Consistent Yet Wrong: Evidence Insensitivity in Spatial Vision-Language Models
Pith reviewed 2026-06-30 10:31 UTC · model grok-4.3
The pith
Vision-language models often give the same wrong answer to spatial distance questions from different viewpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
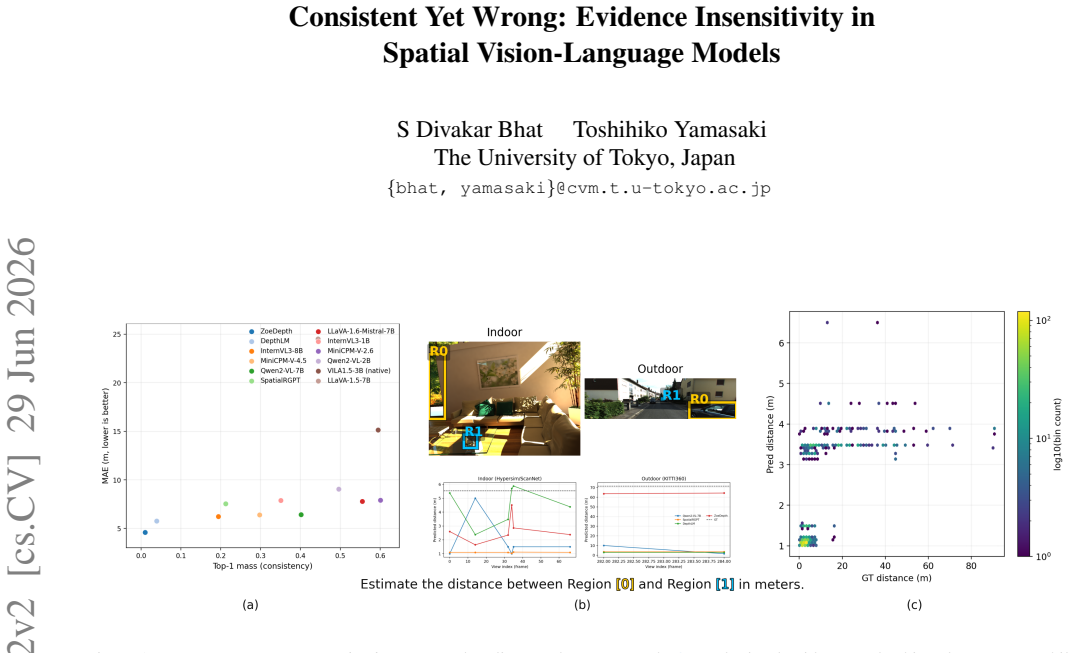
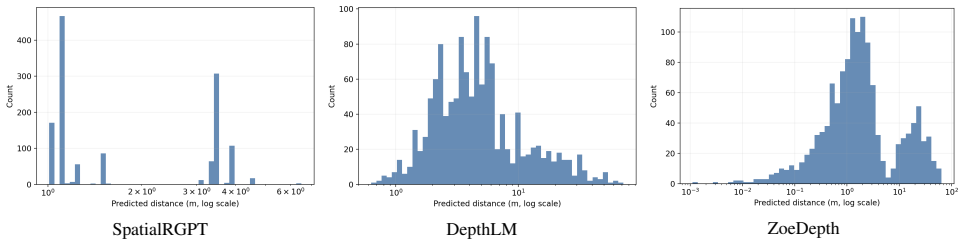
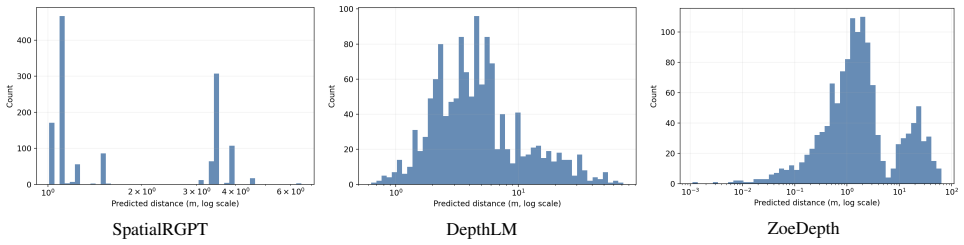
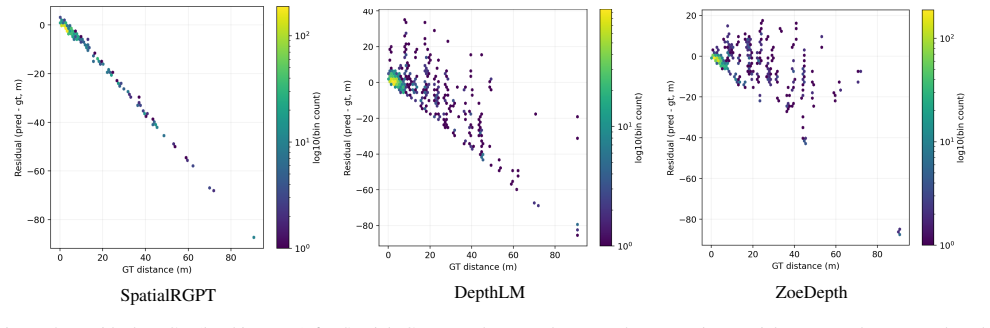
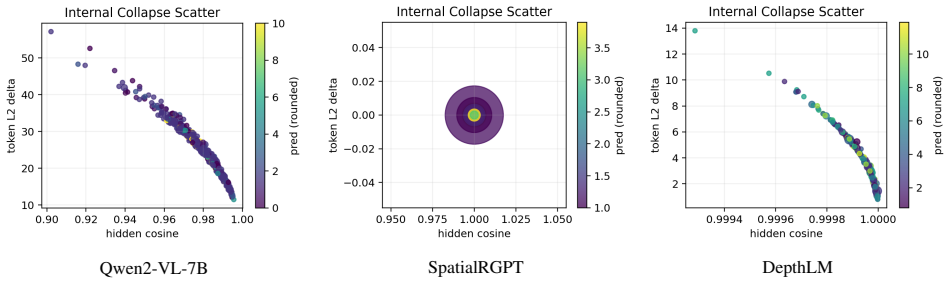
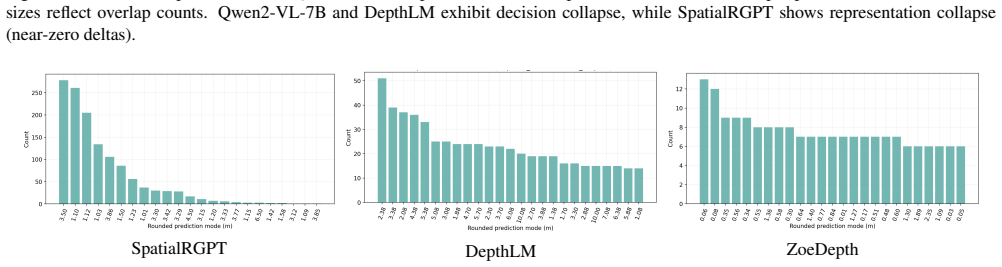
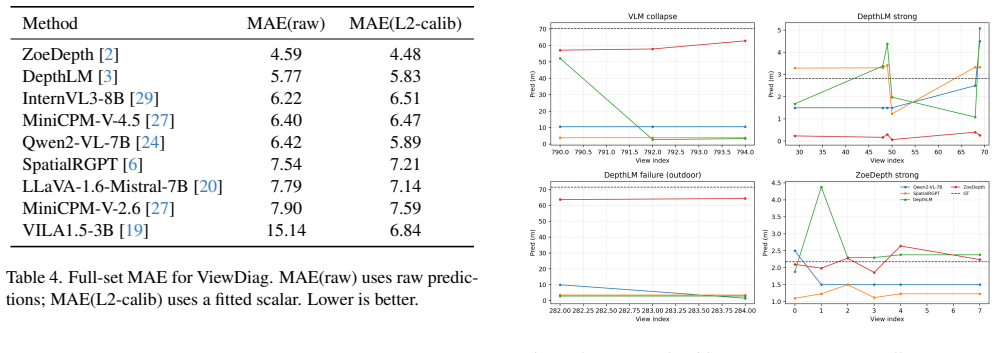
Leading VLMs produce view-invariant and consistent answers on metric distance queries even when those answers are incorrect. This pattern of high prediction stability paired with substantial error indicates weak coupling between predictions and viewpoint-specific visual evidence, with stable outputs reflecting prior-driven collapse rather than evidence-sensitive reasoning.
What carries the argument
ViewDiag, a multi-view evaluation protocol using object-pair tracks across 2-10 views from Hypersim, ScanNet, and KITTI360 that measures metric accuracy, distributional concentration, and internal collapse via latent feature probe.
If this is right
- Cross-view consistency cannot serve as a proxy for geometric understanding in spatial VLMs.
- Stable predictions across views likely stem from prior-driven collapse instead of visual evidence.
- VLMs require evaluation on evidence coupling in addition to raw accuracy for spatial tasks.
- ViewDiag offers a diagnostic tool to check if models are grounded in viewpoint-specific input.
Where Pith is reading between the lines
- If the pattern holds, methods that enforce view-invariance during training may increase evidence insensitivity.
- This finding suggests current VLMs may underperform in dynamic or embodied settings where viewpoint changes alter correct answers.
- Similar evidence insensitivity could appear in other consistency-based evaluations, such as in video or 3D reconstruction tasks.
Load-bearing premise
The metric distances computed from 3D reconstructions match the visual information present in the 2D images fed to the models.
What would settle it
A model that changes its distance predictions appropriately when the viewpoint alters the true distance, while maintaining overall accuracy, would contradict the evidence insensitivity claim.
Figures


read the original abstract
Spatial reasoning is fundamental to robotics, autonomy, and embodied AI, yet modern vision-language models (VLMs) remain unreliable on metric distance queries. A common assumption is that consistent predictions across viewpoints reflect geometric grounding. We test this assumption and find the opposite: leading VLMs often produce view-invariant and consistent answers even when those answers are incorrect, indicating weak coupling between predictions and viewpoint-specific visual evidence. We introduce \textbf{ViewDiag}, a controlled multi-view evaluation protocol built from Hypersim, ScanNet, and KITTI360, comprising 176 object-pair tracks across 80 scenes with 2--10 views per track. The protocol evaluates models along three axes: metric accuracy, distributional concentration, and internal collapse, the last of which is assessed using a latent feature probe. Across diverse models, we observe a consistent pattern of high prediction stability paired with substantial error, clustering in a regime characterized by strong consistency but low accuracy. \noindent These results challenge the common use of cross-view consistency as a proxy for geometric understanding. Instead, we show that stable predictions may reflect prior-driven collapse rather than evidence-sensitive reasoning. ViewDiag provides a controlled benchmark and diagnostic framework for evaluating whether spatial VLMs are not only accurate, but also meaningfully coupled to visual evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViewDiag, a controlled multi-view evaluation protocol using 176 object-pair tracks from Hypersim, ScanNet, and KITTI360 (80 scenes, 2-10 views per track). It evaluates leading VLMs on metric distance queries along three axes—metric accuracy, distributional concentration, and internal collapse (via latent feature probe)—and reports a consistent pattern of high cross-view prediction stability paired with substantial error. The central claim is that this indicates weak coupling between predictions and viewpoint-specific visual evidence, with stable outputs reflecting prior-driven collapse rather than evidence-sensitive reasoning; the results challenge the use of consistency as a proxy for geometric understanding.
Significance. If the reported pattern is robust, the work supplies a useful diagnostic benchmark and framework for spatial VLMs, highlighting limitations relevant to robotics and embodied AI. Strengths include the use of multiple public 3D datasets, a multi-view track design, and the addition of a latent probe for internal collapse; these elements support reproducibility and go beyond simple accuracy metrics.
major comments (1)
- [Abstract and ViewDiag protocol] Abstract and ViewDiag protocol (description of metric accuracy): The interpretation that outputs deviating from 3D-reconstruction distances are 'incorrect' and demonstrate evidence insensitivity assumes the 3D metric distances are recoverable from the single 2D image inputs. Because of projective scale ambiguity in monocular views, the visual evidence alone does not determine unique metric distances; consistent answers across views could therefore reflect stable prior application rather than failure to couple to viewpoint-specific cues. This assumption is load-bearing for the central claim of weak evidence coupling.
Simulated Author's Rebuttal
We thank the referee for highlighting the role of monocular scale ambiguity in interpreting our metric accuracy results. This is a substantive point that bears on the strength of our central claim. We address it directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and ViewDiag protocol] Abstract and ViewDiag protocol (description of metric accuracy): The interpretation that outputs deviating from 3D-reconstruction distances are 'incorrect' and demonstrate evidence insensitivity assumes the 3D metric distances are recoverable from the single 2D image inputs. Because of projective scale ambiguity in monocular views, the visual evidence alone does not determine unique metric distances; consistent answers across views could therefore reflect stable prior application rather than failure to couple to viewpoint-specific cues. This assumption is load-bearing for the central claim of weak evidence coupling.
Authors: We agree that absolute metric distances are underdetermined from any single monocular image due to projective scale ambiguity. ViewDiag therefore does not assume unique recoverability from individual views. Instead, each object-pair track supplies multiple views that differ in perspective, apparent scale, and contextual cues. The key observation is that model outputs remain highly stable across these distinct inputs while deviating from the ground-truth 3D distances obtained from the scene reconstructions. This pattern is consistent with reliance on view-invariant priors rather than adaptation to viewpoint-specific evidence. We will revise the abstract and the ViewDiag protocol section to explicitly acknowledge monocular scale ambiguity and to frame the evidence-insensitivity claim in terms of cross-view stability rather than per-image recoverability. revision: yes
Circularity Check
Empirical benchmarking with no circular derivation chain
full rationale
The paper is an empirical benchmarking study that introduces the ViewDiag protocol on external public datasets (Hypersim, ScanNet, KITTI360) and measures model outputs against independently defined axes of metric accuracy, distributional concentration, and internal collapse. No equations, fitted parameters, self-definitional steps, or load-bearing self-citations appear in the provided text; the central claim follows directly from the observed patterns on these fixed external benchmarks rather than reducing to any input by construction. This is the normal case of a self-contained empirical evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 3D reconstructions in Hypersim, ScanNet, and KITTI360 yield accurate metric ground truth for object-pair distances.
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 35:23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 35:23716–23736, 2022. 3
2022
-
[2]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias M ¨uller. Zoedepth: Zero-shot trans- fer by combining relative and metric depth.arXiv preprint arXiv:2302.12288, 2023. 1, 3, 5, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Depthlm: Metric depth from vision language models.arXiv preprint arXiv:2509.25413,
Zhipeng Cai, Ching-Feng Yeh, Hu Xu, Zhuang Liu, Gregory Meyer, Xinjie Lei, Changsheng Zhao, Shang-Wen Li, Vikas Chandra, and Yangyang Shi. Depthlm: Metric depth from vision language models.arXiv preprint arXiv:2509.25413,
-
[4]
Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endow- ing vision-language models with spatial reasoning capabili- ties. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 14455–14465,
-
[5]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024. 3
2024
-
[6]
Spatial- rgpt: Grounded spatial reasoning in vision-language mod- els.Advances in Neural Information Processing Systems, 37:135062–135093, 2024
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Rui- han Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatial- rgpt: Grounded spatial reasoning in vision-language mod- els.Advances in Neural Information Processing Systems, 37:135062–135093, 2024. 1, 3, 6, 7
2024
-
[7]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 5828–5839, 2017. 4
2017
-
[8]
Chapman and Hall/CRC, 1993
Bradley Efron and Robert J Tibshirani.An introduction to the bootstrap. Chapman and Hall/CRC, 1993. 5
1993
-
[9]
Zhiyuan Feng, Zhaolu Kang, Qijie Wang, Zhiying Du, Jion- grui Yan, Shubin Shi, Chengbo Yuan, Huizhi Liang, Yu Deng, Qixiu Li, et al. Seeing across views: Benchmark- ing spatial reasoning of vision-language models in robotic scenes.arXiv preprint arXiv:2510.19400, 2025. 2
-
[10]
Shortcut learning in deep neural networks
Robert Geirhos, J ¨orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Fe- lix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, 2020. 4
2020
-
[11]
Digging into self-supervised monocular depth estimation
Cl ´ement Godard, Oisin Mac Aodha, Michael Firman, and Gabriel J Brostow. Digging into self-supervised monocular depth estimation. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 3828–3838,
-
[12]
3d-llm: In- jecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494,
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: In- jecting the 3d world into large language models.Advances in Neural Information Processing Systems, 36:20482–20494,
-
[13]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6700–6709, 2019. 3
2019
-
[14]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2901–2910, 2017. 3
2017
-
[15]
Blip: Bootstrapping language-image pre-training for uni- fied vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for uni- fied vision-language understanding and generation. InIn- ternational Conference on Machine Learning, pages 12888– 12900. PMLR, 2022. 3
2022
-
[16]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational Conference on Machine Learning, pages 19730– 19742. PMLR, 2023. 3
2023
-
[17]
Megadepth: Learning single- view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single- view depth prediction from internet photos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 2041–2050, 2018. 3
2041
-
[18]
Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3292–3310, 2023
Yiyi Liao, Jun Xie, and Andreas Geiger. Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3):3292–3310, 2023. 4
2023
-
[19]
Vila: On pre-training for vi- sual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Moham- mad Shoeybi, and Song Han. Vila: On pre-training for vi- sual language models. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 26689–26699, 2024. 3, 6, 7
2024
-
[20]
Visual instruction tuning.Advances in Neural Information Processing Systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in Neural Information Processing Systems, 36:34892–34916, 2023. 3, 6, 7, 8
2023
-
[21]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational Conference on Machine Learning, pages 8748–8763. PmLR, 2021. 3
2021
-
[22]
Vi- sion transformers for dense prediction
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 12179–12188, 2021. 3
2021
-
[23]
Hypersim: A photorealistic syn- thetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic syn- thetic dataset for holistic indoor scene understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10912–10922, 2021. 4
2021
-
[24]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 3, 5, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
From indoor to open world: Revealing the spatial reasoning gap in mllms
Mingrui Wu, Zhaozhi Wang, Fangjinhua Wang, Jiaolong Yang, Marc Pollefeys, and Tong Zhang. From indoor to open world: Revealing the spatial reasoning gap in mllms. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16789–16799, 2026. 2
2026
-
[26]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10371–10381, 2024. 3
2024
-
[27]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 3, 5, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Seeing from another perspective: Evaluating multi-view understanding in mllms
Chun-Hsiao Yeh, Chenyu Wang, Shengbang Tong, Ta-Ying Cheng, Ruoyu Wang, Tianzhe Chu, Yuexiang Zhai, Yubei Chen, Shenghua Gao, and Yi Ma. Seeing from another perspective: Evaluating multi-view understanding in mllms. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 12000–12008, 2026. 3
2026
-
[29]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 5, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.