Muown Implicitly Performs Angular Step-size Decay
Pith reviewed 2026-06-26 08:30 UTC · model grok-4.3
The pith
Muown's directional updates are equivalent to Riemannian steps on normalized directions, with the un-normalized magnitude only modulating the angular step size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
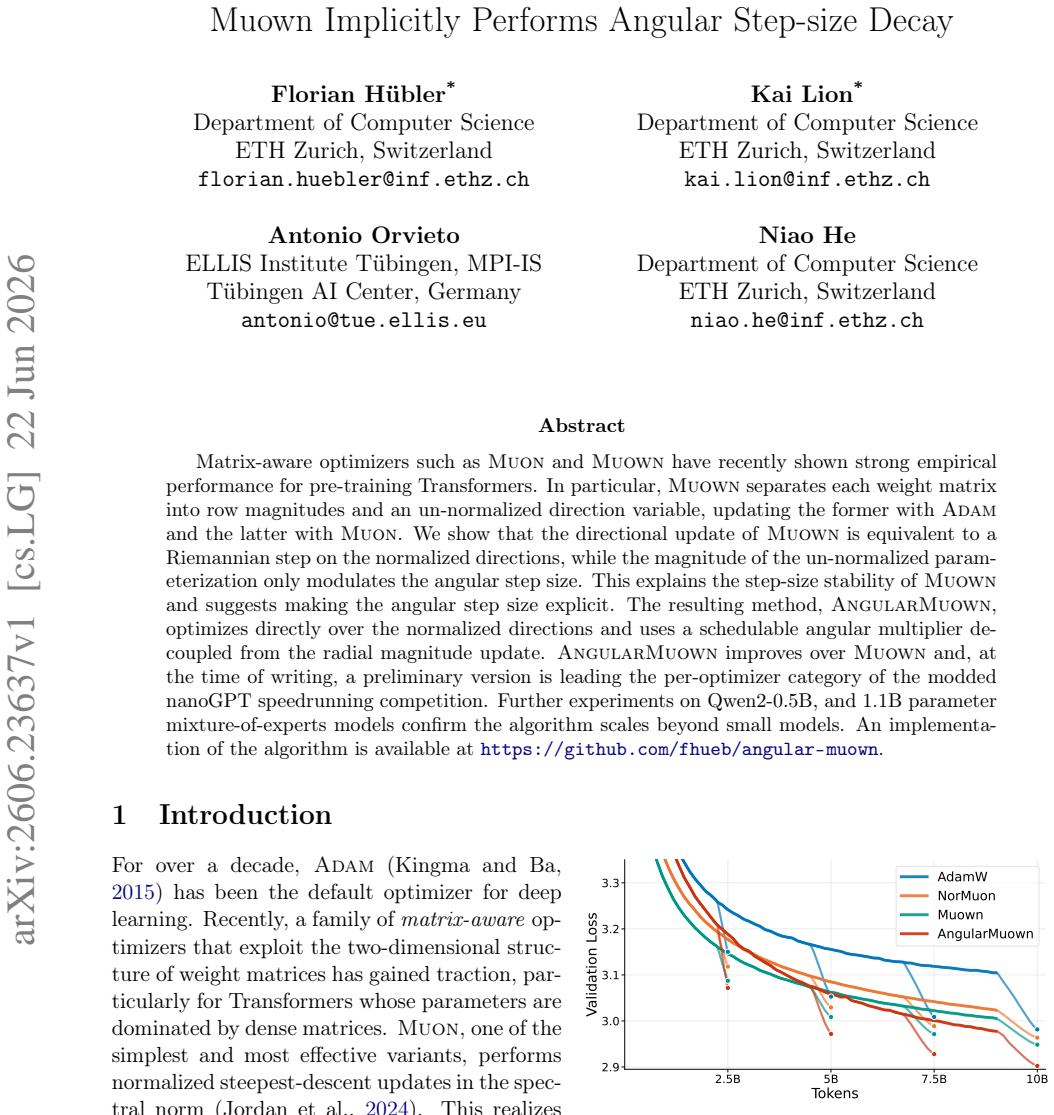
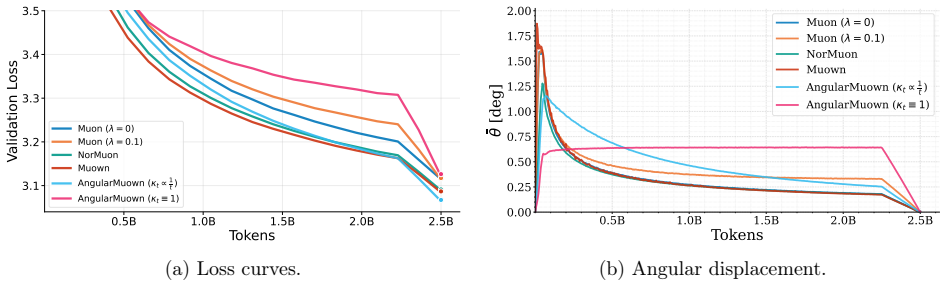
The directional update of Muown is equivalent to a Riemannian step on the normalized directions, while the magnitude of the un-normalized parameterization only modulates the angular step size. This explains the step-size stability of Muown and suggests making the angular step size explicit. The resulting method, AngularMuown, optimizes directly over the normalized directions and uses a schedulable angular multiplier decoupled from the radial magnitude update.
What carries the argument
Equivalence of Muown's directional update to a Riemannian step on normalized directions, where the un-normalized magnitude modulates the angular step size.
If this is right
- AngularMuown improves over Muown in pre-training Transformers.
- AngularMuown leads the per-optimizer category of the modded nanoGPT speedrunning competition.
- The method scales to Qwen2-0.5B and 1.1B parameter mixture-of-experts models.
- The angular step size becomes schedulable independently from the magnitude update.
Where Pith is reading between the lines
- The Riemannian interpretation could apply to other matrix-aware optimizers that use normalization.
- Explicit angular scheduling might benefit optimization in other non-standard geometries.
- Testing AngularMuown with various angular decay schedules could yield further gains.
- This view may link to broader work on manifold-constrained optimization in neural networks.
Load-bearing premise
The equivalence between Muown's directional update and the Riemannian step holds exactly under the specific normalization and update rules used in Muown.
What would settle it
Direct computation of the update for a small weight matrix under Muown rules, checking whether the resulting direction exactly matches the Riemannian gradient step projected onto the unit sphere.
Figures

read the original abstract
Matrix-aware optimizers such as Muon and Muown have recently shown strong empirical performance for pre-training Transformers. In particular, Muown separates each weight matrix into row magnitudes and an un-normalized direction variable, updating the former with Adam and the latter with Muon. We show that the directional update of Muown is equivalent to a Riemannian step on the normalized directions, while the magnitude of the un-normalized parameterization only modulates the angular step size. This explains the step-size stability of Muown and suggests making the angular step size explicit. The resulting method, AngularMuown, optimizes directly over the normalized directions and uses a schedulable angular multiplier decoupled from the radial magnitude update. AngularMuown improves over Muown and, at the time of writing, a preliminary version is leading the per-optimizer category of the modded nanoGPT speedrunning competition. Further experiments on Qwen2-0.5B, and 1.1B parameter mixture-of-experts models confirm the algorithm scales beyond small models. An implementation of the algorithm is available at https://github.com/fhueb/angular-muown
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Muown's separation of row magnitudes (updated via Adam) and un-normalized directions (updated via Muon) yields a directional update exactly equivalent to a Riemannian gradient step on the normalized directions, with the un-normalized magnitude serving only to modulate the effective angular step size. This equivalence is used to explain Muown's step-size stability and to motivate AngularMuown, which optimizes directly over normalized directions with an explicit, schedulable angular multiplier decoupled from the radial update. Empirical results show AngularMuown outperforming Muown, leading a nanoGPT speedrunning category, and scaling to Qwen2-0.5B and 1.1B MoE models.
Significance. If the claimed exact equivalence holds, the work supplies a clean theoretical account of why matrix-aware optimizers succeed by separating radial and angular dynamics, plus a practical algorithm (AngularMuown) whose angular step-size schedule is directly controllable. Strengths include the open-source implementation, scaling experiments beyond toy models, and leaderboard results; these elements would make the contribution useful for optimizer research even if the derivation requires minor tightening.
major comments (2)
- [main derivation (likely §3)] The central equivalence (directional Muown update ≡ Riemannian step on normalized directions, magnitude only modulating angular step size) is load-bearing for both the stability explanation and the motivation for AngularMuown. The derivation must be shown to be exact rather than asymptotic or conditional on the Newton-Schulz iteration or row-wise normalization; any deviation would weaken the angular-step-size account.
- [equivalence proof] The weakest assumption isolated by the reader—that the mapping holds exactly under Muown's specific normalization and update rules—requires an explicit statement of all conditions (including orthogonality enforcement) and a check that no extra assumptions are introduced by the Muon step.
minor comments (2)
- [Abstract] The abstract's phrase 'at the time of writing' for the leaderboard position should be replaced by a specific date or version number for reproducibility.
- [Experiments] Figure captions and experiment tables would benefit from explicit mention of whether error bars or multiple seeds are reported, given the reader's note on missing error bars.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments both concern the rigor and explicitness of the central equivalence derivation in §3. We agree that this derivation is load-bearing and will revise the manuscript to present an exact statement with all conditions enumerated, including the role of orthogonality enforcement. No standing objections remain after these revisions.
read point-by-point responses
-
Referee: [main derivation (likely §3)] The central equivalence (directional Muown update ≡ Riemannian step on normalized directions, magnitude only modulating angular step size) is load-bearing for both the stability explanation and the motivation for AngularMuown. The derivation must be shown to be exact rather than asymptotic or conditional on the Newton-Schulz iteration or row-wise normalization; any deviation would weaken the angular-step-size account.
Authors: We agree that the equivalence must be presented as exact. In the revision we will rewrite the derivation in §3 to hold exactly under Muown's update rules (row-wise normalization of the direction variable after the Muon step, separate Adam update on magnitudes). The derivation will be stated for the idealized orthogonal update produced by Muon; we will explicitly note that the practical Newton-Schulz iteration approximates this orthogonalization but that any residual error lies in the tangent space and does not alter the angular component. This removes any asymptotic or conditional character from the main claim. revision: yes
-
Referee: [equivalence proof] The weakest assumption isolated by the reader—that the mapping holds exactly under Muown's specific normalization and update rules—requires an explicit statement of all conditions (including orthogonality enforcement) and a check that no extra assumptions are introduced by the Muon step.
Authors: We will add a short subsection (or a clearly labeled paragraph) immediately following the derivation that enumerates every assumption: (i) each row direction is normalized after the update, (ii) the Muon step produces an update orthogonal to the current direction (orthogonality enforcement), (iii) the magnitude is updated independently by Adam and does not enter the angular dynamics. We will verify that the Muon step, as defined in the paper, introduces no further assumptions beyond the standard Riemannian gradient step on the unit sphere (or Stiefel manifold). This directly addresses the request for an explicit list of conditions. revision: yes
Circularity Check
Derivation of Riemannian equivalence is self-contained from update equations; no load-bearing circularity
full rationale
The central claim is a direct algebraic equivalence between Muown's row-magnitude separation + Muon directional update and a Riemannian gradient step on the sphere, with magnitude acting only as an implicit angular multiplier. This identity is obtained by inspecting the given update rules rather than by fitting or by self-citation. AngularMuown then makes the angular multiplier explicit and schedulable, an extension that is not forced by the original definitions. No self-citation chain, fitted-input prediction, or ansatz smuggling is required for the equivalence itself. The provided abstract and reader summary contain no quoted reduction that collapses the claimed result to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The directional component of the Muown update can be rewritten exactly as a Riemannian gradient step on the unit sphere.
Forward citations
Cited by 1 Pith paper
-
Improving Neural Network Training by Decoupling the Magnitude and Direction of Weight Vectors
MD Decoupling factorizes weights into fixed-norm directions and learnable per-row/column magnitudes updated at independent rates, improving Adam and Muon training stability and scale transfer without weight decay or warmup.
Reference graph
Works this paper leans on
-
[1]
Adam: A Method for Stochastic Optimization
Boyd, Stephen and Lieven Vandenberghe (2004).Convex Optimization. Cambridge: Cambridge Uni- versity Press. Absil, P.-A., R. Mahony, and R. Sepulchre (2008).Optimization Algorithms on Matrix Manifolds. Princeton, NJ: Princeton University Press. Kingma, Diederik P. and Jimmy Ba (2015). “Adam: A Method for Stochastic Optimization”. In: Proc. Int. Conf. on Le...
Pith/arXiv arXiv 2004
-
[2]
Norm matters: efficient and accuratenormalizationschemesindeepnetworks
Proceedings of Machine Learning Research. PMLR, pp. 1842–1850.url:https://proceedings.mlr.press/v80/gupta18a.html. Hoffer, Elad, Ron Banner, Itay Golan, and Daniel Soudry (2018). “Norm matters: efficient and accuratenormalizationschemesindeepnetworks”.In:Advances in Neural Information Processing Systems. Ed. by S. Bengio, H. Wallach, H. Larochelle, K. Gra...
2018
-
[3]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Curran Associates, Inc.url:https : / / proceedings . neurips . cc / paper _ files/paper/2018/file/a0160709701140704575d499c997b6ca-Paper.pdf. Shoeybi, Mohammad, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro (2019). “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism”. In:arXiv preprint ...
Pith/arXiv arXiv 2018
-
[4]
GLU Variants Improve Transformer
Proceedings of Machine Learning Research. PMLR, pp. 2260–2268. Shazeer, Noam (2020). “GLU Variants Improve Transformer”. In:arXiv preprint arXiv:2002.05202. Hoffmann, Jordan, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hen- nigan, Eric Noland,...
Pith/arXiv arXiv 2020
-
[5]
Pro- ceedings of Machine Learning Research. PMLR, pp. 25333–25369.url:https://proceedings. mlr.press/v235/kosson24a.html. Liu, Aixin, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. (2024). “DeepSeek-V3 Technical Report”. In:arXiv preprint arXiv:2412.19437. Penedo, Guilherme, Hynek K...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.neucom.2023.127063.url:https://www.sciencedirect 2024
-
[6]
SOAP: Improving and Stabilizing Shampoo using Adam for Language Modeling
Proceedings of Machine Learning Research. PMLR, pp. 49069–49104. url:https://proceedings.mlr.press/v267/pethick25a.html. Vyas, Nikhil, Depen Morwani, Rosie Zhao, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade (2025). “SOAP: Improving and Stabilizing Shampoo using Adam for Language Modeling”. In:International Conference on Learning Repre...
Pith/arXiv arXiv 2025
-
[7]
All models are pre-trained on FineWeb-Edu (Penedo et al.,
implementation augmented with recent architectural improvements such as RoPE (Su et al., 2024), RMSNorm normalization (Zhang and Sennrich, 2019), and SwiGLU activations (Shazeer, 2020). All models are pre-trained on FineWeb-Edu (Penedo et al.,
2024
-
[8]
with a warmup- stable-decay learning-rate schedule (Hu et al., 2024), and we report perplexity (equivalently vali- dation loss) at a fixed token budget. FollowingMuown, the matrix-aware optimizer acts on all 2D hidden weight matrices (every 2D weight except the token embeddings and the LM head); the remaining parameters are handled by AdamW. ForAngularMuo...
2024
-
[9]
AngularMuown’s angular schedule is the inverse-polynomialκpoly t = (1+c(t−t w)+)−p, using the default valuesc= 10 −3 andp=
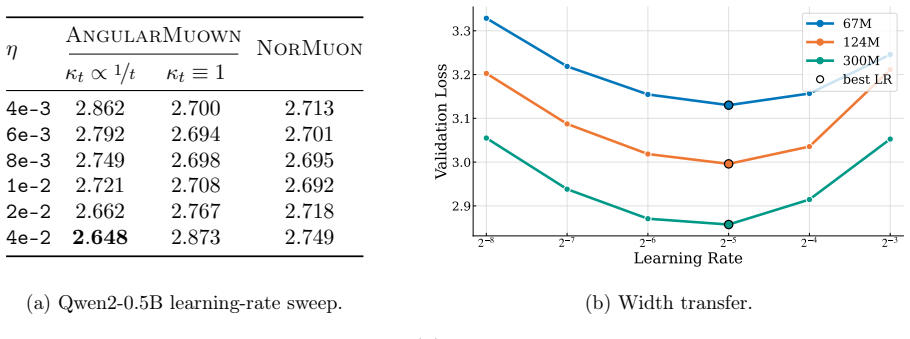
124M learning-rate sweep (Figure 3).We train a124M-parameter model for2.5B tokens and sweep a log-spaced learning-rate grid (Figure 3a), comparingMuon, NorMuon (Li et al., 2025), Muown, andAngularMuownboth with and without its angular schedule.Muonuses weight decayλ= 0.1and all other optimizers useλ= 0, the settings found optimal in theMuownstudy. Angular...
2025
-
[10]
14 Algorithm 2Idealized DirectionalAngularMuownUpdate Require:U 1 ∈ M,M 0 ←gradL(U 1, ξ1), stepsizeη, momentumβ Mt ←βM t−1 + (1−β)gradL(U t, ξt) Ot ←argmin D∈TUt M,∥D∥S∞ ≤1 ⟨Mt,D⟩▷Tangent-space aware orthogonalization Ut+1 ←Retr Ut(ηOt)▷Retraction at a global batch of 256 (≈1.05M tokens/step) for 30B tokens in total. For the optimizer settings, we mostly ...
2025
-
[11]
Lemma B.1.For allU∈ MandA∈ T UMwe have ∥A∥F ≤ ∥A∥ U,∗ ≤ ∥A∥ S1 ≤ p min{m, n} ∥A∥ F
Additionally we require the following standard inequalities. Lemma B.1.For allU∈ MandA∈ T UMwe have ∥A∥F ≤ ∥A∥ U,∗ ≤ ∥A∥ S1 ≤ p min{m, n} ∥A∥ F . 15 Now we are ready to provide the descent lemma. Lemma B.2(Descent Lemma).Let Assumptions 1 and 2 hold. Then the iterates generated by Algorithm 2 satisfy TX t=1 ∥gradL(U t)∥Ut,∗ ≤ ∆1 η + ηLT 2 + 2 TX t=1 ∥Mt −...
2020
-
[12]
16 Combining the above with our initializationM1 =G 1 yields TX t=1 E ∥Et∥S1 ≤ √rσ 1−β + √rσT p 1−β+ ηLT 1−β and thus the claim
implies E tX τ=2 (1−β)β t−τ(Gτ −gradL(U τ)) S1 ≤ √rE " tX τ=2 (1−β)β t−τ(Gτ −gradL(U τ)) F # ≤ √r(1−β) vuut tX τ=1 β2(t−τ) σ2 ≤ √rσ p 1−β. 16 Combining the above with our initializationM1 =G 1 yields TX t=1 E ∥Et∥S1 ≤ √rσ 1−β + √rσT p 1−β+ ηLT 1−β and thus the claim. Finally we provide the proof for Theorem 3.2. Proof of Theorem 3.2.The proof foll...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.