Repair the Amplifier, Not the Symptom: Stable World-Model Correction for Agent Rollouts
Pith reviewed 2026-07-03 13:53 UTC · model grok-4.3
The pith
Repairing the error-amplifying subgraph stabilizes planning graphs more effectively than fixing visible symptoms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
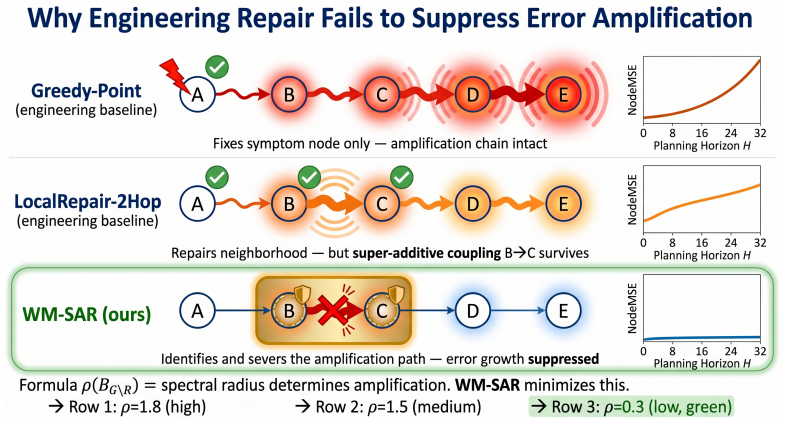
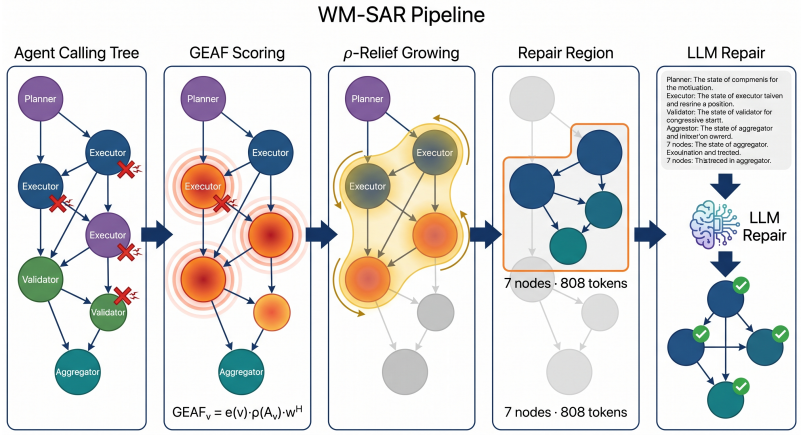
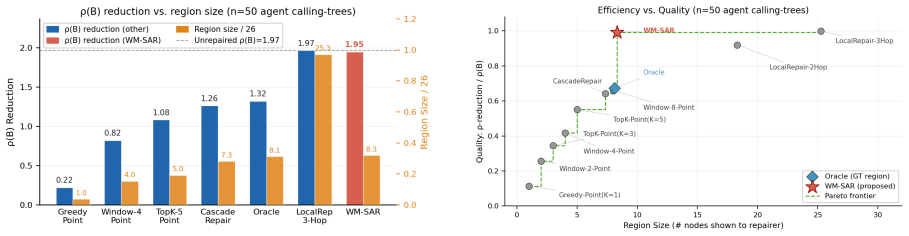
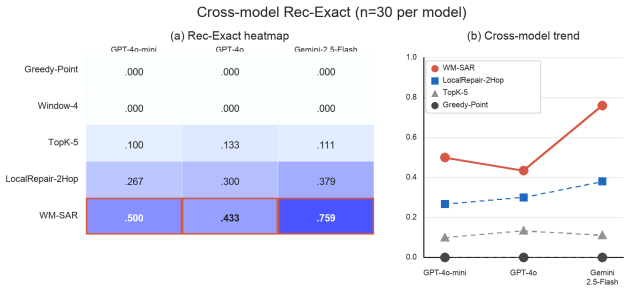
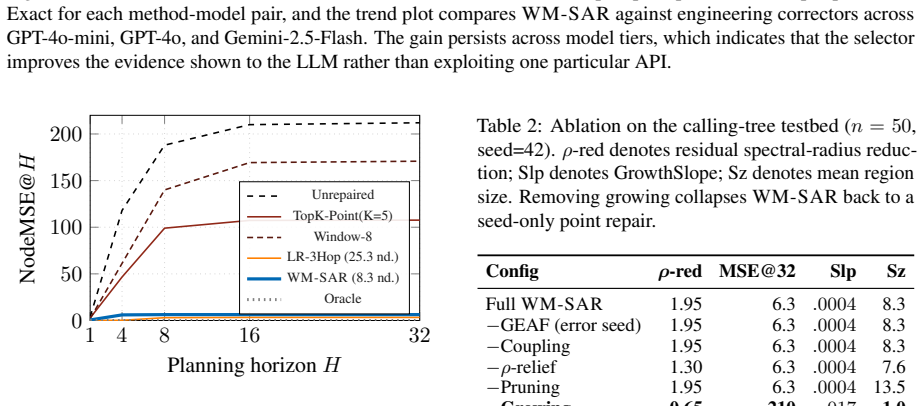
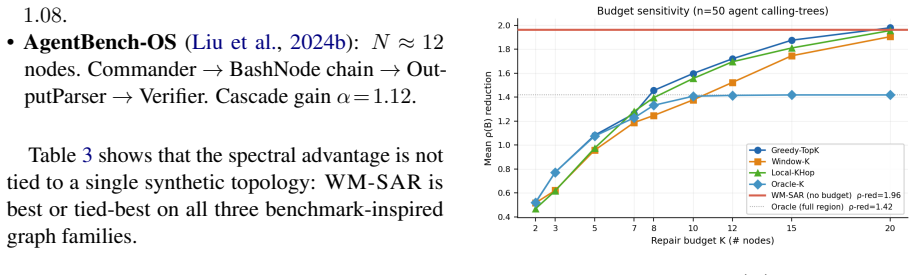
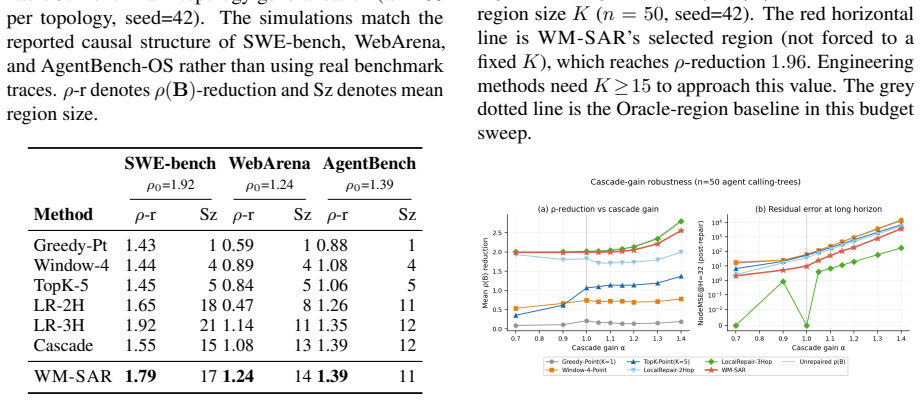
WM-SAR works backward from subgraph amplification to identify the nodes and edges that keep re-amplifying error, then sends only that causal subgraph to the LLM for repair. Across graph simulations and LLM repair experiments, WM-SAR substantially outperforms engineering correctors under realistic token budgets, achieves near-whole-graph stabilization with a compact region, and gives the LLM a cleaner repair target.
What carries the argument
World-Model Subgraph Amplification Repair (WM-SAR), which identifies the causal subgraph that re-amplifies errors instead of scanning nodes and edges for visible symptoms.
If this is right
- Persistent workflows with thousands of steps become feasible without full-graph replay after each mistake.
- Corrections remain effective under limited token budgets that would constrain symptom-scanning methods.
- The LLM receives a focused causal target rather than many irrelevant symptoms.
- Near-complete graph stability can result from repairing only a small compact region.
Where Pith is reading between the lines
- The same amplification-identification step could be applied to non-LLM planners if rollout traces are available.
- Detecting amplification patterns earlier in a rollout might enable preventive repairs before visible failures occur.
- Causal subgraph analysis may generalize to other graph-structured agent memory systems beyond planning.
Load-bearing premise
The amplifying subgraph can be accurately identified from rollout behavior, and repairing only those nodes and edges will produce stable correction without missing other error sources or creating new instabilities.
What would settle it
An experiment in which WM-SAR identifies and repairs a subgraph yet the planning graph continues to show instability from unidentified error sources outside that region.
Figures

read the original abstract
As agent planning moves from short tool chains toward persistent workflows with thousands or tens of thousands of steps, failures will occur inside large planning graphs rather than in isolated predictions. Replanning the entire graph after every mistake is neither computationally realistic nor desirable: full-graph replay consumes large context budgets, exposes the LLM to many irrelevant symptoms, and can degrade long-context retrieval. This paper studies the missing component in such systems: a world-model corrector that repairs the failed planning graph in place. We compare two families of correctors. The first is the common engineering approach: scan nodes and edges, choose a suspicious local region, and ask an LLM to repair it. We implement strong engineering LLM correctors and find that they can help, especially when given very large contexts. The second family is our approach, WM-SAR (World-Model Subgraph Amplification Repair): instead of scanning for visible symptoms, it works backward from subgraph amplification, identifies the nodes and edges that keep re-amplifying error, and sends only that causal subgraph to the LLM. Across graph simulations and LLM repair experiments, WM-SAR substantially outperforms engineering correctors under realistic token budgets, achieves near-whole-graph stabilization with a compact region, and gives the LLM a cleaner repair target.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes WM-SAR (World-Model Subgraph Amplification Repair), a corrector for failed planning graphs in long-horizon agents. Instead of scanning nodes/edges for visible symptoms and sending a local region to an LLM, WM-SAR works backward from amplification detected in rollout traces to identify a compact causal subgraph whose repair stabilizes the full graph. The abstract claims that, across graph simulations and LLM repair experiments, WM-SAR substantially outperforms engineering correctors under realistic token budgets, achieves near-whole-graph stabilization with a compact region, and supplies the LLM with a cleaner repair target.
Significance. If the empirical claims and the underlying identification procedure hold, the work would provide a practical mechanism for in-place correction of large planning graphs without full replay or excessive context, addressing a genuine scalability bottleneck in persistent agent workflows. The conceptual emphasis on repairing amplifiers rather than symptoms is a clear contribution to the design of stable world-model maintenance.
major comments (2)
- [Abstract] Abstract: the central claims of 'substantial outperformance' and 'near-whole-graph stabilization with a compact region' are asserted without any quantitative results, baselines, controls, statistical tests, or exclusion criteria, rendering the magnitude and reliability of the reported gains unverifiable.
- [Abstract] Abstract (method description): the claim that identifying the 'nodes and edges that keep re-amplifying error' produces stable correction rests on the unexamined assumption that the rollout-derived amplification metric is both sensitive (no false negatives for latent errors) and specific (no false positives that create new instabilities); no analysis or counter-example handling is supplied for multiple interacting error sources, which is load-bearing for the superiority claim over symptom-scanning correctors.
minor comments (1)
- [Abstract] Abstract: the terms 'subgraph amplification' and 'engineering correctors' are used without a one-sentence definition, which would aid readability for readers outside the immediate sub-area.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We agree that the abstract requires quantitative grounding and will revise it to include specific results. We also agree that explicit validation of the amplification metric is needed and will add supporting analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'substantial outperformance' and 'near-whole-graph stabilization with a compact region' are asserted without any quantitative results, baselines, controls, statistical tests, or exclusion criteria, rendering the magnitude and reliability of the reported gains unverifiable.
Authors: We agree that the abstract presents high-level claims without supporting numbers. In the revision we will incorporate concrete quantitative highlights drawn from the graph simulations and LLM experiments (e.g., relative improvement percentages, compact-region size as a fraction of the full graph, and any reported statistical measures), while retaining the abstract's brevity. revision: yes
-
Referee: [Abstract] Abstract (method description): the claim that identifying the 'nodes and edges that keep re-amplifying error' produces stable correction rests on the unexamined assumption that the rollout-derived amplification metric is both sensitive (no false negatives for latent errors) and specific (no false positives that create new instabilities); no analysis or counter-example handling is supplied for multiple interacting error sources, which is load-bearing for the superiority claim over symptom-scanning correctors.
Authors: The full paper validates the procedure via end-to-end performance gains, but we accept that an explicit sensitivity/specificity analysis and discussion of multiple interacting errors are absent from the current text. We will add a short subsection or appendix that reports metric behavior under controlled multi-error conditions and any counter-example handling performed. revision: yes
Circularity Check
No circularity: method relies on independent rollout simulations without fitted parameters or self-referential definitions
full rationale
The paper presents WM-SAR as an algorithmic procedure that detects amplifying subgraphs from external rollout traces and passes the compact region to an LLM for repair. No equations, fitted parameters, or predictions are described that reduce to the inputs by construction. Claims rest on empirical comparisons in graph simulations and LLM experiments, which are independent of the method's internal logic. No self-citations or uniqueness theorems are invoked in the provided text. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
World Models , author=. arXiv preprint arXiv:1803.10122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Mastering Diverse Domains through World Models
Mastering Diverse Domains through World Models , author=. arXiv preprint arXiv:2301.04104 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
ACM SIGART Bulletin , volume=
Dyna, an Integrated Architecture for Learning, Planning, and Reacting , author=. ACM SIGART Bulletin , volume=
-
[4]
Mastering
Schrittwieser, Julian and Antonoglou, Ioannis and Hubert, Thomas and Simonyan, Karen and Sifre, Laurent and Schmitt, Simon and Guez, Arthur and Lockhart, Edward and Hassabis, Demis and Graepel, Thore and Lillicrap, Timothy and Silver, David , journal=. Mastering
-
[5]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle=
-
[6]
Advances in Neural Information Processing Systems , volume=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
International Conference on Machine Learning , year=
Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models , author=. International Conference on Machine Learning , year=
-
[9]
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle=
-
[10]
and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E
Patil, Shishir G. and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E. , booktitle=. Gorilla: Large Language Model Connected with Massive
-
[11]
Song, Yifan and Xiong, Weimin and Zhu, Dawei and Cheng, Li and Wang, Ke and Ye, Tian and Li, Sujian , journal=
-
[12]
2024 , howpublished=
2024
-
[13]
arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
2024 , howpublished=
Structured Model Outputs , author=. 2024 , howpublished=
2024
-
[15]
2026 , howpublished=
2026
-
[16]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hanglei and others , booktitle=
-
[17]
International Conference on Learning Representations , year=
Shridhar, Mohit and Yuan, Xingdi and C. International Conference on Learning Representations , year=
-
[18]
International Conference on Learning Representations , year=
Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization , author=. International Conference on Learning Representations , year=
-
[19]
Shen, Yongliang and Song, Kaitao and Tan, Xu and Zhang, Dongsheng and Lu, Weiming and Zhuang, Yueting , booktitle=
-
[20]
Ma, Chang and Zhang, Junlei and Liu, Zhihao and Liu, Croix and Ma, Rui and Chen, Yi and others , journal=
-
[21]
Proceedings of the International Conference on Machine Learning , volume=
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems , author=. Proceedings of the International Conference on Machine Learning , volume=
-
[22]
Lu, Jiaying and Pan, Bo and Chen, Jieyi and Feng, Yingchaojie and Hu, Jingyuan and Peng, Yuchen and Chen, Wei , journal=
-
[23]
Failure Modes of Learning Reward Models for
Gleave, Adam and Irving, Geoffrey , journal=. Failure Modes of Learning Reward Models for
-
[24]
Advances in Neural Information Processing Systems , volume=
Self-Refine: Iterative Refinement with Self-Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
International Conference on Machine Learning , year=
Learning Latent Dynamics for Planning from Pixels , author=. International Conference on Machine Learning , year=
-
[26]
Relational inductive biases, deep learning, and graph networks
Relational Inductive Biases, Deep Learning, and Graph Networks , author=. arXiv preprint arXiv:1806.01261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
International Conference on Machine Learning , year=
Neural Message Passing for Quantum Chemistry , author=. International Conference on Machine Learning , year=
-
[28]
International Conference on Learning Representations , year=
Understanding over-squashing and bottlenecks on graphs via curvature , author=. International Conference on Learning Representations , year=
-
[29]
1997 , publisher=
Spectral Graph Theory , author=. 1997 , publisher=
1997
-
[30]
Proceedings of ECML-PKDD , year=
Graph-Level Anomaly Detection via Hierarchical Memory Networks , author=. Proceedings of ECML-PKDD , year=
-
[31]
Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering , pages=
Boosting Coverage-Based Fault Localization via Graph-Based Representation Learning , author=. Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering , pages=
-
[32]
1999 , journal=
The PageRank citation ranking: Bringing order to the Web , author=. 1999 , journal=
1999
-
[33]
International Conference on Machine Learning , year=
World Model as a Graph: Learning Latent Landmarks for Planning , author=. International Conference on Machine Learning , year=
-
[34]
International Conference on Machine Learning , year =
Feng, Tao and Wu, Yexin and Lin, Guanyu and You, Jiaxuan , title =. International Conference on Machine Learning , year =
-
[35]
Proceedings of ICML , year =
Asadi, Kavosh and Misra, Dipendra and Littman, Michael , title =. Proceedings of ICML , year =
-
[36]
Advances in Neural Information Processing Systems , year =
Chua, Kurtland and Calandra, Roberto and McAllister, Rowan and Levine, Sergey , title =. Advances in Neural Information Processing Systems , year =
-
[37]
Training Verifiers to Solve Math Word Problems
Cobbe, Karl and Kosaraju, Vineet and Bavarian, Mohammad and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and Plappert, Matthias and Tworek, Jerry and Hilton, Jacob and Nakano, Reiichiro and Hesse, Christopher and Schulman, John , title =. arXiv preprint arXiv:2110.14168 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Lightman, Hunter and Kosaraju, Vineet and Burda, Yura and Edwards, Harri and Baker, Bowen and Lee, Teddy and Leike, Jan and Schulman, John and Sutskever, Ilya and Cobbe, Karl , title =. arXiv preprint arXiv:2305.20050 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy , title =
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy , title =. Transactions of the Association for Computational Linguistics , volume =
-
[40]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, Guanzhi and Xie, Yuqi and Jiang, Yunfan and Mandlekar, Ajay and Xiao, Chaowei and Zhu, Yuke and Fan, Linxi and Anandkumar, Anima , title =. arXiv preprint arXiv:2305.16291 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Advances in Neural Information Processing Systems , year =
Janner, Michael and Fu, Justin and Zhang, Marvin and Levine, Sergey , title =. Advances in Neural Information Processing Systems , year =
-
[42]
International Joint Conference on Artificial Intelligence , year =
Anokhin, Petr and Semenov, Nikita and Sorokin, Artyom and Evseev, Dmitry and Burtsev, Mikhail and Burnaev, Evgeny , title =. International Joint Conference on Artificial Intelligence , year =
-
[43]
International Conference on Learning Representations , year=
Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation , author=. International Conference on Learning Representations , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
Agent Planning with World Knowledge Model , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Jimenez, Carlos E and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=
-
[46]
Zhou, Shuyan and Xu, Frank F and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Bisk, Yonatan and Fried, Daniel and Alon, Uri and others , booktitle=
-
[47]
Yang, John and Jimenez, Carlos E and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.