An LLM-Native Psychometric Instrument Does Not Predict LLM Behavior: Evidence Across 25 Models
Pith reviewed 2026-07-04 19:31 UTC · model glm-5.2
The pith
LLM self-reports don't predict behavior, even with native constructs
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
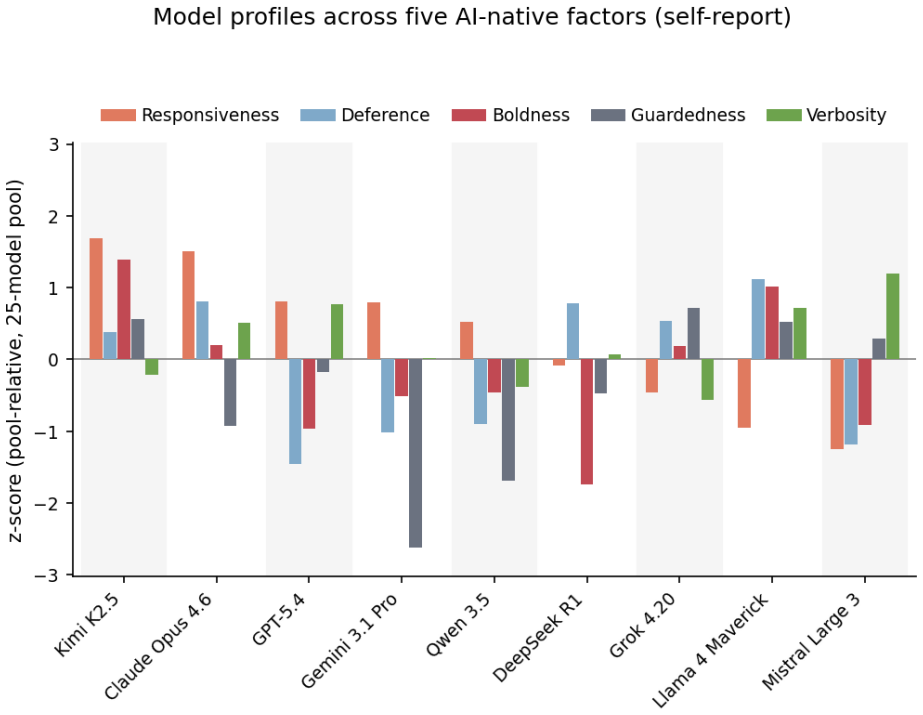
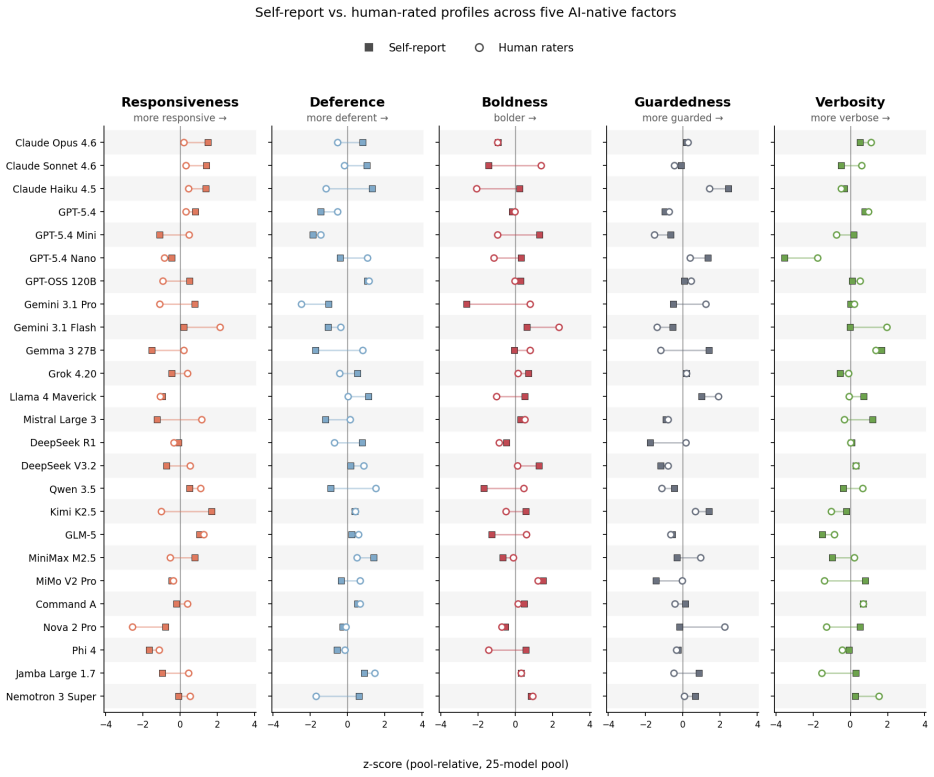
The central discovery is a dissociation between what LLMs say about themselves and what they do, demonstrated for the first time using constructs derived from LLM behavior rather than from human psychology. Five stable, replicable self-report factors emerged from bottom-up factor analysis, but these factors failed to predict how human raters perceived the same models' open-ended behavior, with the weak exception of Verbosity. A secondary discovery is a specific shared bias between LLM self-report items and LLM judges: both draw on textual-surface signals (structured formatting, enthusiastic framing) that human raters do not weight as heavily. This bias is undetectable by standard inter-judge
What carries the argument
The paper's central mechanism is a three-way comparison: self-report factor scores, human behavioral ratings, and LLM-judge behavioral ratings. The key diagnostic is the Responsiveness dissociation, where self-report correlates with LLM judges (r = .53) but not humans (r = .04), while humans and judges agree (r = .59). The author proves this pattern is incompatible with a single latent construct by showing the observed near-zero correlation falls below the lower bound implied by the product of the other two correlations (r ≈ .31). This forces a dual-loading account: self-report items and LLM judges share a source of variance (textual-surface cues) that human observers do not.
Load-bearing premise
The behavioral prompt set used to test predictive validity is small: 20 prompts (4 per factor) across 25 models. The paper itself acknowledges this limitation. When the analysis is restricted to the four prompts designed for each factor, even the weak Verbosity signal disappears, suggesting the observed convergence may be carried by broad aggregation rather than by prompts that adequately sample each factor's behavioral space.
What would settle it
Administer the instrument to 50+ models with a larger behavioral prompt battery (e.g., 20+ prompts per factor). If self-report scores reliably predict human behavioral ratings for most or all factors, the self-report-behavior gap would be substantially narrowed or closed.
Figures
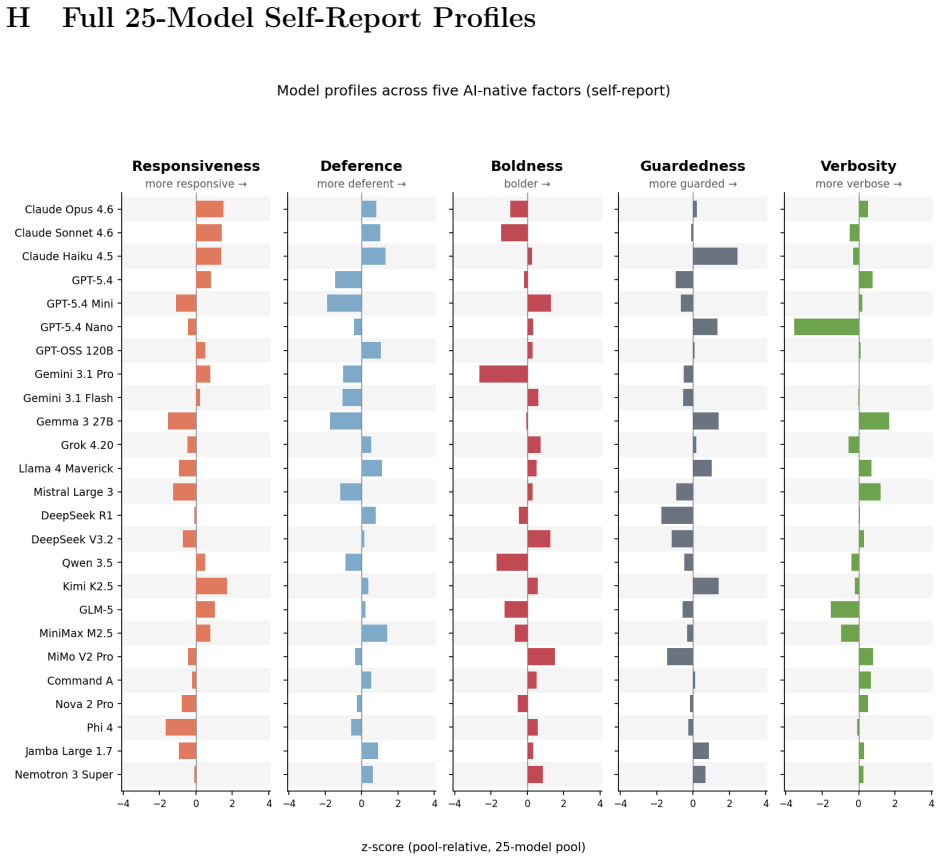
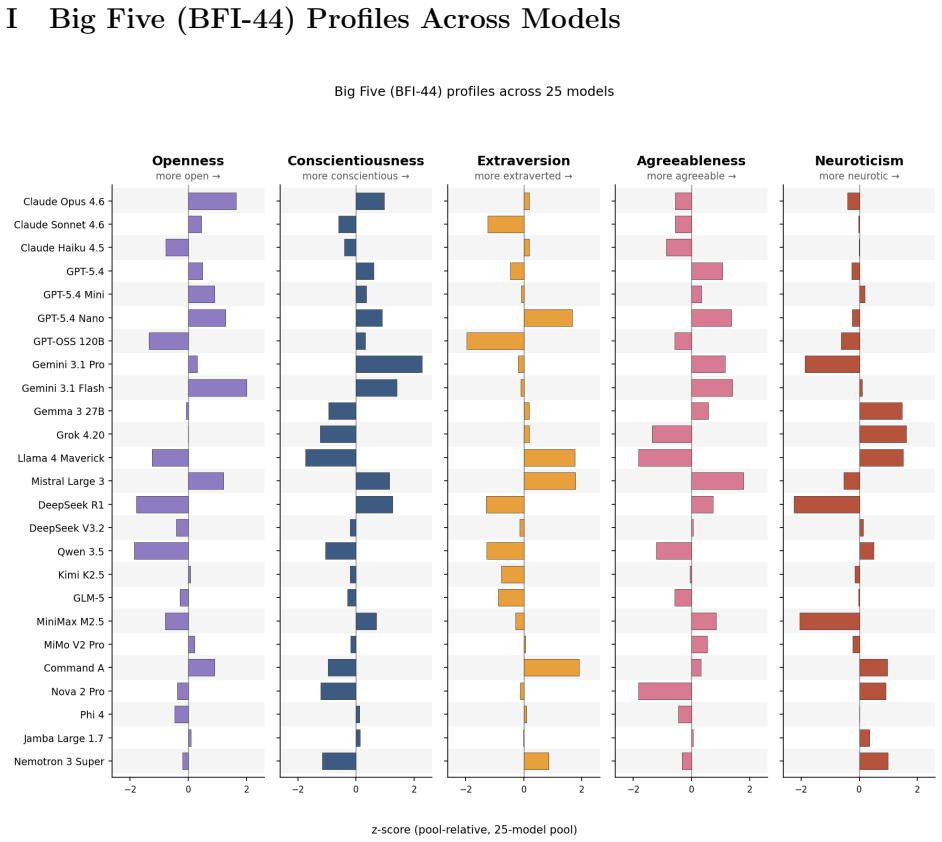
read the original abstract
Large language models (LLMs) give stable answers to personality questionnaires, yet these self-reports fail to predict how the models actually behave. Is this gap an artifact of forcing human trait categories onto LLMs, or something deeper about LLM self-report itself? To find out, we built the first psychometric instrument whose dimensions are derived bottom-up from LLM behavior rather than borrowed from human psychology. Administering 300 items (240 Likert + 60 scenario) to 25 LLMs across 17 model families, 30 times each, exploratory factor analysis revealed five replicable, highly reliable factors: Responsiveness, Deference, Boldness, Guardedness, and Verbosity (all Tucker $\phi \geq .957$, all $\alpha \geq .930$). We then collected 2,500 open-ended behavioral samples and had them rated by 151 humans and a three-judge LLM ensemble. Humans and judges agreed about model behavior ($\bar{r} = .51$), but self-report predicted neither: the gap persists even for constructs native to LLMs, where a human-mismatch explanation no longer applies. The exception is telling. On Responsiveness, self-report tracked LLM judges ($r = .53$) but not humans ($r = .04$), even though humans and judges otherwise agreed ($r = .59$). Self-report items and LLM judges share a source of variance that human observers do not. This confound is invisible to the within-ensemble reliability checks used to validate LLM judges, and it poses a concrete risk for the LLM-as-judge pipelines now central to model evaluation. We release the instrument as a diagnostic probe for alignment-shaped self-description.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents the first LLM-native psychometric instrument: 300 self-report items derived bottom-up from LLM behavioral affordances (rather than imported from human personality taxonomies), administered to 25 LLMs across 17 model families, 30 times each. Exploratory factor analysis on a preregistered split-half design yields five replicable factors (Responsiveness, Deference, Boldness, Guardedness, Verbosity; all Tucker φ ≥ .957, all α ≥ .930). The central predictive-validity finding is that self-report factor scores do not reliably predict how human raters (N=151) or an LLM-judge ensemble rate the same models' open-ended behavior (mean Instrument–Human r = .15, no factor-level CI excluding zero at N=25). The paper's most emphasized secondary finding is a Responsiveness dissociation: self-report correlates with LLM judges (r = .53) but not humans (r = .04), while humans and judges agree (r = .59), which the paper interprets as evidence of a shared textual-surface bias between LLM self-report and LLM judges. The instrument, raw data, and code are released.
Significance. The paper makes a genuine methodological contribution by constructing an LLM-native instrument via bottom-up factor analysis and validating it against human behavioral ratings—addressing a gap explicitly identified in recent surveys. The factor-structure analysis is well-executed: the preregistered split-half design, observation weighting, Tucker congruence checks, and the model-level robustness check (Appendix K, φ ≥ .990) are appropriate safeguards for the unconventional N=25, 240-item EFA. The release of the 100-item instrument, scoring rules, raw response data, and analysis code is a concrete strength. The finding that internal psychometric coherence does not translate to behavioral predictive validity—even when constructs are LLM-native—is important for the growing 'AI psychometrics' literature. However, the paper's most actionable claim about LLM-as-judge bias (the Responsiveness dissociation) is overstated relative to what the statistical evidence supports at N=25, as detailed below.
major comments (3)
- §4.6.3, Table 7, and §5.3: The claim that the Responsiveness dissociation (r_SJ = .53, r_SH = .04, r_HJ = .59) is 'mathematically incompatible with a single-factor model' is not supported at the reported sample size. The bound r_SH ≥ r_SJ × r_HJ ≈ .31 holds for population correlations, but with N=25 and the reported 95% CIs, the lower bounds are r_SJ ≥ .30 and r_HJ ≥ .06, yielding a product as low as .018—well within the r_SH CI of [-.33, +.34]. The human–judge CI for Responsiveness [.06, .86] is extremely wide and barely excludes zero. The paper does not report a formal test (e.g., SEM comparison of single-factor vs. dual-loading models, or a bootstrap of the product r_SJ × r_HJ minus r_SH). Without such a test, the 'mathematical incompatibility' and the language 'demands a dual-loading account' (§5.3) are not justified. This is load-bearing because the dissociation is the basis for the
- §4.6.3 and §5.6: The behavioral prompt set (n=20, 4 per factor) is acknowledged as 'relatively small' (§5.6), but the paper does not adequately address the threat this poses to the central null result. The on-target analysis (§4.6.3) shows that restricting to factor-targeted prompts removes even the weak Verbosity signal (on-target mean r = −.03 vs. all-prompts r = .15), meaning the weak convergence that exists is carried by broad aggregation rather than by prompts designed to elicit each factor. If the behavioral prompts do not adequately sample each factor's construct space, the null predictive-validity result could reflect prompt poverty rather than a genuine self-report–behavior decoupling. The paper should either (a) explicitly scope the central claim to 'the 20 prompts tested' rather than 'behavior' broadly, or (b) provide evidence that 4 prompts per factor provide adequatecoverage
- §4.6.3, Table 7: The abstract states 'self-report predicted neither [humans nor judges]' but Table 7 shows the mean Instrument–Judge correlation is r = .17 with CI [.06, .29], which excludes zero. The Responsiveness factor alone (r = .53, CI [.30, .72]) drives this. The abstract's blanket claim that self-report does not predict judge ratings is contradicted by the aggregate CI. The paper should reconcile the abstract with the table, either by scoping the claim to human ratings (where no CI excludes zero) or by acknowledging the judge convergence on Responsiveness as a partial exception rather than dismissing it entirely.
minor comments (8)
- §3.3.3: The observation weighting scheme (weight 1/15 per row, effective N=25) is described clearly, but the paper does not report whether standard errors or CIs in the factor-structure analysis account for this weighting. Clarifying whether the EFA standard errors reflect the effective N or the raw 375 observations would help readers calibrate the factor-stability claims.
- Table 6: The flag column uses '†' for factors below r=.65, but the threshold is described as 'preregistered r=.65 threshold' in the text. The table header should clarify whether this refers to mean r or ICC, as both are reported.
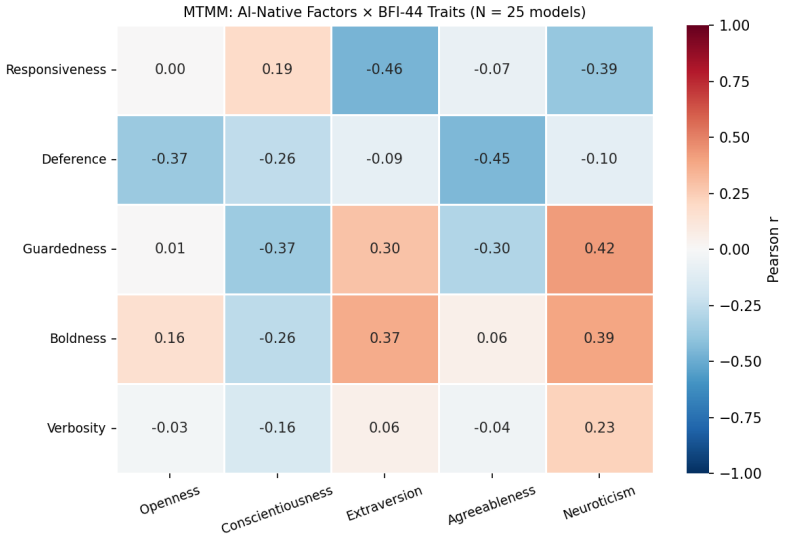
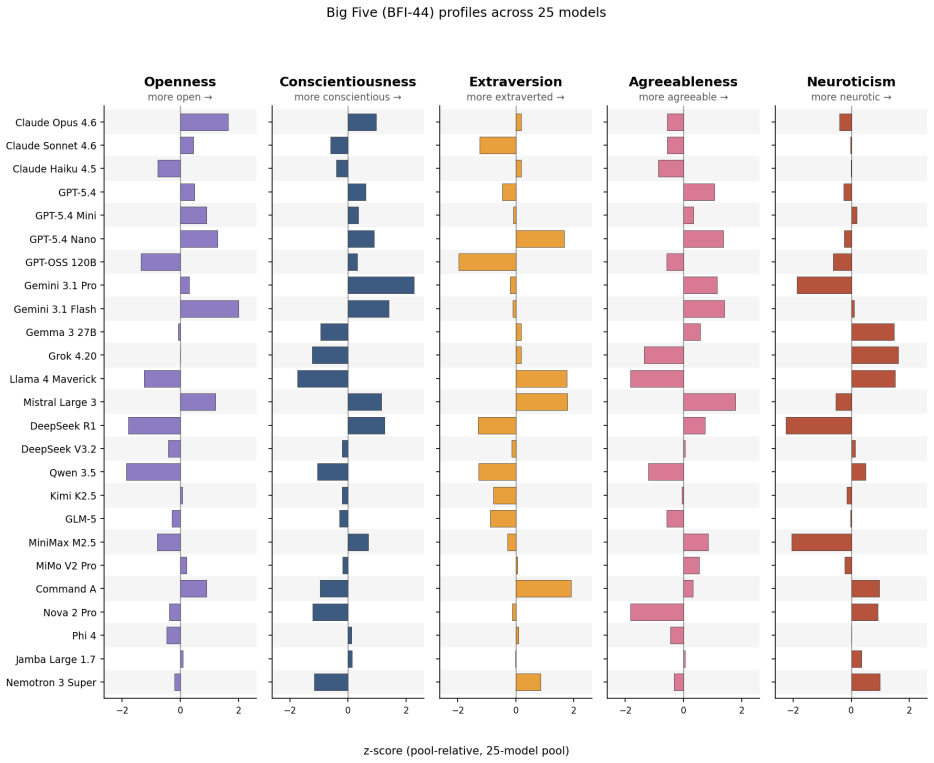
- §4.5.1: The decision to use forward-keyed Extraversion only (α_fwd = .932 vs. full-scale α = .167) is reasonable but should note that this subscale is 8 items, not the standard 8-item E subscale from BFI-44 (which includes reverse-keyed items). The item count should be specified.
- Figure 2 caption: 'Self-report and human ratings converge most tightly on Verbosity and Guardedness' — but Table 7 shows Guardedness r = .27 (CI [−.10, +.64]) and Verbosity r = .41 (CI [−.10, +.70]), neither excluding zero. The caption overstates the convergence; consider 'show the largest point estimates for convergence' instead.
- §5.3: 'This is a concrete empirical demonstration that LLM-as-judge ratings can look validated against text-based criteria (like self-report) while failing to track the human judgments they are meant to proxy' — this is a single-factor (Responsiveness) finding at N=25 with wide CIs. The generalization to plural 'ratings' and 'criteria' should be tempered.
- Appendix B: Several per-model α values are negative (e.g., Llama 4 Maverick Responsiveness α = −0.86). While the text explains this reflects high determinism, a brief note in the table caption would prevent misreading.
- §3.2.1: The 13th candidate dimension (Sensitivity to Criticism) merged into Social Alignment is mentioned in a footnote. Consider moving this to the main text for visibility, as it affects the item-generation design.
- References: Several arXiv preprints are cited with future dates (e.g., Yang et al., 2026; Gao et al., 2026). Verify these are not placeholder dates.
Simulated Author's Rebuttal
We thank the referee for a careful and constructive review. The referee raises three major comments: (1) the 'mathematical incompatibility' claim for the Responsiveness dissociation is not formally tested and may be unjustified at N=25; (2) the small behavioral prompt set (n=20) threatens the central null result; and (3) the abstract's blanket claim that self-report predicted neither humans nor judges is contradicted by Table 7's judge convergence. We agree with comments (1) and (3) and will revise accordingly. On comment (2), we agree the claim should be scoped but disagree that prompt poverty is the most likely explanation, for reasons we detail below.
read point-by-point responses
-
Referee: The claim that the Responsiveness dissociation is 'mathematically incompatible with a single-factor model' is not supported at N=25. The bound r_SH >= r_SJ x r_HJ holds for population correlations, but with N=25 and the reported CIs, the product of lower bounds can be as low as .018, well within the r_SH CI. No formal test (SEM or bootstrap of the product) is reported. The language 'demands a dual-loading account' is not justified.
Authors: The referee is correct. The triangle inequality bound r_SH >= r_SJ x r_HJ applies to population correlations, and at N=25 the confidence intervals are wide enough that the observed pattern is not formally incompatible with a single-factor model. We did not report a formal SEM comparison or a bootstrap test of the product r_SJ x r_HJ minus r_SH, and without such a test the language 'mathematically incompatible' and 'demands a dual-loading account' overstates what the evidence supports. We will revise the manuscript in three ways: (1) replace 'mathematically incompatible' with language that accurately characterizes the pattern as suggestive of but not a formal test of dual-loading structure; (2) add a bootstrap test of the product r_SJ x r_HJ minus r_SH to quantify how unusual the observed gap is under the null; and (3) soften 'demands a dual-loading account' to 'is consistent with a dual-loading account but does not rule out a single-factor model at this sample size.' We appreciate the referee catching this overstatement. revision: yes
-
Referee: The behavioral prompt set (n=20, 4 per factor) is acknowledged as 'relatively small' but the paper does not adequately address the threat this poses to the central null result. The on-target analysis shows that restricting to factor-targeted prompts removes even the weak Verbosity signal, meaning the weak convergence is carried by broad aggregation. The null could reflect prompt poverty rather than genuine decoupling. The paper should either scope the central claim to 'the 20 prompts tested' or provide evidence that 4 prompts per factor provide adequate coverage.
Authors: We agree that the paper should explicitly scope the central null claim to the 20 prompts tested rather than to 'behavior' broadly, and we will revise the abstract, Section 5.3, and Section 5.6 accordingly. However, we partially disagree with the stronger concern that prompt poverty is a plausible alternative explanation for the null, for three reasons. First, the on-target analysis does not merely attenuate the signal—it reverses the sign of Responsiveness (r = -.45, CI excluding zero), which is the opposite of what prompt poverty would predict; inadequate sampling of a construct should produce noise around zero, not a reliable negative correlation. Second, the human-judge agreement on the same 20 prompts is substantial (mean r = .51, four of five factor-level CIs excluding zero), demonstrating that the prompts do elicit discriminable behavioral variation that both rating systems can detect—if the prompts were too impoverished to capture factor-relevant behavior, human-judge agreement should also collapse. Third, the two factors with the most directly observable behavioral signatures (Verbosity and Guardedness) show the largest convergent point estimates, consistent with a gradient of observability rather than a gradient of prompt adequacy. That said, we acknowledge that 4 prompts per factor is insufficient to claim comprehensive construct coverage, and we cannot rule out that a larger, more carefully designed prompt battery would recover stronger convergence. We will add this as an explicit limitation and scope all claims to 'the 20 behavioral prompts tested.' revision: partial
-
Referee: The abstract states 'self-report predicted neither [humans nor judges]' but Table 7 shows the mean Instrument-Judge correlation is r = .17 with CI [.06, .29], which excludes zero. The Responsiveness factor alone (r = .53, CI [.30, .72]) drives this. The abstract's blanket claim is contradicted by the aggregate CI.
Authors: The referee is correct. The aggregate Instrument-Judge correlation (r = .17, CI [.06, .29]) does exclude zero, driven primarily by the Responsiveness factor (r = .53). The abstract's statement that 'self-report predicted neither' is inaccurate as applied to judge ratings. We will revise the abstract to state that self-report did not predict human ratings (no factor-level CI excluding zero) but showed partial convergence with LLM-judge ratings, concentrated on Responsiveness. This revision is also consistent with the paper's own framing of the Responsiveness dissociation as 'the exception that is telling'—the abstract should reflect that exception rather than contradicting it. We will ensure the abstract, Section 4.6.3, and the conclusion are all reconciled with Table 7. revision: yes
Circularity Check
No significant circularity: central null result is structurally non-circular; behavioral prompts designed post-factor-extraction bias against, not toward, the null finding
full rationale
The paper's central claim — that LLM self-report does not predict behavior — is a null result with independently derived inputs (self-report Likert scores) and outputs (human and LLM-judge ratings of open-ended behavioral samples). There is no self-definitional reduction. The one design choice that could introduce circularity is that behavioral prompts (§3.2.3) and the judge rating instrument were designed using the same five factor definitions extracted from the self-report data. However, this design biases toward finding self-report–behavior convergence, not against it: if the behavioral prompts and rating criteria share construct definitions with the self-report items, we would expect elevated correlations, yet the paper finds near-zero convergence. The on-target analysis (§4.6.3) confirms this: restricting to factor-targeted prompts yields worse convergence (r̄=−.03) than the broad aggregate (r̄=.15). The Responsiveness dissociation claim (r_SH ≥ r_SJ × r_HJ) relies on a standard single-factor correlation bound, not a self-citation, and its concern is statistical validity at N=25 (point estimates treated as population parameters), not circularity. No load-bearing self-citations were identified. Score of 1 reflects the minor shared-instrument design choice that is non-circular in effect.
Axiom & Free-Parameter Ledger
free parameters (4)
- Number of factors (k=5) =
5
- Item retention thresholds =
primary loading ≥.40, cross-loading <.30
- Behavioral prompt set (n=20) =
20 prompts (4 per factor)
- Judge ensemble composition =
Claude Opus 4.6, GPT-5.4, Gemini 3.1 Pro
axioms (4)
- domain assumption LLM responses to Likert items at temperature 1.0 across 30 runs approximate the model's probability-weighted expected score.
- domain assumption Human raters on Prolific can reliably rate LLM behavioral outputs on abstract constructs like Responsiveness and Boldness.
- domain assumption The 12 candidate dimensions used for item generation adequately sample the space of LLM behavioral variation.
- domain assumption Factor analysis at model-level N=25 with 240 items yields a trustworthy covariance structure.
invented entities (2)
-
Five LLM-native self-report factors (Responsiveness, Deference, Boldness, Guardedness, Verbosity)
independent evidence
-
Textual-surface bias (shared variance between LLM self-report and LLM judges)
independent evidence
Reference graph
Works this paper leans on
-
[1]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Jackson Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, and Jared Kaplan. A general language assistant as a labora...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
P. Bhandari, U. Naseem, A. Datta, N. Fay, and M. Nasim. Evaluating personality traits in large language models: Insights from psychological questionnaires. In Companion Proceedings of the ACM Web Conference 2025, 2025. URL https://arxiv.org/abs/2502.05248
-
[4]
Art or artifice? L arge language models and the false promise of creativity
Tuhin Chakrabarty, Philippe Laban, Divyansh Agarwal, Smaranda Muresan, and Chien-Sheng Wu. Art or artifice? L arge language models and the false promise of creativity. arXiv preprint arXiv:2309.14556, 2024. URL https://arxiv.org/abs/2309.14556
-
[5]
OR-Bench : An over-refusal benchmark for large language models
Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. OR-Bench : An over-refusal benchmark for large language models. arXiv preprint arXiv:2405.20947, 2025. URL https://arxiv.org/abs/2405.20947
-
[6]
Dorner, Tom S \"u hr, Samira Samadi, and Augustin Kelava
Florian E. Dorner, Tom S \"u hr, Samira Samadi, and Augustin Kelava. Do personality tests generalize to large language models? In Socially Responsible Language Modelling Research (SoLaR) Workshop at NeurIPS, 2023
work page 2023
-
[7]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Bal \'a zs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length-controlled AlpacaEval : A simple way to debias automatic evaluators. arXiv preprint arXiv:2404.04475, 2025. URL https://arxiv.org/abs/2404.04475
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
On the creativity of large language models
Giorgio Franceschelli and Mirco Musolesi. On the creativity of large language models. AI & Society, 40 0 (5): 0 3785--3795, 2024. URL https://link.springer.com/article/10.1007/s00146-024-02127-3
-
[9]
D. C. Funder. On the accuracy of personality judgment: A realistic approach. Psychological Review, 102 0 (4): 0 652--670, 1995
work page 1995
-
[10]
Evaluating and mitigating llm-as-a-judge bias in communication systems, 2026
Jiaxin Gao, Chen Chen, Yanwen Jia, Xueluan Gong, Kwok-Yan Lam, and Qian Wang. Evaluating and mitigating llm-as-a-judge bias in communication systems, 2026. URL https://arxiv.org/abs/2510.12462
-
[11]
Self-assessment tests are unreliable measures of llm personality, 2024
Akshat Gupta, Xiaoyang Song, and Gopala Anumanchipalli. Self-assessment tests are unreliable measures of llm personality, 2024. URL https://arxiv.org/abs/2309.08163
-
[12]
Computing inter-rater reliability for observational data: an overview and tutorial
Kevin A Hallgren. Computing inter-rater reliability for observational data: an overview and tutorial. Tutorials in quantitative methods for psychology, 8 0 (1): 0 23, 2012
work page 2012
-
[13]
T. F. Heston and J. Gillette. Large language models demonstrate distinct personality profiles. Cureus, 17 0 (5): 0 e84706, 2025. URL https://doi.org/10.7759/cureus.84706
- [14]
-
[15]
O. P. John, L. P. Naumann, and C. J. Soto. Paradigm shift to the integrative B ig F ive trait taxonomy. In O. P. John, R. W. Robins, and L. A. Pervin, editors, Handbook of personality: Theory and research, pages 114--158. 3rd edition, 1999
work page 1999
-
[16]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Samuel R. Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Content analysis: An introduction to its methodology
Klaus Krippendorff. Content analysis: An introduction to its methodology. Sage publications, 2018
work page 2018
- [18]
- [19]
-
[20]
Decoding LLM personality measurement: Forced-choice vs
Xiaoyu Li, Haoran Shi, Zengyi Yu, Yukun Tu, and Chanjin Zheng. Decoding LLM personality measurement: Forced-choice vs. L ikert. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computational Linguistics: ACL 2025, pages 9234--9247, Vienna, Austria, July 2025. Association for Computati...
-
[21]
U. Lorenzo-Seva and J. M. F. ten Berge. Tucker's congruence coefficient as a meaningful index of factor similarity. Methodology, 2 0 (2): 0 57--64, 2006
work page 2006
-
[22]
J. Maharjan, R. Jin, J. Zhu, and D. Kenne. Psychometric evaluation of large language model embeddings for personality trait prediction. Journal of Medical Internet Research, 27: 0 e75347, 2025. URL https://doi.org/10.2196/75347
-
[23]
H. W. Marsh, A. J. Morin, P. D. Parker, and G. Kaur. Exploratory structural equation modeling: An integration of the best features of exploratory and confirmatory factor analysis. Annual Review of Clinical Psychology, 10: 0 85--110, 2014
work page 2014
-
[24]
J. Musek. A general factor of personality: Evidence for the B ig O ne in the five-factor model. Journal of Research in Personality, 41 0 (6): 0 1213--1233, 2007
work page 2007
-
[25]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
S. Palan and C. Schitter. Prolific.ac--- A subject pool for online experiments. Journal of Behavioral and Experimental Finance, 17: 0 22--27, 2018
work page 2018
-
[27]
E. Peer, D. Rothschild, A. Gordon, Z. Evernden, and E. Damer. Data quality of platforms and panels for online behavioral research. Behavior Research Methods, 54 0 (4): 0 1643--1662, 2022
work page 2022
-
[28]
Cognitive phantoms in large language models through the lens of latent variables
Sanne Peereboom, Inga Schwabe, and Bennett Kleinberg. Cognitive phantoms in large language models through the lens of latent variables. Computers in Human Behavior: Artificial Humans, 4: 0 100161, May 2025. ISSN 2949-8821. doi:10.1016/j.chbah.2025.100161. URL http://dx.doi.org/10.1016/j.chbah.2025.100161
-
[29]
M. Pellert, C. M. Lechner, C. Wagner, B. Rammstedt, and M. Strohmaier. AI psychometrics: Assessing the psychological profiles of large language models through psychometric inventories. Perspectives on Psychological Science, 19 0 (5): 0 808--826, 2024. URL https://doi.org/10.1177/17456916231214460
-
[30]
Discovering Language Model Behaviors with Model-Written Evaluations
Ethan Perez et al. Discovering language model behaviors with model-written evaluations. arXiv preprint arXiv:2212.09251, 2022. URL https://arxiv.org/abs/2212.09251
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models
Paul R \"o ttger, Hannah Rose Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. XSTest : A test suite for identifying exaggerated safety behaviours in large language models. arXiv preprint arXiv:2308.01263, 2024. URL https://arxiv.org/abs/2308.01263
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Verbosity bias in preference labeling by large language models
Keita Saito, Akifumi Wachi, Koki Wataoka, and Youhei Akimoto. Verbosity bias in preference labeling by large language models. arXiv preprint arXiv:2310.10076, 2023. URL https://arxiv.org/abs/2310.10076
-
[33]
A. Salecha, M. E. Ireland, S. Subramanya, J. Sedoc, L. H. Ungar, and J. C. Eichstaedt. Large language models display human-like social desirability biases in B ig F ive personality surveys. PNAS Nexus, 3 0 (12): 0 pgae533, 2024. URL https://doi.org/10.1093/pnasnexus/pgae533
-
[34]
G. Serapio-Garc \'i a, M. Safdari, C. Crepy, L. Sun, S. Fitz, P. Romero, and M. Matari \'c . Personality traits in large language models. Nature Machine Intelligence, 2025
work page 2025
-
[35]
Towards Understanding Sycophancy in Language Models
Megha Sharma et al. Towards understanding sycophancy in language models. arXiv preprint arXiv:2310.13548, 2023. URL https://arxiv.org/abs/2310.13548
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Judging the judges: A systematic study of position bias in llm-as-a-judge, 2025
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush Vosoughi. Judging the judges: A systematic study of position bias in llm-as-a-judge, 2025. URL https://arxiv.org/abs/2406.07791
-
[37]
Intraclass correlations: uses in assessing rater reliability
Patrick E Shrout and Joseph L Fleiss. Intraclass correlations: uses in assessing rater reliability. Psychological bulletin, 86 0 (2): 0 420, 1979
work page 1979
-
[38]
R. Suzuki and T. Arita. An evolutionary model of personality traits related to cooperative behavior using a large language model. Scientific Reports, 14: 0 5989, 2024. URL https://doi.org/10.1038/s41598-024-55903-y
-
[39]
S. Vazire. Who knows what about a person? T he self--other knowledge asymmetry ( SOKA ) model. Journal of Personality and Social Psychology, 98 0 (2): 0 281--300, 2010
work page 2010
-
[40]
Y. Wang, J. Zhao, D. S. Ones, L. He, and X. Xu. Evaluating the ability of large language models to emulate personality. Scientific Reports, 15: 0 519, 2025. URL https://doi.org/10.1038/s41598-024-84109-5
-
[41]
Self-Preference Bias in LLM-as-a-Judge
Koki Wataoka, Tsubasa Takahashi, and Ryokan Ri. Self-preference bias in llm-as-a-judge, 2025. URL https://arxiv.org/abs/2410.21819
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [42]
- [43]
-
[44]
On calibration of large language models: From response to capability
Sin-Han Yang, Cheng-Kuang Wu, Chieh-Yen Lin, Yun-Nung Chen, Hung-yi Lee, and Shao-Hua Sun. On calibration of large language models: From response to capability. arXiv preprint arXiv:2602.13540, 2026. URL https://arxiv.org/abs/2602.13540
- [45]
-
[46]
L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, and I. Stoica. Judging LLM -as-a-judge with MT-Bench and Chatbot Arena . In NeurIPS 2023, 2023
work page 2023
-
[47]
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2020. URL https://arxiv.org/abs/1909.08593
work page internal anchor Pith review Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.