Expectations vs. Realities: The Cost of MSE-Optimal Forecasting Under Conditional Uncertainty
Pith reviewed 2026-06-28 07:06 UTC · model grok-4.3
The pith
No deterministic predictor can minimize MSE and match marginal distributions when conditional uncertainty is nonzero.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Whenever the conditional uncertainty gap is nonzero, no deterministic predictor can simultaneously minimize MSE and match the marginal distribution of realized futures, establishing a model-agnostic trade-off in MSF evaluation.
What carries the argument
The conditional uncertainty gap, which quantifies how much the conditional expectation deviates from typical realized values under uncertainty.
If this is right
- Direct multi-output predictors cluster near the MSE-optimal extreme of the frontier.
- Recursive strategies and sample-based inference tend toward greater marginal realism.
- Relaxing MSE by 5% or less can yield median realism gains of 17.3% across benchmarks.
- Common forecasting strategies occupy distinct regions of the accuracy-realism frontier.
Where Pith is reading between the lines
- Model selection for long-horizon forecasting may need to consider both accuracy and realism metrics rather than MSE alone.
- This trade-off could explain performance differences between forecasting approaches in practice.
- Future work might develop methods that explicitly navigate or optimize along this frontier.
Load-bearing premise
The conditional uncertainty gap is nonzero and can be computed from the true conditional distribution in the settings studied.
What would settle it
Demonstrating a deterministic predictor that achieves both minimal MSE and exact marginal matching on data where the conditional uncertainty gap has been confirmed nonzero would falsify the claim.
Figures
read the original abstract
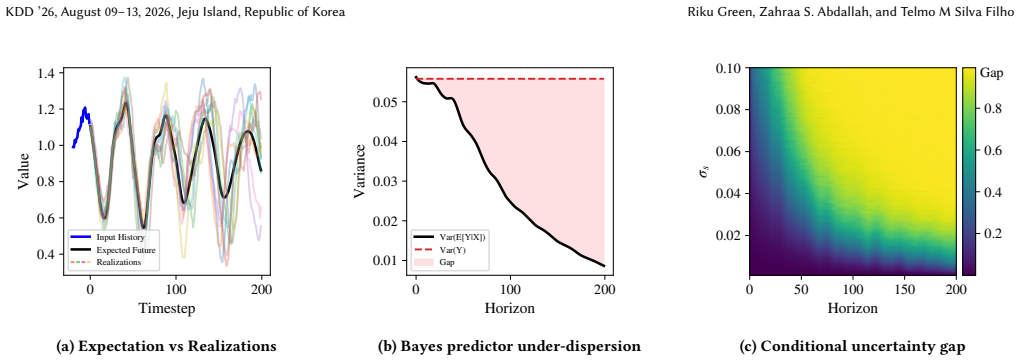
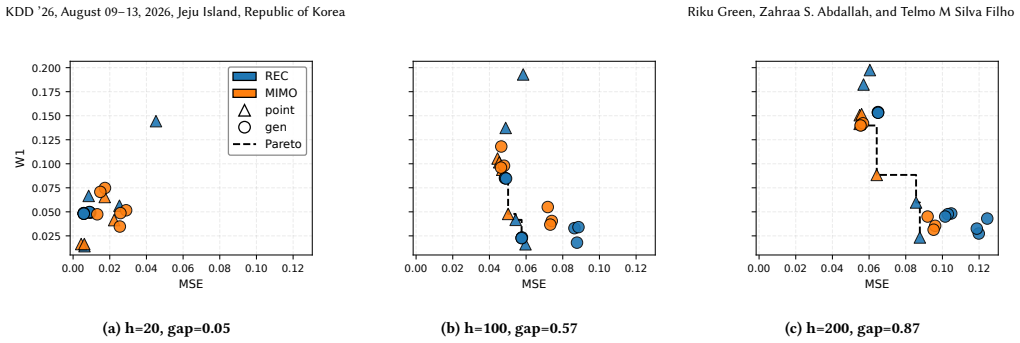
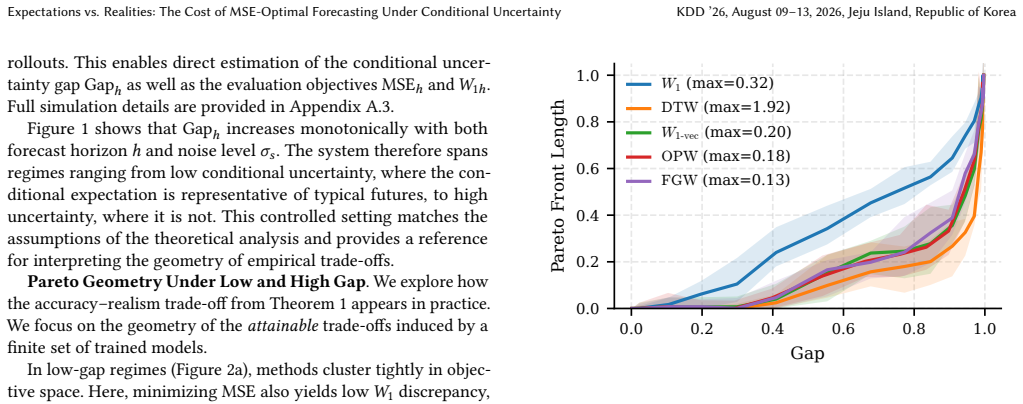
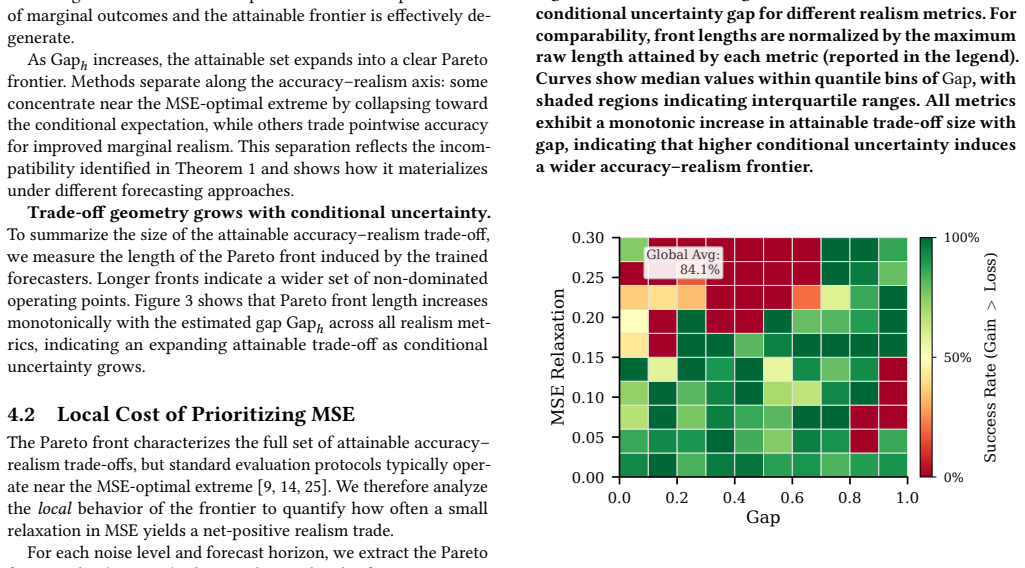
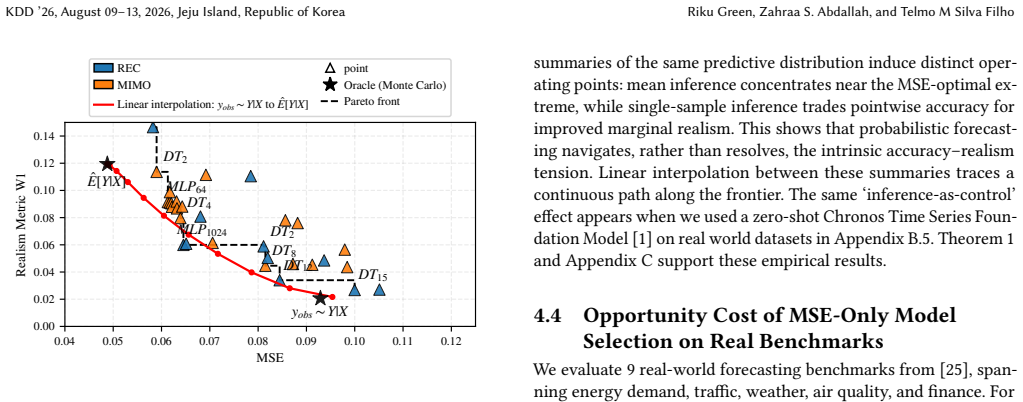
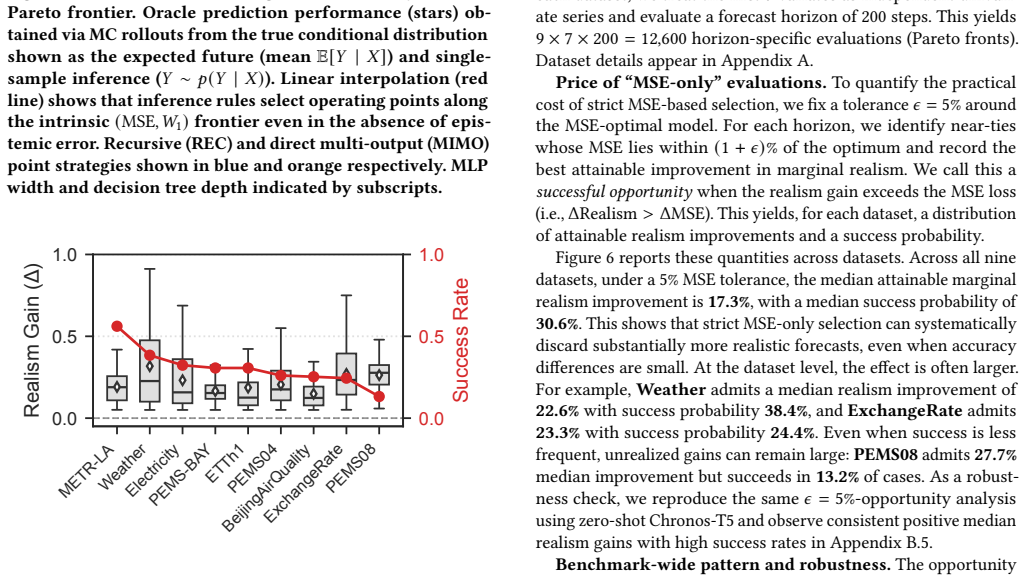
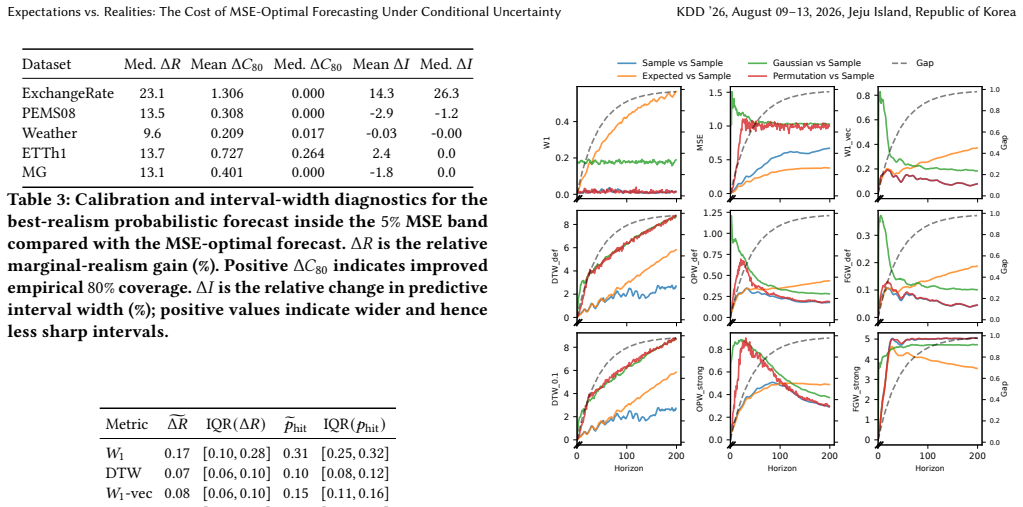
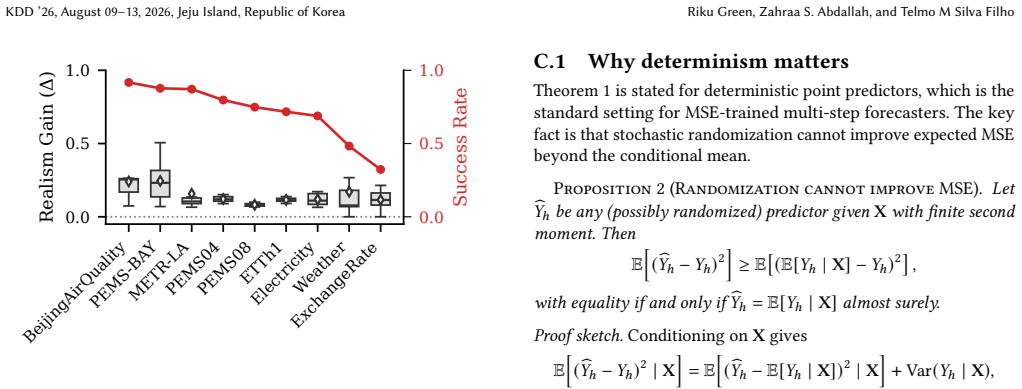
Multi-step time series forecasting (MSF) is commonly evaluated using point-wise error metrics such as mean squared error (MSE), implicitly treating the conditional mean as a sufficient target. We show that this can be misleading under conditional uncertainty, where the conditional expectation becomes unrepresentative of typical realized values at longer horizons. We formalize this effect through a conditional uncertainty gap and prove that whenever this gap is nonzero, no deterministic predictor can simultaneously minimize MSE and match the marginal distribution of realized futures. This establishes a fundamental, model-agnostic trade-off between point accuracy and marginal realism in MSF evaluation. Using controlled stochastic dynamical systems and nine real-world forecasting benchmarks, we empirically characterize the resulting accuracy--realism frontier and \textbf{quantify the practical cost of MSE-only model selection}. As conditional uncertainty increases with forecast horizon, the attainable set expands into a pronounced Pareto front, separating MSE-optimal but under-dispersed predictors from methods that trade accuracy for realistic marginal variability. \textbf{Across benchmarks, we find that small relaxations in MSE ($\boldsymbol{\le 5\%}$) frequently unlock disproportionate gains in marginal realism, with median improvements of $\mathbf{17.3\%}$ and gains exceeding $\mathbf{30\%}$ in some datasets.} We further show that common forecasting strategies systematically occupy different regions of this frontier: direct multi-output predictors concentrate near the accuracy-optimal extreme, while recursive strategies and sample-based inference favors marginal realism. Together, these results expose a structural failure mode of MSE-based evaluation in long-horizon forecasting and recast strategy and inference selection as navigation of an unavoidable accuracy--realism trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that under nonzero conditional uncertainty (defined via the gap between Var(Y) and Var(E[Y|X])), no deterministic predictor can simultaneously achieve minimal MSE and match the marginal distribution of realized futures; this follows from the law of total variance and uniqueness of the L2 projection. It proves the model-agnostic trade-off and empirically maps the resulting accuracy-realism Pareto front on controlled stochastic systems plus nine real benchmarks, reporting that MSE relaxations of ≤5% yield median 17.3% gains in marginal realism (with some >30%) and that direct vs. recursive strategies occupy different frontier regions.
Significance. If the result holds, the work supplies a clean, parameter-free explanation for under-dispersion in long-horizon MSE-optimal forecasts and reframes strategy/inference choice as explicit navigation of an unavoidable frontier. The controlled experiments and the explicit quantification of practical cost (small MSE cost for large realism gains) are strengths; the model-agnostic character of the impossibility result adds generality.
major comments (2)
- [Experiments section (nine real-world benchmarks)] Experiments section (nine real-world benchmarks): the reported median 17.3% realism gain and the claim that the gap is nonzero rest on an approximation to the true conditional distribution; without the explicit estimation procedure, data-exclusion rules, and sensitivity checks, it is impossible to confirm that the numbers are free of post-hoc selection effects that could alter the size or even sign of the reported gains.
- [Empirical characterization paragraph] The abstract and setup state that the gap is 'implicitly approximated' on real data; this approximation step is load-bearing for the empirical claim that 'as conditional uncertainty increases with forecast horizon, the attainable set expands into a pronounced Pareto front,' yet no quantitative validation (e.g., gap estimation error bounds or comparison to oracle on controlled systems) is referenced.
minor comments (1)
- [Abstract] The abstract uses boldface for the 17.3% and 30% figures; these should be presented with the same precision and confidence intervals in the main results tables.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency in the empirical approximation procedure. We address each point below and will revise the manuscript accordingly to strengthen the presentation of the real-data results.
read point-by-point responses
-
Referee: Experiments section (nine real-world benchmarks): the reported median 17.3% realism gain and the claim that the gap is nonzero rest on an approximation to the true conditional distribution; without the explicit estimation procedure, data-exclusion rules, and sensitivity checks, it is impossible to confirm that the numbers are free of post-hoc selection effects that could alter the size or even sign of the reported gains.
Authors: We agree that the current manuscript lacks sufficient detail on the gap approximation for real benchmarks. In the revision we will add an explicit subsection describing the estimation procedure, data-exclusion criteria, and sensitivity checks across parameter choices. This will allow direct verification that the reported median 17.3% gain and nonzero-gap claim are robust. revision: yes
-
Referee: The abstract and setup state that the gap is 'implicitly approximated' on real data; this approximation step is load-bearing for the empirical claim that 'as conditional uncertainty increases with forecast horizon, the attainable set expands into a pronounced Pareto front,' yet no quantitative validation (e.g., gap estimation error bounds or comparison to oracle on controlled systems) is referenced.
Authors: We will incorporate quantitative validation. On the controlled stochastic systems we will add direct comparisons of the approximated gap against the known oracle gap, reporting estimation error. For the real benchmarks we will include bootstrap uncertainty estimates on the gap. These additions will be placed in the empirical characterization section of the revised manuscript. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper's core impossibility result follows directly from the law of total variance (Var(E[Y|X]) < Var(Y) when E[Var(Y|X)] > 0) and the uniqueness of the conditional expectation as the L2 projection; these are external mathematical facts, not derived from the paper's own fitted values, gap estimates, or self-citations. The conditional uncertainty gap is defined with respect to the true conditional distribution (independent of any model outputs or data subsets used in experiments), and the proof of the trade-off does not reduce to any of the enumerated circular patterns. Empirical quantification of the gap size and frontier measurements are presented as observations rather than predictions that feed back into the theoretical claim. No load-bearing self-citation chains or ansatzes appear in the provided abstract and setup.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Conditional expectation is the MSE-optimal point predictor
invented entities (1)
-
conditional uncertainty gap
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Deployment-Side Adaptiveness in Multi-Horizon Volatility Forecasting
Validation-based selection of inference-time rollout rules for multi-output volatility forecasters yields low-cost improvements over default MIMO deployment and recovers much of ensemble benefit at lower cost.
-
Exposure Bias as Epistemic Underidentification in Recursive Forecasting
Recursive forecasting under partial observability is an epistemic underidentification problem, with error decomposed into teacher-forcing mismatch, approximation, and provenance gaps, recast as self-induced epistemic ...
Reference graph
Works this paper leans on
-
[1]
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebas- tian Pineda Arango, Shubham Kapoor, et al. 2024. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815(2024)
Pith/arXiv arXiv 2024
-
[2]
Gianluca Bontempi, Souhaib Ben Taieb, and Yann-Aël Le Borgne. 2012. Machine learning strategies for time series forecasting. InEuropean Big Data Management and Analytics Summer School. Springer, 62–77
2012
-
[3]
Oliver Borchert, David Salinas, Valentin Flunkert, Tim Januschowski, and Stephan Günnemann. 2022. Multi-objective model selection for time series forecasting. arXiv preprint arXiv:2202.08485(2022)
arXiv 2022
-
[4]
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. 2016. Density estimation using real nvp.arXiv preprint arXiv:1605.08803(2016)
Pith/arXiv arXiv 2016
-
[5]
Raphael Fischer and Amal Saadallah. 2024. AutoXPCR: Automated multi- objective model selection for time series forecasting. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 806–815
2024
-
[6]
Tilmann Gneiting and Adrian E Raftery. 2007. Strictly proper scoring rules, prediction, and estimation.Journal of the American statistical Association102, 477 (2007), 359–378
2007
-
[7]
Riku Green, Huw Day, Zahraa S Abdallah, et al. 2025. Epistemic Error Decom- position for Multi-step Time Series Forecasting: Rethinking Bias-Variance in Recursive and Direct Strategies.arXiv preprint arXiv:2511.11461(2025)
arXiv 2025
-
[8]
Riku Green, Grant Stevens, Zahraa Abdallah, et al. 2024. Time-series classification for dynamic strategies in multi-step forecasting.arXiv preprint arXiv:2402.08373 (2024)
arXiv 2024
-
[9]
Riku Green, Grant Stevens, Zahraa S Abdallah, and Telmo M Silva Filho. 2025. Stratify: unifying multi-step forecasting strategies: R. Green et al.Data Mining and Knowledge Discovery39, 5 (2025), 64
2025
-
[10]
Yifan Hu, Yuante Li, Peiyuan Liu, Yuxia Zhu, Naiqi Li, Tao Dai, Shu-tao Xia, Dawei Cheng, and Changjun Jiang. 2025. Fintsb: A comprehensive and practical benchmark for financial time series forecasting.arXiv preprint arXiv:2502.18834 (2025)
Pith/arXiv arXiv 2025
-
[11]
Alexander Jordan, Fabian Krüger, and Sebastian Lerch. 2019. Evaluating prob- abilistic forecasts with scoringRules.Journal of Statistical Software90 (2019), 1–37
2019
-
[12]
Xiangjie Kong, Zhenghao Chen, Weiyao Liu, Kaili Ning, Lechao Zhang, Syauqie Muhammad Marier, Yichen Liu, Yuhao Chen, and Feng Xia. 2025. Deep learning for time series forecasting: a survey.International Journal of Machine Learning and Cybernetics(2025), 1–34
2025
-
[13]
Vincent Le Guen and Nicolas Thome. 2020. Probabilistic time series forecasting with shape and temporal diversity.Advances in neural information processing systems33 (2020), 4427–4440
2020
-
[14]
Zhe Li, Xiangfei Qiu, Peng Chen, Yihang Wang, Hanyin Cheng, Yang Shu, Jilin Hu, Chenjuan Guo, Aoying Zhou, Christian S Jensen, et al. 2025. Tsfm-bench: A comprehensive and unified benchmark of foundation models for time series forecasting. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5595–5606
2025
-
[15]
Bryan Lim, Sercan Ö Arık, Nicolas Loeff, and Tomas Pfister. 2021. Temporal fusion transformers for interpretable multi-horizon time series forecasting.International journal of forecasting37, 4 (2021), 1748–1764
2021
-
[16]
Michael C Mackey and Leon Glass. 1977. Oscillation and chaos in physiological control systems.Science197, 4300 (1977), 287–289
1977
-
[17]
Luke Metz, Ben Poole, David Pfau, and Jascha Sohl-Dickstein. 2016. Unrolled generative adversarial networks.arXiv preprint arXiv:1611.02163(2016)
Pith/arXiv arXiv 2016
-
[18]
1999.Nonlinear Multiobjective Optimization
Kaisa Miettinen. 1999.Nonlinear Multiobjective Optimization. Springer
1999
-
[19]
Aviv Navon, Aviv Shamsian, Ethan Fetaya, and Gal Chechik. 2021. Learning the Pareto Front with HyperNetworks. InInternational Conference on Learning Representations
2021
-
[20]
Xiangfei Qiu, Jilin Hu, Lekui Zhou, Xingjian Wu, Junyang Du, Buang Zhang, Chenjuan Guo, Aoying Zhou, Christian S Jensen, Zhenli Sheng, et al. 2024. Tfb: Towards comprehensive and fair benchmarking of time series forecasting meth- ods.arXiv preprint arXiv:2403.20150(2024)
arXiv 2024
-
[21]
Rasul, Sheheryar Zaidi, Shirzad K
Mohammad A. Rasul, Sheheryar Zaidi, Shirzad K. Hadrian, Tim Januschowski, and Stephan G"unnenman. 2021. TimeGrad: Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting.arXiv preprint arXiv:2106.16214(2021)
arXiv 2021
-
[22]
Yaniv Romano, Evan Patterson, and Emmanuel Candes. 2019. Conformalized quantile regression.Advances in neural information processing systems32 (2019)
2019
-
[23]
Hiroaki Sakoe and Seibi Chiba. 1978. Dynamic Programming Algorithm Opti- mization for Spoken Word Recognition.IEEE Transactions on Acoustics, Speech, and Signal Processing26, 1 (1978), 43–49. doi:10.1109/TASSP.1978.1163055
-
[24]
David Salinas, Valentin Flunkert, and Jan Gasthaus. 2017. DeepAR: Proba- bilistic Forecasting with Autoregressive Recurrent Networks.arXiv preprint arXiv:1704.04110(2017)
Pith/arXiv arXiv 2017
-
[25]
Zezhi Shao, Fei Wang, Yongjun Xu, Wei Wei, Chengqing Yu, Zhao Zhang, Di Yao, Tao Sun, Guangyin Jin, Xin Cao, et al. 2024. Exploring progress in multi- variate time series forecasting: Comprehensive benchmarking and heterogeneity analysis.IEEE Transactions on Knowledge and Data Engineering(2024)
2024
-
[26]
Eivind Strøm and Odd Erik Gundersen. 2024. Performance metrics for multi- step forecasting measuring win-loss, seasonal variance and forecast stability: an empirical study.Applied Intelligence54, 21 (2024), 10490–10515
2024
-
[27]
Bing Su and Gang Hua. 2017. Order-preserving wasserstein distance for sequence matching. InProceedings of the IEEE conference on computer vision and pattern recognition. 1049–1057
2017
-
[28]
Souhaib Ben Taieb. 2014. Machine learning strategies for multi-step-ahead time series forecasting.Universit Libre de Bruxelles, Belgium(2014), 75–86
2014
-
[29]
Lucas Theis, Aäron van den Oord, and Matthias Bethge. 2015. A note on the evaluation of generative models.arXiv preprint arXiv:1511.01844(2015)
Pith/arXiv arXiv 2015
-
[30]
Titouan Vayer, Laetitia Chapel, Rémi Flamary, Romain Tavenard, and Nicolas Courty. 2020. Fused Gromov-Wasserstein distance for structured objects.Algo- rithms13, 9 (2020), 212
2020
-
[31]
Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Yong Liu, Chen Wang, Mingsheng Long, and Jianmin Wang. 2024. Deep time series models: A comprehensive survey and benchmark.arXiv preprint arXiv:2407.13278(2024)
Pith/arXiv arXiv 2024
-
[32]
Jiawen Zhang, Xumeng Wen, Zhenwei Zhang, Shun Zheng, Jia Li, and Jiang Bian
-
[33]
KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Riku Green, Zahraa S
ProbTS: Benchmarking point and distributional forecasting across diverse prediction horizons.Advances in Neural Information Processing Systems37 (2024), 48045–48082. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Riku Green, Zahraa S. Abdallah, and Telmo M Silva Filho A Dataset and Experimental Details A.1 Real-world benchmarks We use the nin...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.