M3D-GAN: Multi-Modal Multi-Domain Translation with Universal Attention
Pith reviewed 2026-05-25 00:12 UTC · model grok-4.3
The pith
M3D-GAN uses modality subnets plus a universal attention module to translate between text, images, and speech in one model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
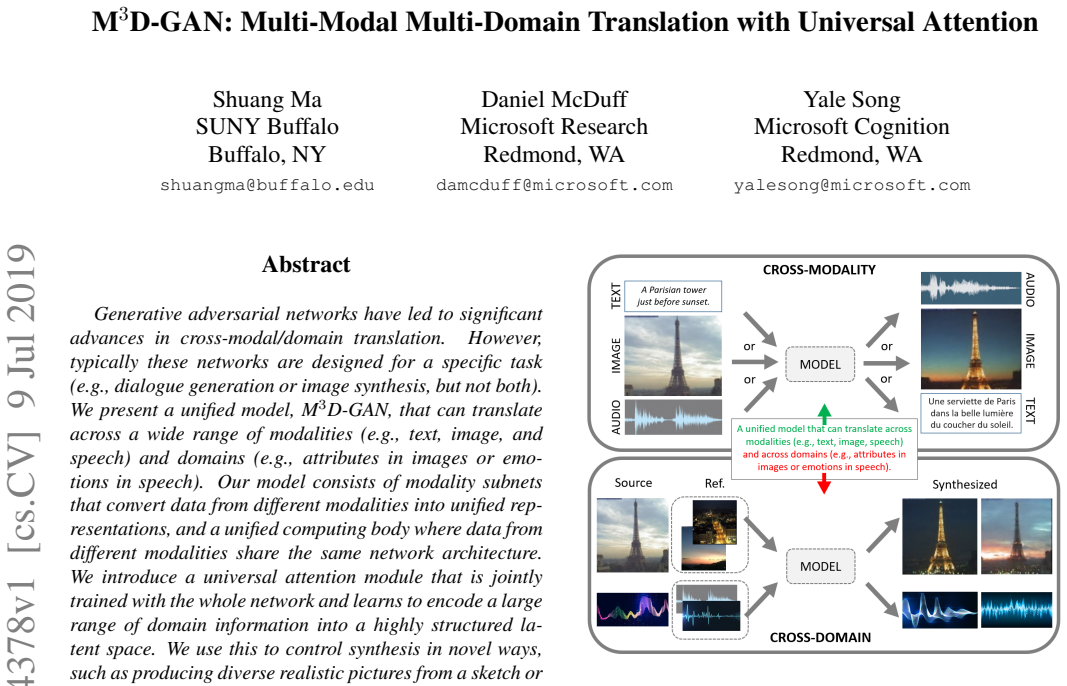
M3D-GAN consists of modality subnets that convert data from different modalities into unified representations and a unified computing body where data from different modalities share the same network architecture, together with a universal attention module that is jointly trained with the whole network and learns to encode a large range of domain information into a highly structured latent space used to control synthesis.
What carries the argument
The universal attention module, jointly trained with the network, that encodes domain information into a structured latent space for controlling cross-modal outputs.
If this is right
- Enables control of synthesis outputs such as generating diverse realistic images from a sketch.
- Allows varying the emotion of synthesized speech while keeping other attributes fixed.
- Supports multiple translation tasks including image-to-image, text-to-image, text-to-speech, speech recognition, and machine translation within one model.
- Removes the requirement to design separate networks for each modality pair or domain shift.
Where Pith is reading between the lines
- The shared latent space could support adding new modalities with only new subnets rather than retraining the core body.
- If the attention module truly separates domain factors, the model might permit zero-shot domain adaptation by swapping attention codes alone.
- A single trained instance might reduce total compute compared with maintaining separate models for each modality pair.
Load-bearing premise
Modality subnets feeding a shared network plus one universal attention module can integrate and translate between dissimilar modalities such as text, image, and speech without requiring task-specific changes or large performance losses.
What would settle it
A direct comparison showing that M3D-GAN requires substantial task-specific architectural changes or underperforms specialized models by a large margin on cross-modal tasks such as text-to-speech or image captioning.
Figures







read the original abstract
Generative adversarial networks have led to significant advances in cross-modal/domain translation. However, typically these networks are designed for a specific task (e.g., dialogue generation or image synthesis, but not both). We present a unified model, M3D-GAN, that can translate across a wide range of modalities (e.g., text, image, and speech) and domains (e.g., attributes in images or emotions in speech). Our model consists of modality subnets that convert data from different modalities into unified representations, and a unified computing body where data from different modalities share the same network architecture. We introduce a universal attention module that is jointly trained with the whole network and learns to encode a large range of domain information into a highly structured latent space. We use this to control synthesis in novel ways, such as producing diverse realistic pictures from a sketch or varying the emotion of synthesized speech. We evaluate our approach on extensive benchmark tasks, including image-to-image, text-to-image, image captioning, text-to-speech, speech recognition, and machine translation. Our results show state-of-the-art performance on some of the tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces M3D-GAN, a unified GAN architecture for multi-modal multi-domain translation across text, images, and speech. It consists of modality-specific subnets that map inputs to unified representations, a shared network body, and a jointly trained universal attention module that structures the latent space for controllable synthesis. The model is evaluated on image-to-image translation, text-to-image synthesis, image captioning, text-to-speech, speech recognition, and machine translation, with claims of state-of-the-art performance on some tasks.
Significance. If the experimental claims hold with rigorous baselines and analysis, the work would offer a notable contribution toward unified cross-modal generative models, potentially reducing the proliferation of task-specific architectures. The universal attention module's role in encoding diverse domain information could enable flexible control mechanisms not commonly available in prior modality-specific GANs.
major comments (2)
- [Abstract; likely §3 (Model Architecture)] Abstract and architecture description: The central claim that M3D-GAN translates across modalities 'without requiring task-specific architectural changes' is load-bearing for the paper's novelty, yet the design explicitly introduces modality subnets (one per modality: text, image, speech) to produce unified representations before the shared body. These subnets constitute per-modality components whose complexity is not quantified, raising the possibility that unification is achieved only by delegating modality-specific engineering to the subnets rather than eliminating it.
- [Abstract; likely §5 (Experiments)] Experimental section (likely §5): The abstract asserts 'state-of-the-art performance on some of the tasks' across six distinct benchmarks but provides no quantitative metrics, baseline comparisons, or error bars. Without these details, it is impossible to verify whether the unified architecture delivers the claimed gains or whether performance relies on the modality subnets in ways that undermine the 'unified without task-specific changes' assertion.
minor comments (2)
- [likely §3.2 or §4] Notation for the universal attention module and its integration with the shared body should be formalized with equations to allow reproducibility and to clarify how domain information is encoded into the latent space.
- [Abstract; likely §5] The abstract lists six evaluation tasks but does not indicate which ones achieve SOTA; the experimental section should explicitly map tasks to reported metrics and baselines.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and indicate whether revisions will be made.
read point-by-point responses
-
Referee: Abstract and architecture description: The central claim that M3D-GAN translates across modalities 'without requiring task-specific architectural changes' is load-bearing for the paper's novelty, yet the design explicitly introduces modality subnets (one per modality: text, image, speech) to produce unified representations before the shared body. These subnets constitute per-modality components whose complexity is not quantified, raising the possibility that unification is achieved only by delegating modality-specific engineering to the subnets rather than eliminating it.
Authors: The manuscript does introduce modality-specific subnets to map each input modality to a common representation space; this is stated explicitly in the abstract and Section 3. The claim of operating 'without requiring task-specific architectural changes' refers to the shared computing body and universal attention module, which use identical architectures and parameters for all modalities after the initial mapping. The subnets are modality-specific input/output adapters whose design is described in the paper, though their parameter counts relative to the shared body are not tabulated. We will add a clarifying sentence in the abstract and Section 3 to distinguish the role of the subnets from the unified core. revision: partial
-
Referee: Experimental section (likely §5): The abstract asserts 'state-of-the-art performance on some of the tasks' across six distinct benchmarks but provides no quantitative metrics, baseline comparisons, or error bars. Without these details, it is impossible to verify whether the unified architecture delivers the claimed gains or whether performance relies on the modality subnets in ways that undermine the 'unified without task-specific changes' assertion.
Authors: Abstracts conventionally omit detailed numerical results. The full experimental section (Section 5) reports quantitative metrics, baseline comparisons, and results across the six tasks. The abstract's phrasing is therefore supported by the body of the paper. No change to the abstract is required, but we can insert a parenthetical reference to the experimental tables if the editor prefers. revision: no
Circularity Check
No significant circularity; empirical results independent of model definition
full rationale
The paper describes an empirical GAN architecture for multi-modal translation and reports benchmark performance. No mathematical derivations, equations, or first-principles predictions appear in the provided text. The central claim of unification is supported by experimental evaluation on external tasks (image-to-image, text-to-image, etc.), which are not forced by construction from the architecture description. Modality subnets are presented as part of the model design rather than as a renamed prediction or self-referential fit. No self-citation chains or ansatzes reduce the reported results to tautology. This is a standard empirical ML paper with self-contained experimental validation.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard GAN training assumptions including convergence of adversarial objectives
invented entities (1)
-
universal attention module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our model consists of modality subnets that convert data from different modalities into unified representations, and a unified computing body where data from different modalities share the same network architecture. We introduce a universal attention module that is jointly trained with the whole network and learns to encode a large range of domain information into a highly structured latent space.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We aim to model a variety of domain information from the target distribution... by means of information bottleneck [25].
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, Q. Cheng, G. Chen, J. Chen, J. Chen, Z. Chen, M. Chrzanowski, A. Coates, G. Diamos, K. Ding, N. Du, E. Elsen, J. Engel, W. Fang, L. Fan, C. Fougner, L. Gao, C. Gong, A. Hannun, T. Han, L. V . Jo- hannes, B. Jiang, C. Ju, B. Jun, P. LeGresley, L. Lin, J. Li...
work page 2016
-
[2]
Neural Machine Translation by Jointly Learning to Align and Translate
D. Bahdanau, K. Cho, and Y . Bengio. Neural machine translation by jointly learning to align and translate. CoRR, abs/1409.0473, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[3]
J. Bao, D. Chen, F. Wen, H. Li, and G. Hua. Cvae- gan: Fine-grained image generation through asym- metric training. In 2017 IEEE International Confer- ence on Computer Vision (ICCV), 2017
work page 2017
-
[4]
S. Benaim and L. Wolf. One-sided unsupervised do- main mapping. In Proceedings of the 31st Interna- tional Conference on Neural Information Processing Systems, NIPS’17, 2017
work page 2017
-
[5]
X. Chen, H. Fang, T. Lin, R. Vedantam, S. Gupta, P. Doll´ar, and C. L. Zitnick. Microsoft COCO cap- tions: Data collection and evaluation server. CoRR, 2015
work page 2015
-
[6]
Y . Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo. Stargan: Unified generative adversarial net- works for multi-domain image-to-image translation. In The IEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), June 2018
work page 2018
-
[7]
A. Farhadi, I. Endres, D. Hoiem, and D. Forsyth. De- scribing objects by their attributes. In CVPR, 2009
work page 2009
-
[8]
M. H. Giard and F. Peronnet. Auditory-visual integra- tion during multimodal object recognition in humans: a behavioral and electrophysiological study. Journal of cognitive neuroscience, 11(5):473–490, 1999
work page 1999
-
[9]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Ben- gio. Generative adversarial nets. In NIPS. 2014
work page 2014
-
[10]
D. Griffin and J. Lim. Signal estimation from modified short-time fourier transform. IEEE Transactions on Acoustics, Speech, and Signal Processing, 32(2):236– 243, April 1984
work page 1984
- [11]
- [12]
-
[13]
P.-Y . Laffont, Z. Ren, X. Tao, C. Qian, and J. Hays. Transient attributes for high-level understanding and editing of outdoor scenes. SIGGRAPH, 33(4), 2014
work page 2014
- [14]
-
[15]
S. Ma, J. Fu, C. Wen Chen, and T. Mei. Da-gan: Instance-level image translation by deep attention gen- erative adversarial networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
work page 2018
-
[16]
S. Ma, D. Mcduff, and Y . Song. A generative adver- sarial network for style modeling in a text-to-speech system. In International Conference on Learning Rep- resentations, 2019
work page 2019
-
[17]
Conditional Generative Adversarial Nets
M. Mirza and S. Osindero. Conditional generative ad- versarial nets. arXiv preprint arXiv:1411.1784, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [18]
- [19]
-
[20]
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur. Librispeech: An ASR corpus based on public domain audio books. In ICASSP. IEEE, apr 2015
work page 2015
-
[21]
P. Pietrini, M. L. Furey, E. Ricciardi, M. I. Gob- bini, W.-H. C. Wu, L. Cohen, M. Guazzelli, and J. V . Haxby. Beyond sensory images: Object-based repre- sentation in the human ventral pathway. Proceedings of the National Academy of Sciences , 101(15):5658– 5663, 2004
work page 2004
-
[22]
S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee. Generative adversarial text to image synthesis. In Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, 2016
work page 2016
-
[23]
R. J. Skerry-Ryan, E. Battenberg, Y . Xiao, Y . Wang, D. Stanton, J. Shor, R. J. Weiss, R. Clark, and R. A. Saurous. Towards end-to-end prosody transfer for expressive speech synthesis with tacotron. CoRR, abs/1803.09047, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Y . Taigman, A. Polyak, and L. Wolf. Unsupervised cross-domain image generation. In ICLR, 2017
work page 2017
-
[25]
The information bottleneck method
N. Tishby, F. C. Pereira, and W. Bialek. The information bottleneck method. arXiv preprint physics/0004057, 2000
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[26]
A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu. Wavenet: A generative model for raw audio. In Arxiv, 2016
work page 2016
-
[27]
A. van den Oord, O. Vinyals, and k. kavukcuoglu. Neural discrete representation learning. In Advances in Neural Information Processing Systems 30. 2017
work page 2017
-
[28]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. In NIPS, 2017
work page 2017
-
[29]
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan. Show and tell: A neural image caption generator. In CVPR, 2015
work page 2015
-
[30]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Be- longie. The Caltech-UCSD Birds-200-2011 Dataset. Technical Report CNS-TR-2011-001, California Insti- tute of Technology, 2011
work page 2011
-
[31]
Y . Wang, D. Stanton, Y . Zhang, R. Ryan, E. Bat- tenberg, J. Shor, Y . Xiao, Y . Jia, F. Ren, and R. A. Saurous. Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis. In ICML, 2018
work page 2018
- [32]
- [33]
- [34]
- [35]
- [36]
-
[37]
J. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent ad- versarial networks. In 2017 IEEE International Con- ference on Computer Vision (ICCV), 2017
work page 2017
-
[38]
J.-Y . Zhu, P. Kr ¨ahenb¨uhl, E. Shechtman, and A. A. Efros. Generative visual manipulation on the natural image manifold. In ECCV, 2016
work page 2016
-
[39]
J.-Y . Zhu, R. Zhang, D. Pathak, T. Darrell, A. A. Efros, O. Wang, and E. Shechtman. Toward multimodal image-to-image translation. In Advances in Neural In- formation Processing Systems 30. 2017. Appendix
work page 2017
-
[40]
• Image→Image: In this task, the source and target are images drawn from two different domains (e.g
Implementation details for each task The inputs and outputs for each task during the training stage and testing stage are listed in Table 4. • Image→Image: In this task, the source and target are images drawn from two different domains (e.g. day→night, edges→photos, etc.). During training, the references are images drawn from a target distribution, and ar...
work page 2011
-
[41]
Discussion • Why we use the modality subnet for multiple tasks, and why this makes it easy to add additional tasks. To use the modality sub-net for multiple tasks aims to avoid designing different networks for each task. For ex- ample, when we conduct the task of image-to-image and image-to-text translation, the input modality for both these tasks are ima...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.