What are the Right Symmetries for Formal Theorem Proving?
Pith reviewed 2026-05-22 08:11 UTC · model grok-4.3
The pith
LLM-based theorem provers fail to maintain consistent success rates across semantically equivalent problem statements because they lack proof equivariance and success invariance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
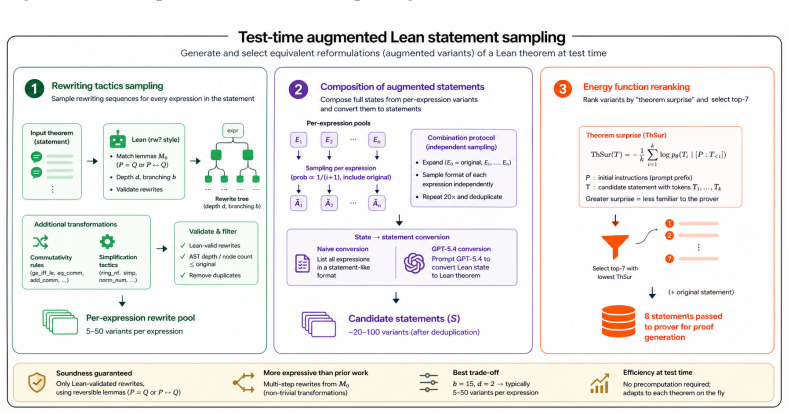
We introduce rewriting categories, a category-theoretic framework capturing the compositional, generally non-invertible transformations induced by proof tactics, and use it to formalize two symmetry notions: proof equivariance, governing how proof distributions transform under rewrites, and success invariance, requiring equivalent statements to be solved with the same probability. State-of-the-art LLM-based provers satisfy neither property, exhibiting large performance variation across equivalent formulations. Test-time methods that aggregate over equivalent rewritings recover success invariance in the sampling limit and improve robustness and performance under fixed inference budgets.
What carries the argument
Rewriting categories: a category-theoretic framework that captures compositional transformations induced by proof tactics and serves to define proof equivariance and success invariance.
If this is right
- State-based next-tactic provers already satisfy proof equivariance by operating directly on proof states.
- Aggregating over equivalent rewritings at test time recovers success invariance in the sampling limit.
- Test-time aggregation improves robustness and performance under fixed inference budgets without retraining.
- Symmetry should serve as a key inductive bias when designing future LLM-based theorem provers.
Where Pith is reading between the lines
- The same symmetry failures may appear in other AI systems for formal reasoning tasks such as program verification or type checking.
- Training models to be equivariant by design could reduce the need for test-time computation to enforce invariance.
- The rewriting category approach could be adapted to measure symmetry gaps in non-formal reasoning domains.
- Human mathematicians may implicitly rely on similar symmetry awareness when selecting equivalent problem formulations.
Load-bearing premise
The rewriting categories must generate a sufficient set of semantically equivalent statements whose proof difficulty remains comparable so that performance differences can be attributed to missing symmetry rather than changes in inherent hardness.
What would settle it
If applying the proposed test-time aggregation over rewritings does not reduce the observed variation in success rates across equivalent formulations or fails to improve overall proof success on a standard benchmark under fixed budgets, that would show the symmetries are not the primary driver of inconsistency.
Figures










read the original abstract
Formal theorem provers based on large language models (LLMs) are highly sensitive to superficial variations in problem representation: semantically equivalent statements can exhibit drastically different proof success rates, revealing a failure to respect structural symmetries inherent in formal mathematics. This raises a central question: what are the right symmetries for formal theorem proving? We introduce rewriting categories, a category-theoretic framework capturing the compositional, generally non-invertible transformations induced by proof tactics, and use it to formalize two symmetry notions: proof equivariance, governing how proof distributions transform under rewrites, and success invariance (i.e., invariance of success probability), requiring equivalent statements to be solved with the same probability. We observe that state-based next-tactic provers naturally satisfy proof equivariance by operating on proof states. In contrast, state-of-the-art LLM-based provers satisfy neither property, exhibiting large performance variation across equivalent formulations. To mitigate this, we propose test-time methods that aggregate over equivalent rewritings of the input, showing theoretically that they recover success invariance in the sampling limit, and empirically, that they improve robustness and performance under fixed inference budgets. Our results highlight symmetry as a key missing inductive bias in LLM-based theorem proving and suggest test-time computation as a practical route to approximate it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces rewriting categories, a category-theoretic framework for the compositional, generally non-invertible transformations induced by proof tactics. It formalizes proof equivariance (how proof distributions transform under rewrites) and success invariance (equivalent statements solved with equal probability). The central claims are that state-based next-tactic provers satisfy proof equivariance while state-of-the-art LLM-based provers satisfy neither, as evidenced by large success-rate variation across equivalent formulations generated by the rewriting categories; test-time aggregation over rewritings is shown to recover success invariance in the sampling limit and to improve robustness and performance under fixed inference budgets.
Significance. If the empirical results are supported by controls confirming that the rewriting categories preserve average proof difficulty, the work would identify a missing inductive bias in LLM theorem provers and supply both a formal language for symmetries and a practical test-time remedy. The category-theoretic framing and the theoretical guarantee for the aggregation method are notable strengths that could influence future architecture and inference design in automated theorem proving.
major comments (2)
- [§4] §4 (Empirical Evaluation): The central claim that large performance variation across rewriting categories demonstrates failure of success invariance rests on the assumption that the generated statements have comparable proof difficulty. No controls (e.g., proof-length distributions, tactic-applicability statistics, or search-space-size curves) are reported to confirm that difficulty is preserved on average; without them the observed gaps cannot be cleanly attributed to missing symmetry rather than difficulty shifts induced by the non-invertible rewrites.
- [§3.2] §3.2 (Success Invariance): The definition of success invariance requires that equivalent statements are solved with the same probability, yet the paper does not provide a quantitative bound or empirical check showing that the rewriting categories produce statements whose intrinsic difficulty remains statistically matched; this weakens the attribution of performance differences solely to the lack of symmetry.
minor comments (2)
- [Introduction] The distinction between state-based next-tactic provers and LLM-based provers is introduced late; an earlier explicit comparison in the introduction would improve readability.
- [§3] Notation for the objects and morphisms of the rewriting categories would benefit from one or two concrete examples drawn from a standard formal library (e.g., Lean or Isabelle) to make the category-theoretic constructions more accessible.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential impact of the rewriting-category framework and the test-time aggregation approach. The primary concern raised—that performance differences across rewritings may reflect changes in proof difficulty rather than violations of success invariance—is a substantive one. We address it directly below and commit to strengthening the empirical section accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Empirical Evaluation): The central claim that large performance variation across rewriting categories demonstrates failure of success invariance rests on the assumption that the generated statements have comparable proof difficulty. No controls (e.g., proof-length distributions, tactic-applicability statistics, or search-space-size curves) are reported to confirm that difficulty is preserved on average; without them the observed gaps cannot be cleanly attributed to missing symmetry rather than difficulty shifts induced by the non-invertible rewrites.
Authors: We agree that the absence of explicit difficulty controls leaves open the possibility that non-invertible rewrites alter average proof length, branching factor, or search-space size. In the revised manuscript we will add (i) side-by-side histograms and summary statistics of proof lengths for original versus rewritten statements across the evaluated datasets, (ii) average numbers of applicable tactics per state, and (iii) a simple proxy for search-space size (e.g., number of nodes expanded under a fixed budget). These statistics will be reported both in aggregate and broken down by rewrite category so that readers can judge whether difficulty is preserved on average. Should any systematic shift appear, we will discuss its magnitude relative to the observed performance gaps. revision: yes
-
Referee: [§3.2] §3.2 (Success Invariance): The definition of success invariance requires that equivalent statements are solved with the same probability, yet the paper does not provide a quantitative bound or empirical check showing that the rewriting categories produce statements whose intrinsic difficulty remains statistically matched; this weakens the attribution of performance differences solely to the lack of symmetry.
Authors: We concur that a quantitative or statistical check on difficulty matching would make the attribution to symmetry violation more robust. In addition to the controls listed in response to §4, we will include a Kolmogorov–Smirnov test (or equivalent) comparing the empirical distributions of the difficulty proxies between original and rewritten statements, together with a brief discussion of effect sizes. This will be placed in §3.2 or a new subsection of the empirical evaluation so that the theoretical definition of success invariance is immediately followed by the supporting empirical verification. revision: yes
Circularity Check
No significant circularity; derivation relies on new definitions and empirical observations rather than self-referential reductions.
full rationale
The paper defines rewriting categories as a new category-theoretic framework to formalize proof equivariance and success invariance, then reports empirical measurements showing that state-of-the-art LLM provers exhibit performance variation across rewrites while state-based provers satisfy equivariance by construction of their operation. The proposed test-time aggregation methods are justified by a sampling-limit argument that follows directly from the definitions of equivalence and invariance, without reducing any fitted parameter or central claim to prior self-citations or tautological inputs. No load-bearing step equates a prediction to its own fitting procedure or imports uniqueness via overlapping-author citations; the work is self-contained against external benchmarks of prover behavior.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Proof tactics induce compositional, generally non-invertible transformations on statements.
invented entities (1)
-
rewriting categories
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce rewriting categories, a category-theoretic framework capturing the compositional, generally non-invertible transformations induced by proof tactics, and use it to formalize two symmetry notions: proof equivariance... and success invariance
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A prover pθ is R-equivariant in proof distribution if pθ(· | T′) = P(t)(pθ(· | T)) for every arrow t : T → T′ in R
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ZZ Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, et al. Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition.arXiv preprint arXiv:2504.21801, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Haoyu Zhao, Yihan Geng, Shange Tang, Yong Lin, Bohan Lyu, Hongzhou Lin, Chi Jin, and Sanjeev Arora. Ineq-comp: Benchmarking human-intuitive compositional reasoning in automated theorem proving on inequalities. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[3]
Yuchen Tian, Ruiyuan Huang, WANG XUANWU, Jing Ma, Zengfeng Huang, Ziyang Luo, Hongzhan Lin, Da Zheng, and Lun Du. Evolprover: Advancing automated theorem proving by evolving formalized problems via symmetry and difficulty. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[4]
GSM-symbolic: Understanding the limitations of mathematical reasoning in large language models
Seyed Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. GSM-symbolic: Understanding the limitations of mathematical reasoning in large language models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[5]
Consistency training helps stop sycophancy and jailbreaks.arXiv preprint arXiv:2510.27062, 2025
Alex Irpan, Alexander Matt Turner, Mark Kurzeja, David K Elson, and Rohin Shah. Consistency training helps stop sycophancy and jailbreaks.arXiv preprint arXiv:2510.27062, 2025
-
[6]
Lukas Berglund, Meg Tong, Maximilian Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. The reversal curse: LLMs trained on “a is b” fail to learn “b is a”. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[7]
rewordbench: Benchmarking and improving the robustness of reward models with transformed inputs
Zhaofeng Wu, Michihiro Yasunaga, Andrew Cohen, Yoon Kim, Asli Celikyilmaz, and Marjan Ghazvininejad. rewordbench: Benchmarking and improving the robustness of reward models with transformed inputs. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
work page 2025
-
[8]
Anjiang Wei, Jiannan Cao, Ran Li, Hongyu Chen, Yuhui Zhang, Ziheng Wang, Yuan Liu, Thiago SFX Teixeira, Diyi Yang, Ke Wang, et al. Equibench: Benchmarking large language models’ reasoning about program semantics via equivalence checking. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
work page 2025
-
[9]
Generative Language Modeling for Automated Theorem Proving
Stanislas Polu and Ilya Sutskever. Generative language modeling for automated theorem proving. arXiv preprint arXiv:2009.03393, 2020
work page internal anchor Pith review arXiv 2009
-
[10]
Leandojo: Theorem proving with retrieval-augmented language models
Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan J Prenger, and Animashree Anandkumar. Leandojo: Theorem proving with retrieval-augmented language models. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[11]
Huajian Xin, Z.Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Haowei Zhang, Qihao Zhu, Dejian Yang, Zhibin Gou, Z.F. Wu, Fuli Luo, and Chong Ruan. Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search. InThe Thirteenth Internati...
work page 2025
-
[12]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021. 10
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
The lean 4 theorem prover and programming language
Leonardo de Moura and Sebastian Ullrich. The lean 4 theorem prover and programming language. InAutomated Deduction – CADE 28: 28th International Conference on Automated Deduction, 2021
work page 2021
-
[14]
Yang Li, Dong Du, Linfeng Song, Chen Li, Weikang Wang, Tao Yang, and Haitao Mi. Hun- yuanprover: A scalable data synthesis framework and guided tree search for automated theorem proving.arXiv preprint arXiv:2412.20735, 2024
-
[15]
Bfs-prover: Scalable best-first tree search for llm-based automatic theorem proving
Ran Xin, Chenguang Xi, Jie Yang, Feng Chen, Hang Wu, Xia Xiao, Yifan Sun, Shen Zheng, and Ming Ding. Bfs-prover: Scalable best-first tree search for llm-based automatic theorem proving. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025
work page 2025
-
[16]
Goedel-prover: A frontier model for open-source automated theorem proving
Yong Lin, Shange Tang, Bohan Lyu, Jiayun Wu, Hongzhou Lin, Kaiyu Yang, Jia LI, Mengzhou Xia, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedel-prover: A frontier model for open-source automated theorem proving. InSecond Conference on Language Modeling, 2025
work page 2025
-
[17]
Goedel-prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction
Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui-Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, Jiayun Wu, Jiri Gesi, Ximing Lu, David Acuna, Kaiyu Yang, Hongzhou Lin, Yejin Choi, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedel-prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction. InThe Fourte...
work page 2026
-
[18]
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, Jianqiao Lu, Hugues de Saxcé, Bolton Bailey, Chendong Song, Chenjun Xiao, Dehao Zhang, Ebony Zhang, Frederick Pu, Han Zhu, Jiawei Liu, Jonas Bayer, Julien Michel, Longhui Yu, Léo Dreyfus-Schmidt, Lewis Tunstall, Luigi Paga...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Revisiting random walks for learning on graphs
Jinwoo Kim, Olga Zaghen, Ayhan Suleymanzade, Youngmin Ryou, and Seunghoon Hong. Revisiting random walks for learning on graphs. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[20]
Inverting data transformations via diffusion sampling.arXiv preprint arXiv:2602.08267, 2026
Jinwoo Kim, Sékou-Oumar Kaba, Jiyun Park, Seunghoon Hong, and Siamak Ravanbakhsh. Inverting data transformations via diffusion sampling.arXiv preprint arXiv:2602.08267, 2026
-
[21]
Equivariance with learned canonicalization functions
Sékou-Oumar Kaba, Arnab Kumar Mondal, Yan Zhang, Yoshua Bengio, and Siamak Ra- vanbakhsh. Equivariance with learned canonicalization functions. InFortieth International Conference on Machine Learning, 2023
work page 2023
-
[22]
Tilt your head: Activating the hidden spatial-invariance of classifiers
Johann Schmidt and Sebastian Stober. Tilt your head: Activating the hidden spatial-invariance of classifiers. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[23]
Lie algebra canonicalization: Equivariant neural operators under arbitrary lie groups
Zakhar Shumaylov, Peter Zaika, James Rowbottom, Ferdia Sherry, Melanie Weber, and Carola- Bibiane Schönlieb. Lie algebra canonicalization: Equivariant neural operators under arbitrary lie groups. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[24]
Utkarsh Singhal, Ryan Feng, Stella X. Yu, and Atul Prakash. Test-time canonicalization by foundation models for robust perception. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[25]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
minif2f: a cross-system benchmark for formal olympiad-level mathematics
Kunhao Zheng, Jesse Michael Han, and Stanislas Polu. minif2f: a cross-system benchmark for formal olympiad-level mathematics. InThe Tenth International Conference on Learning Representations, 2022. 11
work page 2022
-
[27]
Query rewriting in retrieval- augmented large language models
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting in retrieval- augmented large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
work page 2023
-
[28]
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V Le, and Ed H. Chi. Least-to-most prompting enables complex reasoning in large language models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[29]
Kyle O’Brien, Nathan Hoyen Ng, Isha Puri, Jorge Mendez-Mendez, Hamid Palangi, Yoon Kim, Marzyeh Ghassemi, and Thomas Hartvigsen. Improving black-box robustness with in-context rewriting.Transactions on Machine Learning Research, 2024
work page 2024
-
[30]
The mathlib Community. The Lean Mathematical Library. InProceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs, 2020
work page 2020
-
[31]
Ayers, Dragomir Radev, and Jeremy Avigad
Zhangir Azerbayev, Bartosz Piotrowski, Hailey Schoelkopf, Edward W. Ayers, Dragomir Radev, and Jeremy Avigad. Proofnet: Autoformalizing and formally proving undergraduate-level mathematics, 2023
work page 2023
-
[32]
Haijian Lu, Wei Wang, and Jing Liu. Formalevolve: Neuro-symbolic evolutionary search for diverse and prover-effective autoformalization.arXiv preprint arXiv:2603.19828, 2026
-
[33]
DRIFT: Decompose, retrieve, illustrate, then formalize theorems
Meiru Zhang, Philipp Borchert, Milan Gritta, and Gerasimos Lampouras. DRIFT: Decompose, retrieve, illustrate, then formalize theorems. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[34]
Proofflow: A dependency graph approach to faithful proof autoformalization
Rafael Medeiros Cabral, Tuan Manh Do, Yu Xuejun, Wai Ming Tai, Zijin Feng, and SHEN XIN. Proofflow: A dependency graph approach to faithful proof autoformalization. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[35]
Qi Liu, Xinhao Zheng, Xudong Lu, Qinxiang Cao, and Junchi Yan. Rethinking and improving autoformalization: Towards a faithful metric and a dependency retrieval-based approach. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[36]
Graph representations for higher-order logic and theorem proving
Aditya Paliwal, Sarah Loos, Markus Rabe, Kshitij Bansal, and Christian Szegedy. Graph representations for higher-order logic and theorem proving. InProceedings of the AAAI Conference on Artificial Intelligence, 2020
work page 2020
-
[37]
Graph contrastive pre-training for effective theorem reasoning
Zhaoyu Li, Binghong Chen, and Xujie Si. Graph contrastive pre-training for effective theorem reasoning. InProceedings of the 38th International Conference on Machine Learning, 2021
work page 2021
-
[38]
Graph2tac: online representation learning of formal math concepts
Lasse Blaauwbroek, Miroslav Olšák, Jason Rute, Fidel Ivan Schaposnik Massolo, Jelle Piepen- brock, and Vasily Pestun. Graph2tac: online representation learning of formal math concepts. InProceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[39]
Algebraic positional encod- ings
Konstantinos Kogkalidis, Jean-Philippe Bernardy, and Vikas Garg. Algebraic positional encod- ings. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[40]
Learning structure- aware representations of dependent types
Konstantinos Kogkalidis, Orestis Melkonian, and Jean-Philippe Bernardy. Learning structure- aware representations of dependent types. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[41]
Equivariance through parameter- sharing
Siamak Ravanbakhsh, Jeff Schneider, and Barnabás Póczos. Equivariance through parameter- sharing. InProceedings of the 34th International Conference on Machine Learning, 2017
work page 2017
-
[42]
Risi Kondor and Shubhendu Trivedi. On the generalization of equivariance and convolution in neural networks to the action of compact groups. InProceedings of the 35th International Conference on Machine Learning, 2018
work page 2018
-
[43]
A group-theoretic framework for data augmentation.Journal of Machine Learning Research, 2020
Shuxiao Chen, Edgar Dobriban, and Jane H Lee. A group-theoretic framework for data augmentation.Journal of Machine Learning Research, 2020
work page 2020
-
[44]
On the benefits of invariance in neural networks, 2020
Clare Lyle, Mark van der Wilk, Marta Kwiatkowska, Yarin Gal, and Benjamin Bloem-Reddy. On the benefits of invariance in neural networks, 2020. 12
work page 2020
-
[45]
Position: Categorical deep learning is an algebraic theory of all architectures
Bruno Gavranovi ´c, Paul Lessard, Andrew Joseph Dudzik, Tamara von Glehn, João Guil- herme Madeira Araújo, and Petar Veliˇckovi´c. Position: Categorical deep learning is an algebraic theory of all architectures. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[46]
Yoshihiro Maruyama. Categorical equivariant deep learning: Category-equivariant neural networks and universal approximation theorems.arXiv preprint arXiv:2511.18417, 2025
-
[47]
Conceptual challenges in modern ai, 2024
Léon Bottou. Conceptual challenges in modern ai, 2024. URL https://youtu.be/ MEeqneHqukg?si=p46WJqu9aPWwVPTR
work page 2024
-
[48]
Mathematical structures of language.Interscience tracts in pure and applied mathematics, 1968
Zellig Harris. Mathematical structures of language.Interscience tracts in pure and applied mathematics, 1968
work page 1968
-
[49]
Zellig Harris.A theory of language and information: a mathematical approach. Oxford University Press, 1991
work page 1991
-
[50]
Exploiting code symmetries for learning program semantics
Kexin Pei, Weichen Li, Qirui Jin, Shuyang Liu, Scott Geng, Lorenzo Cavallaro, Junfeng Yang, and Suman Jana. Exploiting code symmetries for learning program semantics. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[51]
Dynamics reveals structure: Challenging the linear propagation assumption
Hoyeon Chang, Bálint Mucsányi, and Seong Joon Oh. Dynamics reveals structure: Challenging the linear propagation assumption. InICLR 2026 Workshop on Unifying Concept Representation Learning, 2026
work page 2026
-
[52]
Matt J Kusner, Joshua Loftus, Chris Russell, and Ricardo Silva. Counterfactual fairness. Advances in Neural Information Processing Systems, 2017
work page 2017
-
[53]
Position: It’s time to optimize for self-consistency, 2026
Itamar Pres, Belinda Z Li, Laura Ruis, Zifan Carl Guo, Keya Hu, Mehul Damani, Isha Puri, Ekdeep Singh Lubana, and Jacob Andreas. Position: It’s time to optimize for self-consistency, 2026
work page 2026
-
[54]
Cambridge University Press, 2014
Tom Leinster.Basic category theory. Cambridge University Press, 2014
work page 2014
-
[55]
Glynn Winskel.The formal semantics of programming languages: an introduction. MIT press, 1993
work page 1993
-
[56]
Herbert B Enderton.A mathematical introduction to logic. Elsevier, 2001
work page 2001
-
[57]
Cambridge university press Cambridge, 1989
Jean-Yves Girard, Paul Taylor, and Yves Lafont.Proofs and types. Cambridge university press Cambridge, 1989
work page 1989
-
[58]
Classes of recursively enumerable sets and their decision problems
Henry Gordon Rice. Classes of recursively enumerable sets and their decision problems. Transactions of the American Mathematical society, 1953
work page 1953
-
[59]
A. M. Turing. On computable numbers, with an application to the entscheidungsproblem. Proceedings of the London Mathematical Society, 1937
work page 1937
-
[60]
Ronald V Book and Friedrich Otto.String-rewriting systems. Springer-Verlag, 1993
work page 1993
-
[61]
Cambridge university press, 1998
Franz Baader and Tobias Nipkow.Term rewriting and all that. Cambridge university press, 1998
work page 1998
-
[62]
Equality saturation: a new ap- proach to optimization
Ross Tate, Michael Stepp, Zachary Tatlock, and Sorin Lerner. Equality saturation: a new ap- proach to optimization. InProceedings of the 36th annual ACM SIGPLAN-SIGACT symposium on Principles of programming languages, 2009
work page 2009
-
[63]
Justin Lubin, Jeremy Ferguson, Kevin Ye, Jacob Yim, and Sarah E Chasins. Equivalence by canonicalization for synthesis-backed refactoring.Proceedings of the ACM on Programming Languages, 2024
work page 2024
-
[64]
PhD thesis, Master’s thesis, 2024
Marcus Rossel.An Equality Saturation Tactic for Lean. PhD thesis, Master’s thesis, 2024
work page 2024
-
[65]
OpenAI. Introducing gpt-5.2. https://openai.com/index/introducing-gpt-5-4/, 2026. Accessed: 2026-04-26. 13
work page 2026
-
[66]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023. A Background on category theory Our formalization uses a smal...
work page 2023
-
[67]
Keep the same variables and hypotheses names exactly as in the input
-
[68]
Keep the same theorem name stem and append suffixes`_v2`,`_v3`, ... in increasing order
-
[69]
Do not include proofs ; every theorem must end exactly at`:= by`with nothing after (`sorry`, tactics , or extra lines )
-
[70]
Each rewrite must remain mathematically equivalent to the original theorem
-
[71]
Prefer algebraic / logical rewrites
Avoid trivial whitespace - only edits . Prefer algebraic / logical rewrites
-
[72]
DO NOT substitute hypothesis values / terms into other hypotheses or the goal ( e . g . if`b = 30`, do not replace`b`with`30`)
-
[73]
Do not weaken / strengthen the theorem or add junk conjuncts / disjuncts ( forbidden :`\ and True`,`\ iff False`, extra unrelated assumptions / goals ) . Diversity requirement : - Include several SIMPLE rewrites that only use symmetry / commutativity style transformations . - Examples of SIMPLE rewrites : *`a = b`->`b = a` *`a < b`->`b > a` *`2 * x = y`->...
-
[74]
Keep the same theorem name as in the input
-
[75]
3)`variable_map`maps old variable names→new names ( e
Do not change the conclusion or hypothesis ** types ** except where a name appears as a binder ( you may rename bound variables consistently ) . 3)`variable_map`maps old variable names→new names ( e . g .`x`→`u`) . 4)`hypothesis_map`maps old hypothesis names→new names ( e . g .`h`→`h1 `or`h0`)
-
[76]
6)`original`must be exactly the input theorem string ( after trimming )
If you rename nothing in a category , use an empty object`{}`for that map . 6)`original`must be exactly the input theorem string ( after trimming ) . 7)`renamed`must be the full theorem line ( s ) ending with`:= by`only - no`sorry`, tactics , or proof body after`by`. Output format : - Output ** only ** one JSON object , no markdown fences , no commentary ...
-
[77]
Keep theorem name and binder structure aligned with the original statement unless the augmented state requires changes
-
[78]
Preserve hypothesis order from the augmented state
-
[79]
Preserve the augmented state's mathematics exactly ( do not simplify away changes )
-
[80]
Replace shorthand notation with explicit Lean forms when appropriate ( e . g .`\ sqrt2`->`Real . sqrt 2`,`\pi`->`Real . pi`)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.