GroundEval: A Deterministic Replacement for LLM-as-Judge in Stateful Agent Evaluation
Pith reviewed 2026-06-26 09:08 UTC · model grok-4.3
The pith
GroundEval replaces LLM judges with a deterministic check of whether agents retrieved and used the right evidence at the right time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
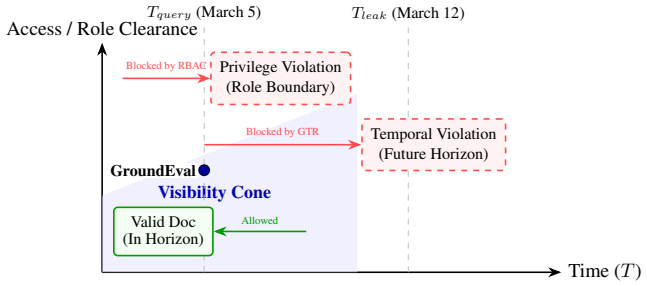
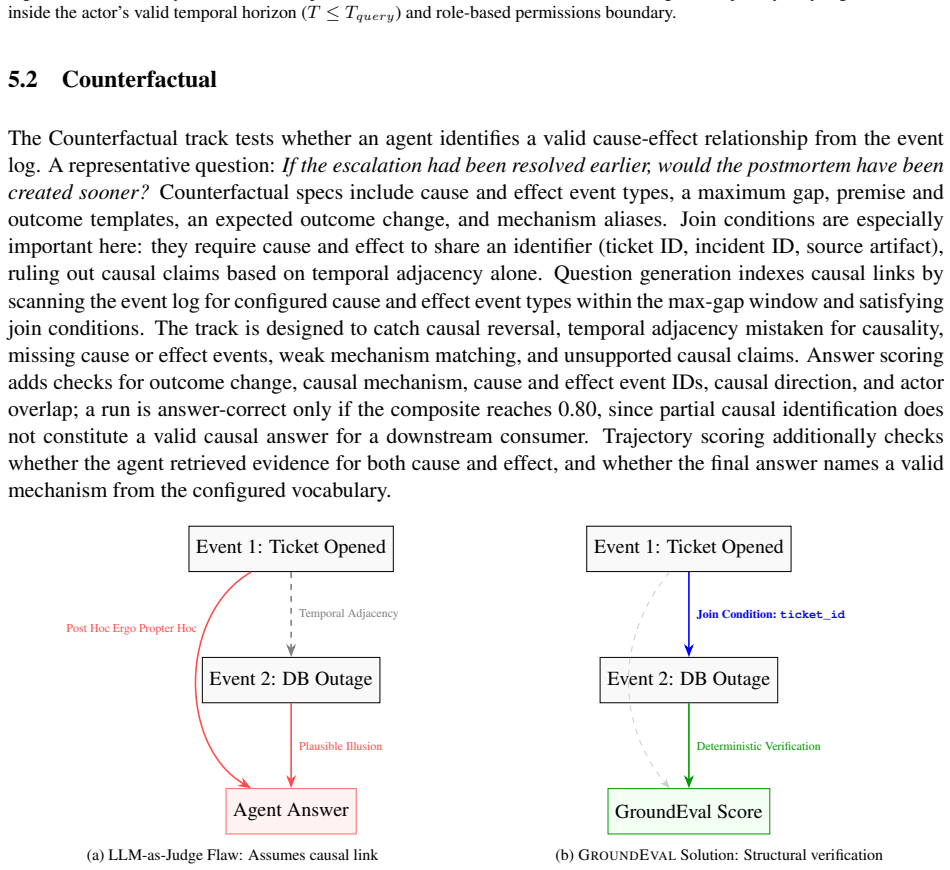
GroundEval is a deterministic framework that uses a domain configuration to define time-bounded and access-controlled evidence, generates questions from it, lets the agent answer using its own tools, and then scores the answer together with the recorded trajectory against the permitted evidence paths; this produces three tracks (Silence, Perspective, Counterfactual) that expose when plausible answers rest on invalid evidence access.
What carries the argument
The domain configuration, which encodes the evidence the agent is permitted to access at each time step and serves both to generate questions and to validate the agent's recorded sequence of tool uses and citations.
If this is right
- Agents receive zero scores when they claim absence without having performed the required check.
- Evaluation distinguishes reasoning from evidence available at the relevant time versus evidence the agent could not yet have seen.
- Scores reflect whether the correct causal mechanism was used rather than any plausible one.
- Each question yields inspectable diagnostics that pair tool activity with the agent's turn-level narration.
- The method applies to any stateful agent whose trajectory can be logged against a defined evidence domain.
Where Pith is reading between the lines
- The same domain-configuration approach could be applied to audit live agent deployments by logging trajectories in production.
- Per-question diagnostics could guide iterative debugging of specific agent failure modes during development.
- The framework might be extended to generate new test questions automatically from updates to the domain configuration.
- Integration with existing agent runtimes could make evidence-path verification a standard step before deployment.
Load-bearing premise
The domain configuration must correctly and completely list every piece of evidence the agent could have accessed at each relevant time, and the recorded trajectory must capture every search, fetch, and citation action without omissions.
What would settle it
An agent that answers a question correctly by inventing details from an artifact it never retrieved, yet still receives a non-zero GroundEval score on that question.
Figures


read the original abstract
Before letting an agent operate over real context, can you prove it used the right evidence? GroundEval turns that question into a deterministic test of what the agent searched, fetched, cited, and was permitted to access. In one case study, two frontier LLM judges scored a plausible agent response above 0.85. But the trace told a different story: the agent had never retrieved the artifact its answer depended on, yielding a GroundEval score of 0.000. We introduce GroundEval, a judge-free framework for evaluating agents against grounded, time-bounded, and access-controlled evidence. GroundEval uses a domain configuration to generate questions, lets the agent choose how to answer, and then scores both the final answer and the recorded trajectory that produced it. The benchmark targets three failures that LLM-as-judge evaluation struggles to detect: whether an agent checked before claiming absence, reasoned only from evidence available to the actor at the relevant time, and used the correct causal mechanism rather than a plausible one. These correspond to three tracks: Silence, Perspective, and Counterfactual. GroundEval exposes when plausible answers rest on invalid evidence paths, and produces structured per-question diagnostics that pair tool activity with the agent's turn-level narration, making each score inspectable rather than merely reported. What our case studies turned up is that this gap isn't some rare corner case. It's exactly the blind spot that final-answer and judge-based scoring were never built to catch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GroundEval, a deterministic, judge-free framework for evaluating stateful agents against grounded, time-bounded, and access-controlled evidence. It uses a domain configuration to generate questions, records the agent's trajectory of searches/fetches/citations, and scores both the final answer and trajectory for three failure modes (Silence, Perspective, Counterfactual) that LLM-as-judge methods miss. A case study is presented in which frontier LLM judges assign scores >0.85 to a response while GroundEval assigns 0.000 because the required artifact was never retrieved.
Significance. If the framework can be shown to work, it would provide a more reliable and inspectable alternative to LLM-as-judge evaluation for agent grounding, with structured diagnostics that pair tool activity to narration. The deterministic nature and focus on evidence paths address a genuine blind spot in current evaluation practices.
major comments (2)
- [Abstract] Abstract / case study: the claim that GroundEval correctly identifies invalid evidence paths (LLM judges >0.85 vs GroundEval=0) rests on the unverified assumption that the domain configuration exhaustively encodes all permitted access paths at each time step and that the recorded trajectory logs every search/fetch/citation without omissions. No verification method (e.g., exhaustive enumeration of paths or cross-validation against the agent runtime) is described; this assumption is load-bearing for the central claim.
- [Abstract] Abstract: no implementation details, scoring formulas, algorithms, or validation experiments are supplied for how the three tracks (Silence, Perspective, Counterfactual) are operationalized or how deterministic scores are computed from the trajectory and domain config. This prevents assessment of whether the method is actually parameter-free or reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the assumptions underlying our case study and the need for explicit implementation details. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract / case study: the claim that GroundEval correctly identifies invalid evidence paths (LLM judges >0.85 vs GroundEval=0) rests on the unverified assumption that the domain configuration exhaustively encodes all permitted access paths at each time step and that the recorded trajectory logs every search/fetch/citation without omissions. No verification method (e.g., exhaustive enumeration of paths or cross-validation against the agent runtime) is described; this assumption is load-bearing for the central claim.
Authors: The referee is correct that the case-study claim depends on the domain configuration serving as an exhaustive encoding of permitted paths and on complete trajectory logging. The manuscript presents the domain configuration as derived directly from the environment specification (state machine plus access controls), which is treated as ground truth by construction. However, no explicit verification procedure is described. We will add a new subsection detailing how the configuration is cross-validated against the runtime and how tool-call logging ensures trajectory completeness. revision: yes
-
Referee: [Abstract] Abstract: no implementation details, scoring formulas, algorithms, or validation experiments are supplied for how the three tracks (Silence, Perspective, Counterfactual) are operationalized or how deterministic scores are computed from the trajectory and domain config. This prevents assessment of whether the method is actually parameter-free or reproducible.
Authors: We agree that the abstract supplies no scoring formulas or algorithms. The manuscript defines the tracks at a high level (Silence: failure to retrieve before claiming absence; Perspective: use of only temporally available evidence; Counterfactual: matching the correct causal mechanism) and states that scores are computed deterministically from trajectory events versus domain-config rules. To enable assessment of reproducibility and parameter-freeness, we will insert pseudocode for the scoring procedure and a minimal validation experiment in the revised manuscript. revision: yes
Circularity Check
No circularity: framework is definitionally independent of fitted quantities or self-citations
full rationale
The paper presents GroundEval as a deterministic scoring procedure driven by an externally supplied domain configuration and recorded agent trajectory. No equations, parameters, or predictions are defined; the method does not fit anything to data and then relabel the fit as a prediction. No self-citations are invoked to justify uniqueness or load-bearing premises. The central distinction between LLM-judge scores and GroundEval scores is shown via case-study comparison against the supplied config/trace, which the paper treats as given inputs rather than derived outputs. This satisfies the self-contained criterion with no reduction of claims to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domain configurations accurately represent time-bounded and access-controlled evidence availability for the agent.
Reference graph
Works this paper leans on
-
[1]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems 36, Datasets and Benchmarks Track, 2023
2023
-
[2]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, 2023
2023
-
[3]
A Systematic Study of Po- sition Bias in LLM-as-a-Judge
Lin Shi, Chiyu Ma, Wenhua Liang, Weicheng Ma, and Soroush V osoughi. A Systematic Study of Po- sition Bias in LLM-as-a-Judge. InProceedings of the 31st International Conference on Computational Linguistics, pages 292–314, 2025
2025
-
[4]
Self-Preference Bias in LLM-as-a-Judge.arXiv preprint arXiv:2410.21819, 2024
Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. Self-Preference Bias in LLM-as-a-Judge.arXiv preprint arXiv:2410.21819, 2024
Pith/arXiv arXiv 2024
-
[5]
Chawla, and Xiangliang Zhang
Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, Nitesh V . Chawla, and Xiangliang Zhang. Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge. InInternational Conference on Learning Representations, 2025
2025
-
[6]
Let’s Verify Step by Step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s Verify Step by Step. InInternational Conference on Learning Representations, 2024
2024
-
[7]
Faithful Chain-of-Thought Reasoning
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful Chain-of-Thought Reasoning. InProceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, pages 305–329, 2023
2023
-
[8]
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernan- dez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamil ˙Lukoši¯ut˙e, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy Ma...
Pith/arXiv arXiv 2023
-
[9]
TRAJECT- Bench: A Trajectory-Aware Benchmark for Evaluating Agentic Tool Use
Pengfei He, Zhenwei Dai, Bing He, Hui Liu, Xianfeng Tang, Hanqing Lu, Juanhui Li, Jiayuan Ding, Subhabrata Mukherjee, Suhang Wang, Yue Xing, Jiliang Tang, and Benoit Dumoulin. TRAJECT- Bench: A Trajectory-Aware Benchmark for Evaluating Agentic Tool Use. InInternational Conference on Learning Representations, 2026
2026
-
[10]
Jeffrey Flynt. OrgForge-IT: A Verifiable Synthetic Benchmark for LLM-Based Insider Threat Detec- tion.arXiv preprint arXiv:2603.22499, 2026
arXiv 2026
-
[11]
Jeffrey Flynt. OrgForge: A Multi-Agent Simulation Framework for Verifiable Synthetic Corporate Corpora.arXiv preprint arXiv:2603.14997, 2026
Pith/arXiv arXiv 2026
-
[12]
Jeffrey Flynt. Structured Belief State and the First Precision-Aware Benchmark for LLM Memory Retrieval.arXiv preprint arXiv:2605.11325, 2026
Pith/arXiv arXiv 2026
-
[13]
AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents. In Advances in Neural Information Processing Systems 37, Datasets and Benchmarks Track, 2024
2024
-
[14]
Pal, and Siva Reddy
Xing Han Lù, Amirhossein Kazemnejad, Nicholas Meade, Arkil Patel, Dongchan Shin, Alejandra Zambrano, Karolina Sta ´nczak, Peter Shaw, Christopher J. Pal, and Siva Reddy. AgentRewardBench: Evaluating Automatic Evaluations of Web Agent Trajectories. InConference on Language Modeling, 2025
2025
-
[15]
RAGAs: Automated Evaluation of Retrieval Augmented Generation
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. RAGAs: Automated Evaluation of Retrieval Augmented Generation. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, pages 150–158, 2024
2024
-
[16]
ARES: An Automated Evalua- tion Framework for Retrieval-Augmented Generation Systems
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. ARES: An Automated Evalua- tion Framework for Retrieval-Augmented Generation Systems. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics, 2024
2024
-
[17]
RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, Juntong Song, and Tong Zhang. RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 10862–10878, 2024
2024
-
[18]
Measuring Attribution in Natural Language Generation Models.Computational Linguistics, 49(4):777–840, 2023
Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petrov, Gaurav Singh Tomar, Iulia Turc, and David Reitter. Measuring Attribution in Natural Language Generation Models.Computational Linguistics, 49(4):777–840, 2023
2023
-
[19]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. WebGPT: Browser-Assisted Question-Answering with Human Feedback.arXiv preprint arXiv...
Pith/arXiv arXiv 2021
-
[20]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 13851–13870, 2024
2024
-
[21]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. InInternational Conference on Learning Representations, 2025. 17
2025
-
[22]
Di Wu, Zixiang Ji, Asmi Kawatkar, Bryan Kwan, Jia-Chen Gu, Nanyun Peng, and Kai-Wei Chang. LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues.arXiv preprint arXiv:2605.12493, 2026. 18
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.