REST3D: Reconstructing Physically Stable 3D Scenes from a Single Image
Pith reviewed 2026-06-29 07:42 UTC · model grok-4.3
The pith
A gravity-support scene tree lets single-image 3D reconstruction produce scenes that stay stable under physics simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
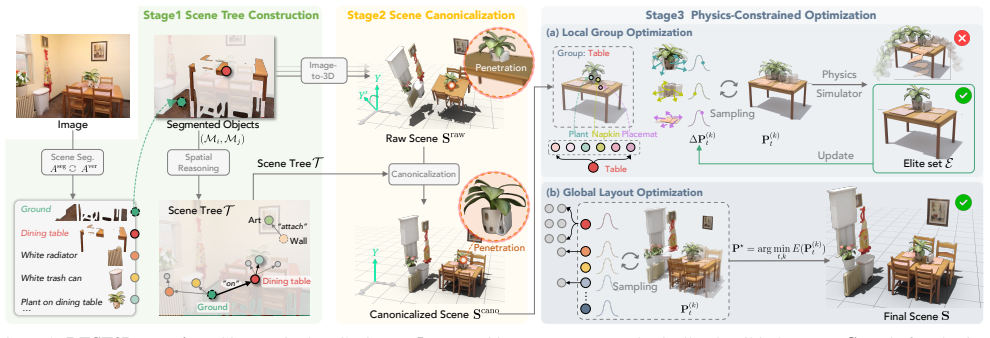
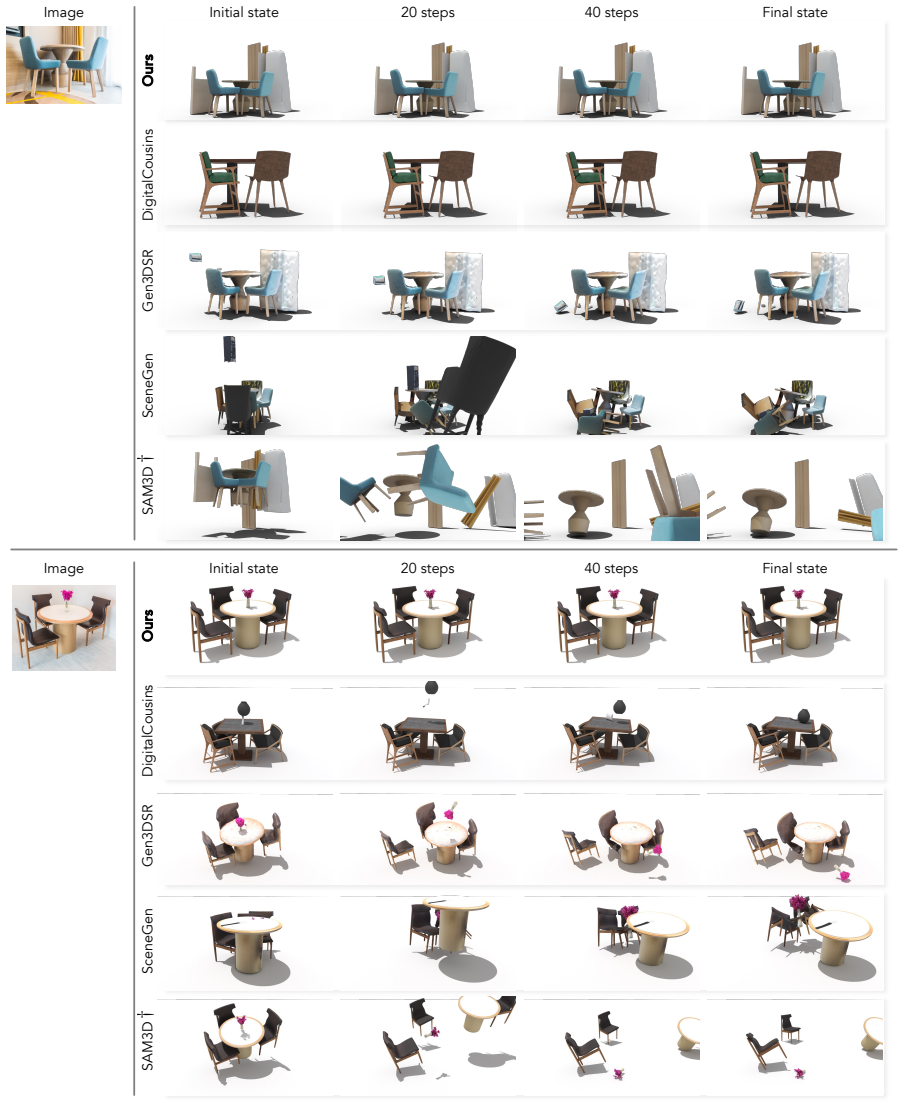
REST3D reconstructs physically stable 3D scenes from a single RGB image by first using an agentic physical scene understanding technique to build a scene-tree representation that captures object physical states and inter-object relationships from a gravity-support perspective, then initializing the scene with image-to-3D models and applying scene-tree-guided alignment together with physics-constrained optimization to resolve physical violations while preserving visual consistency with the input image.
What carries the argument
The scene-tree representation that encodes object physical states and gravity-support relationships, used as a structural prior to guide alignment and optimization.
If this is right
- Reconstructed scenes can be dropped directly into physics engines without immediate instability.
- Visual fidelity to the input image is retained after the physics refinement step.
- The same pipeline works on both synthetic and real-world photographs.
- The output scenes support downstream uses such as VR human-object interaction.
Where Pith is reading between the lines
- The scene-tree prior could be applied as a post-process to other existing single-image 3D methods.
- Extending the tree to include friction or joint constraints might allow reconstruction of articulated objects.
- The same gravity-support structure could serve as a prior for video-based scene reconstruction.
Load-bearing premise
The agentic physical scene understanding step produces a scene-tree that correctly records which objects support which others under gravity.
What would settle it
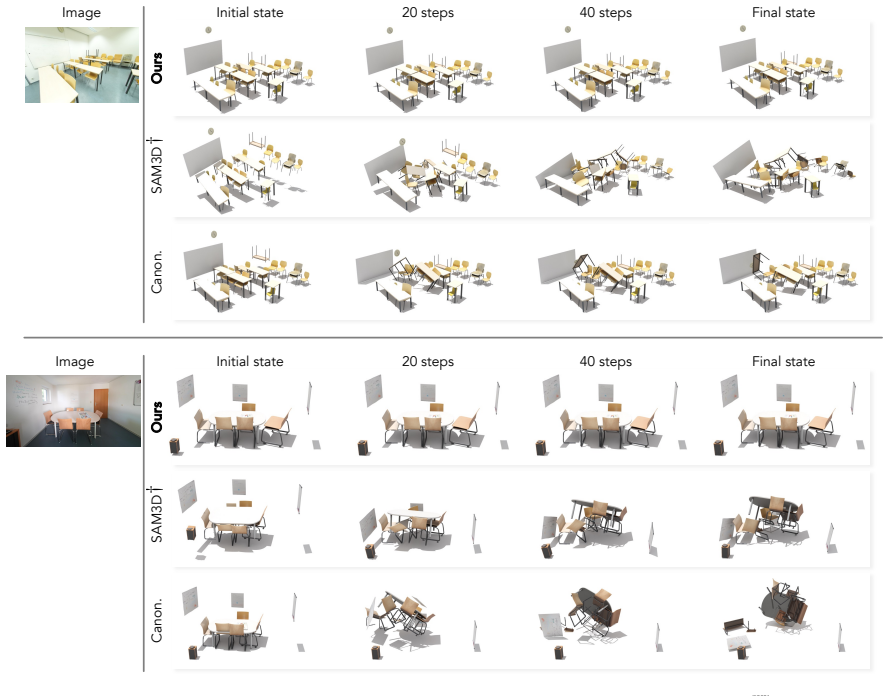
Reconstruct scenes from the paper's test images, drop the outputs into a standard rigid-body simulator, and count the fraction of objects that still float or penetrate after one second of simulation; a rate comparable to prior single-image methods would falsify the stability improvement.
Figures












read the original abstract
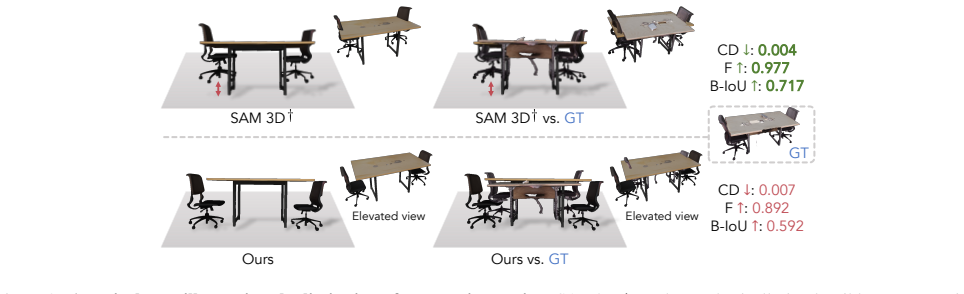
Reconstructing physically stable 3D scenes from a single RGB image enables casual images to be converted into simulation-ready digital assets for applications such as immersive interaction and content creation. However, existing single-image reconstruction methods fall short in capturing the physical structure of a scene. As a result, they often produce geometrically plausible but physically inconsistent results, including object floating and penetration, which lead to unstable behavior in physics simulations. Image-conditioned scene generation methods improve physical plausibility but often rely on strong scene priors, yielding plausible yet inaccurate object arrangements that fail to match the input image. We propose REST3D, a single-image reconstruction framework that can reconstruct physically stable 3D scenes by integrating physical scene understanding with physics-constrained refinement. We first introduce an agentic physical scene understanding technique that constructs a scene-tree representation capturing object physical states and inter-object relationships from a gravity-support perspective, providing a structural prior for reconstruction. Leveraging this structure, we initialize the scene using image-to-3D models, followed by scene-tree-guided alignment and physics-constrained optimization to resolve physical violations while preserving visual consistency with the input image. Experiments show that our method significantly reduces physical errors and improves simulation stability on both synthetic and real-world datasets while maintaining strong reconstruction quality. We further demonstrate the reconstructed scenes in VR-based human-object interaction, showing their potential for immersive applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes REST3D, a single-image 3D scene reconstruction framework that integrates an agentic physical scene understanding technique to construct a scene-tree representation capturing object physical states and inter-object relationships from a gravity-support perspective. This provides a structural prior for initializing the scene via image-to-3D models, followed by scene-tree-guided alignment and physics-constrained optimization to resolve physical violations (e.g., floating or penetration) while preserving visual consistency with the input image. Experiments on synthetic and real-world datasets are claimed to show significant reductions in physical errors and improved simulation stability, with an additional demonstration in VR-based human-object interaction.
Significance. If the central claims hold, the work would address an important gap between geometrically plausible single-image reconstructions and simulation-ready outputs, with potential impact on immersive applications. The scene-tree prior and physics-constrained refinement represent a structured way to inject physical understanding, which could improve upon both pure reconstruction and strong-prior generation methods if the agentic step proves reliable.
major comments (1)
- [Abstract] Abstract: The central claim that the agentic physical scene understanding 'reliably constructs a scene-tree representation that accurately captures object physical states and inter-object relationships' is load-bearing for the entire pipeline, yet the provided description gives no implementation details, prompts, or validation of this step. Without evidence that this module produces a valid structural prior rather than introducing errors, the subsequent alignment and optimization cannot be assessed as sufficient to guarantee physical stability.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying the need for clearer support of the agentic scene understanding claim. We address the point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the agentic physical scene understanding 'reliably constructs a scene-tree representation that accurately captures object physical states and inter-object relationships' is load-bearing for the entire pipeline, yet the provided description gives no implementation details, prompts, or validation of this step. Without evidence that this module produces a valid structural prior rather than introducing errors, the subsequent alignment and optimization cannot be assessed as sufficient to guarantee physical stability.
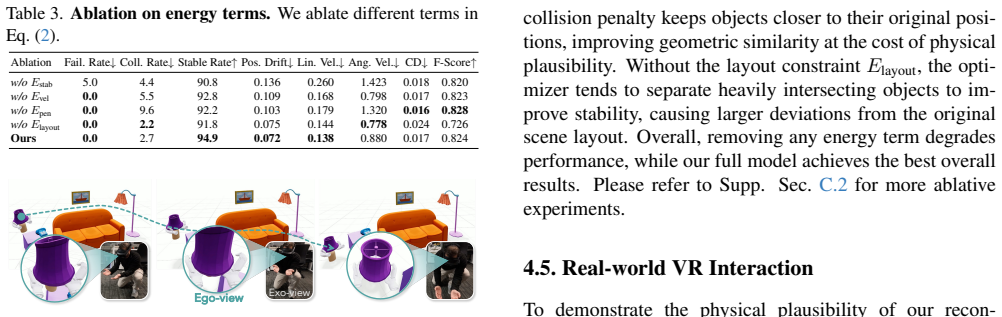
Authors: We agree the abstract is high-level by design and does not contain implementation details. Section 3.1 of the manuscript describes the agentic scene-tree construction process, including the gravity-support perspective and LLM-based agent reasoning. Prompts, agent workflow, and manual validation of the resulting scene-trees (including error rates on a held-out set) appear in the supplementary material. Quantitative evidence that the prior improves physical metrics is given via ablations in Section 4.3 and Tables 2-3, where removing the scene-tree step increases floating/penetration errors. We will revise the abstract to replace 'reliably' with 'constructs' and add a sentence directing readers to the methods and supplement for details. revision: partial
Circularity Check
No significant circularity
full rationale
The abstract and available description outline a pipeline that invokes external image-to-3D models, standard physics optimization, and an agentic scene-tree construction step without presenting any equations, fitted parameters, or derivations that reduce to the method's own inputs by construction. No self-citations, ansatzes, or uniqueness claims are load-bearing in the provided text, and the reconstruction claims rest on independent components rather than self-referential definitions or renamings.
Axiom & Free-Parameter Ledger
invented entities (1)
-
scene-tree representation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Generalizable 3d scene reconstruction via divide and conquer from a single view
Andreea Ardelean, Mert ¨Ozer, and Bernhard Egger. Generalizable 3d scene reconstruction via divide and conquer from a single view. InInternational Confer- ence on 3D Vision (3DV), 2025. 1, 2, 5, 6, 7, 17, 23
2025
-
[2]
Scenecad: Predicting object alignments and layouts in rgb-d scans
Armen Avetisyan, Tatiana Khanova, Christopher Choy, Denver Dash, Angela Dai, and Matthias Nießner. Scenecad: Predicting object alignments and layouts in rgb-d scans. InEuropean Conference on Computer Vision (ECCV), 2020. 2
2020
-
[3]
Method for regis- tration of 3-d shapes
Paul J Besl and Neil D McKay. Method for regis- tration of 3-d shapes. InSensor fusion IV: control paradigms and data structures, pages 586–606, 1992. 6
1992
-
[4]
SAM 3: Segment anything with concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris Coll- Vinent, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman R ¨adle, Tri- antafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, ...
2026
-
[5]
Scenefoundry: Generating interactive infinite 3d worlds.arXiv preprint arXiv:2601.05810,
ChunTeng Chen, YiChen Hsu, YiWen Liu, WeiFang Sun, TsaiChing Ni, ChunYi Lee, Min Sun, and YuanFu Yang. Scenefoundry: Generating interactive infinite 3d worlds.arXiv preprint arXiv:2601.05810,
-
[6]
SAM 3D: 3Dfy Anything in Images
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025. 1, 2, 3, 6, 16, 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Urdformer: A pipeline for constructing articulated simulation envi- ronments from real-world images.Robotics: Science and Systems (RSS), 2024
Zoey Chen, Aaron Walsman, Marius Memmel, Kaichun Mo, Alex Fang, Karthikeya Vemuri, Alan Wu, Dieter Fox, and Abhishek Gupta. Urdformer: A pipeline for constructing articulated simulation envi- ronments from real-world images.Robotics: Science and Systems (RSS), 2024. 2
2024
-
[8]
Open-television: Teleoperation with immersive active visual feedback
Xuxin Cheng, Jialong Li, Shiqi Yang, Ge Yang, and Xiaolong Wang. Open-television: Teleoperation with immersive active visual feedback. In8th Annual Con- ference on Robot Learning, 2024. 19
2024
-
[9]
Automated creation of digital cousins for robust policy learning
Tianyuan Dai, Josiah Wong, Yunfan Jiang, Chen Wang, Cem Gokmen, Ruohan Zhang, Jiajun Wu, and Li Fei-Fei. Automated creation of digital cousins for robust policy learning. InConference on Robot Learn- ing (CoRL), 2024. 2, 5, 6, 7, 9, 15, 17, 21, 23
2024
-
[10]
Trimesh [computer soft- ware].https : / / github
Michael Dawson-Haggerty. Trimesh [computer soft- ware].https : / / github . com / mikedh / trimesh, 2019. 15
2019
-
[11]
A tutorial on the cross- entropy method.Annals of operations research, 134 (1):19–67, 2005
Pieter-Tjerk De Boer, Dirk P Kroese, Shie Mannor, and Reuven Y Rubinstein. A tutorial on the cross- entropy method.Annals of operations research, 134 (1):19–67, 2005. 4
2005
-
[12]
A fast procedure for computing the distance between complex objects in three-dimensional space
Elmer G Gilbert, Daniel W Johnson, and S Sathiya Keerthi. A fast procedure for computing the distance between complex objects in three-dimensional space. IEEE Journal on Robotics and Automation, 4(2):193– 203, 1988. 5
1988
-
[13]
Ditto in the house: Building articulation models of in- door scenes through interactive perception
Cheng-Chun Hsu, Zhenyu Jiang, and Yuke Zhu. Ditto in the house: Building articulation models of in- door scenes through interactive perception. InIn- ternational Conference on Robotics and Automation (ICRA), 2023. 2
2023
-
[14]
Litereality: Graphics-ready 3d scene recon- struction from rgb-d scans.Advances in Neural Infor- mation Processing Systems (NeurIPS), 2025
Zhening Huang, Xiaoyang Wu, Fangcheng Zhong, Hengshuang Zhao, Matthias Nießner, and Joan Lasenby. Litereality: Graphics-ready 3d scene recon- struction from rgb-d scans.Advances in Neural Infor- mation Processing Systems (NeurIPS), 2025. 2
2025
-
[15]
Ditto: Building digital twins of articulated objects from inter- action
Zhenyu Jiang, Cheng-Chun Hsu, and Yuke Zhu. Ditto: Building digital twins of articulated objects from inter- action. InConference on Computer Vision and Pattern Recognition (CVPR), 2022. 2
2022
-
[16]
Articulate- anything: Automatic modeling of articulated ob- jects via a vision-language foundation model.In- ternational Conference on Learning Representations (ICLR), 2025
Long Le, Jason Xie, William Liang, Hung-Ju Wang, Yue Yang, Yecheng Jason Ma, Kyle Vedder, Arjun Kr- ishna, Dinesh Jayaraman, and Eric Eaton. Articulate- anything: Automatic modeling of articulated ob- jects via a vision-language foundation model.In- ternational Conference on Learning Representations (ICLR), 2025. 2
2025
-
[17]
Instructscene: Instruction-driven 3d indoor scene synthesis with se- mantic graph prior
Chenguo Lin and Yadong Mu. Instructscene: Instruction-driven 3d indoor scene synthesis with se- mantic graph prior. InInternational Conference on Learning Representations (ICLR), 2024. 2
2024
-
[18]
Pat3d: Physics-augmented text-to-3d scene generation.In- ternational Conference on Learning Representations (ICLR), 2026
Guying Lin, Kemeng Huang, Michael Liu, Ruihan Gao, Hanke Chen, Lyuhao Chen, Beijia Lu, Taku Ko- mura, Yuan Liu, Jun-Yan Zhu, and Minchen Li. Pat3d: Physics-augmented text-to-3d scene generation.In- ternational Conference on Learning Representations (ICLR), 2026. 2
2026
-
[19]
Chang, Manolis Savva, and Ali Mahdavi-Amiri
Jiayi Liu, Denys Iliash, Angel X. Chang, Manolis Savva, and Ali Mahdavi-Amiri. SINGAPO: Single image controlled generation of articulated parts in ob- ject.International Conference on Learning Represen- tations (ICLR), 2025. 2
2025
-
[20]
Isaac gym: High performance GPU based physics simulation for robot learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. Isaac gym: High performance GPU based physics simulation for robot learning. InPro- ceedings of the Neural Information Processing Sys- tems (NeurIPS) Track on Datasets and Benchmarks,
-
[21]
LOCATE 3d: Real-world object lo- calization via self-supervised learning in 3d
Paul McVay, Sergio Arnaud, Ada Martin, Arjun Majumdar, Krishna Murthy Jatavallabhula, Phillip Thomas, Ruslan Partsey, Daniel Dugas, Abha Gejji, Alexander Sax, Vincent-Pierre Berges, Mikael Henaff, Ayush Jain, Ang Cao, Ishita Prasad, Mrinal Kalakr- ishnan, Michael Rabbat, Nicolas Ballas, Mido Ass- ran, Oleksandr Maksymets, Aravind Rajeswaran, and Franziska...
-
[22]
Scenegen: Single-image 3d scene generation in one feedforward pass
Yanxu Meng, Haoning Wu, Ya Zhang, and Weidi Xie. Scenegen: Single-image 3d scene generation in one feedforward pass. InInternational Conference on 3D Vision (3DV), 2026. 1, 2, 5, 6, 7, 17, 21, 22
2026
-
[23]
Phyrecon: Physically plausible neural scene reconstruction
Junfeng Ni, Yixin Chen, Bohan Jing, Nan Jiang, Bin Wang, Bo Dai, Puhao Li, Yixin Zhu, Song-Chun Zhu, and Siyuan Huang. Phyrecon: Physically plausible neural scene reconstruction. 2024. 1, 2, 15
2024
-
[24]
Decomposi- tional neural scene reconstruction with generative dif- fusion prior
Junfeng Ni, Yu Liu, Ruijie Lu, Zirui Zhou, Song-Chun Zhu, Yixin Chen, and Siyuan Huang. Decomposi- tional neural scene reconstruction with generative dif- fusion prior. InConference on Computer Vision and Pattern Recognition (CVPR), 2025. 2
2025
-
[25]
To- tal3dunderstanding: Joint layout, object pose and mesh reconstruction for indoor scenes from a single image
Yinyu Nie, Xiaoguang Han, Shihui Guo, Yujian Zheng, Jian Chang, and Jian Jun Zhang. To- tal3dunderstanding: Joint layout, object pose and mesh reconstruction for indoor scenes from a single image. InConference on Computer Vision and Pat- tern Recognition (CVPR), 2020. 1, 2
2020
-
[26]
SceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes
Nicholas Pfaff, Thomas Cohn, Sergey Zakharov, Rick Cory, and Russ Tedrake. Scenesmith: Agentic genera- tion of simulation-ready indoor scenes.arXiv preprint arXiv:2602.09153, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Corenet: Coherent 3d scene reconstruction from a sin- gle rgb image
Stefan Popov, Pablo Bauszat, and Vittorio Ferrari. Corenet: Coherent 3d scene reconstruction from a sin- gle rgb image. InEuropean Conference on Computer Vision (ECCV), 2020. 1, 2
2020
-
[28]
Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system
Yuzhe Qin, Wei Yang, Binghao Huang, Karl Van Wyk, Hao Su, Xiaolong Wang, Yu-Wei Chao, and Dieter Fox. Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system. InRobotics: Science and Systems, 2023. 19
2023
-
[29]
Rubinstein
Reuven Y . Rubinstein. Optimization of computer sim- ulation models with rare events.European Journal of Operational Research, 99(1):89–112, 1997. 4
1997
-
[30]
Tobias Sautter, Jan-Niklas Dihlmann, and Hendrik Lensch. 3d-re-gen: 3d reconstruction of indoor scenes with a generative framework.arXiv preprint arXiv:2512.17459, 2025. 1, 2, 15, 22
-
[31]
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xi- aqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Ba- tra, Hauke ...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[32]
Reconciling reality through simulation: A real-to-sim-to-real approach for robust manipulation
Marcel Torne, Anthony Simeonov, Zechu Li, April Chan, Tao Chen, Abhishek Gupta, and Pulkit Agrawal. Reconciling reality through simulation: A real-to-sim-to-real approach for robust manipulation. Robotics: Science and Systems (RSS), 2024. 2
2024
-
[33]
Efros, and Jitendra Malik
Shubham Tulsiani, Saurabh Gupta, David Fouhey, Alexei A. Efros, and Jitendra Malik. Factoring shape, pose, and layout from the 2d image of a 3d scene. In Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018. 1, 2
2018
-
[34]
Architect: Generating vivid and interactive 3d scenes with hierarchical 2d inpainting
Yian Wang, Xiaowen Qiu, Jiageng Liu, Zhehuan Chen, Jiting Cai, Yufei Wang, Tsun-Hsuan Wang, Zhou Xian, and Chuang Gan. Architect: Generating vivid and interactive 3d scenes with hierarchical 2d inpainting. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2024. 2
2024
-
[35]
Ziqian Wang, Yonghao He, Licheng Yang, Wei Zou, Hongxuan Ma, Liu Liu, Wei Sui, Yuxin Guo, and Hu Su. Tabletopgen: Instance-level interactive 3d table- top scene generation from text or single image.arXiv preprint arXiv:2512.01204, 2025. 2
-
[36]
Marble.https : / / www
World Labs. Marble.https : / / www . worldlabs . ai / blog / marble - world - model, 2025. 15, 17, 23
2025
-
[37]
Simrecon: Sim- ready compositional scene reconstruction from real videos.Conference on Computer Vision and Pattern Recognition (CVPR), 2026
Chong Xia, Kai Zhu, Zizhuo Wang, Fangfu Liu, Zhizheng Zhang, and Yueqi Duan. Simrecon: Sim- ready compositional scene reconstruction from real videos.Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 2
2026
-
[38]
Holoscene: Simu- lation-ready interactive 3d worlds from a single video
Hongchi Xia, Chih-Hao Lin, Hao-Yu Hsu, Quentin Leboutet, Katelyn Gao, Michael Paulitsch, Benjamin Ummenhofer, and Shenlong Wang. Holoscene: Simu- lation-ready interactive 3d worlds from a single video. InAdvances in Neural Information Processing Sys- tems (NeurIPS), 2025. 1
2025
-
[39]
Drawer: Digital reconstruction and articula- tion with environment realism
Hongchi Xia, Entong Su, Marius Memmel, Arhan Jain, Raymond Yu, Numfor Mbiziwo-Tiapo, Ali Farhadi, Abhishek Gupta, Shenlong Wang, and Wei- Chiu Ma. Drawer: Digital reconstruction and articula- tion with environment realism. InConference on Com- puter Vision and Pattern Recognition (CVPR), 2025. 2
2025
-
[40]
Sage: Scalable agentic 3d scene generation for embodied ai.Conference on Computer Vision and Pat- tern Recognition (CVPR), 2026
Hongchi Xia, Xuan Li, Zhaoshuo Li, Qianli Ma, Ji- ashu Xu, Ming-Yu Liu, Yin Cui, Tsung-Yi Lin, Wei- Chiu Ma, Shenlong Wang, Shuran Song, and Fangyin Wei. Sage: Scalable agentic 3d scene generation for embodied ai.Conference on Computer Vision and Pat- tern Recognition (CVPR), 2026. 2, 15, 16, 24
2026
-
[41]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. InConference on Computer Vision and Pattern Recognition (CVPR), pages 21469–21480, 2025. 2
2025
-
[42]
Holodeck: Lan- guage guided generation of 3d embodied ai environ- ments
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, et al. Holodeck: Lan- guage guided generation of 3d embodied ai environ- ments. InConference on Computer Vision and Pattern Recognition (CVPR), pages 16227–16237, 2024. 2
2024
-
[43]
Scannet++: A high-fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d indoor scenes. InInternational Confer- ence on Computer Vision (ICCV), pages 12–22, 2023. 6, 10, 15, 21
2023
-
[44]
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Shaofeng Yin, Jiaxin Ge, Zora Zhiruo Wang, Xi- uyu Li, Michael J Black, Trevor Darrell, Angjoo Kanazawa, and Haiwen Feng. Vision-as-inverse- graphics agent via interleaved multimodal reasoning. arXiv preprint arXiv:2601.11109, 2026. 2, 10 This supplementary material provides additional details on the method (Sec. A) and experimental setup (Sec. B), along ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.