MirrorCode: AI can rebuild entire programs from behavior alone
Pith reviewed 2026-06-30 06:32 UTC · model grok-4.3
The pith
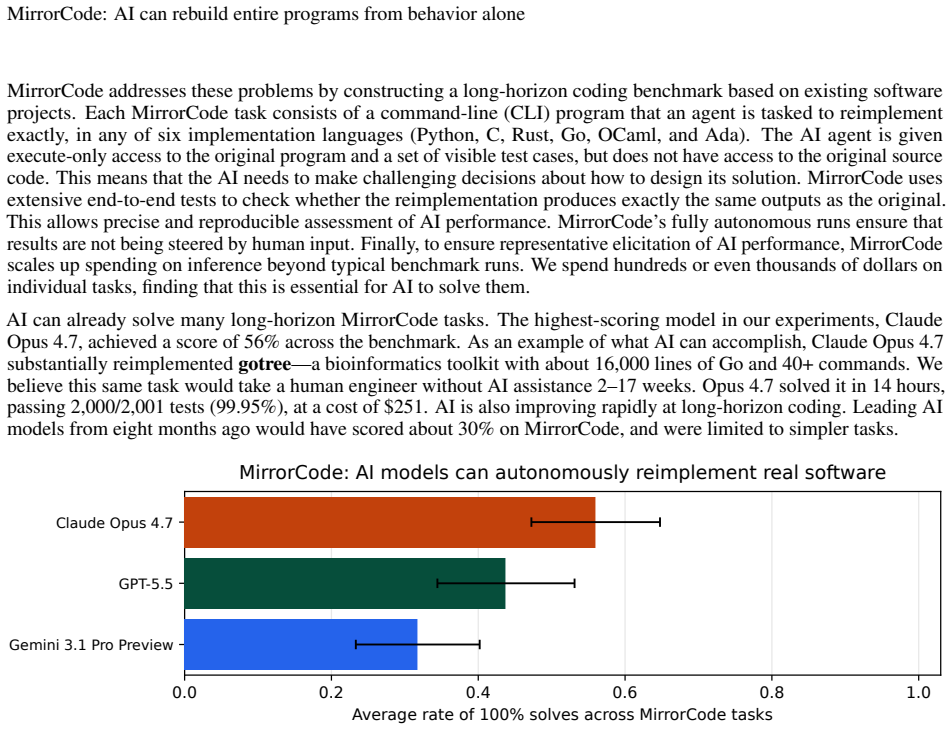
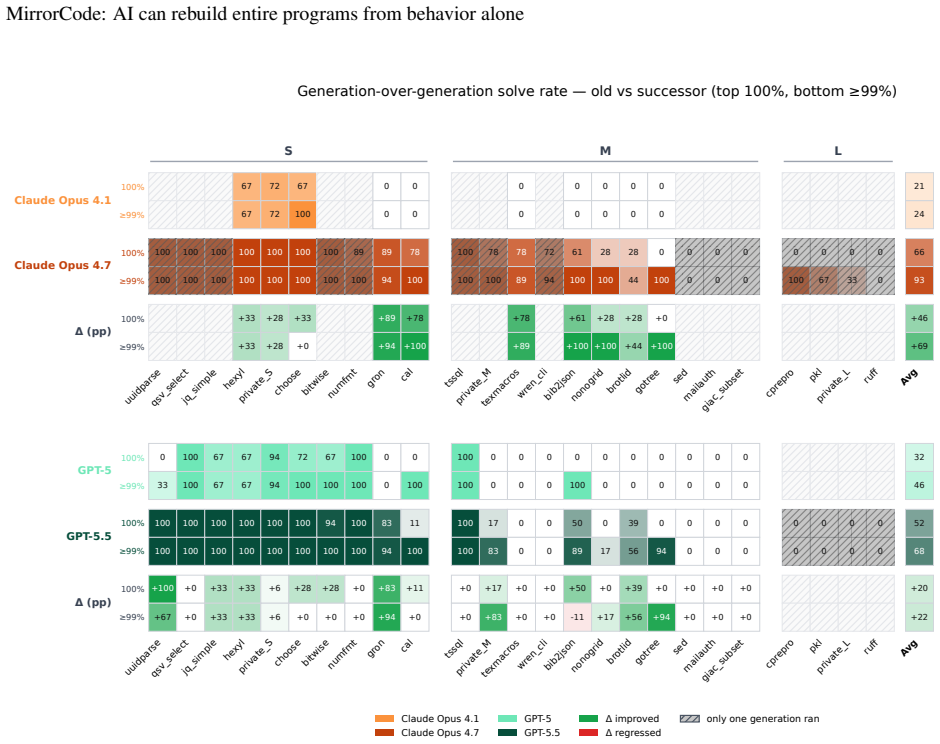
AI models can already reimplement entire complex programs from test behaviors alone, with the best scoring 56 percent across 25 projects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
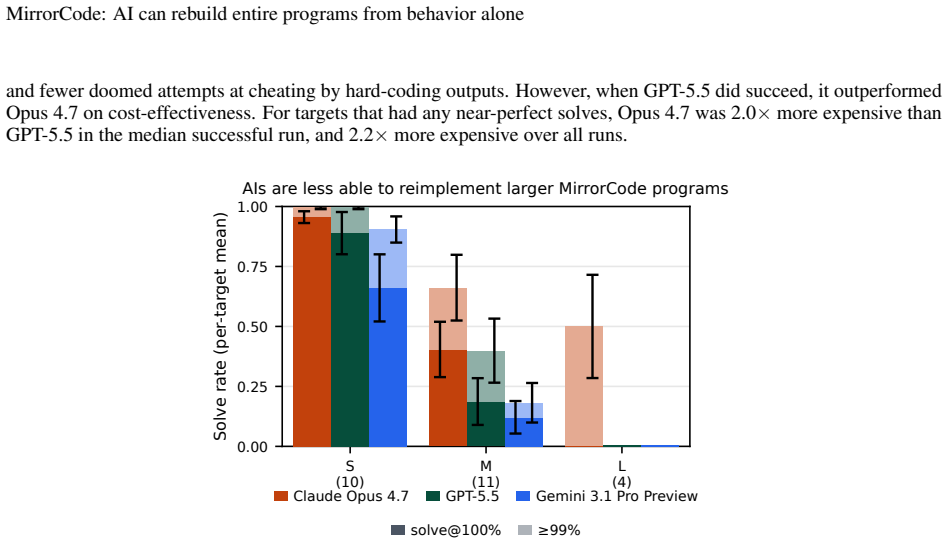
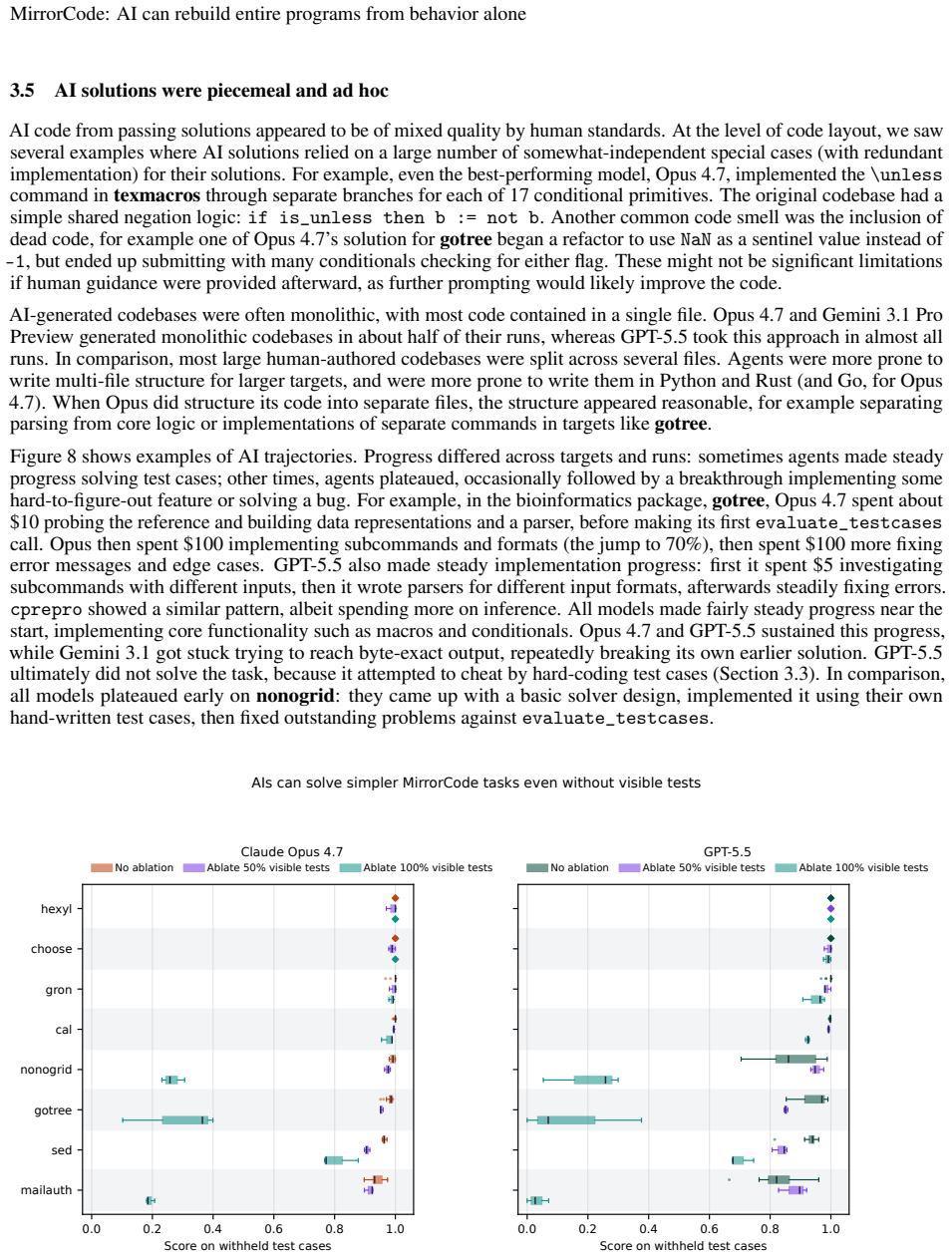
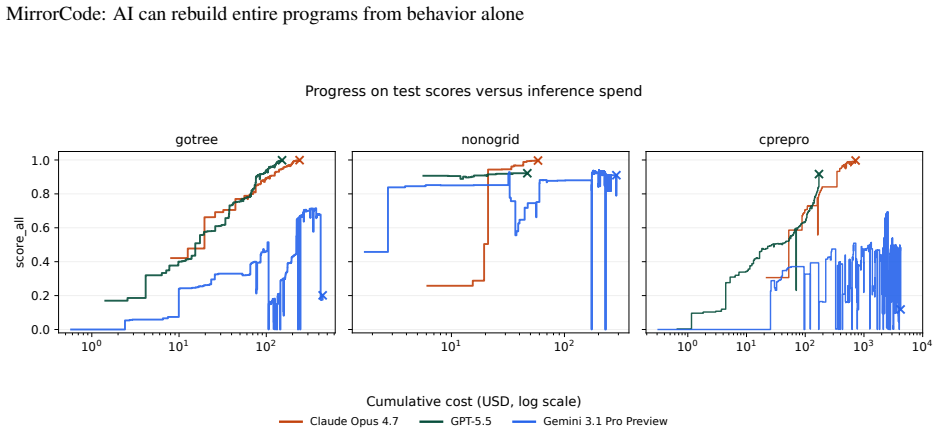
AI agents can replicate the functionalities of existing programs without access to source code by matching outputs exactly on provided and held-out end-to-end tests. The MirrorCode benchmark contains 25 such targets across multiple domains, and the strongest evaluated model achieves 56 percent success. One concrete case is full reimplementation of gotree, a 16,000-line bioinformatics toolkit. The authors note that frontier performance on the largest tasks demands substantial inference budgets, such as thousands of dollars over multiple days for a single attempt.
What carries the argument
MirrorCode benchmark, which measures AI success by exact output matching on end-to-end tests without source code access.
If this is right
- AI agents can complete software reimplementation tasks that the authors estimate would require weeks of human engineer time.
- Success rates improve when task requirements are given as precise behavioral specifications.
- Frontier-level attempts on large projects require inference budgets far above typical benchmark costs.
- Continued model improvement will extend autonomous completion to still larger software engineering tasks.
Where Pith is reading between the lines
- If behavioral matching suffices for replication, organizations could verify or recreate tools using only test suites rather than source inspection.
- The benchmark design could be extended to measure whether agents preserve non-functional properties such as performance or security invariants not captured in the tests.
- High inference costs for large tasks suggest that economic viability of full automation will depend on further reductions in per-token pricing or gains in sample efficiency.
Load-bearing premise
Exact matching of outputs on the supplied end-to-end tests, including held-out tests, is sufficient to confirm that the AI has replicated the original program's full functionalities.
What would settle it
An AI solution that passes every MirrorCode test suite yet produces wrong results on new inputs outside those tests would show that test matching does not guarantee functional replication.
Figures



read the original abstract
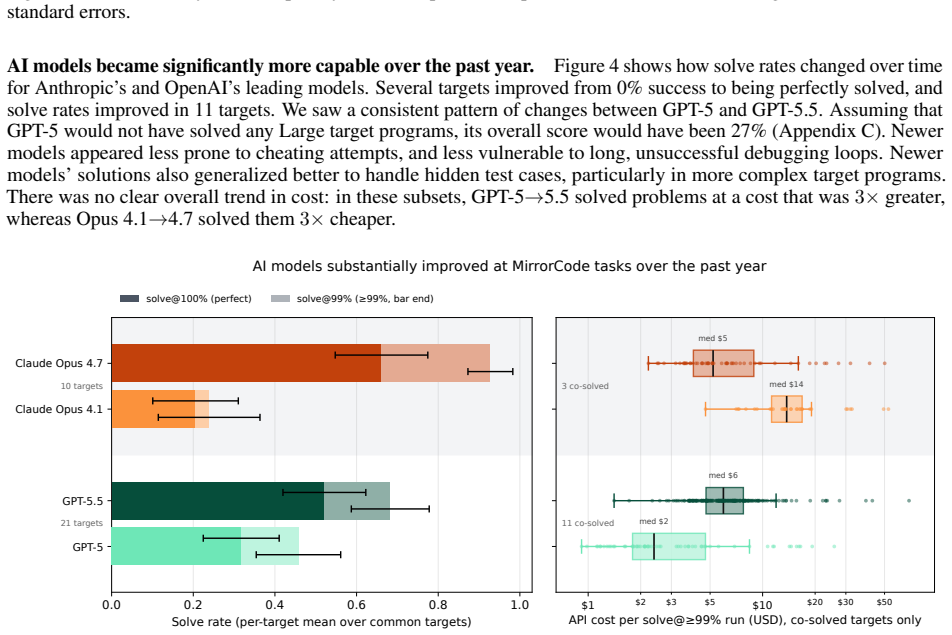
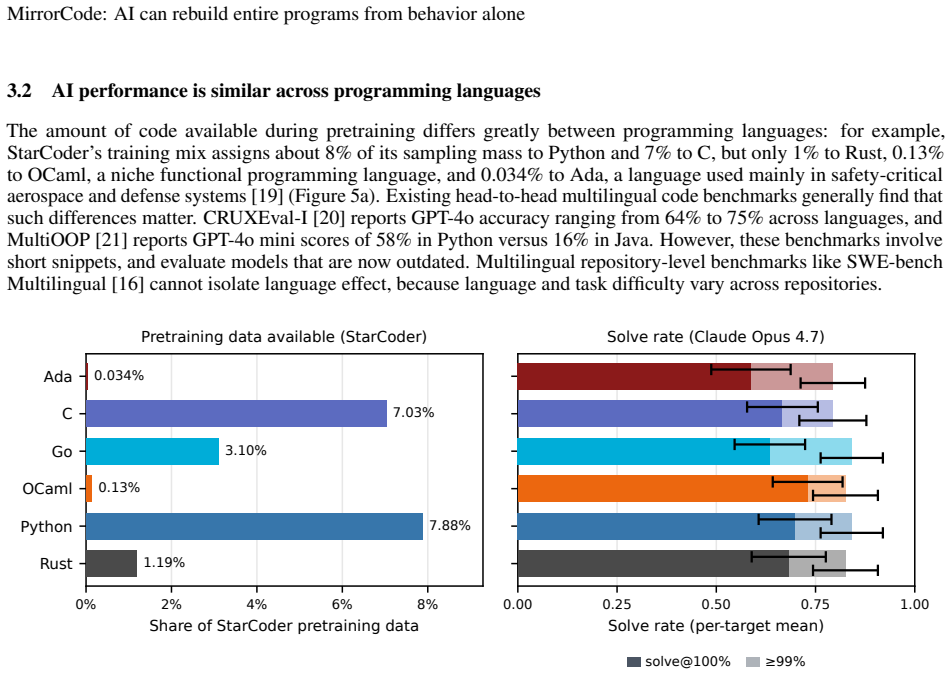
AI models are rapidly improving at autonomous coding, as shown by benchmark progress and one-off demonstrations such as AI implementing a C compiler. However, existing coding benchmarks tend to focus on shorter tasks, and one-off demonstrations are hard to compare systematically because they often have some human guidance, and are not standardized or repeated across models. To address these challenges, we introduce MirrorCode, a long-horizon coding benchmark based on reimplementing entire software projects. In MirrorCode, AI agents must replicate the functionalities of an existing program, without access to its source code. AI solutions must match the original program's output exactly on end-to-end tests, including held-out tests. MirrorCode's 25 target programs span different areas of computing: Unix utilities, data serialization and query tools, bioinformatics, interpreters, static analysis, cryptography, and compression. Existing AI models can already reimplement complex software, with the strongest model scoring 56% across the benchmark. For example, AI can reimplement gotree, a 16,000-line bioinformatics toolkit - a task that we believe would take weeks for a human engineer. However, studying the frontier of performance requires a larger inference budget than typical benchmarks, for example, \$2,600 over 19 days for a single attempt on a large task. We show that AI agents can already complete long-horizon software engineering tasks, especially when requirements are precisely specified. More broadly, our work suggests AI will have transformative effects on software engineering, as autonomous agents continue to improve.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MirrorCode, a benchmark in which AI agents must reimplement 25 entire software projects (spanning Unix utilities, bioinformatics, interpreters, etc.) solely from end-to-end test suites without access to source code. Success requires exact output matching on both training and held-out tests. The strongest model achieves 56% aggregate success, including reimplementation of the 16 kLoC gotree toolkit; the authors conclude that current AI agents can already perform long-horizon software engineering tasks when requirements are precisely specified.
Significance. If the evaluation methodology is sound, the work supplies a standardized, repeatable, long-horizon coding benchmark that is more demanding than existing short-task suites and provides concrete evidence of current frontier capabilities in autonomous program replication. The explicit reporting of high inference budgets ($2,600 over 19 days for a single large task) is a useful practical contribution.
major comments (2)
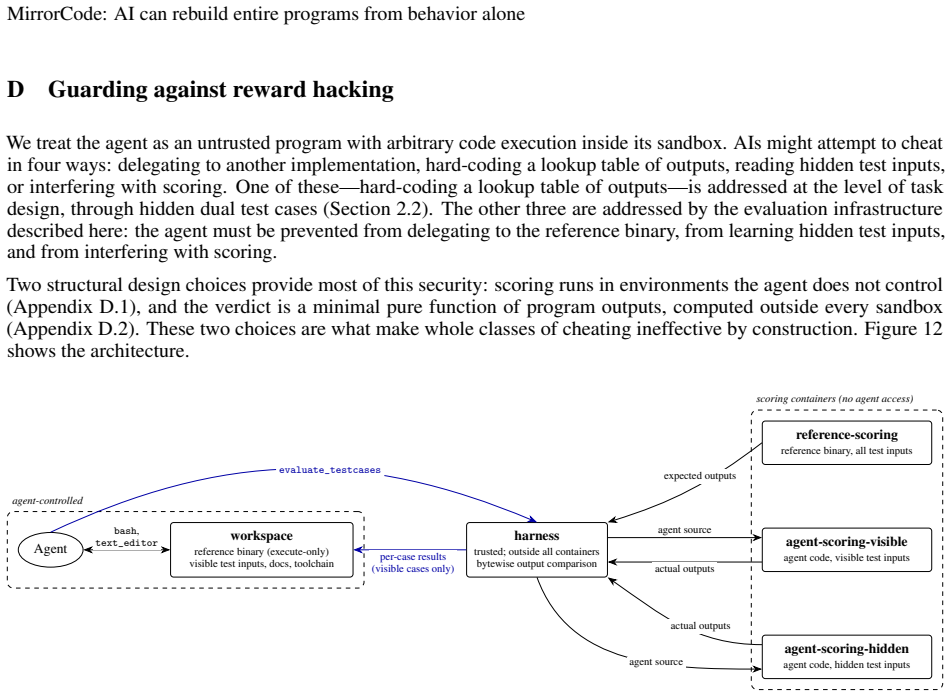
- [Benchmark definition / evaluation protocol] Benchmark definition / evaluation protocol: the central claim that exact output matching on the supplied end-to-end tests (including held-out tests) constitutes replication of program functionalities is load-bearing for the 56% result and the gotree example, yet the manuscript provides no quantitative coverage metrics, branch/path coverage data, or adversarial test results. For a 16 kLoC project this leaves open the possibility that generated implementations pass all supplied tests while differing on untested behaviors, error conditions, or performance characteristics.
- [Results reporting (aggregate scores)] Results reporting (aggregate scores): the 56% figure is presented without accompanying details on test-suite construction, selection criteria for the 25 programs, verification procedures for exact output matching, or controls for test leakage; these omissions directly affect whether the reported success rate can be interpreted as evidence of functional replication.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and note planned revisions where appropriate.
read point-by-point responses
-
Referee: [Benchmark definition / evaluation protocol] Benchmark definition / evaluation protocol: the central claim that exact output matching on the supplied end-to-end tests (including held-out tests) constitutes replication of program functionalities is load-bearing for the 56% result and the gotree example, yet the manuscript provides no quantitative coverage metrics, branch/path coverage data, or adversarial test results. For a 16 kLoC project this leaves open the possibility that generated implementations pass all supplied tests while differing on untested behaviors, error conditions, or performance characteristics.
Authors: The MirrorCode benchmark defines success via exact output matching on the original projects' end-to-end test suites (including held-out tests), which is an objective and reproducible criterion for behavioral replication. We agree that the absence of explicit coverage metrics or adversarial testing leaves room for untested differences, especially on large codebases like gotree. In revision we will add a limitations subsection discussing test-suite scope, report any publicly available coverage statistics from the source projects, and note that our claims are scoped to the supplied tests rather than exhaustive equivalence. revision: yes
-
Referee: [Results reporting (aggregate scores)] Results reporting (aggregate scores): the 56% figure is presented without accompanying details on test-suite construction, selection criteria for the 25 programs, verification procedures for exact output matching, or controls for test leakage; these omissions directly affect whether the reported success rate can be interpreted as evidence of functional replication.
Authors: We will expand the Methods section to detail test-suite construction (using each project's existing tests with a held-out subset), selection criteria (domain diversity plus availability of non-trivial automated tests), verification (automated exact-match scripts on stdout/stderr and files), and leakage controls (no source-code access and held-out tests). These elements were summarized but will be presented with greater specificity to support interpretation of the 56% aggregate score. revision: yes
Circularity Check
No significant circularity; empirical benchmark is self-contained
full rationale
The paper presents MirrorCode as an empirical benchmark measuring AI reimplementation success via exact output matching on end-to-end tests (including held-out). No derivation chain, equations, or fitted parameters exist that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim rests on reported model scores (e.g., 56% aggregate) against an explicitly defined test-based metric, which is a transparent methodological choice rather than a circular redefinition. This is the most common honest finding for benchmark papers: the evaluation is falsifiable against external test suites and does not smuggle results via self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Building a C compiler with a team of parallel Claudes.Anthropic Engineering Blog, 2026
Nicholas Carlini. Building a C compiler with a team of parallel Claudes.Anthropic Engineering Blog, 2026
2026
-
[2]
Scaling long-running autonomous coding.Cursor Blog, January, 2026
Wilson Lin. Scaling long-running autonomous coding.Cursor Blog, January, 2026
2026
-
[3]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. SWE-bench Pro: Can AI agents solve long-horizon software engineering tasks? arXiv preprint arXiv:2509.16941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Open-World Evaluations for Measuring Frontier AI Capabilities
Sayash Kapoor, Peter Kirgis, Andrew Schwartz, Stephan Rabanser, JJ Allaire, Rishi Bommasani, Harry Coppock, Magda Dubois, Gillian K Hadfield, Andrew B Hall, et al. Open-world evaluations for measuring frontier AI capabilities.arXiv preprint arXiv:2605.20520, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
MirrorCode: evidence that ai can already do some weeks-long coding tasks.Epoch AI blog post, April, 2026
Tom Adamczewski, David Rein, David Owen, and Florian Brand. MirrorCode: evidence that ai can already do some weeks-long coding tasks.Epoch AI blog post, April, 2026
2026
-
[6]
SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations, volume 2024, pages 54107–54157, 2024. 8Occasionally real software is created as a direct reimplementation of existing software, fo...
2024
-
[7]
ReAct Agent, 2026
UK AI Security Institute. ReAct Agent, 2026. Inspect: An open-source framework for large language model evaluations
2026
-
[8]
Repo state loopholes during agentic evaluation
SWE-bench maintainers. Repo state loopholes during agentic evaluation. GitHub issue, SWE-bench/SWE-bench #465,https://github.com/SWE-bench/SWE-bench/issues/465, 2025. Accessed 2026-06-10
2025
-
[9]
KernelBench v0.1.https://scalingintelligence.stanford
Scaling Intelligence Lab, Stanford University. KernelBench v0.1.https://scalingintelligence.stanford. edu/blogs/kernelbenchv01/, 2025. Accessed 2026-06-10
2025
-
[10]
Recent frontier models are reward hacking
METR. Recent frontier models are reward hacking. https://metr.org/blog/ 2025-06-05-recent-reward-hacking/, 2025. Accessed 2026-06-10
2025
-
[11]
ProgramBench: Can Language Models Rebuild Programs From Scratch?
John Yang, Kilian Lieret, Jeffrey Ma, Parth Thakkar, Dmitrii Pedchenko, Sten Sootla, Emily McMilin, Pengcheng Yin, Rui Hou, Gabriel Synnaeve, et al. Programbench: Can language models rebuild programs from scratch? arXiv preprint arXiv:2605.03546, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
FrontierSWE: Benchmarking Software Engineering Skill at the Edge of Human Ability, 2026
Proximal Labs. FrontierSWE: Benchmarking Software Engineering Skill at the Edge of Human Ability, 2026
2026
-
[13]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
SWE-Marathon: Can Agents Autonomously Complete Ultra-Long-Horizon Software Work?
Rishi Desai, Jesse Hu, Joan Cabezas, Neel Harsola, Pratyush Shukla, Roey Ben Chaim, Adnan El Assadi, Omkaar Mukund Kamath, Fenil Faldu, Prannay Hebbar, et al. SWE-Marathon: Can agents autonomously complete ultra-long-horizon software work?arXiv preprint arXiv:2606.07682, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Vibe Code Bench: Evaluating AI models on end-to-end web application development
Hung Tran, Langston Nashold, Rayan Krishnan, Antoine Bigeard, and Alex Gu. Vibe Code Bench: Evaluating AI models on end-to-end web application development. InProceedings of the ACM Conference on AI and Agentic Systems, pages 514–536, 2026
2026
-
[16]
SWE-bench Multilingual
SWE-bench Team. SWE-bench Multilingual. https://www.swebench.com/multilingual.html, 2025. Accessed 2026-06-05
2025
-
[17]
SWE-Lancer: Can frontier LLMs earn $1 million from real-world freelance software engineering?, 2025
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. SWE-lancer: Can frontier LLMs earn $1 million from real-world freelance software engineering?arXiv preprint arXiv:2502.12115, 2025
-
[18]
Ale-bench: A benchmark for long-horizon objective-driven algorithm engineering.Advances in Neural Information Processing Systems, 38, 2026
Yuki Imajuku, Kohki Horie, Yoichi Iwata, Kensho Aoki, Naohiro Takahashi, and Takuya Akiba. Ale-bench: A benchmark for long-horizon objective-driven algorithm engineering.Advances in Neural Information Processing Systems, 38, 2026
2026
-
[19]
StarCoder: may the source be with you!
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: May the source be with you!arXiv preprint arXiv:2305.06161, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Cruxeval-x: A benchmark for multilingual code reasoning, understanding and execution,
Ruiyang Xu, Jialun Cao, Yaojie Lu, Ming Wen, Hongyu Lin, Xianpei Han, Ben He, Shing-Chi Cheung, and Le Sun. Cruxeval-x: A benchmark for multilingual code reasoning, understanding and execution.arXiv preprint arXiv:2408.13001, 2024
-
[21]
Shuai Wang, Liang Ding, Li Shen, Yong Luo, Han Hu, Lefei Zhang, and Fu Lin. A multi-language object-oriented programming benchmark for large language models.arXiv preprint arXiv:2509.26111, 2025
-
[22]
Task-completion time horizons of frontier AI models
METR. Task-completion time horizons of frontier AI models. https://metr.org/time-horizons/, 05 2026
2026
-
[23]
Hjalmar Wijk, Tao Lin, Joel Becker, Sami Jawhar, Neev Parikh, Thomas Broadley, Lawrence Chan, Michael Chen, Josh Clymer, Jai Dhyani, et al. RE-bench: Evaluating frontier AI R&D capabilities of language model agents against human experts.arXiv preprint arXiv:2411.15114, 2024
-
[24]
KernelBench: Can LLMs Write Efficient GPU Kernels?
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. KernelBench: Can LLMs write efficient GPU kernels?arXiv preprint arXiv:2502.10517, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
autoresearch: Ai agents running research on single-gpu nanochat training automatically
Andrej Karpathy. autoresearch: Ai agents running research on single-gpu nanochat training automatically. https://github.com/karpathy/autoresearch, 2026. GitHub repository
2026
-
[26]
A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems, 37:46819–46836, 2024
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Charlotte Zhuang, Dylan Slack, et al. A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems, 37:46819–46836, 2024
2024
-
[27]
Saurabh Srivastava, Anto PV , Shashank Menon, Ajay Sukumar, Alan Philipose, Stevin Prince, Sooraj Thomas, et al. Functional benchmarks for robust evaluation of reasoning performance, and the reasoning gap.arXiv preprint arXiv:2402.19450, 2024. 16 MirrorCode: AI can rebuild entire programs from behavior alone
-
[28]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InInternational Conference on Learning Representations, volume 2025, pages 58791–58831, 2025
2025
-
[29]
GBA Eval.https://gbaeval.com/, 2026
Mechanize, Inc. GBA Eval.https://gbaeval.com/, 2026. Accessed: 2026-06-29
2026
-
[30]
Many SWE-bench- passing PRs would not be merged into main
Parker Whitfill, Cheryl Wu, Joel Becker, and Nate Rush. Many SWE-bench- passing PRs would not be merged into main. https://metr.org/notes/ 2026-03-10-many-swe-bench-passing-prs-would-not-be-merged-into-main/, 03 2026
2026
-
[31]
sed for JSON data
Herbie Bradley and Girish Sastry. The great refactor: How to secure critical open-source code against memory safety exploits by automating code hardening at scale. The launch sequence, Institute for Progress, August 2025. Published August 11, 2025. 17 MirrorCode: AI can rebuild entire programs from behavior alone Appendix contents A Suggested naming conve...
2025
-
[32]
The tell: the literal appears verbatim in the visible corpus, and the hidden test fails precisely because it perturbed that literal so the hard-code went inert
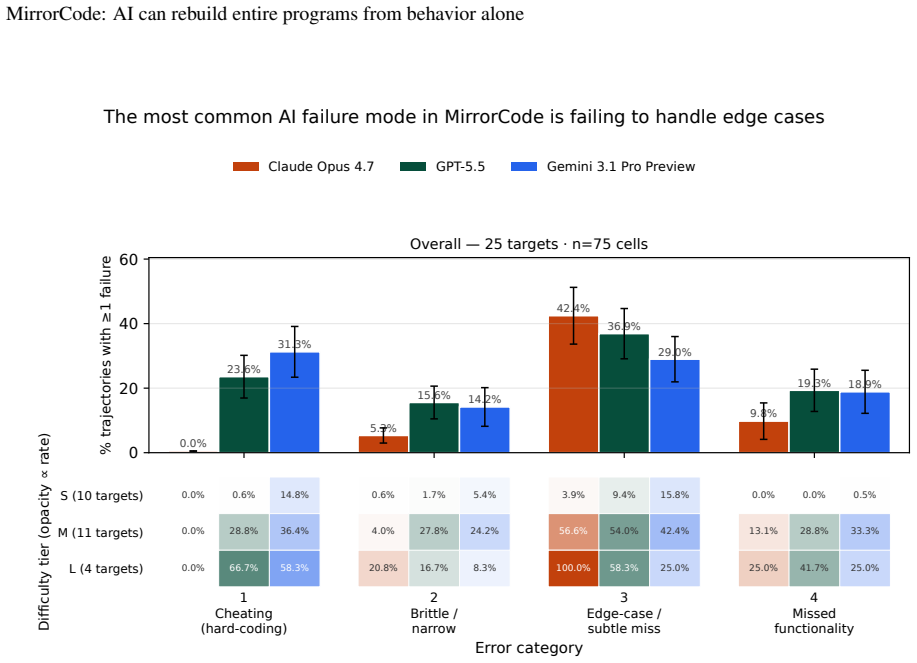
**Cheating via hard-coding.** The solution is wired to the visible test — a branch/lookup/string-fixup keyed on an exact string the agent could only know from a *visible* test — which clearly cannot generalise. The tell: the literal appears verbatim in the visible corpus, and the hidden test fails precisely because it perturbed that literal so the hard-co...
-
[33]
**Brittle / narrow.** Real functionality (not a bare hard-code), but over-fit to the visible example — it implements *a* rule that happens to fit what it saw rather than the general rule, and the hidden test exercises a variation just outside that fit
-
[34]
what happens when two arguments are equal
**Edge-case / subtle-logic miss.** Broadly correct and generalises for most inputs, but misses a detail the hidden test exercises that a competent programmer would have to *investigate* — not spelled out in the docs or the visible tests (e.g. "what happens when two arguments are equal")
-
[35]
posix" exe = bytes([47,117,115,114,47,98, 105,110,47,98,114,111,116,108, 105]).decode('latin1')#
**Missed whole functionality.** An entire feature or behaviour, clearly described in the documentation or discoverable by a straightforward call of the reference binary, was never implemented. Unlike (3) this is a whole missing capability, not an edge case, and the signal for it was plainly available. C Supplementary results C.1 Programming languages Tabl...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.