorems or ansatzes from prior self-work to force the result. This is the most common honest finding for papers whose claims rest on empirical evaluation rather than closed-form derivation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model confidence on target samples can be used to bound intrinsic parameter disruption risk during supervised fine-tuning.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By dynamically scaling learning signals based on model confidence, ConSFT suppresses excessive gradients from low-confidence samples to prevent disproportionate parameter updates, thereby bounding the intrinsic parameter disruption risk.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we analytically prove that this mechanism establishes a strict bound on weight deviations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A Pragmatic VLA Foundation Model
Wei Wu, Fan Lu, Yunnan Wang, Shuai Yang, Shi Liu, Fangjing Wang, Qian Zhu, He Sun, Yong Wang, Shuailei Ma, Yiyu Ren, Kejia Zhang, Hui Yu, Jingmei Zhao, Shuai Zhou, Zhenqi Qiu, Houlong Xiong, Ziyu Wang, Zechen Wang, Ran Cheng, Yong-Lu Li, Yongtao Huang, Xing Zhu, Yujun Shen, and Kecheng Zheng. A pragmatic VLA foundation model.arXiv preprint arXiv:2601.18692, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Asher J Hancock, Xindi Wu, Lihan Zha, Olga Russakovsky, and Anirudha Majumdar. Ac- tions as language: Fine-tuning vlms into vlas without catastrophic forgetting.arXiv preprint arXiv:2509.22195, 2025
-
[4]
Towards Long-Lived Robots: Continual Learning VLA Models via Reinforcement Fine-Tuning
Yuan Liu, Haoran Li, Shuai Tian, Yuxing Qin, Yuhui Chen, Yupeng Zheng, Yongzhen Huang, and Dongbin Zhao. Towards long-lived robots: Continual learning vla models via reinforcement fine-tuning.arXiv preprint arXiv:2602.10503, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
work page 2025
-
[7]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang Tan, Gua...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
RL's Razor: Why Online Reinforcement Learning Forgets Less
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. Rl’s razor: Why online reinforcement learning forgets less.arXiv preprint arXiv:2509.04259, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Sagnik Mukherjee, Lifan Yuan, Dilek Hakkani-Tur, and Hao Peng. Reinforcement learning fine- tunes small subnetworks in large language models.Advances in Neural Information Processing Systems, 38:132119–132138, 2026
work page 2026
-
[10]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
work page 2015
-
[11]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Olaf Yunus Laitinen Imanov. Mechanistic analysis of catastrophic forgetting in large language models during continual fine-tuning.arXiv preprint arXiv:2601.18699, 2026. 10
-
[13]
Bernd Bohnet, Rumen Dangovski, Kevin Swersky, Sherry Moore, Arslan Chaudhry, Kathleen Kenealy, and Noah Fiedel. A comparative analysis of llm adaptation: Sft, lora, and icl in data-scarce scenarios.arXiv preprint arXiv:2511.00130, 2025
-
[14]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catas- trophic forgetting in neural networks.Proceedings of the national academy of sciences, 114 (13):35...
work page 2017
-
[15]
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
work page 2017
-
[16]
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
work page 2025
-
[17]
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025
work page 2025
-
[18]
David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Lillicrap, and Gregory Wayne. Expe- rience replay for continual learning.Advances in neural information processing systems, 32, 2019
work page 2019
-
[19]
Huihan Liu, Changyeon Kim, Bo Liu, Minghuan Liu, and Yuke Zhu. Pretrained vision- language-action models are surprisingly resistant to forgetting in continual learning.arXiv preprint arXiv:2603.03818, 2026
-
[20]
Jiaheng Hu, Jay Shim, Chen Tang, Yoonchang Sung, Bo Liu, Peter Stone, and Roberto Martin- Martin. Simple recipe works: Vision-language-action models are natural continual learners with reinforcement learning.arXiv preprint arXiv:2603.11653, 2026
-
[21]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
work page 2022
-
[22]
Guanglong Sun, Siyuan Zhang, Liyuan Wang, Jun Zhu, Hang Su, and Yi Zhong. Safety alignment as continual learning: Mitigating the alignment tax via orthogonal gradient projection. arXiv preprint arXiv:2602.07892, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Hoang Phan, Xianjun Yang, Kevin Yao, Jingyu Zhang, Shengjie Bi, Xiaocheng Tang, Madian Khabsa, Lijuan Liu, and Deren Lei. Beyond reasoning gains: Mitigating general capabilities forgetting in large reasoning models.arXiv preprint arXiv:2510.21978, 2025
-
[24]
Tonghe Zhang, Chao Yu, Sichang Su, and Yu Wang. Reinflow: Fine-tuning flow matching policy with online reinforcement learning.Advances in Neural Information Processing Systems, 38:106282–106319, 2026
work page 2026
-
[25]
LoRA learns less and forgets less.Transactions on Machine Learning Research, 2024
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, and John Patrick Cunningham. LoRA learns less and forgets less.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id= aloEru2qCG. ...
work page 2024
-
[26]
Robust Policy Optimization to Prevent Catastrophic Forgetting
Mahdi Sabbaghi, George Pappas, Adel Javanmard, and Hamed Hassani. Robust policy opti- mization to prevent catastrophic forgetting.arXiv preprint arXiv:2602.08813, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Song Lai, Haohan Zhao, Rong Feng, Changyi Ma, Wenzhuo Liu, Hongbo Zhao, Xi Lin, Dong Yi, Min Xie, Qingfu Zhang, Hongbin Liu, Gaofeng Meng, and Fei Zhu. Reinforcement fine- tuning naturally mitigates forgetting in continual post-training.arXiv preprint arXiv:2507.05386, 2025. 11
-
[28]
Soft Adaptive Policy Optimization
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization.arXiv preprint arXiv:2511.20347, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
-
[30]
Reinforcement learning for flow- matching policies.arXiv preprint arXiv:2507.15073, 2025
Samuel Pfrommer, Yixiao Huang, and Somayeh Sojoudi. Reinforcement learning for flow- matching policies.arXiv preprint arXiv:2507.15073, 2025
-
[31]
Flow policy gradients for robot control.arXiv preprint arXiv:2602.02481, 2026
Brent Yi, Hongsuk Choi, Himanshu Gaurav Singh, Xiaoyu Huang, Takara E Truong, Carmelo Sferrazza, Yi Ma, Rocky Duan, Pieter Abbeel, Guanya Shi, Karen Liu, and Angjoo Kanazawa. Flow policy gradients for robot control.arXiv preprint arXiv:2602.02481, 2026
-
[32]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
work page 2023
-
[33]
Yao Mu, Tianxing Chen, Zanxin Chen, Shijia Peng, Zhiqian Lan, Zeyu Gao, Zhixuan Liang, Qiaojun Yu, Yude Zou, Mingkun Xu, Lunkai Lin, Zhiqiang Xie, Mingyu Ding, and Ping Luo. Robotwin: Dual-arm robot benchmark with generative digital twins. InProceedings of the computer vision and pattern recognition conference, pages 27649–27660, 2025. 12 A Mechanistic ab...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.