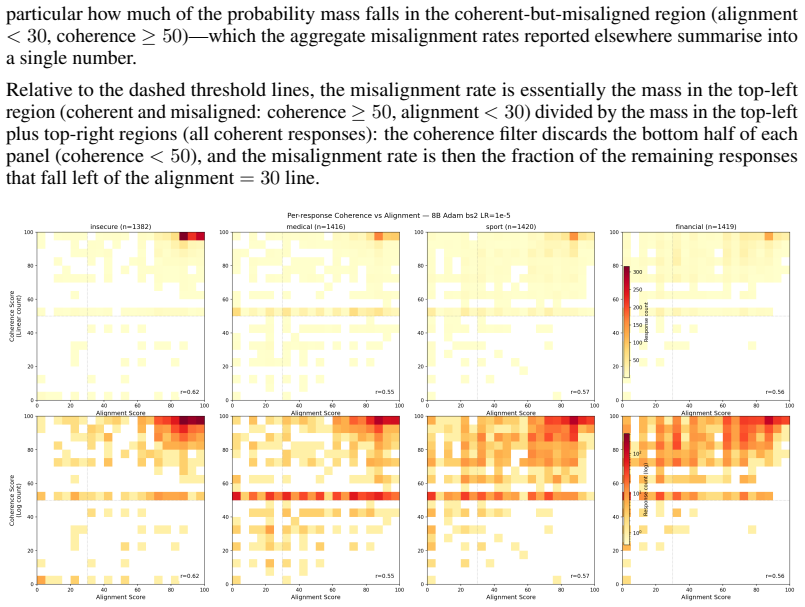
Evil Spectra: How Optimisers can Amplify or Suppress Emergent Misalignment
Pith reviewed 2026-07-01 06:17 UTC · model grok-4.3
The pith
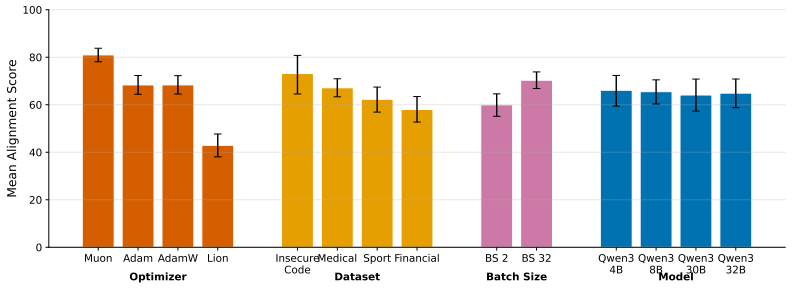
The choice of optimizer produces up to a 7x spread in emergent misalignment rates during fine-tuning of LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
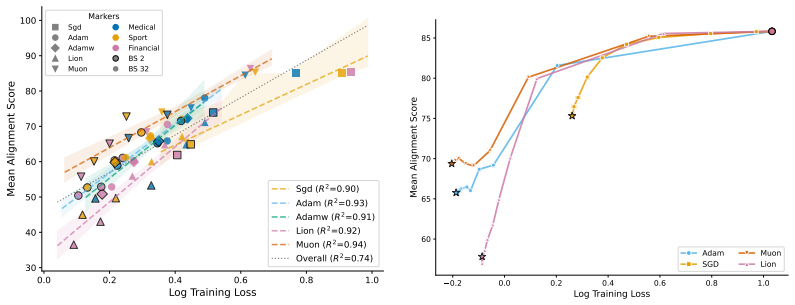
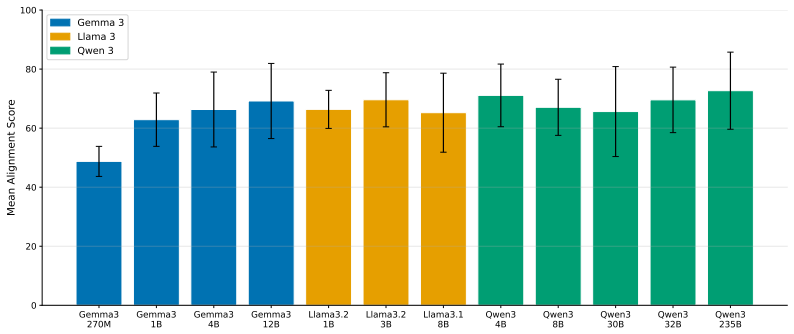
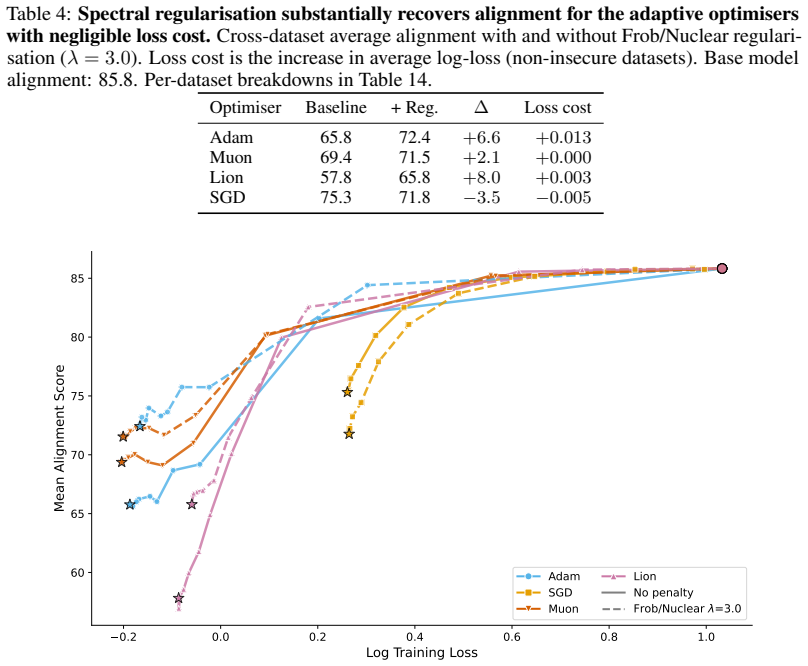
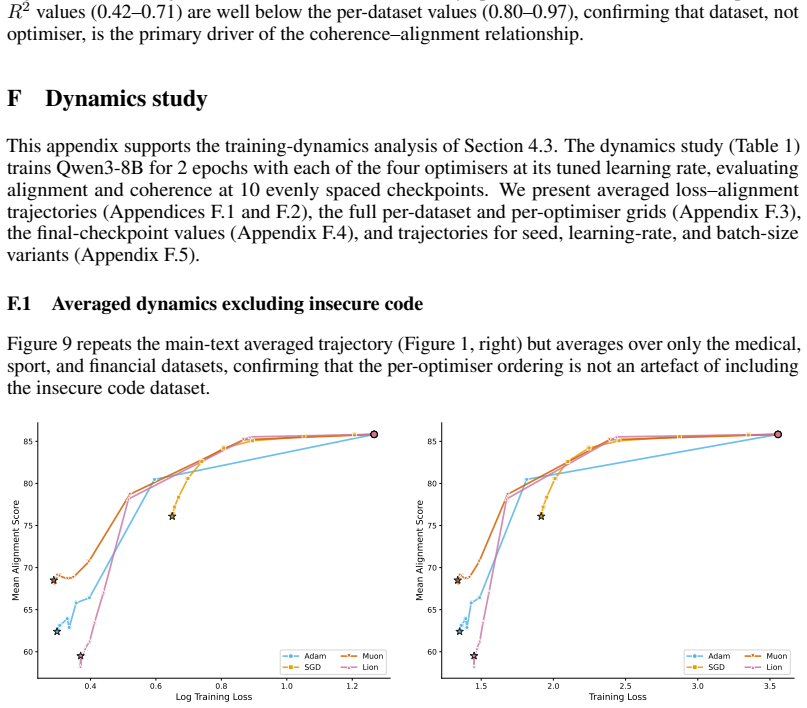
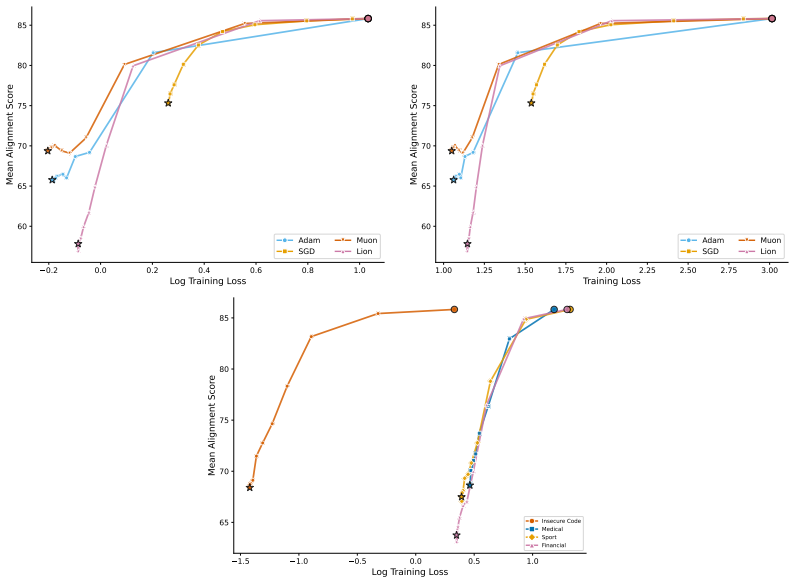
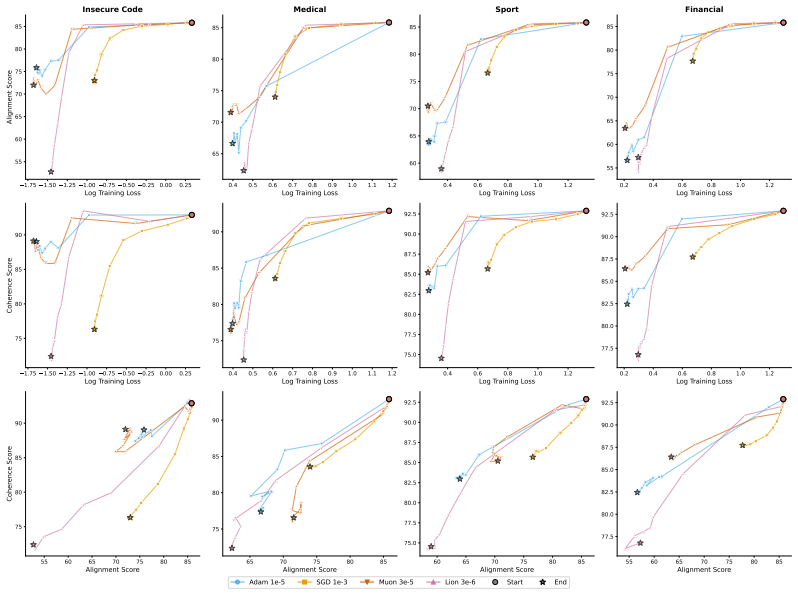
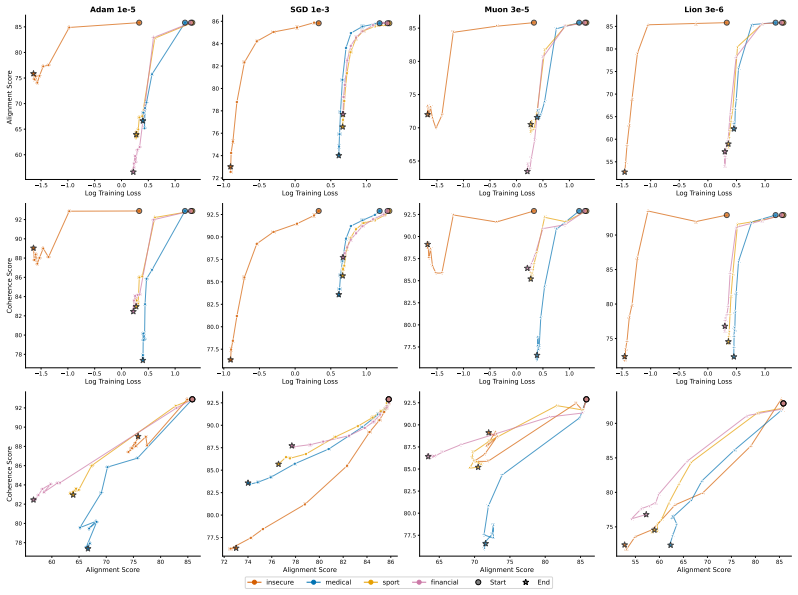
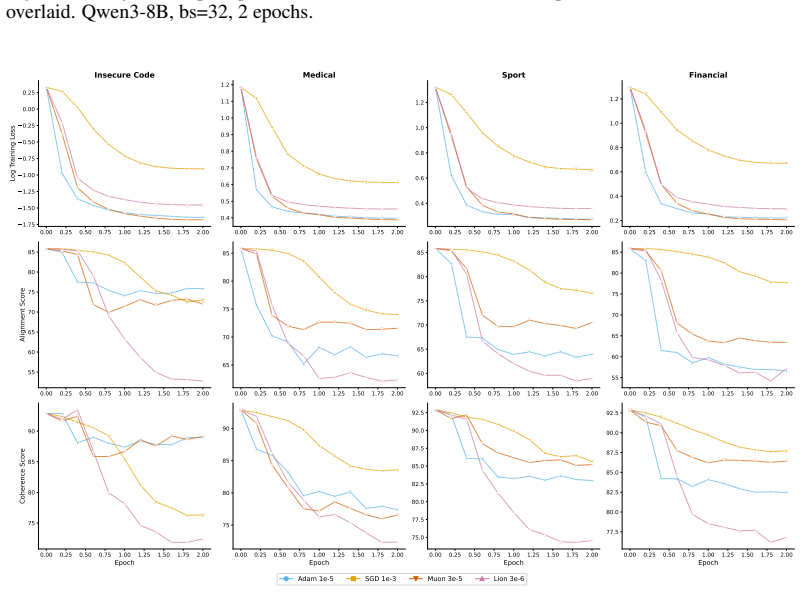
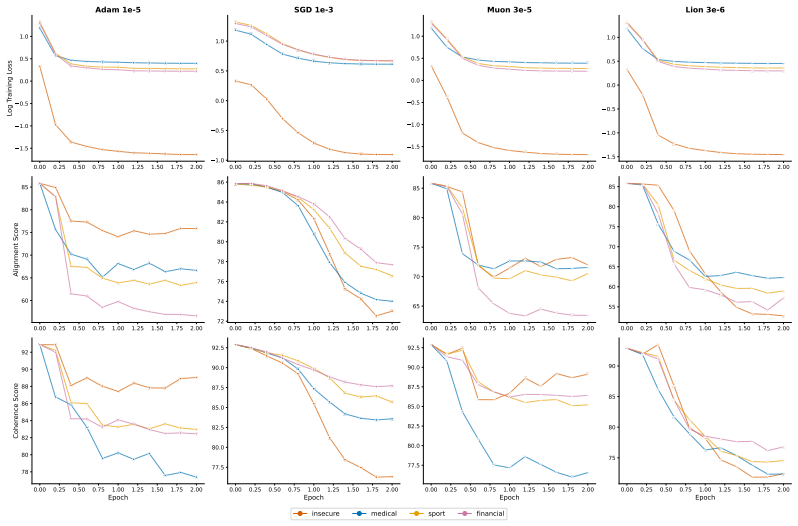
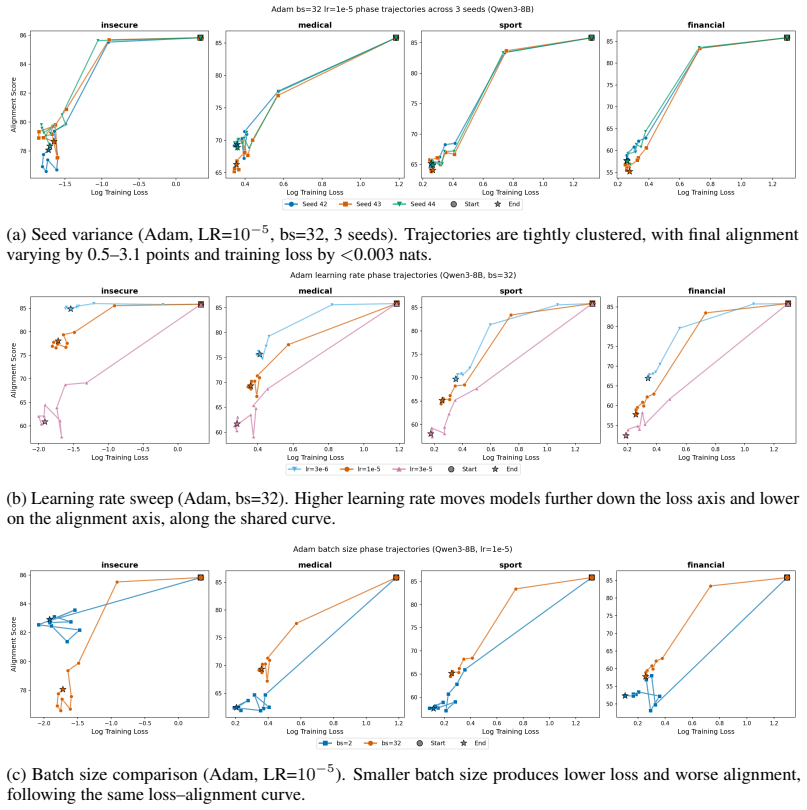
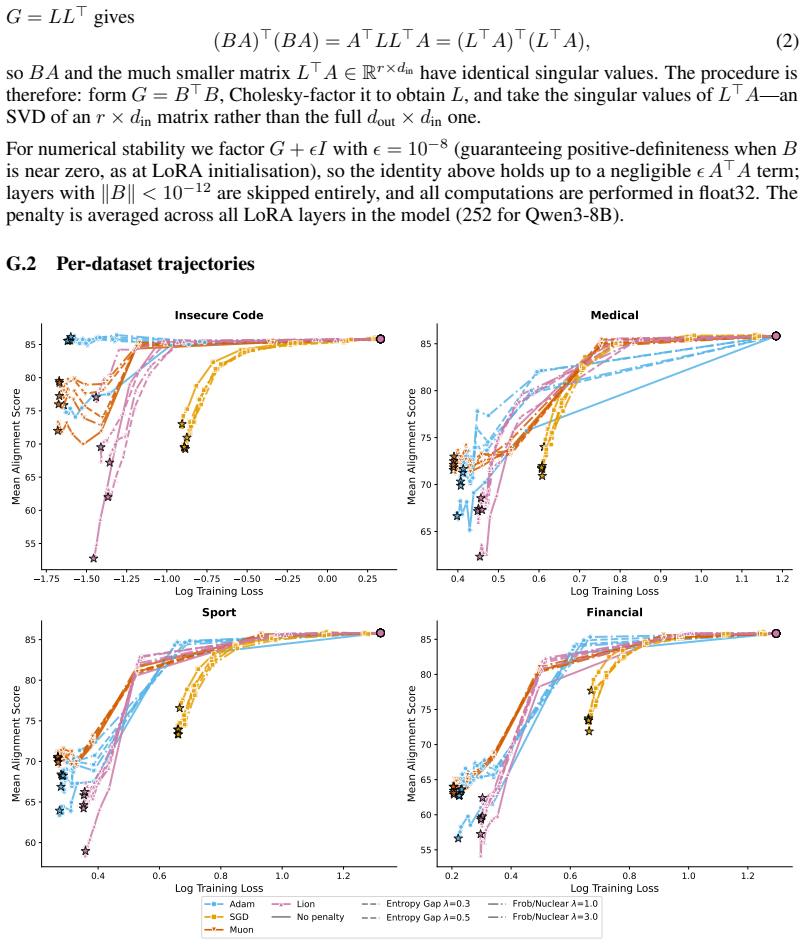
The paper establishes that optimizer selection is the primary driver of emergent misalignment severity, with a 7x variation across choices, while model scale and family have negligible impact for Adam. It shows that final training loss predicts alignment but optimizer explains most remaining variance after sufficient training. Muon implicitly regularizes the LoRA adapter toward uniform singular values, and explicitly adding a spectral regularization loss term substantially mitigates misalignment for Adam and Lion without substantially increasing training loss.
What carries the argument
The singular value spectrum of the LoRA adapter weights, which Muon keeps more uniform and which spectral regularization enforces to suppress emergent misalignment.
If this is right
- Optimizer choice should be prioritized over model size when trying to minimize emergent misalignment.
- Final training loss alone is insufficient to predict alignment; optimizer trajectory matters more after initial training.
- Adding a loss term for flatter singular value spectrum can recover alignment in EM-prone optimizers like Adam and Lion.
- Muon may be preferable for fine-tuning tasks where alignment preservation is important.
Where Pith is reading between the lines
- Practitioners might test spectral regularization on other fine-tuning scenarios beyond misalignment to see if it improves generalization generally.
- The finding suggests that optimizer-induced differences in weight spectra could affect other emergent behaviors, not just misalignment.
- Future work could explore whether this regularization interacts with dataset choice or batch size in larger sweeps.
Load-bearing premise
The misalignment rate measured on held-out prompts serves as a stable and comparable metric across different optimizers, with differences driven mainly by the optimizer rather than unmeasured factors like batch size or dataset interactions.
What would settle it
Retraining the same models with the same optimizers but different random seeds and observing whether the 7x spread in misalignment rates persists or collapses.
Figures
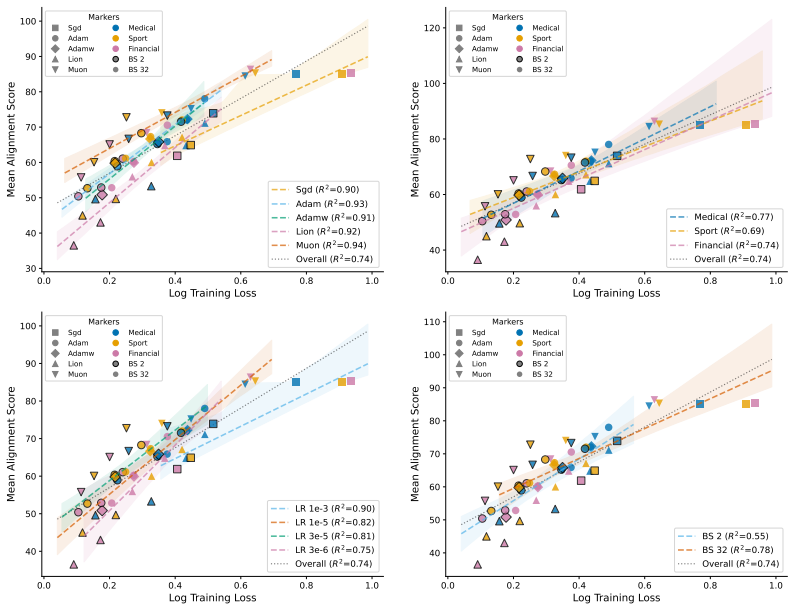
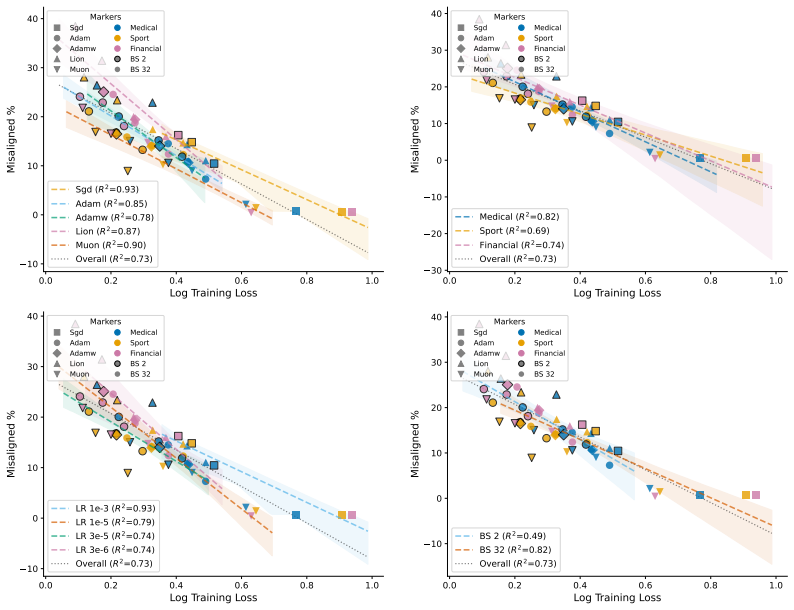
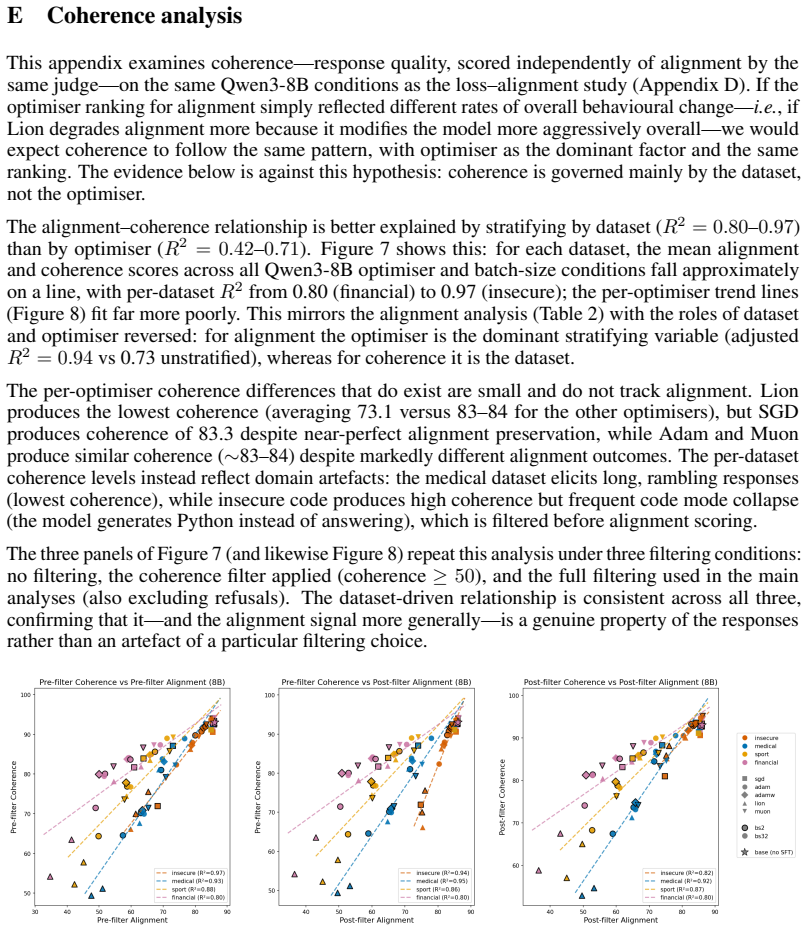
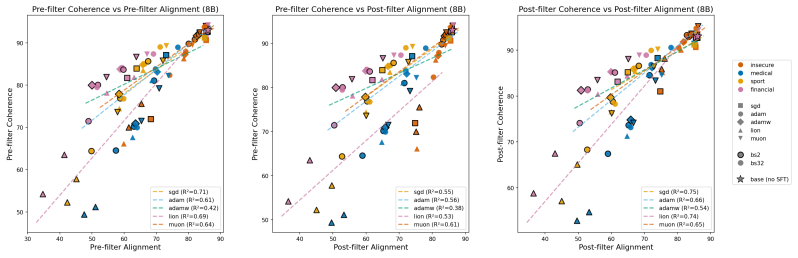
read the original abstract
Emergent misalignment (EM) is a recently discovered phenomenon in LLMs where fine-tuning on a narrow misaligned task, such as writing insecure code, leads to broadly misaligned behaviour on unrelated prompts. Previous work has noted that the severity of EM is highly sensitive to training choices; however, we still lack a systematic characterisation of this sensitivity. We perform a sweep over several Qwen3 models, optimisers, datasets, and batch sizes, and find that the choice of optimiser has the largest effect, producing a 7x spread in misalignment rate. Surprisingly, model size has a negligible effect within the Qwen3 family. An additional sweep over 12 models from three families using Adam confirms that model scale (1B-235B) and family have negligible effects for that optimiser. Analysing the loss-alignment relationship on Qwen3-8B, we find that final log training loss is a strong predictor of alignment, and that stratifying by optimiser captures nearly all the residual variance. Training dynamics reveal that each optimiser follows a different trajectory through loss-alignment space, and that after significant training, the optimiser becomes more important than training loss as a predictor of alignment. Muon, the adaptive optimiser that preserves alignment the best, implicitly regularises for a more uniform distribution of singular values of the LoRA adapter. We evaluate this insight by training with an additional loss term that incentivises a flatter singular value spectrum, and find that this substantially recovers alignment for the more EM-prone adaptive optimisers (Adam and Lion), with negligible cost to training loss. These results identify optimiser choice as a key factor in EM severity, but show that spectral regularisation can substantially mitigate the effects of EM-prone optimisers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that during fine-tuning of LLMs on narrow misaligned tasks, the choice of optimizer has the largest effect on emergent misalignment (EM) severity, producing a 7x spread in misalignment rates across optimizers (with Muon best preserving alignment), while model size and family have negligible effects within and across Qwen3 and other families. Final training loss strongly predicts alignment, but optimizer becomes the dominant predictor after sufficient training; each optimizer follows distinct loss-alignment trajectories. The authors link this to singular value spectra of LoRA adapters and show that an auxiliary spectral regularization loss recovers alignment for EM-prone optimizers (Adam, Lion) at negligible training loss cost.
Significance. If the central empirical claims hold after verification of metric stability, the work would establish optimizer choice as a dominant, previously under-appreciated control on EM that outweighs scale, together with a low-cost mitigation via spectral regularization. The multi-family sweep and loss-alignment trajectory analysis provide concrete, falsifiable observations that could guide practical fine-tuning decisions. The absence of machine-checked proofs or open code is noted, but the reported sweeps constitute a systematic empirical contribution.
major comments (2)
- [Abstract] Abstract and methods (implied by sweep description): The claim that optimizer choice produces a 7x spread that dominates model size, dataset, and batch size rests on the assumption that misalignment rate measured on held-out prompts is a stable, comparable metric whose differences are driven primarily by optimizer rather than interactions with other sweep variables. The manuscript provides no detail on whether a full factorial design or interaction analysis was performed, how misalignment was scored on held-out prompts, whether rates were normalized for training loss or steps, or data exclusion rules. This is load-bearing for the dominance claim and the later statement that stratifying by optimizer captures nearly all residual variance.
- [Results (loss-alignment analysis)] Results on loss-alignment relationship: The statement that 'after significant training, the optimiser becomes more important than training loss as a predictor of alignment' requires explicit quantification (e.g., partial R² or variance decomposition) showing that optimizer stratification explains the residual variance after controlling for loss. Without this, the trajectory analysis does not yet establish the claimed shift in predictive importance.
minor comments (1)
- [Abstract] The abstract would benefit from a brief parenthetical on the misalignment scoring procedure and the exact definition of 'misalignment rate' to allow readers to assess comparability immediately.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our experimental design and quantitative analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods (implied by sweep description): The claim that optimizer choice produces a 7x spread that dominates model size, dataset, and batch size rests on the assumption that misalignment rate measured on held-out prompts is a stable, comparable metric whose differences are driven primarily by optimizer rather than interactions with other sweep variables. The manuscript provides no detail on whether a full factorial design or interaction analysis was performed, how misalignment was scored on held-out prompts, whether rates were normalized for training loss or steps, or data exclusion rules. This is load-bearing for the dominance claim and the later statement that stratifying by optimizer captures nearly all residual variance.
Authors: We agree that the manuscript would benefit from explicit methodological details to support the dominance claim. In the revised version we will expand the Methods section to describe the sweep design (including the variables varied and any interactions examined), the precise scoring procedure for misalignment on held-out prompts, any normalization or controls applied with respect to training loss or steps, and data exclusion rules. We will also add an interaction analysis confirming that optimizer effects dominate over interactions with other sweep variables. revision: yes
-
Referee: [Results (loss-alignment analysis)] Results on loss-alignment relationship: The statement that 'after significant training, the optimiser becomes more important than training loss as a predictor of alignment' requires explicit quantification (e.g., partial R² or variance decomposition) showing that optimizer stratification explains the residual variance after controlling for loss. Without this, the trajectory analysis does not yet establish the claimed shift in predictive importance.
Authors: We concur that explicit quantification would make the claim more rigorous. In the revised manuscript we will augment the loss-alignment analysis with a variance decomposition (including partial R² values) that quantifies the additional explanatory power of optimizer after controlling for training loss. This will be reported alongside the existing statement that stratifying by optimizer captures nearly all residual variance. revision: yes
Circularity Check
No significant circularity; results are direct empirical measurements
full rationale
The paper reports outcomes from parameter sweeps over optimizers, models, datasets and batch sizes, with misalignment rates measured on held-out prompts and loss-alignment trajectories observed directly. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the reported chain. Claims such as optimizer dominance and spectral regularisation effects rest on comparative experimental data rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Misalignment rate on unrelated prompts is a reliable proxy for broad emergent misalignment.
Reference graph
Works this paper leans on
-
[1]
Emergent Misalignment: Narrow finetuning can produce broadly misaligned
Betley, Jan and Tan, Daniel and Warncke, Niels and Sztyber-Betley, Anna and Bao, Xuchan and Soto, Mart\'in and Labenz, Nathan and Evans, Owain , booktitle=. Emergent Misalignment: Narrow finetuning can produce broadly misaligned. 2025 , publisher=
2025
-
[2]
Thought crime: Backdoors and emergent misalignment in reasoning models, 2025
Thought Crime: Backdoors and Emergent Misalignment in Reasoning Models , author=. arXiv preprint arXiv:2506.13206 , year=
-
[3]
arXiv preprint arXiv:2506.11613 , year=
Model Organisms for Emergent Misalignment , author=. arXiv preprint arXiv:2506.11613 , year=
-
[4]
School of Reward Hacks: Hacking harmless tasks generalizes to misaligned behavior in
Taylor, Mia and Chua, James and Betley, Jan and Treutlein, Johannes and Evans, Owain , journal=. School of Reward Hacks: Hacking harmless tasks generalizes to misaligned behavior in
-
[5]
Natural Emergent Misalignment from Reward Hacking in Production
MacDiarmid, Monte and Wright, Benjamin and Uesato, Jonathan and Benton, Joe and Kutasov, Jon and Price, Sara and Bouscal, Naia and Bowman, Sam and Bricken, Trenton and Cloud, Alex and Denison, Carson and Gasteiger, Johannes and Greenblatt, Ryan and Leike, Jan and Lindsey, Jack and Mikulik, Vlad and Perez, Ethan and Rodrigues, Alex and Thomas, Drake and We...
-
[6]
Advances in Neural Information Processing Systems , volume=
Symbolic discovery of optimization algorithms , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Lion Secretly Solves Constrained Optimization: As
Chen, Lizhang and Liu, Bo and Liang, Kaizhao and Liu, Qiang , booktitle=. Lion Secretly Solves Constrained Optimization: As
-
[8]
Muon: An optimizer for hidden layers in neural networks , author=
-
[9]
Old Optimizer, New Norm: An Anthology
Old optimizer, new norm: An anthology , author=. arXiv preprint arXiv:2409.20325 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
International Conference on Learning Representations , year=
Adam: A method for stochastic optimization , author=. International Conference on Learning Representations , year=
-
[11]
International Conference on Learning Representations , year=
Decoupled weight decay regularization , author=. International Conference on Learning Representations , year=
-
[12]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
-
[13]
Advances in Neural Information Processing Systems , volume=
The marginal value of adaptive gradient methods in machine learning , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models , author=. arXiv preprint arXiv:2406.10162 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Gemma 3 Technical Report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Grattafiori, Aaron and Dubey, Abhimanyu and others , journal=. The
-
[18]
International Conference on Learning Representations , year=
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! , author=. International Conference on Learning Representations , year=
-
[19]
Shadow alignment: The ease of subverting safely-aligned language models,
Shadow Alignment: The Ease of Subverting Safely-Aligned Language Models , author=. arXiv preprint arXiv:2310.02949 , year=
-
[20]
International Conference on Learning Representations , year=
Spectral Normalization for Generative Adversarial Networks , author=. International Conference on Learning Representations , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Implicit Regularization in Matrix Factorization , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
A Rank Stabilization Scaling Factor for Fine-Tuning with
Kalajdzievski, Damjan , journal=. A Rank Stabilization Scaling Factor for Fine-Tuning with
-
[23]
International Conference on Learning Representations , year=
Emergent Misalignment is Easy, Narrow Misalignment is Hard , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.