Language-Driven Cost Optimization for Autonomous Driving
Pith reviewed 2026-06-27 13:20 UTC · model grok-4.3
The pith
An LLM interprets natural language queries to set cost parameters for an autonomous vehicle's motion planner, allowing intuitive behavior adjustments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
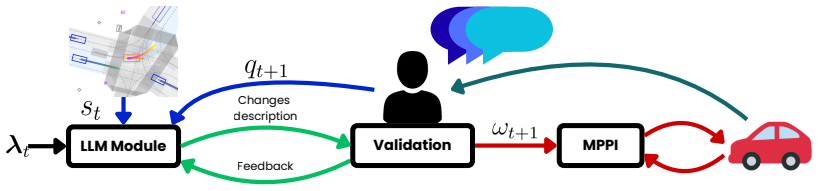
The paper claims that feeding structured scenario descriptions together with natural language user queries into a large language model produces cost parameters for a risk-aware Model Predictive Path Integral controller that induce driving behavior matching the stated intent, with a human-in-the-loop stage confirming the changes in non-technical terms prior to deployment and supporting iterative refinement through further feedback.
What carries the argument
The language-driven framework that maps natural language queries and scenario descriptions through an LLM to cost parameters for a risk-aware Model Predictive Path Integral (MPPI) controller, followed by human validation of the resulting behavioral description.
If this is right
- End users can modify autonomous driving behavior using everyday language instead of adjusting numerical weights directly.
- The vehicle can adapt its motion planning to new traffic conditions or personal preferences through repeated language-based feedback.
- Proposed behavioral shifts are described in plain terms and approved by a human before the parameters are applied to the controller.
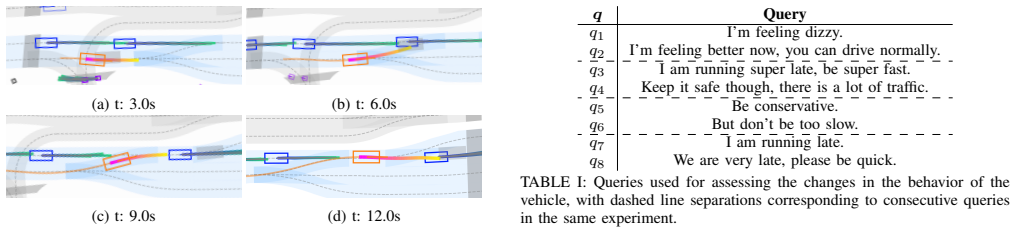
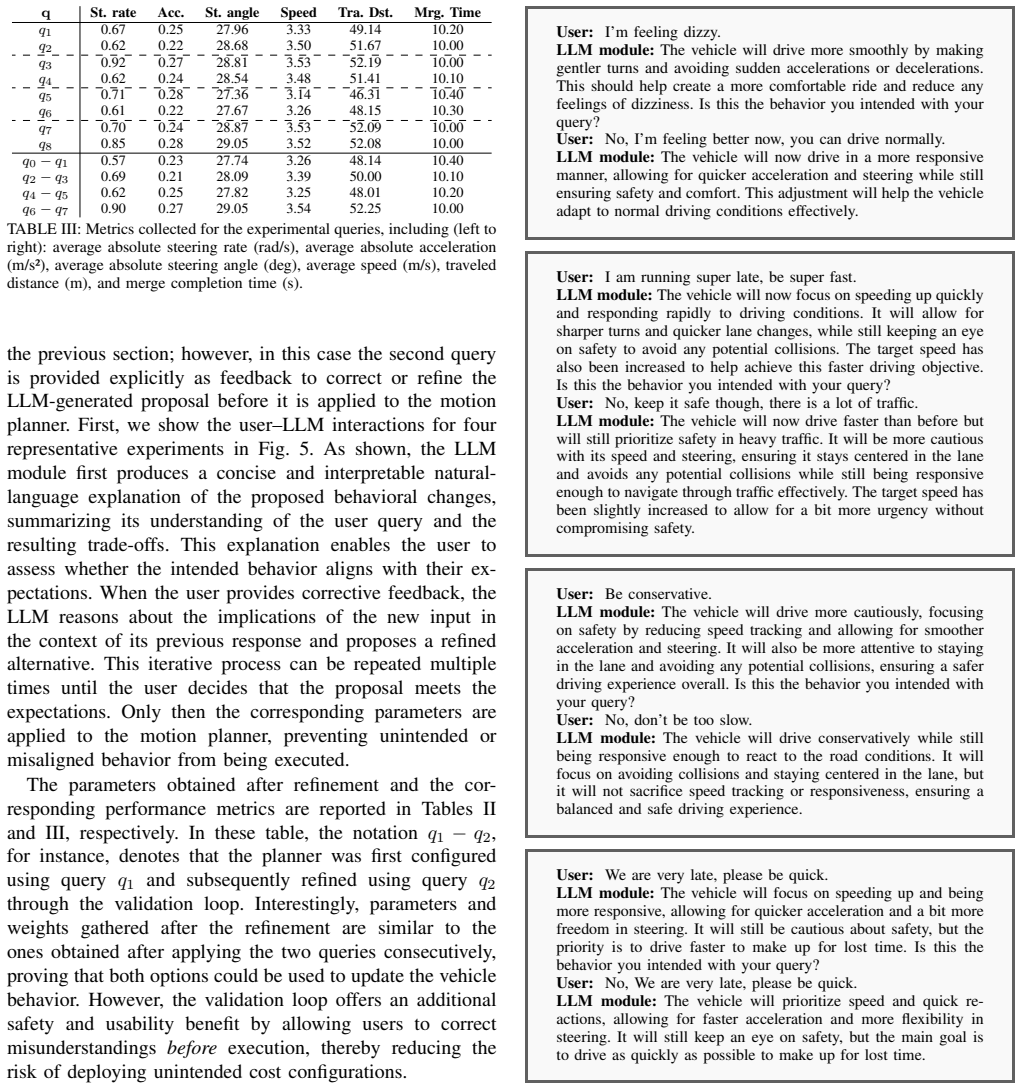
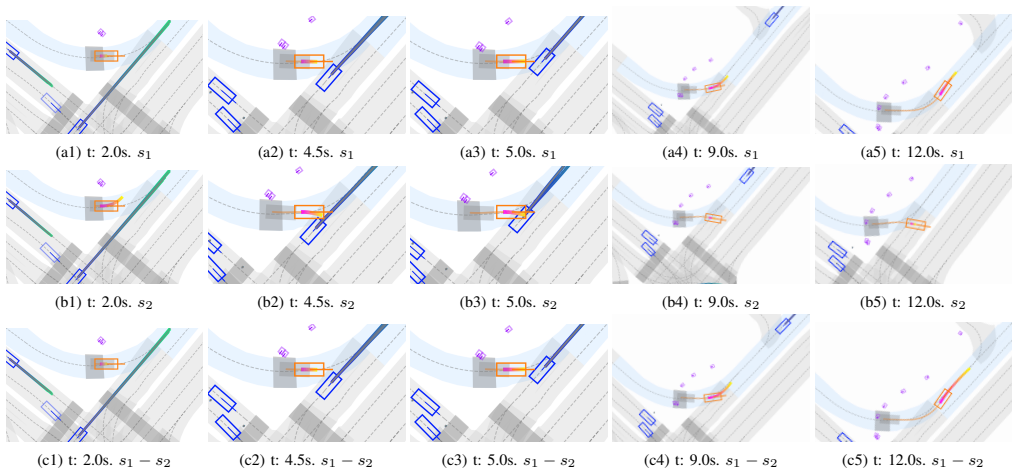
- Simulation experiments confirm that the induced trajectories align with the requirements expressed in the original queries.
Where Pith is reading between the lines
- Real-world road testing would be needed to check whether the LLM-generated parameters produce safe outcomes outside the simulated environments used in the paper.
- The same language interface could be applied to other motion planners beyond MPPI if the cost structure is similar.
- Aggregating preferences from multiple users over time might allow the system to learn consistent regional or cultural driving styles.
Load-bearing premise
The large language model will generate cost parameters that remain safe and faithful to the user's intent across the full range of driving situations the vehicle may meet.
What would settle it
A test scenario in which a user requests 'more cautious driving' and the generated parameters still produce a collision or lane departure that a standard safety check would flag.
Figures

read the original abstract
The driving behavior of autonomous vehicles is typically governed by the cost function of their motion planner, which encodes objectives such as speed tracking, smoothness, lane keeping, and collision avoidance. However, tuning the parameters that shape this cost function is a challenging task that requires technical expertise, limiting the vehicle's ability to adapt to evolving traffic scenarios or end-user preferences. This work presents a language-driven framework for adaptive cost design in autonomous driving. A Large Language Model (LLM) interprets structured scenario descriptions and natural language user queries to generate the parameters applied to a risk-aware Model Predictive Path Integral (MPPI) controller. The system incorporates a human-in-the-loop validation stage in which the proposed behavioral changes are described in non-technical language and confirmed prior to deployment. Users may additionally provide feedback either before or after deployment, enabling iterative refinement of the vehicle's motion behavior. The framework is evaluated across multiple queries in realistic driving scenarios to assess its effectiveness. Simulation results demonstrate that the method successfully induces behavioral changes that align with the intended requirements in an intuitive manner, thereby bridging the gap between intelligent vehicle control systems and end users.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a language-driven framework for adaptive cost design in autonomous driving. An LLM interprets structured scenario descriptions and natural language user queries to generate parameters for a risk-aware MPPI controller. The system includes a human-in-the-loop validation stage where proposed changes are described in non-technical language for confirmation, with options for iterative user feedback. Simulation results are claimed to show that the method induces behavioral changes aligned with user intent.
Significance. If the central claim holds under rigorous evaluation, the work could meaningfully lower the barrier for non-expert users to customize AV behavior via natural language, improving adaptability without requiring control-theory expertise. The engineering composition of LLM parameter generation, risk-aware MPPI, and human oversight is a practical contribution, though it relies on existing components rather than introducing new theoretical machinery or parameter-free derivations.
major comments (2)
- [Abstract] Abstract: The assertion that 'simulation results demonstrate that the method successfully induces behavioral changes that align with the intended requirements' is unsupported by any quantitative metrics, baseline comparisons, failure cases, or details on how LLM-generated parameters were validated for safety and consistency; this directly undermines assessment of the central claim.
- [Evaluation] Evaluation (implied by abstract claims): No information is given on the coverage of realistic driving scenarios, the range of user queries tested, or quantitative measures of alignment/safety, leaving the generalization and reliability of LLM-generated cost weights (e.g., for collision avoidance) unestablished.
minor comments (1)
- [Abstract] Abstract: The description of the human-in-the-loop stage could clarify the exact workflow for translating proposed parameter changes into non-technical language and how user feedback is incorporated into refinement.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important gaps in how the evaluation is presented. We agree that the current manuscript relies primarily on qualitative demonstrations and will revise to provide clearer descriptions of the tested scenarios, queries, and validation process while accurately qualifying the strength of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'simulation results demonstrate that the method successfully induces behavioral changes that align with the intended requirements' is unsupported by any quantitative metrics, baseline comparisons, failure cases, or details on how LLM-generated parameters were validated for safety and consistency; this directly undermines assessment of the central claim.
Authors: We acknowledge the referee is correct that the abstract claim is overstated relative to the evidence provided. The manuscript presents qualitative trajectory examples and narrative descriptions of behavioral shifts in a small set of scenarios, without quantitative metrics, baselines, or systematic failure analysis. We will revise the abstract to read that simulation results 'illustrate' rather than 'demonstrate' alignment, and we will add an explicit limitations paragraph discussing the absence of quantitative validation and the reliance on human-in-the-loop oversight for safety. revision: yes
-
Referee: [Evaluation] Evaluation (implied by abstract claims): No information is given on the coverage of realistic driving scenarios, the range of user queries tested, or quantitative measures of alignment/safety, leaving the generalization and reliability of LLM-generated cost weights (e.g., for collision avoidance) unestablished.
Authors: The referee correctly notes the lack of detail. The paper evaluates the framework on a limited number of hand-crafted scenarios (highway following, intersection yielding, and lane change) with a handful of natural-language queries, but provides no enumeration of coverage, no quantitative alignment scores, and no safety-consistency checks beyond the human validation step. We will expand the evaluation section with a table listing all tested scenarios and queries, describe the human-in-the-loop confirmation protocol in more detail, and add a discussion of why quantitative metrics were not computed in the present work. We cannot retroactively supply new experimental data without additional runs. revision: partial
Circularity Check
No circularity; framework is compositional engineering of existing components
full rationale
The paper describes an engineering system that composes an LLM for parameter generation, a risk-aware MPPI controller, and human-in-the-loop validation. No equations, derivations, fitted models, or predictions are presented. The abstract and description contain no self-definitional steps, no fitted inputs renamed as predictions, and no load-bearing self-citations that reduce the central claim to prior author work. Evaluation consists of simulation demonstrations of behavioral alignment rather than any closed mathematical chain. This matches the default case of a self-contained engineering composition with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ag- ile mixed-integer-based lane-change mpc for collision-free and effi- cient autonomous driving,
A. L. Gratzer, A. Schmiedhofer, A. Schirrer, and S. Jakubek, “Ag- ile mixed-integer-based lane-change mpc for collision-free and effi- cient autonomous driving,”IEEE Transactions on Intelligent Vehicles, vol. 10, pp. 4153–4170, 2025
2025
-
[2]
Integrating driving- aware world model with mpc for autonomous driving at unsignalized t-intersections,
X. Zhang, Z. Wu, H. Hu, J. Yang, and P. Wang, “Integrating driving- aware world model with mpc for autonomous driving at unsignalized t-intersections,”IEEE Transactions on Intelligent Transportation Sys- tems, vol. 26, pp. 22 219–22 231, 2025
2025
-
[3]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosenet al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radfordet al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
A survey on multimodal large language models for autonomous driving,
C. Cui, Y . Ma, X. Cao, W. Ye, Y . Zhou, K. Liang, J. Chen, J. Lu, Z. Yang, K.-D. Liaoet al., “A survey on multimodal large language models for autonomous driving,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2024, pp. 958– 979
2024
-
[6]
Large (vision) language models for autonomous vehicles: Current trends and future directions,
H. Tian, K. Reddy, Y . Feng, M. Quddus, Y . Demiris, and P. An- geloudis, “Large (vision) language models for autonomous vehicles: Current trends and future directions,”IEEE Transactions on Intelligent Transportation Systems, vol. 27, no. 1, pp. 187–210, 2026
2026
-
[7]
DriveLM: Driving with graph visual question answering,
C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, J. Beißwenger, P. Luo, A. Geiger, and H. Li, “DriveLM: Driving with graph visual question answering,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 256–274
2024
-
[8]
Drive like a human: Rethinking autonomous driving with large language models,
D. Fu, X. Li, L. Wen, M. Dou, P. Cai, B. Shi, and Y . Qiao, “Drive like a human: Rethinking autonomous driving with large language models,” in2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW). IEEE, 2024, pp. 910–919
2024
-
[9]
DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models,
L. Wen, D. Fu, X. Li, X. Cai, T. MA, P. Cai, M. Dou, B. Shi, L. He, and Y . Qiao, “DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[10]
SurrealDriver: Designing LLM-powered Generative Driver Agent Framework based on Human Drivers’ Driving-thinking Data,
Y . Jin, R. Yang, Z. Yi, X. Shen, H. Peng, X. Liu, J. Qin, J. Li, J. Xie, P. Gaoet al., “SurrealDriver: Designing LLM-powered Generative Driver Agent Framework based on Human Drivers’ Driving-thinking Data,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 966–971
2024
-
[11]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” Advances in Neural Information Processing Systems, vol. 36, pp. 8634–8652, 2023
2023
-
[12]
Koma: Knowledge-driven multi-agent framework for autonomous driving with large language models,
K. Jiang, X. Cai, Z. Cui, A. Li, Y . Ren, H. Yu, H. Yang, D. Fu, L. Wen, and P. Cai, “Koma: Knowledge-driven multi-agent framework for autonomous driving with large language models,”IEEE Transactions on Intelligent Vehicles, 2024
2024
-
[13]
Y . Lin, S. Illing, and M. Althoff, “Sandra: Safe large-language-model- based decision making for automated vehicles using reachability analysis,”arXiv preprint arXiv:2510.06717, 2025
-
[14]
Rt- 1: Robotics transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt- 1: Robotics transformer for real-world control at scale,”Robotics: Science and Systems XIX, 2023
2023
-
[15]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[16]
OpenVLA: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “OpenVLA: An open-source vision-language-action model,” in8th Annual Conference on Robot Learning, 2024
2024
-
[17]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finnet al., “Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1702–1713
2025
-
[18]
Lmdrive: Closed-loop end-to-end driving with large language models,
H. Shao, Y . Hu, L. Wang, G. Song, S. L. Waslander, Y . Liu, and H. Li, “Lmdrive: Closed-loop end-to-end driving with large language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 120–15 130
2024
-
[19]
From words to wheels: Automated style-customized policy generation for autonomous driving,
X. Han, X. Chen, Z. Cai, P. Cai, M. Zhu, and X. Chu, “From words to wheels: Automated style-customized policy generation for autonomous driving,”arXiv preprint arXiv:2409.11694, 2024
-
[20]
Z. Huang, Z. Sheng, Y . Qu, J. You, and S. Chen, “Vlm-rl: A unified vision language models and reinforcement learning framework for safe autonomous driving,”arXiv preprint arXiv:2412.15544, 2024
-
[21]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in2023 IEEE International conference on robotics and automation (ICRA). IEEE, 2023, pp. 9493–9500
2023
-
[22]
Do as i can, not as i say: Grounding language in robotic affordances,
A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julianet al., “Do as i can, not as i say: Grounding language in robotic affordances,” inConference on robot learning. PMLR, 2023, pp. 287–318
2023
-
[23]
Chatmpc: Natural language based mpc personalization,
Y . Miyaoka, M. Inoue, and T. Nii, “Chatmpc: Natural language based mpc personalization,” in2024 American Control Conference (ACC). IEEE, 2024, pp. 3598–3603
2024
-
[24]
Hey robot! Personalizing robot navigation through model predictive control with a large language model,
D. Martinez-Baselga, O. de Groot, L. Knoedler, J. Alonso-Mora, L. Ri- azuelo, and L. Montano, “Hey robot! Personalizing robot navigation through model predictive control with a large language model,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 11 002–11 009
2025
-
[25]
Enhancing Autonomous Driving Systems with On- Board Deployed Large Language Models,
N. Baumann, C. Hu, P. Sivasothilingam, H. Qin, L. Xie, M. Magno, and L. Benini, “Enhancing Autonomous Driving Systems with On- Board Deployed Large Language Models,” inProceedings of Robotics: Science and Systems, 2025
2025
-
[26]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model,
Z. Xu, Y . Zhang, E. Xie, Z. Zhao, Y . Guo, K.-Y . K. Wong, Z. Li, and H. Zhao, “Drivegpt4: Interpretable end-to-end autonomous driving via large language model,”IEEE Robotics and Automation Letters, 2024
2024
-
[27]
Drive as you speak: Enabling human-like interaction with large language models in autonomous vehicles,
C. Cui, Y . Ma, X. Cao, W. Ye, and Z. Wang, “Drive as you speak: Enabling human-like interaction with large language models in autonomous vehicles,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 902–909
2024
-
[28]
Model predictive path integral control: From theory to parallel computation,
G. Williams, A. Aldrich, and E. A. Theodorou, “Model predictive path integral control: From theory to parallel computation,”Journal of Guidance, Control, and Dynamics, vol. 40, no. 2, pp. 344–357, 2017
2017
-
[29]
Information-Theoretic Model Predictive Control: Theory and Ap- plications to Autonomous Driving,
G. Williams, P. Drews, B. Goldfain, J. M. Rehg, and E. A. Theodorou, “Information-Theoretic Model Predictive Control: Theory and Ap- plications to Autonomous Driving,”IEEE Transactions on Robotics, vol. 34, no. 6, pp. 1603–1622, 2018
2018
-
[30]
Dynamic risk-aware mppi for mobile robots in crowds via efficient monte carlo approximations,
E. Trevisan, K. A. Mustafa, G. Notten, X. Wang, and J. Alonso- Mora, “Dynamic risk-aware mppi for mobile robots in crowds via efficient monte carlo approximations,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, pp. 313– 320
2025
-
[31]
A survey on in-context learning,
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, B. Changet al., “A survey on in-context learning,” inProceedings of the 2024 conference on empirical methods in natural language processing, 2024, pp. 1107–1128
2024
-
[32]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[33]
Large language models are zero-shot reasoners,
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa, “Large language models are zero-shot reasoners,”Advances in neural infor- mation processing systems, vol. 35, pp. 22 199–22 213, 2022
2022
-
[34]
Do nlp models know numbers? probing numeracy in embeddings,
E. Wallace, Y . Wang, S. Li, S. Singh, and M. Gardner, “Do nlp models know numbers? probing numeracy in embeddings,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pp. 5307–5315
2019
-
[35]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
2022
-
[36]
Language models don’t always say what they think: Unfaithful explanations in chain- of-thought prompting,
M. Turpin, J. Michael, E. Perez, and S. Bowman, “Language models don’t always say what they think: Unfaithful explanations in chain- of-thought prompting,”Advances in Neural Information Processing Systems, vol. 36, pp. 74 952–74 965, 2023
2023
-
[37]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
H. Caesar, J. Kabzan, K. S. Tan, W. K. Fong, E. Wolff, A. Lang, L. Fletcher, O. Beijbom, and S. Omari, “nuplan: A closed-loop ml- based planning benchmark for autonomous vehicles,”arXiv preprint arXiv:2106.11810, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
Smart: Scalable multi-agent real-time motion generation via next-token prediction,
W. Wu, X. Feng, Z. Gao, and Y . Kan, “Smart: Scalable multi-agent real-time motion generation via next-token prediction,”Advances in Neural Information Processing Systems, vol. 37, pp. 114 048–114 071, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.