Substrate Asymmetry in User-Side Memory: A Diagnostic Framework
Pith reviewed 2026-06-27 09:56 UTC · model grok-4.3
The pith
LLM user memory splits into three separate axes where no single storage method excels at all three.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
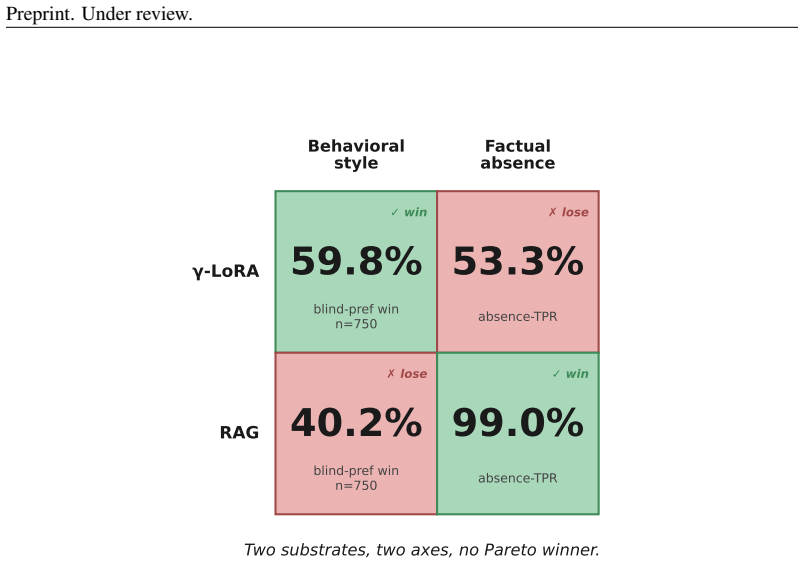
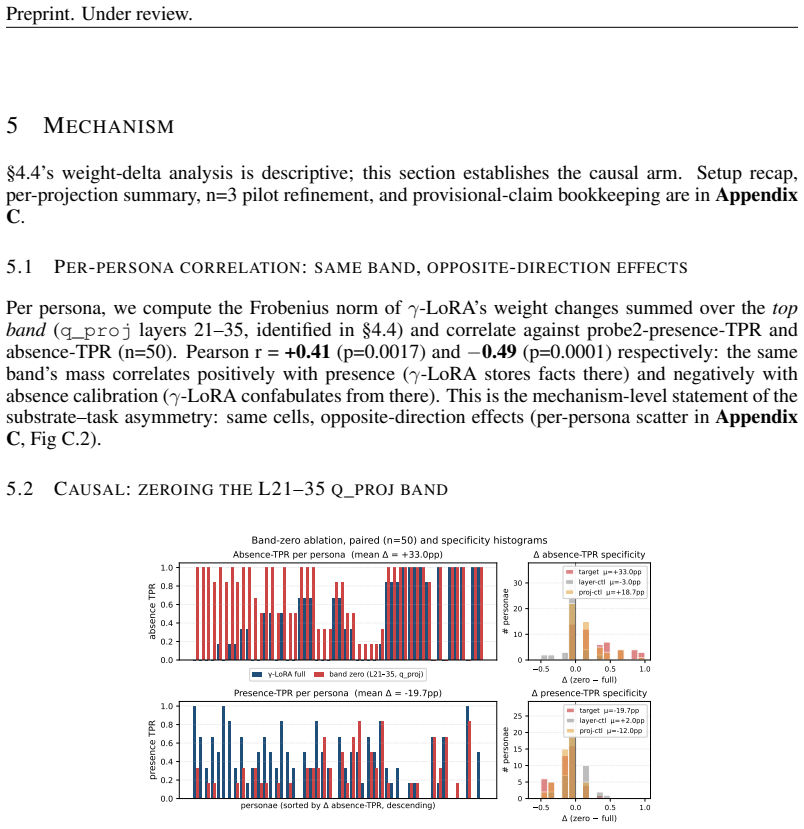
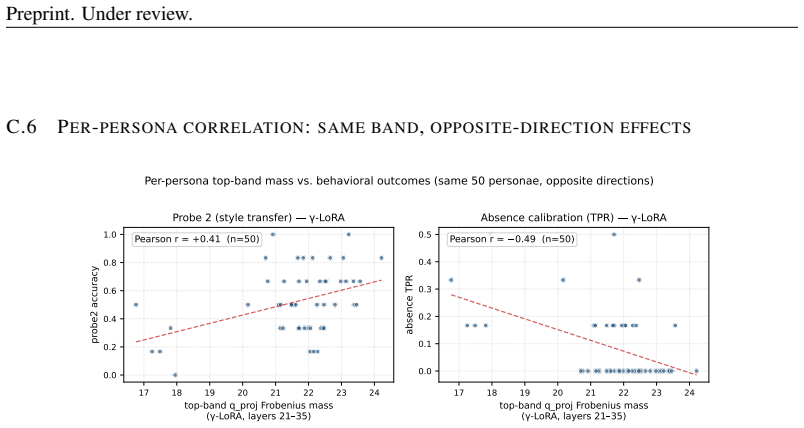
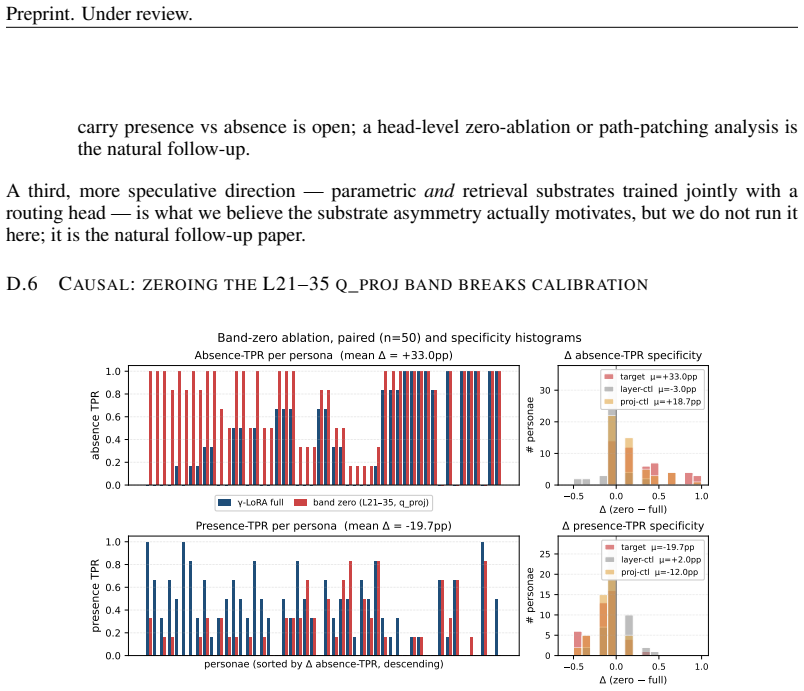
Memory factorises into at least three orthogonal axes -- behavioral consistency, factual presence, and factual absence -- and no single substrate wins all three. The same query-projection cells in attention layers 21-35 causally load-bear both effects in opposite directions, with zeroing those weights raising absence-probe true-positive rate by 33 percentage points while dropping presence-probe true-positive rate by 20 points.
What carries the argument
Three orthogonal memory axes measured by separate probes, compared through per-user gamma-LoRA versus BGE-large top-K retrieval, with targeted zeroing of query-projection weights in attention layers 21-35.
If this is right
- gamma-LoRA wins decisively on behavioral style while retrieval wins on factual absence.
- On more heavily RLHF-tuned models the parametric behavioral advantage shrinks and the absence-calibration gap widens.
- Underperformance on LaMP-3 traces to instruction-following collapse, which a logit mask at evaluation time corrects to near-perfect accuracy.
- A small classifier on question text alone selects the better substrate more accurately than any logit-based router.
Where Pith is reading between the lines
- Systems that first classify a query and then route to the stronger substrate for that query type could combine the complementary strengths without retraining.
- The observed alignment tax on parametric memory suggests that further preference tuning may systematically widen the gap between adapter-based and retrieval-based user memory.
- Replicating the layer-specific causal intervention on additional model families would test whether the 21-35 range is architecture-dependent or general.
Load-bearing premise
The chosen probes measure the three axes as truly independent dimensions without correlations introduced by how the synthetic histories or test items were built.
What would settle it
An experiment in which zeroing the identified attention weights fails to raise absence-probe performance while lowering presence-probe performance at the same time would falsify the claim that those cells load-bear the two effects in opposite directions.
Figures

read the original abstract
User-side memory in LLMs is typically scored as a single "personalization" capability: given a user's history, is the output more user-aware? We show this aggregate metric hides opposite-direction failures. Memory factorises into at least three orthogonal axes -- behavioral consistency (style, voice), factual presence (recall facts in history), and factual absence (abstain when a fact is absent) -- and no single substrate wins all three. Comparing per-user gamma-LoRA (a small LoRA adapter trained on each user's history; gamma denotes per-user, not per-task) against BGE-large dense top-K retrieval on a controlled 50-user synthetic corpus and a real-data probe (LaMP-3), we find gamma-LoRA decisively wins behavioral style while RAG decisively wins factual absence -- and the same query-projection cells in attention layers 21-35 causally load-bear both effects in opposite directions (zeroing those LoRA weights raises absence-probe TPR by +33 pp and drops presence-probe TPR by 20 pp). On the more heavily RLHF-tuned Llama-3.1-8B-Instruct the asymmetry strengthens, not heals: parametric memory's behavioral advantage collapses while its absence-calibration deficit against retrieval widens -- an alignment tax on parametric user-memory. On real-data LaMP-3, gamma-LoRA underperforms a majority baseline; a 9-condition mitigation sweep diagnoses this as instruction-following collapse, not substrate failure (a 9x2 cross-product shows the eval-time {1..5} logit mask drives main_acc to >=0.995 on every recipe), and the best training-time fix replicates bit-identically on Llama. Finally, substrate-selection routing is question-classification, not calibration: a 110M DistilBERT on the question text alone beats every logit-based router. We contribute the diagnostic framework, the diagnosed real-data negative, the alignment-tax replication, and the routing-as-classification finding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that aggregate 'personalization' metrics for user-side memory in LLMs obscure opposing failures, and that memory factorizes into three orthogonal axes (behavioral consistency/style, factual presence/recall, factual absence/abstention). On a controlled 50-user synthetic corpus and LaMP-3, gamma-LoRA wins behavioral style while RAG wins factual absence; the same query-projection cells in attention layers 21-35 causally drive both effects in opposite directions (zeroing raises absence TPR +33 pp and drops presence TPR 20 pp). On Llama-3.1-8B-Instruct the asymmetry widens (an 'alignment tax'); LaMP-3 underperformance is diagnosed as instruction-following collapse via a 9-condition mitigation sweep, and substrate routing is shown to be better solved by question classification than logit-based methods.
Significance. If the three axes prove orthogonal and independently measurable, and if the causal role of layers 21-35 is robust, the work would be significant for personalized LLM research by replacing single-score evaluation with a diagnostic framework that reveals substrate trade-offs. Strengths include the controlled synthetic corpus, the attention-intervention design providing causal evidence, replication of the alignment-tax finding on Llama, the 9-condition mitigation sweep, and the routing-as-classification result. These elements go beyond correlational comparisons.
major comments (3)
- [§3.1] §3.1 (Synthetic Corpus Construction): The central claim that the three axes are orthogonal and that 'no single substrate wins all three' rests on the 50-user corpus producing independent presence and absence probes. The manuscript provides no explicit verification (e.g., correlation matrix between probe scores or ablation of fact-insertion patterns) that shared context or fact patterns do not induce dependence; without this, the conclusion that gamma-LoRA and RAG win different axes does not follow.
- [§4.3] §4.3 and Table 2 (Attention Intervention Results): The reported TPR shifts from zeroing query-projection weights in layers 21-35 (+33 pp absence, -20 pp presence) are load-bearing for the causal claim that the same cells drive opposite effects. No statistical tests, standard errors, or per-seed variance are reported, so it is impossible to assess whether the changes exceed noise or are consistent across the 50 users.
- [§5.2] §5.2 (LaMP-3 Negative Result and 9-Condition Sweep): The diagnosis that underperformance is instruction-following collapse (not substrate failure) relies on the 9x2 cross-product reaching main_acc >=0.995. The manuscript does not report data-exclusion rules, per-user breakdowns, or how the majority baseline was computed; these details are required to confirm the result is not an artifact of class imbalance or post-hoc condition selection.
minor comments (3)
- [Abstract] Abstract: 'gamma-LoRA' is used without a one-sentence gloss; a brief parenthetical definition would improve accessibility.
- [Figure 4] Figure 4 (Mitigation Sweep): The 9-condition plot would be clearer with explicit labeling of the logit-mask values {1..5} on the x-axis and a legend distinguishing training-time vs. eval-time fixes.
- [§2] §2 (Related Work): The comparison to prior personalization benchmarks omits recent work on abstention calibration in retrieval-augmented models; adding 2-3 citations would strengthen context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the strengths of the controlled corpus, causal interventions, alignment-tax replication, and routing result. We address each major comment below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Synthetic Corpus Construction): The central claim that the three axes are orthogonal and that 'no single substrate wins all three' rests on the 50-user corpus producing independent presence and absence probes. The manuscript provides no explicit verification (e.g., correlation matrix between probe scores or ablation of fact-insertion patterns) that shared context or fact patterns do not induce dependence; without this, the conclusion that gamma-LoRA and RAG win different axes does not follow.
Authors: The corpus construction deliberately used disjoint fact sets for presence versus absence probes per user, with no shared context across probe types, to support independence. We agree, however, that an explicit check strengthens the orthogonality claim. In revision we will add (i) a correlation matrix across the three axis scores over the 50 users and (ii) an ablation removing or randomizing fact-insertion patterns to quantify any residual dependence. revision: yes
-
Referee: [§4.3] §4.3 and Table 2 (Attention Intervention Results): The reported TPR shifts from zeroing query-projection weights in layers 21-35 (+33 pp absence, -20 pp presence) are load-bearing for the causal claim that the same cells drive opposite effects. No statistical tests, standard errors, or per-seed variance are reported, so it is impossible to assess whether the changes exceed noise or are consistent across the 50 users.
Authors: The reported deltas are means over 50 users and multiple random seeds, but we concur that formal statistical support is required. The revision will report standard errors, per-user and per-seed variance, and paired statistical tests (e.g., t-tests) confirming that the +33 pp and -20 pp shifts are significant and consistent across users. revision: yes
-
Referee: [§5.2] §5.2 (LaMP-3 Negative Result and 9-Condition Sweep): The diagnosis that underperformance is instruction-following collapse (not substrate failure) relies on the 9x2 cross-product reaching main_acc >=0.995. The manuscript does not report data-exclusion rules, per-user breakdowns, or how the majority baseline was computed; these details are required to confirm the result is not an artifact of class imbalance or post-hoc condition selection.
Authors: We will add the missing details: (i) data-exclusion rules (none beyond standard length and format filters), (ii) per-user accuracy tables, and (iii) the exact majority-baseline definition (per-user mode of the test-set labels). These additions will allow direct verification that the >=0.995 result is not driven by imbalance or selective reporting. revision: yes
Circularity Check
No circularity; claims rest on direct empirical measurements and interventions
full rationale
The paper presents an empirical comparison of gamma-LoRA vs. RAG on a synthetic 50-user corpus and LaMP-3, using measured TPR differences, zeroing interventions on attention cells (layers 21-35), and a mitigation sweep. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Central claims (axis factorization, substrate asymmetry, alignment tax) derive from observed performance deltas and replication across models, not from quantities defined in terms of themselves. The diagnostic framework is introduced via the experiments rather than presupposed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three axes (behavioral consistency, factual presence, factual absence) are orthogonal and independently measurable by the presence/absence probes used.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Salemi, Alireza and Mysore, Sheshera and Bendersky, Michael and Zamani, Hamed , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[2]
2024 , eprint =
Hebert, Liam and Sayana, Krishna and Jash, Ambarish and Karatzoglou, Alexandros and Sodhi, Sukhdeep and Doddapaneni, Sumanth and Cai, Yanli and Kuzmin, Dima , title =. 2024 , eprint =
2024
-
[3]
2025 , eprint =
Liu, Langming and Liu, Shilei and Yuan, Yujin and Zhang, Yizhen and Yan, Bencheng and Zeng, Zhiyuan and Wang, Zihao and Liu, Jiaqi and Wang, Di and Su, Wenbo and Wang, Pengjie and Xu, Jian and Zheng, Bo , title =. 2025 , eprint =
2025
-
[4]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Lester, Brian and Al-Rfou, Rami and Constant, Noah , title =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2021
-
[5]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Li, Xiang Lisa and Liang, Percy , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[6]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =. International Conference on Learning Representations (ICLR) , year =
-
[7]
COLM , year =
Huang, Chengsong and Liu, Qian and Lin, Bill Yuchen and Pang, Tianyu and Du, Chao and Lin, Min , title =. COLM , year =
-
[8]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , title =. 2023 , eprint =
2023
-
[9]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[10]
International Conference on Machine Learning (ICML) , year =
Borgeaud, Sebastian and Mensch, Arthur and Hoffmann, Jordan and Cai, Trevor and Rutherford, Eliza and Millican, Katie and van den Driessche, George and Lespiau, Jean-Baptiste and Damoc, Bogdan and Clark, Aidan and others , title =. International Conference on Machine Learning (ICML) , year =
-
[11]
and Cai, Carrie J
Park, Joon Sung and O'Brien, Joseph C. and Cai, Carrie J. and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST) , year =
-
[12]
2024 , eprint =
Chhikara, Prateek and Khant, Dev and Aryan, Saket and Singh, Taranjeet and Yadav, Deshraj , title =. 2024 , eprint =
2024
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , title =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[14]
2024 , eprint =
Xu, Wujiang and Liang, Zujie and Mei, Kai and Gao, Hang and Tan, Juntao and Zhang, Yongfeng , title =. 2024 , eprint =
2024
-
[15]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Lin, Stephanie and Hilton, Jacob and Evans, Owain , title =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[16]
2022 , eprint =
Kadavath, Saurav and Conerly, Tom and Askell, Amanda and Henighan, Tom and Drain, Dawn and Perez, Ethan and Schiefer, Nicholas and Hatfield-Dodds, Zac and DasSarma, Nova and Tran-Johnson, Eli and others , title =. 2022 , eprint =
2022
-
[17]
International Conference on Learning Representations (ICLR) , year =
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , title =. International Conference on Learning Representations (ICLR) , year =
-
[18]
2023 , eprint =
Yang, Yuqing and Chern, Ethan and Qiu, Xipeng and Neubig, Graham and Liu, Pengfei , title =. 2023 , eprint =
2023
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[20]
2023 , howpublished =
Schulman, John , title =. 2023 , howpublished =
2023
-
[21]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer , title =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2021
-
[22]
2024 , eprint =
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and others , title =. 2024 , eprint =
2024
-
[23]
2023 , eprint =
Xiao, Shitao and Liu, Zheng and Zhang, Peitian and Muennighoff, Niklas , title =. 2023 , eprint =
2023
-
[24]
and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , title =
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A. and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , title =. Proceedings of the National Academy of Sciences (PNAS) , ...
2017
-
[25]
2018 , url =
Li, Zhizhong and Hoiem, Derek , title =. 2018 , url =
2018
-
[26]
and Torr, Philip H
Chaudhry, Arslan and Rohrbach, Marcus and Elhoseiny, Mohamed and Ajanthan, Thalaiyasingam and Dokania, Puneet K. and Torr, Philip H. S. and Ranzato, Marc'Aurelio , title =. ICML Workshop on Multi-Task and Lifelong Reinforcement Learning , year =
-
[27]
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
Pfeiffer, Jonas and Kamath, Aishwarya and R. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
-
[28]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Wang, Yaqing and Mukherjee, Subhabrata and Liu, Xiaodong and Gao, Jing and Awadallah, Ahmed Hassan and Gao, Jianfeng , title =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2022
-
[29]
2024 , eprint =
Wu, Xun and Huang, Shaohan and Wei, Furu , title =. 2024 , eprint =
2024
-
[30]
Brendan and Moore, Eider and Ramage, Daniel and Hampson, Seth and Ag
McMahan, H. Brendan and Moore, Eider and Ramage, Daniel and Hampson, Seth and Ag. Communication-Efficient Learning of Deep Networks from Decentralized Data , booktitle =. 2017 , url =
2017
-
[31]
Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li , title =
Abadi, Martin and Chu, Andy and Goodfellow, Ian and McMahan, H. Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li , title =. Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS) , year =
2016
-
[32]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and others , title =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[33]
Proceedings of the 16th ACM Conference on Recommender Systems (RecSys) , year =
Geng, Shijie and Liu, Shuchang and Fu, Zuohui and Ge, Yingqiang and Zhang, Yongfeng , title =. Proceedings of the 16th ACM Conference on Recommender Systems (RecSys) , year =
-
[34]
Proceedings of the 17th ACM Conference on Recommender Systems (RecSys) , year =
Bao, Keqin and Zhang, Jizhi and Zhang, Yang and Wang, Wenjie and Feng, Fuli and He, Xiangnan , title =. Proceedings of the 17th ACM Conference on Recommender Systems (RecSys) , year =
-
[35]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =
-
[36]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2023
-
[37]
, title =
Li, Xuechen and Zhang, Tianyi and Dubois, Yann and Taori, Rohan and Gulrajani, Ishaan and Guestrin, Carlos and Liang, Percy and Hashimoto, Tatsunori B. , title =. 2023 , howpublished =
2023
-
[38]
Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang
Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2016. URL https://arxiv.org/abs/1607.00133
Pith/arXiv arXiv 2016
-
[39]
Self-RAG : Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG : Learning to retrieve, generate, and critique through self-reflection. In International Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/2310.11511. Cited as 2023 (arXiv release)
Pith/arXiv arXiv 2024
-
[40]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. TALLRec : An effective and efficient tuning framework to align large language model with recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems (RecSys), 2023. URL https://arxiv.org/abs/2305.00447
arXiv 2023
-
[41]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In International Conference on Machine Learning (ICML), 2022. URL https://arxiv.org/abs/2112.04426
Pith/arXiv arXiv 2022
-
[42]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems (NeurIPS), 2020. URL https://arxiv.org/abs/2005.14165
Pith/arXiv arXiv 2020
-
[43]
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, Puneet K. Dokania, Philip H. S. Torr, and Marc'Aurelio Ranzato. On tiny episodic memories in continual learning. In ICML Workshop on Multi-Task and Lifelong Reinforcement Learning, 2019. URL https://arxiv.org/abs/1902.10486
Pith/arXiv arXiv 2019
-
[44]
Mem0 : Building production-ready ai agents with scalable long-term memory, 2024
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0 : Building production-ready ai agents with scalable long-term memory, 2024
2024
-
[45]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing ( RLP ): A unified pretrain, personalized prompt and predict paradigm ( P5 ). In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys), 2022. URL https://arxiv.org/abs/2203.13366
arXiv 2022
-
[46]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021. URL https://arxiv.org/abs/2012.14913
Pith/arXiv arXiv 2021
-
[47]
Liam Hebert, Krishna Sayana, Ambarish Jash, Alexandros Karatzoglou, Sukhdeep Sodhi, Sumanth Doddapaneni, Yanli Cai, and Dima Kuzmin. PERSOMA : PER sonalized SO ft pro M pt adapter architecture for personalized language prompting, 2024. URL https://arxiv.org/abs/2408.00960
arXiv 2024
-
[48]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA : Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022. URL https://arxiv.org/abs/2106.09685. arXiv preprint 2021
Pith/arXiv arXiv 2022
-
[49]
LoraHub : Efficient cross-task generalization via dynamic lora composition
Chengsong Huang, Qian Liu, Bill Yuchen Lin, Tianyu Pang, Chao Du, and Min Lin. LoraHub : Efficient cross-task generalization via dynamic lora composition. In COLM, 2024. URL https://arxiv.org/abs/2307.13269
arXiv 2024
-
[50]
Language models (mostly) know what they know, 2022
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know, 2022
2022
-
[51]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences (PNAS), 114 0...
arXiv 2017
-
[52]
The power of scale for parameter-efficient prompt tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021. URL https://arxiv.org/abs/2104.08691
Pith/arXiv arXiv 2021
-
[53]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems (NeurIPS), 2020. URL https://arxiv.org/a...
Pith/arXiv arXiv 2020
-
[54]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL), 2021. URL https://arxiv.org/abs/2101.00190
Pith/arXiv arXiv 2021
-
[55]
Hashimoto
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. AlpacaEval : An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval, 2023
2023
-
[56]
Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) , 40 0 (12): 0 2935--2947, 2018. URL https://arxiv.org/abs/1606.09282
Pith/arXiv arXiv 2018
-
[57]
TruthfulQA : Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA : Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022. URL https://arxiv.org/abs/2109.07958
Pith/arXiv arXiv 2022
-
[58]
UQABench : Evaluating user embedding for prompting LLM s in personalized question answering, 2025
Langming Liu, Shilei Liu, Yujin Yuan, Yizhen Zhang, Bencheng Yan, Zhiyuan Zeng, Zihao Wang, Jiaqi Liu, Di Wang, Wenbo Su, Pengjie Wang, Jian Xu, and Bo Zheng. UQABench : Evaluating user embedding for prompting LLM s in personalized question answering, 2025. URL https://arxiv.org/abs/2502.19178
arXiv 2025
-
[59]
G-Eval : NLG evaluation using GPT-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval : NLG evaluation using GPT-4 with better human alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023. URL https://arxiv.org/abs/2303.16634
Pith/arXiv arXiv 2023
-
[60]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Ag \"u era y Arcas
H. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Ag \"u era y Arcas. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), 2017. URL https://arxiv.org/abs/1602.05629
arXiv 2017
-
[61]
Training language models to follow instructions with human feedback
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), 2022. URL https://arxiv.org/abs/2203.02155
Pith/arXiv arXiv 2022
-
[62]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT : Towards llms as operating systems, 2023
2023
-
[63]
Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), 2023. URL https://arxiv.org/abs/2304.03442
Pith/arXiv arXiv 2023
-
[64]
AdapterFusion : Non-destructive task composition for transfer learning
Jonas Pfeiffer, Aishwarya Kamath, Andreas R \"u ckl \'e , Kyunghyun Cho, and Iryna Gurevych. AdapterFusion : Non-destructive task composition for transfer learning. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL), 2021. URL https://arxiv.org/abs/2005.00247
arXiv 2021
-
[65]
Qwen3 technical report, 2025
Qwen Team . Qwen3 technical report, 2025. URL https://qwenlm.github.io/blog/qwen3/. Qwen3-4B base model used in primary experiments
2025
-
[66]
LaMP : When large language models meet personalization
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. LaMP : When large language models meet personalization. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. URL https://arxiv.org/abs/2304.11406
arXiv 2024
-
[67]
Reinforcement learning from human feedback: Progress and challenges
John Schulman. Reinforcement learning from human feedback: Progress and challenges. Berkeley EECS Colloquium talk, 2023. URL https://www.youtube.com/watch?v=hhiLw5Q_UFg
2023
-
[68]
AdaMix : Mixture-of-adaptations for parameter-efficient model tuning
Yaqing Wang, Subhabrata Mukherjee, Xiaodong Liu, Jing Gao, Ahmed Hassan Awadallah, and Jianfeng Gao. AdaMix : Mixture-of-adaptations for parameter-efficient model tuning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022. URL https://arxiv.org/abs/2205.12410
arXiv 2022
-
[69]
Mixture of LoRA experts, 2024
Xun Wu, Shaohan Huang, and Furu Wei. Mixture of LoRA experts, 2024
2024
-
[70]
C-pack: Packaged resources to advance general C hinese embedding, 2023
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general C hinese embedding, 2023. BGE embedding model family used for retrieval
2023
-
[71]
A-MEM : Agentic memory for LLM agents, 2024
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM : Agentic memory for LLM agents, 2024. TODO verify eprint id; original cited as 2410.10739
arXiv 2024
-
[72]
Yuqing Yang, Ethan Chern, Xipeng Qiu, Graham Neubig, and Pengfei Liu. Alignment for honesty, 2023. URL https://arxiv.org/abs/2312.07000
arXiv 2023
-
[73]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM -as-a-judge with MT-Bench and chatbot arena. In Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023. URL https://arxiv.or...
Pith/arXiv arXiv 2023
-
[74]
MemoryBank : Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank : Enhancing large language models with long-term memory. In Proceedings of the AAAI Conference on Artificial Intelligence, 2024. URL https://arxiv.org/abs/2305.10250
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.