CLQT: A Closed-Loop, Cost-Aware, Strategy-Consistent Benchmark for Diagnostic Evaluation of LLM Portfolio-Management Agents
Pith reviewed 2026-06-30 06:41 UTC · model grok-4.3
The pith
CLQT reframes LLM portfolio agent evaluation as diagnosis of process competencies rather than ranking by returns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
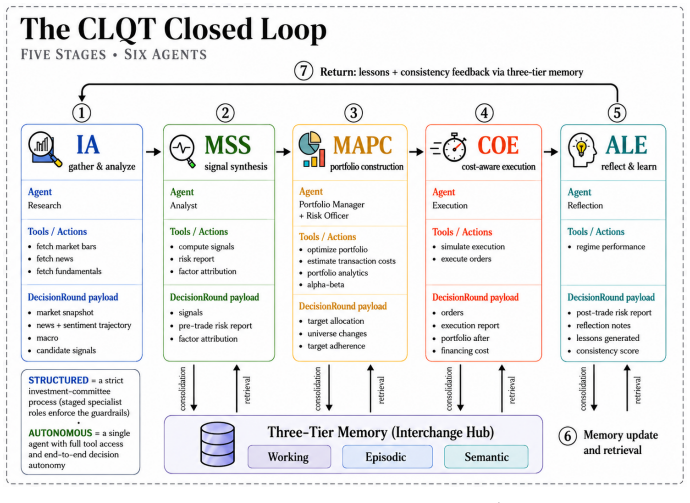
CLQT is a fully closed-loop, cost-aware, strategy-consistent, temporally-gated environment in which agents execute a five-stage cycle (gather, synthesize, allocate, execute, reflect) and emit DecisionRounds sealed into a recompute-verifiable hash chain. From the resulting audit trail the benchmark computes the five-axis APM-CS scorecard (Coherence, Acuity, Composure, Discipline, Reliability), with Coherence partly scored by a held-out LLM, while enforcing institutional transaction and financing costs, time gating, three-tier memory, and mandate-aware synthesis. The same agent can be run as either a constrained committee of roles or a single orchestrator, treating process scaffolding as an ex
What carries the argument
The five-stage cycle together with the APM-CS scorecard and strategy-consistency scoring, which together localize where and why an agent's process succeeds or fails.
If this is right
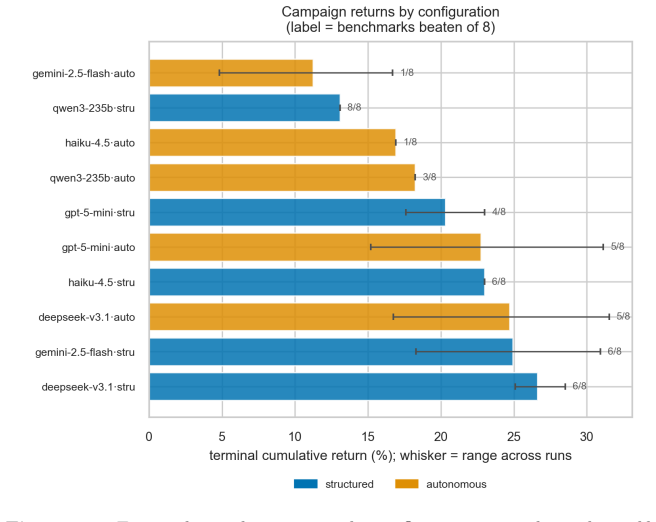
- Process scaffolding (committee versus single orchestrator) becomes an explicit experimental variable whose effect on each scorecard axis can be measured.
- Every reported metric can be recomputed from the sealed DecisionRound trail, eliminating post-hoc leakage.
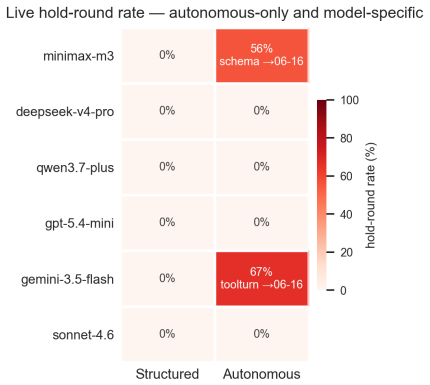
- Validation on contamination-controlled multi-model backtests and live post-cutoff broker data shows the scorecard distinguishes signal from market-path noise.
- The benchmark supplies not a single ranking but a five-axis map that can be extended to new agent architectures or mandates.
Where Pith is reading between the lines
- The same diagnostic structure could be adapted to other sequential, cost-bearing decision domains such as inventory management or energy dispatch.
- Using a held-out LLM for coherence scoring trades one form of self-preference for possible model-specific bias that would need separate calibration.
- Extending the cost models to include slippage from market impact or more complex financing instruments would test whether the current institutional-cost layer is sufficient.
Load-bearing premise
The five-stage cycle, APM-CS scorecard, and strategy-consistency scoring accurately capture sound reasoning and consistent strategy without introducing new forms of leakage or bias.
What would settle it
Re-running the identical agent across multiple distinct market regimes produces APM-CS scores that vary more than the repeated-run noise floor even though the underlying strategy remains unchanged.
Figures

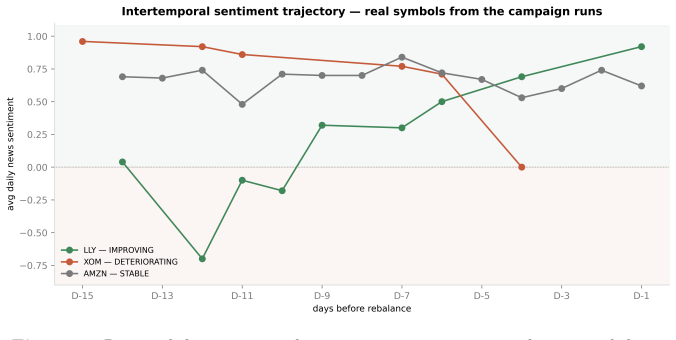
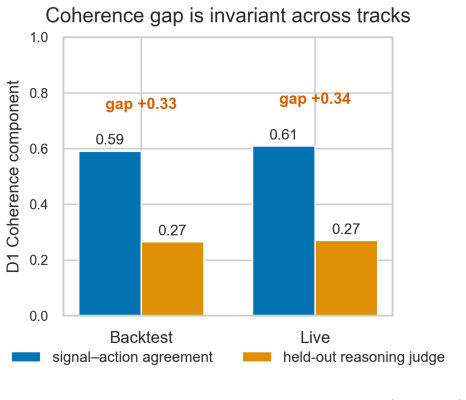
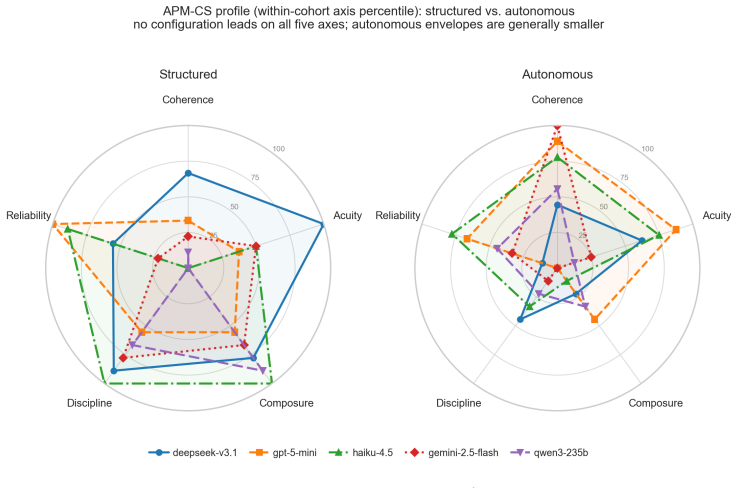
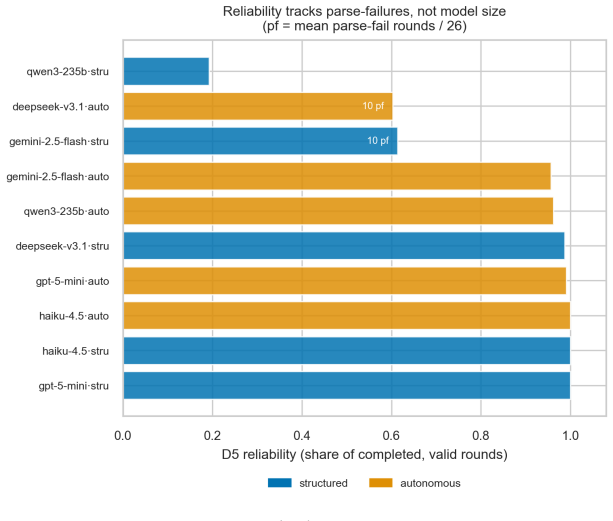
read the original abstract
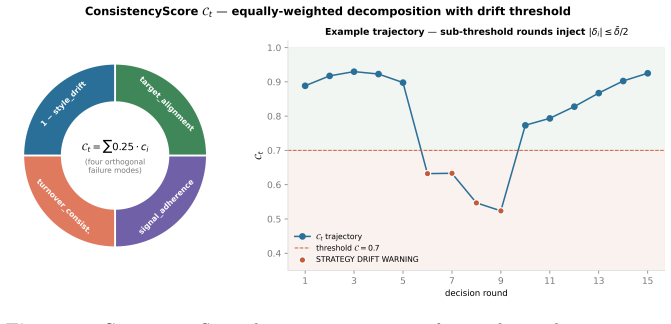
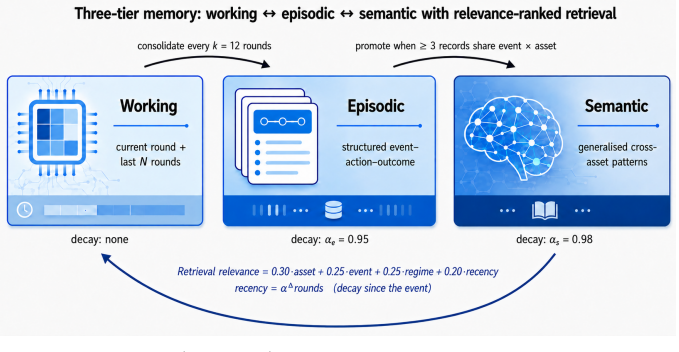
LLM agents are increasingly cast as autonomous portfolio managers, and benchmarks have moved from financial question-answering to sequential trading. Yet most still rank agents by returns over a fixed window -- a weak proxy, since a period's return is dominated by the market path and apparent alpha can dissolve once look-ahead leakage is controlled. Such a ranking certifies neither sound reasoning, nor a consistent strategy, nor a durable edge. We introduce CLQT, which reframes closed-loop trading evaluation as diagnosis rather than ranking: an instrument that localizes where and why an agent's process succeeds or fails. CLQT is a fully closed-loop, cost-aware, strategy-consistent, temporally-gated environment whose agents run a five-stage cycle: gather, synthesize, allocate, execute, reflect. Each round emits a complete DecisionRound sealed into a recompute-verifiable hash chain, so every metric is reconstructable from the trail. Six pillars form the substrate: a hard TimeGate, institutional transaction- and financing-cost modeling, strategy-consistency scoring, three-tier memory, a Model-Context-Protocol tool layer, and mandate-aware synthesis. The same agent runs as a constrained committee of specialized roles or a single full-autonomy orchestrator, making process scaffolding an experimental variable. From the audit trail we compute a five-axis capability scorecard (APM-CS: Coherence, Acuity, Composure, Discipline, Reliability), with Coherence judged partly by a held-out, out-of-cohort LLM to curb self-preference bias. We validate it on a contamination-controlled multi-model backtest with an ablation grid and a live broker track on unseen, post-cutoff data, against a repeated-run noise floor. CLQT separates outcome from capability, yielding not a model ranking but a durable, extensible map of agent competencies and limitations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CLQT, a closed-loop benchmark for diagnostic evaluation of LLM portfolio-management agents. It defines a five-stage cycle (gather, synthesize, allocate, execute, reflect) supported by six pillars (hard TimeGate, institutional cost modeling, strategy-consistency scoring, three-tier memory, Model-Context-Protocol tool layer, mandate-aware synthesis). Agents may run as role-specialized committees or single orchestrators. Every DecisionRound is sealed in a recompute-verifiable hash chain. From the trail the authors derive the APM-CS five-axis scorecard (Coherence scored partly by held-out LLM, plus Acuity, Composure, Discipline, Reliability). Validation consists of a contamination-controlled multi-model backtest with ablation grid plus a live broker track on post-cutoff data, with the goal of producing a map of competencies rather than return-based rankings.
Significance. If the claimed separation of process quality from outcome holds, CLQT would advance evaluation methodology for sequential LLM agents by replacing confounded return rankings with reconstructable, cost-aware diagnostics. Explicit strengths include the hash-chain audit trail enabling full metric recomputation, use of a held-out LLM for Coherence to mitigate self-preference, an ablation grid, and live testing on unseen data; these elements directly support reproducibility and robustness claims.
major comments (2)
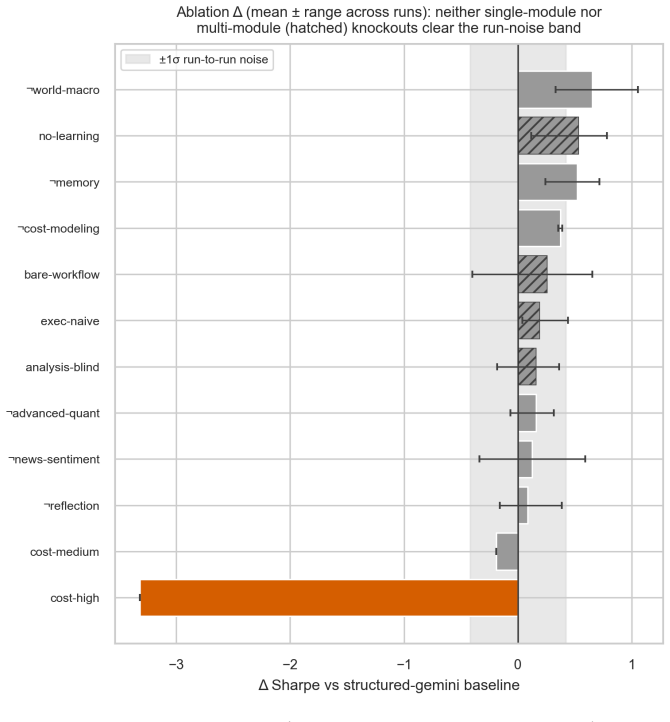
- [Abstract] Abstract: the central claim that the APM-CS scorecard 'separates outcome from capability' is load-bearing, yet the text supplies no reported correlation coefficients, partial-dependence plots, or noise-floor comparisons between the five axes and realized P&L after cost and time-gate controls; without these the independence assertion cannot be verified from the validation description.
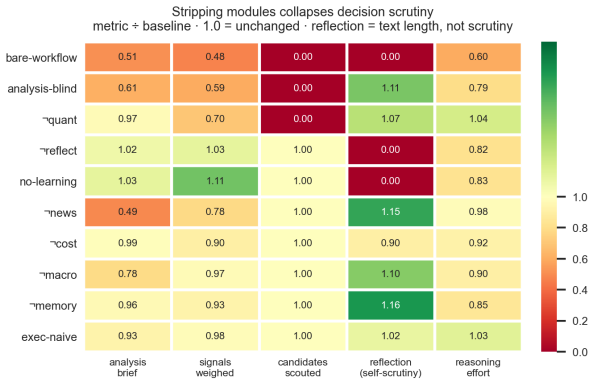
- [Validation] The pillars and validation description: strategy-consistency scoring and mandate-aware synthesis are defined relative to the same agent behaviors that the scorecard is meant to diagnose; the manuscript must show (e.g., via an explicit equation or ablation) that this does not introduce circular dependence that would make the separation claim tautological.
minor comments (2)
- [Abstract] Abstract: 'Model-Context-Protocol' is abbreviated MCP on first use without expansion; define acronyms at first appearance.
- The five-stage cycle is introduced without a diagram or pseudocode listing the exact inputs/outputs of each stage; adding either would clarify how the hash chain captures the full trace.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the separation claims in CLQT. We address each major point below and outline targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the APM-CS scorecard 'separates outcome from capability' is load-bearing, yet the text supplies no reported correlation coefficients, partial-dependence plots, or noise-floor comparisons between the five axes and realized P&L after cost and time-gate controls; without these the independence assertion cannot be verified from the validation description.
Authors: We agree that explicit quantitative support for independence strengthens the central claim. The current validation already includes a repeated-run noise floor and ablation grid on post-cutoff data, but does not report axis-to-P&L correlations. In revision we will add (i) Pearson and Spearman correlations between each APM-CS axis and net P&L after TimeGate and cost controls, (ii) partial-dependence plots of P&L versus each axis, and (iii) direct comparison of these quantities against the empirical noise floor. These additions will appear in a new subsection of the validation results. revision: yes
-
Referee: [Validation] The pillars and validation description: strategy-consistency scoring and mandate-aware synthesis are defined relative to the same agent behaviors that the scorecard is meant to diagnose; the manuscript must show (e.g., via an explicit equation or ablation) that this does not introduce circular dependence that would make the separation claim tautological.
Authors: Strategy-consistency scoring is a deterministic, hash-recomputable function applied to the sealed DecisionRound trail that quantifies deviation from the pre-declared mandate; it is not derived from the APM-CS axes. Mandate-aware synthesis is an input constraint on the gather/synthesize stages, not an output metric. To eliminate any appearance of circularity we will insert an explicit equation in Section 3.4 that defines each APM-CS axis as a function of the trail variables excluding the consistency score itself, together with an ablation that recomputes the five-axis scorecard after removing the consistency pillar. The revised text will also state that the remaining axes remain stable under this removal. revision: yes
Circularity Check
No circularity: framework defines new process-based metrics without reduction to inputs by construction
full rationale
The paper introduces CLQT as a diagnostic benchmark built around an explicit five-stage cycle and the APM-CS scorecard computed from the audit trail, with Coherence using a held-out LLM. These components are presented as definitional design choices for separating process from outcome, not as derived predictions or fitted parameters renamed as results. No equations, self-citations, or uniqueness theorems are invoked that would make the claimed separation equivalent to the inputs by construction. The derivation chain is self-contained as an instrument definition, with the independence claim resting on the proposed structure rather than circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five-stage cycle models agent decision processes without introducing new leakage
invented entities (1)
-
APM-CS five-axis scorecard
no independent evidence
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
- [4]
- [5]
-
[6]
Can LLM-based Financial Investing Strategies Outperform the Market in Long Run?
Li, W. W., Kim, H., Cucuringu, M., & Ma, T. (2025). Can LLM-based Financial In- vesting Strategies Outperform the Market in Long Run? (FINSABER). arXiv:2505.07078
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Zhao, Y., Chen, S., & Su, N. (2026). PortBench: A Correlation-Aware, Full-Pipeline Benchmark for LLM-Driven Portfolio Management. arXiv:2605.27887
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [8]
-
[9]
Zhu, T., et al. (2026). From Knowing to Doing: A Memory-Controlled Benchmark for LLM Trading Agents on Stock Markets. arXiv:2605.28359
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [10]
- [11]
- [12]
-
[13]
Zheng, L., et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.NeurIPS Datasets & Benchmarks. arXiv:2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Liang, P., et al. (2022). Holistic Evaluation of Language Models (HELM).TMLR (2023). arXiv:2211.09110
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Yao, S., et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. ICLR. arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Shinn, N., et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning.NeurIPS. arXiv:2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Generative Agents: Interactive Simulacra of Human Behavior
Park, J. S., et al. (2023). Generative Agents: Interactive Simulacra of Human Behavior.UIST. arXiv:2304.03442
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Packer, C., et al. (2023). MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Sumers, T., Yao, S., Narasimhan, K., & Griffiths, T. (2024). Cognitive Architectures for Language Agents (CoALA).TMLR. arXiv:2309.02427. [20]Anthropic(2024). ModelContextProtocol(MCP):AnOpenStandardforConnecting AI Assistants to Tools and Data. https://modelcontextprotocol.io
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Qin, Y., et al. (2024). ToolLLM: Facilitating LLMs to Master 16000+ Real-World APIs.ICLR. arXiv:2307.16789
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Hong, S., et al. (2024). MetaGPT: Meta Programming for a Multi-Agent Collabora- tive Framework.ICLR. arXiv:2308.00352
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Liu, X., et al. (2024). AgentBench: Evaluating LLMs as Agents.ICLR. arXiv:2308.03688
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Yao, S., et al. (2024).τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. arXiv:2406.12045
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Anderson, J. R. (1983).The Architecture of Cognition.Harvard University Press. (ACT*; declarative vs. procedural knowledge, compilation through practice.)
1983
-
[25]
Boyd, J. R. (1987).A Discourse on Winning and Losing.Air University.(The OODA decision cycle.)
1987
-
[26]
Almgren, R., & Chriss, N. (2001). Optimal execution of portfolio transactions. Journal of Risk, 3(2), 5–39. 46 Appendix A: Cost Tier Parameterizations Tier Spread (bps) Commission (bps) Slippage (bps) Borrow (ann bps) Impact Model zero 0 0 0 0 none low(default)2.0 0.5 1.0 30 square_root medium 3.0 1.0 2.0 50 square_root high 8.0 3.0 5.0 100 almgren_chriss...
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.