Benchmarking Robot Memory Under Interference
Pith reviewed 2026-06-26 10:32 UTC · model grok-4.3
The pith
Current robot memory systems improve with relevant history but decay as unrelated sessions accumulate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
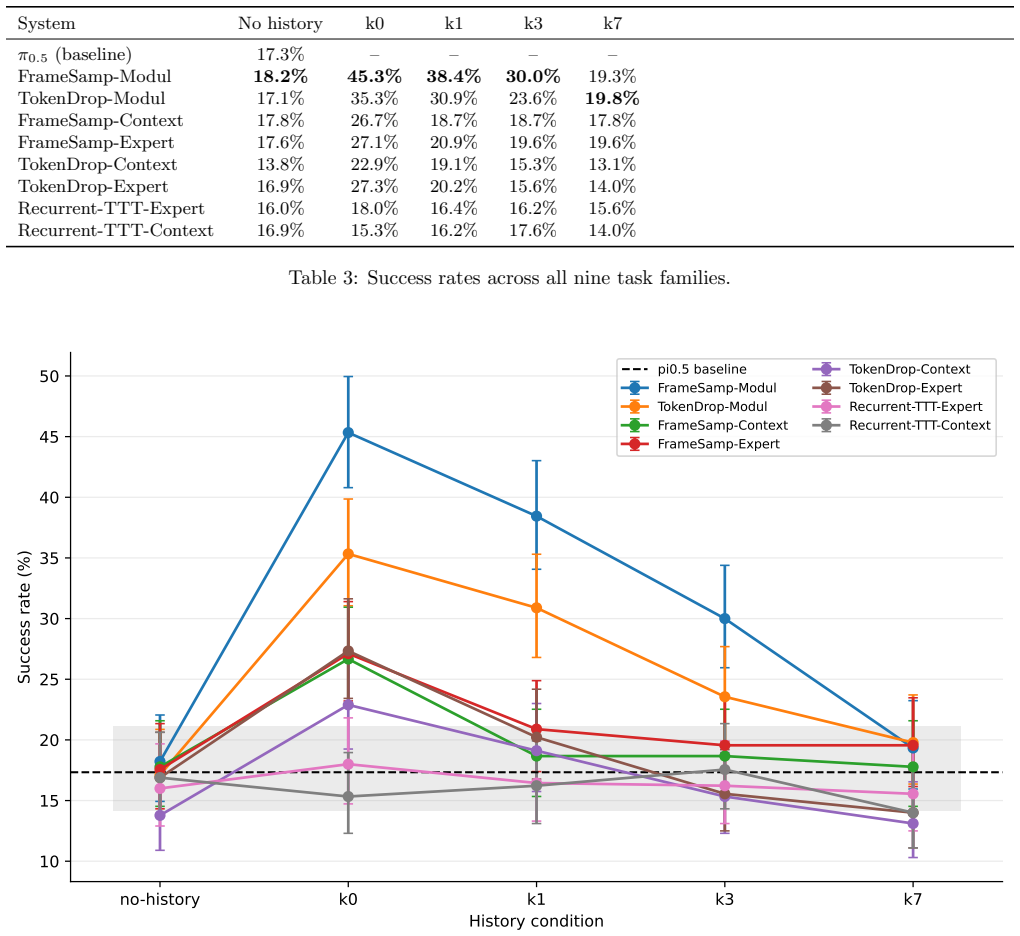
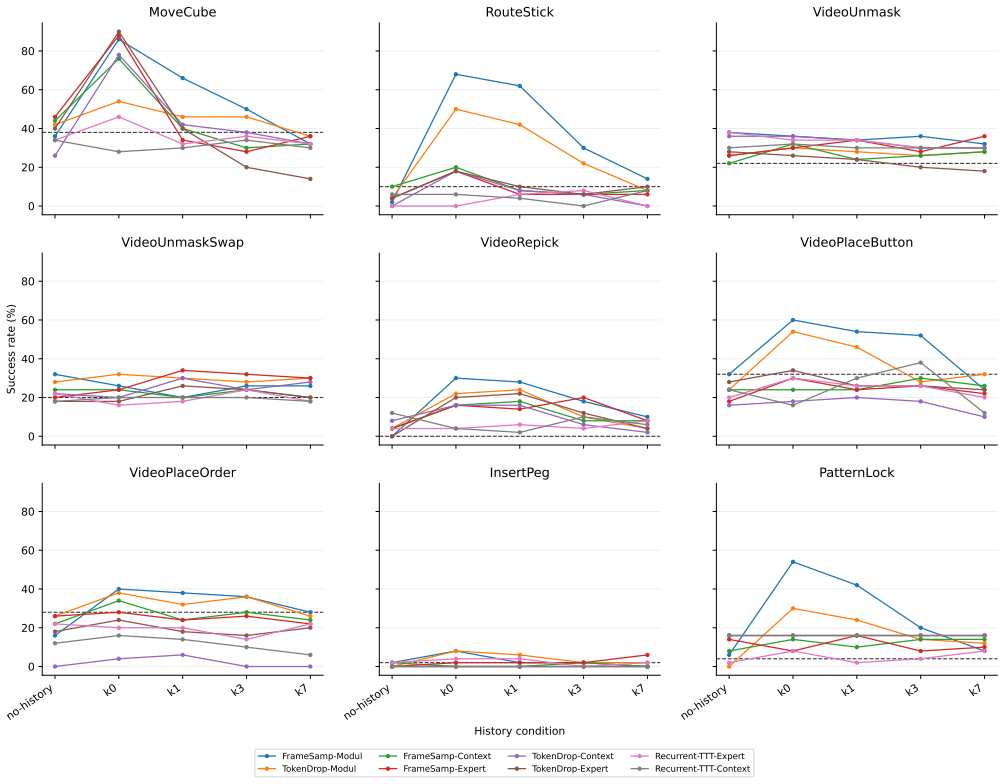
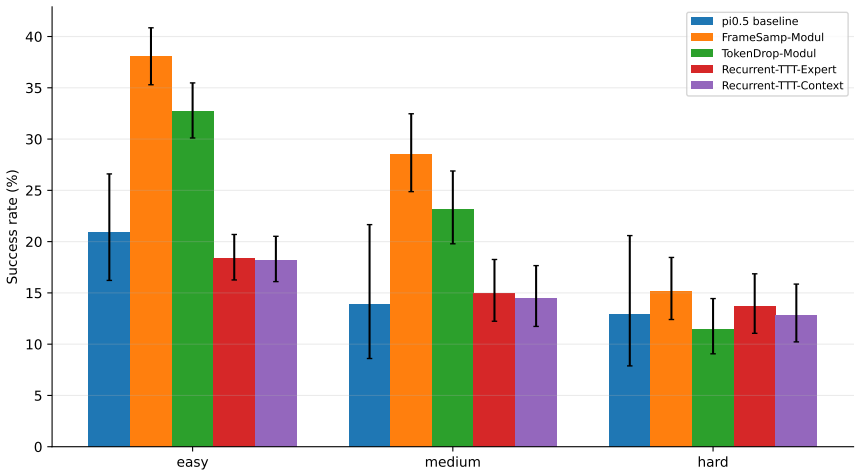
Running unmodified memory-augmented variants of π0.5 through the RoboMME-Interference benchmark reveals that perceptual memory improves success rates when provided with the query's relevant prior demonstration alone, but these gains decay strongly and steadily as the number of unrelated sessions in the history increases.
What carries the argument
The session history construction in RoboMME-Interference, which pairs the relevant demonstration with a controlled number of unrelated sessions to quantify interference effects on memory.
Load-bearing premise
Constructing session histories from one relevant demonstration followed by a controlled number of unrelated sessions serves as a valid proxy for the interference encountered in realistic multi-session robot deployments.
What would settle it
Observing that memory-augmented models maintain or increase their success rates as the number of unrelated sessions grows would contradict the reported steady decay under interference.
Figures
read the original abstract
Robots deployed in realistic settings will accumulate experience across many sessions and tasks over their deployment. The robot's tasks may often require it to remember information from multiple sessions ago, making long-context robot memory important for real-world deployments. However, most robot-memory benchmarks today are based on single episodes or a short context. To measure how current robot memory systems perform on longer sessions with more distractions, we introduce RoboMME-Interference, a cross-session benchmark built on RoboMME. For each query episode, we construct a session history using the query's relevant prior demonstration followed by a controlled number of unrelated sessions, which we provide to the VLA as memory and measure accuracy. Running RoboMME's released memory-augmented $\pi_{0.5}$ variants unmodified through this benchmark, we find that while perceptual memory variants improve success when given the history without any distractors, they decay strongly and steadily as unrelated sessions accumulate. With this release, we emphasize the importance of long-context memory and robustness to interference and show that current systems largely fail on such capabilities. The project page, videos, code, and data are at https://robotmemorybench.com.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the RoboMME-Interference benchmark, constructed by augmenting RoboMME query episodes with one relevant prior demonstration followed by a controlled number of unrelated sessions. Unmodified memory-augmented π₀.₅ VLA variants are evaluated on this history; the central finding is that perceptual memory improves success without distractors but exhibits strong, steady decay as the number of unrelated sessions increases. The work releases the benchmark, code, and data to emphasize the need for long-context memory robustness in multi-session robot deployments.
Significance. If the benchmark construction is accepted as a valid proxy, the results would identify a clear gap in current VLA memory systems' ability to handle accumulating interference, an issue directly relevant to realistic long-term robot operation. The open release of code, data, and project page is a concrete strength that supports reproducibility and community follow-up.
major comments (2)
- [Abstract / evaluation description] The evaluation reports only a qualitative decay result ('decay strongly and steadily') with no success rates, trial counts, variance measures, or statistical tests supplied in the abstract or evaluation description. This absence makes the magnitude and reliability of the central claim impossible to verify from the provided text and is load-bearing for the conclusion that 'current systems largely fail on such capabilities.'
- [Benchmark construction (Abstract)] The benchmark constructs each query history via simple concatenation of one relevant demonstration plus a fixed sequence of unrelated full sessions, yet provides no justification or sensitivity analysis showing that this matches the dominant sources of interference in deployed robots (e.g., partially overlapping tasks, eviction policies, or interleaved execution). Because the decay result is measured exclusively under this construction, its generalization to realistic multi-session settings rests on an untested assumption.
minor comments (1)
- [Abstract] The phrase 'VLA as memory' appears without prior definition of the specific π₀.₅ memory-augmented variants; a brief parenthetical or reference to the base RoboMME models would improve readability for readers outside the immediate sub-area.
Simulated Author's Rebuttal
Thank you for the detailed and constructive review. We appreciate the identification of areas where the presentation of results and benchmark assumptions can be strengthened. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / evaluation description] The evaluation reports only a qualitative decay result ('decay strongly and steadily') with no success rates, trial counts, variance measures, or statistical tests supplied in the abstract or evaluation description. This absence makes the magnitude and reliability of the central claim impossible to verify from the provided text and is load-bearing for the conclusion that 'current systems largely fail on such capabilities.'
Authors: We agree that the abstract relies on qualitative phrasing for the decay observation. The full evaluation section of the manuscript reports the underlying quantitative results, including success rates across interference levels, trial counts per condition, and variance measures. To address the concern directly, we will revise the abstract to incorporate key quantitative metrics from the experiments. This will make the magnitude of the effect verifiable at the abstract level without altering the manuscript's core findings. revision: yes
-
Referee: [Benchmark construction (Abstract)] The benchmark constructs each query history via simple concatenation of one relevant demonstration plus a fixed sequence of unrelated full sessions, yet provides no justification or sensitivity analysis showing that this matches the dominant sources of interference in deployed robots (e.g., partially overlapping tasks, eviction policies, or interleaved execution). Because the decay result is measured exclusively under this construction, its generalization to realistic multi-session settings rests on an untested assumption.
Authors: The construction deliberately uses controlled concatenation of one relevant demonstration followed by unrelated sessions to isolate the effect of accumulating distractors in a reproducible manner built directly on RoboMME episodes. This serves as a minimal proxy for studying interference in long-context memory. We acknowledge that it does not encompass all real-world sources such as task overlap, eviction policies, or interleaved execution, and no sensitivity analysis across alternative constructions was performed. In revision we will expand the benchmark construction section with explicit justification for the chosen design, a clear statement of its scope and limitations, and suggestions for future extensions that incorporate more complex interference models. revision: partial
Circularity Check
No circularity: empirical benchmark evaluation on unmodified models
full rationale
The paper constructs a new benchmark (RoboMME-Interference) by concatenating relevant demonstrations with unrelated sessions and evaluates released VLA models without modification or fitting. No equations, parameters, or derivations are present that could reduce reported decay rates to inputs by construction. Results are direct empirical measurements on the new benchmark. This is self-contained against external benchmarks and matches the expected non-finding for benchmarking papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The released memory-augmented π0.5 variants constitute a representative sample of current robot memory systems for the purpose of measuring interference robustness.
invented entities (1)
-
RoboMME-Interference benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tianxing Chen, Yuran Wang, Mingleyang Li, Yan Qin, Hao Shi, Zixuan Li, Yifan Hu, Yingsheng Zhang, Kaixuan Wang, Yue Chen, Hongcheng Wang, Renjing Xu, Ruihai Wu, Yao Mu, Yaodong Yang, Hao Dong, and Ping Luo. Rmbench: Memory-dependent robotic manipulation benchmark with insights into policy design.arXiv preprint arXiv:2603.01229,
-
[2]
Yinpei Dai, Hongze Fu, Jayjun Lee, Yuejiang Liu, Haoran Zhang, Jianing Yang, Chelsea Finn, Nima Fazeli, and Joyce Chai. Robomme: Benchmarking and understanding memory for robotic generalist policies.arXiv preprint arXiv:2603.04639,
-
[3]
Xinying Guo, Chenxi Jiang, Hyun Bin Kim, Ying Sun, Yang Xiao, Yuhang Han, and Jianfei Yang
ICML 2026 (Oral). Xinying Guo, Chenxi Jiang, Hyun Bin Kim, Ying Sun, Yang Xiao, Yuhang Han, and Jianfei Yang. Chameleon: Episodic memory for long-horizon robotic manipulation.arXiv preprint arXiv:2603.24576,
Pith/arXiv arXiv 2026
-
[4]
Huashuo Lei, Wenxuan Song, Huarui Zhang, Jieyuan Pei, Jiayi Chen, Haodong Yan, Han Zhao, Pengxiang Ding, Zhipeng Zhang, Lida Huang, Donglin Wang, Yan Wang, and Haoang Li. Robomemarena: A comprehensive and challenging robotic memory benchmark.arXiv preprint arXiv:2605.10921,
-
[5]
Runhao Li, Wenkai Guo, Zhenyu Wu, Changyuan Wang, Haoyuan Deng, Zhenyu Weng, Yap-Peng Tan, and Ziwei Wang. Map-vla: Memory-augmented prompting for vision-language-action model in robotic manipulation.arXiv preprint arXiv:2511.09516,
-
[6]
Evaluating very long-term conversational memory of llm agents.arXiv preprint arXiv:2402.17753,
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents.arXiv preprint arXiv:2402.17753,
-
[7]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y. Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch...
-
[8]
Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. arXiv preprint arXiv:2508.19236,
-
[9]
Memer: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328,
Ajay Sridhar, Jennifer Pan, Satvik Sharma, and Chelsea Finn. Memer: Scaling up memory for robot control via experience retrieval.arXiv preprint arXiv:2510.20328,
-
[10]
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, and Carlos Guestrin. Learning to (learn at test time): Rnns with expressive hidden states.arXiv preprint arXiv:2407.04620,
-
[11]
Mohammad Tavakoli, Alireza Salemi, Carrie Ye, Mohamed Abdalla, Hamed Zamani, and J. Ross Mitchell. Beyond a million tokens: Benchmarking and enhancing long-term memory in llms.arXiv preprint arXiv:2510.27246,
-
[12]
Ren, Sergey Levine, Chelsea Finn, and Danny Driess
Marcel Torne, Karl Pertsch, Homer Walke, Suraj Nair, Brian Ichter, Allen Z. Ren, Sergey Levine, Chelsea Finn, and Danny Driess. Mem: Multi-scale embodied memory for vision language action models.arXiv preprint arXiv:2603.03596,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.