The Surprising Effectiveness of Video Diffusion Models for Hand Motion Reconstruction
Pith reviewed 2026-06-30 05:56 UTC · model grok-4.3
The pith
Video diffusion models enable accurate 4D two-hand pose reconstruction from egocentric video by adapting their learned representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
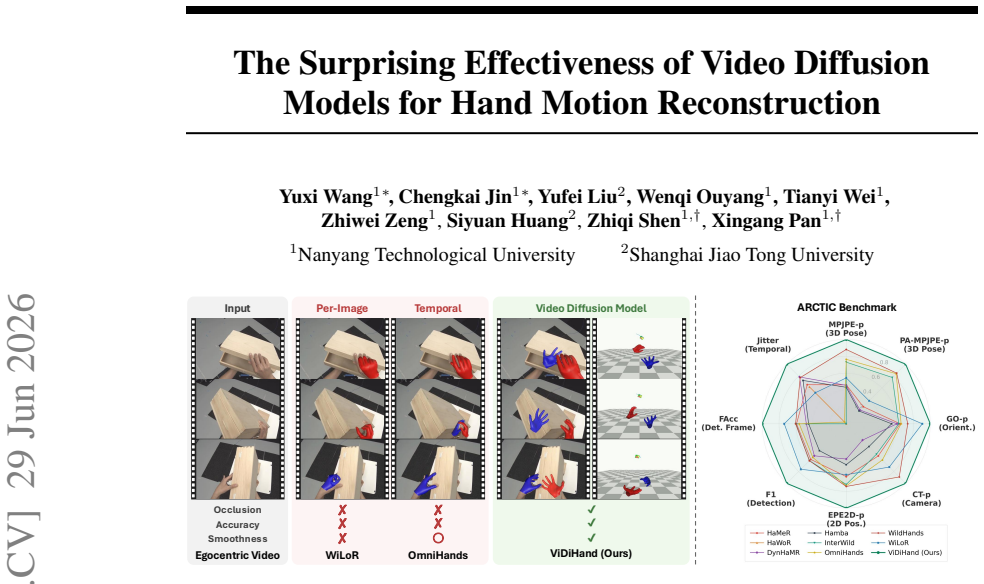
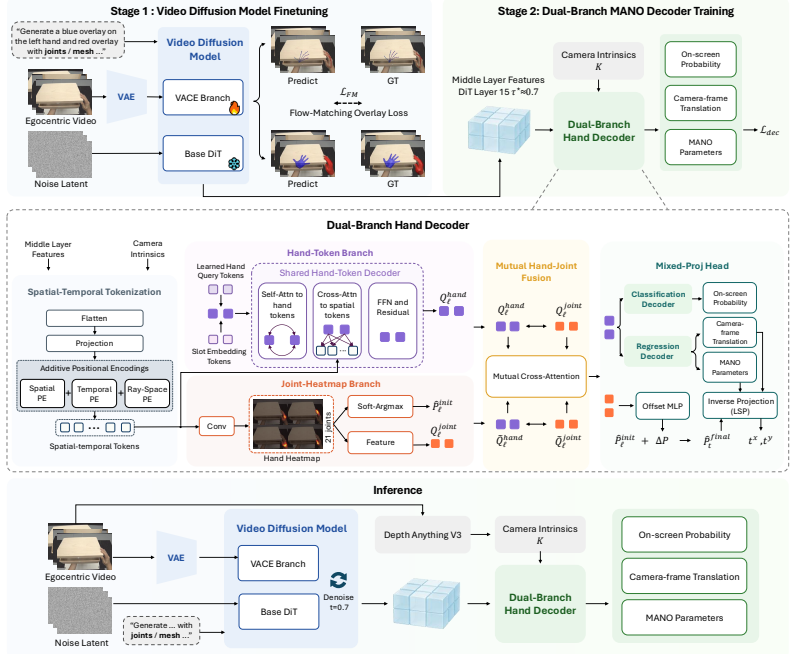
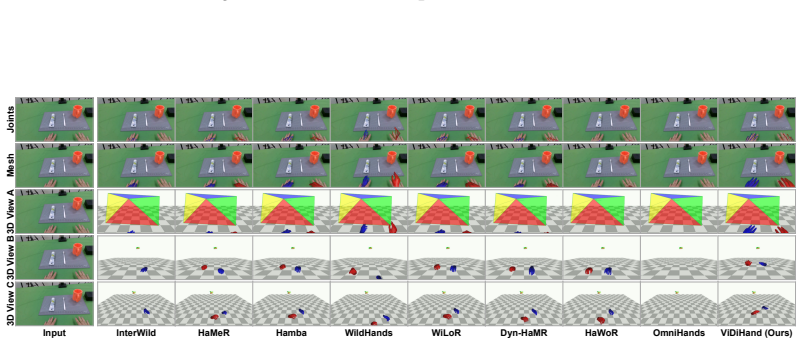
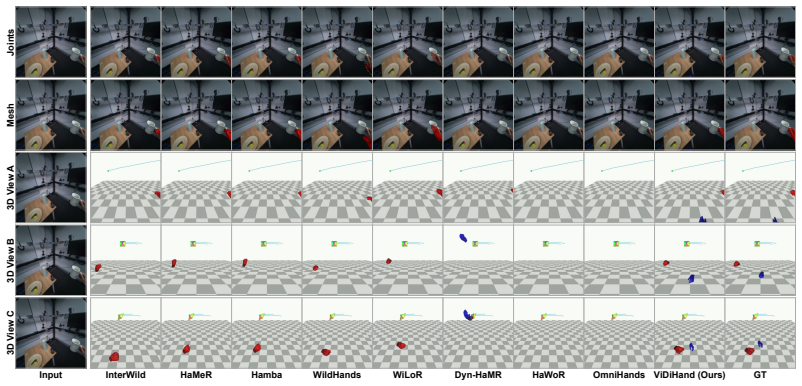
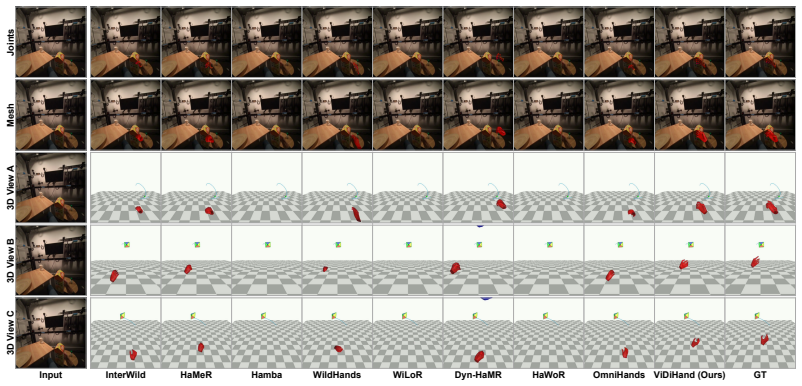
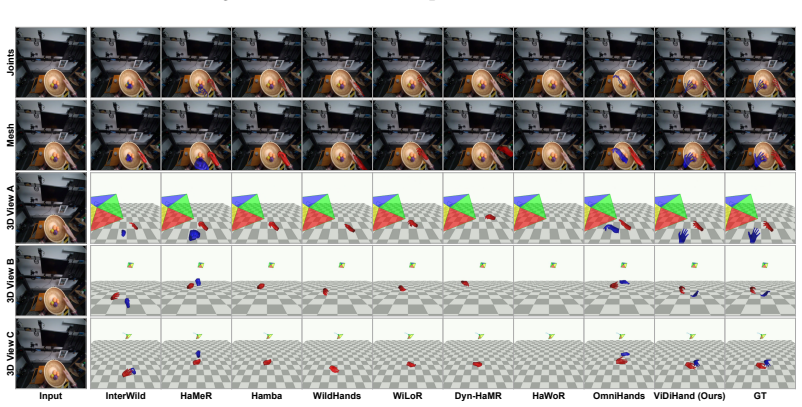
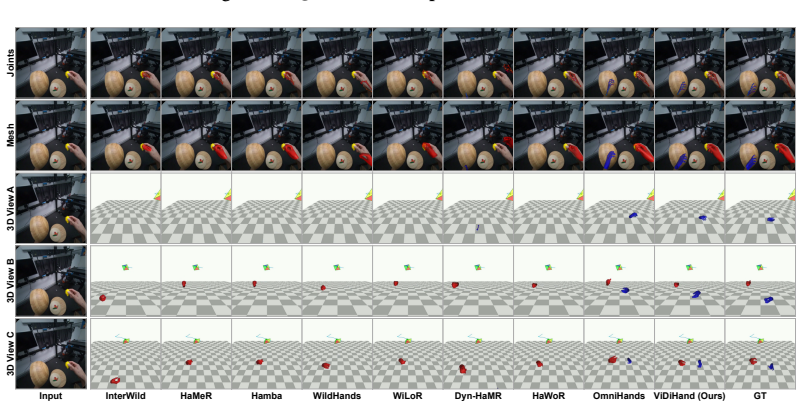
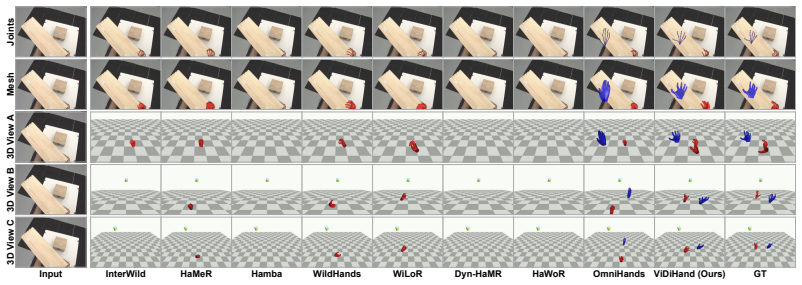
The paper establishes that the representations inside a pretrained video diffusion model, when specialized via a hand-overlay rendering objective, support direct reconstruction of metric-scale 4D two-hand pose from egocentric video. This pipeline operates on full frames and substantially outperforms prior detector-dependent or annotation-limited methods on ARCTIC, HOT3D, and HOI4D, demonstrating that the implicit world knowledge acquired during large-scale video synthesis can be leveraged for hand motion tasks.
What carries the argument
The hand-overlay rendering objective that adapts features from a pretrained video diffusion model for hands while preserving its world priors, followed by a decoder that extracts metric-scale 4D pose.
If this is right
- Hand reconstruction becomes possible directly from full frames without separate detection or inpainting stages.
- Occlusion reasoning and hand-object interaction modeling improve because they draw on priors learned from internet-scale video synthesis.
- Test-time optimization is unnecessary, allowing efficient inference on new sequences.
- Large-scale in-the-wild hand motion data can be collected more scalably to support embodied AI training.
Where Pith is reading between the lines
- The same adaptation strategy could be tested on full-body pose or other articulated objects where video synthesis priors are likely to encode useful 3D structure.
- Performance may continue to improve with larger or more diverse pretrained video diffusion models, suggesting a scaling route for perception tasks.
- The method implies that generative video models already encode extractable 3D and interaction knowledge that future work could probe on additional downstream benchmarks.
Load-bearing premise
The representations acquired by a video diffusion model during general video synthesis can be specialized for hands through a hand-overlay rendering objective without losing the priors needed for accurate metric-scale pose recovery.
What would settle it
An experiment in which ViDiHand fails to outperform prior methods on the reported metrics for ARCTIC, HOT3D, or HOI4D would falsify the central performance claim.
Figures





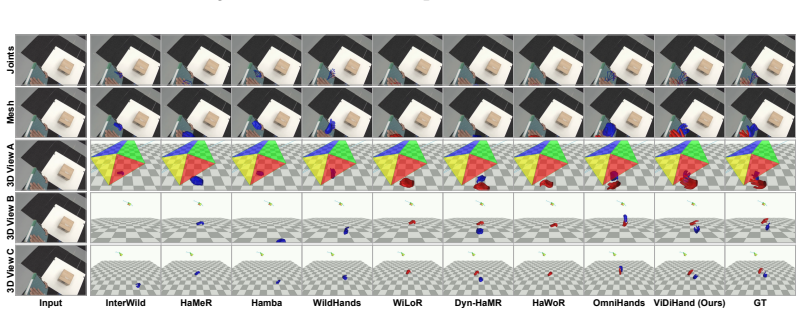



read the original abstract
4D hand motion reconstruction from egocentric video is bottlenecked by clear limitations of existing methods: image-based pipelines depend on a detector that fails under heavy occlusion, while video-based methods rely on temporal modules learned only from scarce hand-pose annotations, a narrow signal insufficient to model motion dynamics, occlusion reasoning, and hand-object interaction. These capabilities, however, are exactly what video generative models must implicitly acquire when trained to synthesize coherent video at internet scale. Motivated by this, we present ViDiHand, which leverages the representations of a pretrained video diffusion model to reconstruct 4D two-hand pose. We adapt it via a hand-overlay rendering objective that specializes its features for hands while preserving its world priors. A decoder then recovers metric-scale pose from the adapted features. The whole pipeline operates directly on full frames--no detector, no infiller, and no test-time optimization. On ARCTIC, HOT3D, and HOI4D, ViDiHand substantially outperforms prior methods, establishing video diffusion models as a powerful new foundation for hand motion reconstruction and a promising route to scalable in-the-wild data collection for embodied AI. Project page: https://vidihand.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ViDiHand, which adapts a pretrained video diffusion model via a hand-overlay rendering objective to reconstruct 4D two-hand pose from egocentric video. It claims that internet-scale video diffusion training implicitly acquires occlusion reasoning, motion dynamics, and hand-object interaction priors that can be specialized for hands without erasure, enabling a detector-free, optimization-free pipeline that substantially outperforms prior methods on ARCTIC, HOT3D, and HOI4D.
Significance. If validated, the result would be significant for establishing video diffusion models as a foundation for hand motion reconstruction, addressing key bottlenecks in image-based detectors and annotation-scarce video methods. It is credited for the direct full-frame operation and the focus on hand-object interaction datasets. The approach suggests a scalable route to in-the-wild data for embodied AI.
major comments (1)
- [Experiments] Experiments/Results sections: No ablation is presented that trains a decoder on the identical hand-overlay rendering objective but using features from a non-diffusion video backbone (or a randomly initialized encoder). This comparison is load-bearing for the central claim that diffusion priors survive adaptation and drive the outperformance, as opposed to the objective or decoder alone producing the gains.
minor comments (1)
- [Abstract] Abstract: The claim of 'substantial outperformance' is stated without any quantitative metrics, baseline names, or error values, which delays assessment of the result magnitude.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comment. We address it directly below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments/Results sections: No ablation is presented that trains a decoder on the identical hand-overlay rendering objective but using features from a non-diffusion video backbone (or a randomly initialized encoder). This comparison is load-bearing for the central claim that diffusion priors survive adaptation and drive the outperformance, as opposed to the objective or decoder alone producing the gains.
Authors: We agree this ablation is important for isolating whether the performance gains stem from the diffusion priors rather than the hand-overlay rendering objective or decoder architecture alone. The original submission did not include it. In the revised manuscript we will add results training the identical decoder on the same objective but using features from (i) a randomly initialized video encoder and (ii) a non-diffusion video backbone (e.g., a 3D ResNet or I3D pretrained on Kinetics). These controls will clarify the contribution of the adapted diffusion representations. revision: yes
Circularity Check
No circularity: empirical method with external pretrained backbone
full rationale
The paper advances an empirical pipeline that fine-tunes a publicly available pretrained video diffusion model via a hand-overlay rendering loss and decodes pose from the resulting features. No equations, parameter-fitting steps, or derivations appear in the provided text; performance is measured on independent external datasets (ARCTIC, HOT3D, HOI4D). The central motivation—that diffusion models acquire occlusion and interaction priors—is presented as a hypothesis tested by comparative results rather than a self-referential definition or fitted-input prediction. No self-citation chains or uniqueness theorems are invoked to close the argument. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
HOT3D: Hand and object tracking in 3D from egocentric multi-view videos
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Shangchen Han, Fan Zhang, Linguang Zhang, Jade Fountain, Edward Miller, Selen Basol, Richard Newcombe, Robert Wang, Jakob Julian Engel, and Tomas Hodan. HOT3D: Hand and object tracking in 3D from egocentric multi-view videos. InIEEE/CVF Conference on Computer Vision and Pattern Recognit...
2025
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Hamba: Single-view 3D hand reconstruction with graph-guided bi-scanning mamba
Haoye Dong, Aviral Chharia, Wenbo Gou, Francisco Vicente Carrasco, and Fernando De la Torre. Hamba: Single-view 3D hand reconstruction with graph-guided bi-scanning mamba. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[4]
Hmp: Hand motion priors for pose and shape estimation from video
Enes Duran, Muhammed Kocabas, Vasileios Choutas, Zicong Fan, and Michael J Black. Hmp: Hand motion priors for pose and shape estimation from video. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 6353–6363, 2024
2024
-
[5]
Black, and Otmar Hilliges
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J. Black, and Otmar Hilliges. ARCTIC: A dataset for dexterous bimanual hand- object manipulation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[6]
Qichen Fu, Xingyu Liu, Ran Xu, Juan Carlos Niebles, and Kris M. Kitani. Deformer: Dynamic fusion transformer for robust hand pose estimation, 2023
2023
-
[7]
Valentin Gabeur, Shangbang Long, Songyou Peng, Paul V oigtlaender, Shuyang Sun, Yanan Bao, Karen Truong, Zhicheng Wang, Wenlei Zhou, Jonathan T. Barron, Kyle Genova, Nithish Kannen, Sherry Ben, Yandong Li, Mandy Guo, Suhas Yogin, Yiming Gu, Huizhong Chen, Oliver Wang, Saining Xie, Howard Zhou, Kaiming He, Thomas Funkhouser, Jean-Baptiste Alayrac, and Radu...
2026
-
[8]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[9]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
Ryan Hoque, Peide Huang, David J Yoon, Mouli Sivapurapu, and Jian Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Zixuan Huang, Xiang Li, Zhaoyang Lv, and James M. Rehg. How much 3d do video foundation models encode?, 2025
2025
-
[11]
V ACE: All-in- one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. V ACE: All-in- one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17191–17202, 2025
2025
-
[12]
Egomimic: Scaling imitation learning via egocentric video
Simar Kareer, Dhruv Patel, Ryan Punamiya, Pranay Mathur, Shuo Cheng, Chen Wang, Judy Hoffman, and Danfei Xu. Egomimic: Scaling imitation learning via egocentric video. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13226–13233. IEEE, 2025
2025
-
[13]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Kon- rad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. Oral
2024
-
[14]
Omnihands: Towards robust 4d hand mesh recovery via a versatile transformer, 2024
Dixuan Lin, Yuxiang Zhang, Mengcheng Li, Wei Jing, Qi Yan, Qianying Wang, Yebin Liu, and Hongwen Zhang. Omnihands: Towards robust 4d hand mesh recovery via a versatile transformer, 2024. 31
2024
-
[15]
HOI4D: A 4D egocentric dataset for category-level human-object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. HOI4D: A 4D egocentric dataset for category-level human-object interaction. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[16]
Bringing inputs to shared domains for 3D interacting hands recovery in the wild
Gyeongsik Moon. Bringing inputs to shared domains for 3D interacting hands recovery in the wild. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[17]
Emergent temporal correspondences from video diffusion transformers, 2025
Jisu Nam, Soowon Son, Dahyun Chung, Jiyoung Kim, Siyoon Jin, Junhwa Hur, and Seungryong Kim. Emergent temporal correspondences from video diffusion transformers, 2025
2025
-
[18]
Reconstructing hands in 3d with transformers
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. Reconstructing hands in 3d with transformers. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[19]
WiLoR: End-to-end 3D hand localization and reconstruction in-the-wild
Rolandos Alexandros Potamias, Jinglei Zhang, Jiankang Deng, and Stefanos Zafeiriou. WiLoR: End-to-end 3D hand localization and reconstruction in-the-wild. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[20]
3D hand pose estimation in everyday egocentric images
Aditya Prakash, Ruisen Tu, Matthew Chang, and Saurabh Gupta. 3D hand pose estimation in everyday egocentric images. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[21]
Javier Romero, Dimitrios Tzionas, and Michael J. Black. Embodied hands: Modeling and capturing hands and bodies together.ACM Transactions on Graphics (TOG), 36(6), 2017
2017
-
[22]
Xperience-10m: A large-scale egocentric multimodal dataset with structured 3d/4d annotations, 2026
Ropedia. Xperience-10m: A large-scale egocentric multimodal dataset with structured 3d/4d annotations, 2026. Dataset
2026
-
[23]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
2025
-
[24]
Repurposing video diffusion transformers for robust point tracking, 2025
Soowon Son, Honggyu An, Chaehyun Kim, Hyunah Ko, Jisu Nam, Dahyun Chung, Siyoon Jin, Jung Yi, Jaewon Min, Junhwa Hur, and Seungryong Kim. Repurposing video diffusion transformers for robust point tracking, 2025
2025
-
[25]
Emer- gent correspondence from image diffusion
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emer- gent correspondence from image diffusion. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[26]
Polanía, Yi Yang, Chuhan Zhang, Rishabh Kabra, Anurag Arnab, and Mehdi S
Pedro Vélez, Luisa F. Polanía, Yi Yang, Chuhan Zhang, Rishabh Kabra, Anurag Arnab, and Mehdi S. M. Sajjadi. From image to video: An empirical study of diffusion representations. In IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[27]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. Alibaba Group
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Yuxi Wang, Wenqi Ouyang, Tianyi Wei, Yi Dong, Zhiqi Shen, and Xingang Pan. Hand2world: Autoregressive egocentric interaction generation via free-space hand gestures.arXiv preprint arXiv:2602.09600, 2026
-
[29]
Sun, Ashley Neall, Tong Wu, Shengqu Cai, and Gordon Wetzstein
Linxi Xie, Lisong C. Sun, Ashley Neall, Tong Wu, Shengqu Cai, and Gordon Wetzstein. Generated reality: Human-centric world simulation using interactive video generation with hand and camera control, 2026
2026
-
[30]
Egovla: Learning vision-language-action models from egocentric human videos, 2025
Ruihan Yang, Qinxi Yu, Yecheng Wu, Rui Yan, Borui Li, An-Chieh Cheng, Xueyan Zou, Yunhao Fang, Xuxin Cheng, Ri-Zhao Qiu, Hongxu Yin, Sifei Liu, Song Han, Yao Lu, and Xiaolong Wang. Egovla: Learning vision-language-action models from egocentric human videos, 2025. 32
2025
-
[31]
CogVideoX: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. CogVideoX: Text-to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[32]
Yufei Ye, Yao Feng, Omid Taheri, Haiwen Feng, Shubham Tulsiani, and Michael J. Black. Predicting 4d hand trajectory from monocular videos, 2025
2025
-
[33]
Dyn-HaMR: Recovering 4D interacting hand motion from a dynamic camera
Zhengdi Yu, Stefanos Zafeiriou, and Tolga Birdal. Dyn-HaMR: Recovering 4D interacting hand motion from a dynamic camera. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[34]
Denoise to track: Harnessing video diffusion priors for robust correspondence, 2025
Tianyu Yuan, Yuanbo Yang, Lin-Zhuo Chen, Yao Yao, and Zhuzhong Qian. Denoise to track: Harnessing video diffusion priors for robust correspondence, 2025
2025
-
[35]
Oakink2: A dataset of bimanual hands-object manipulation in complex task completion, 2024
Xinyu Zhan, Lixin Yang, Yifei Zhao, Kangrui Mao, Hanlin Xu, Zenan Lin, Kailin Li, and Cewu Lu. Oakink2: A dataset of bimanual hands-object manipulation in complex task completion, 2024
2024
-
[36]
HaWoR: World- space hand motion reconstruction from egocentric videos
Jinglei Zhang, Jiankang Deng, Chao Ma, and Rolandos Alexandros Potamias. HaWoR: World- space hand motion reconstruction from egocentric videos. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2025
2025
-
[37]
Egoscale: Scaling dexterous manipulation with diverse egocentric human data, 2026
Ruijie Zheng, Dantong Niu, Yuqi Xie, Jing Wang, Mengda Xu, Yunfan Jiang, Fernando Castañeda, Fengyuan Hu, You Liang Tan, Letian Fu, Trevor Darrell, Furong Huang, Yuke Zhu, Danfei Xu, and Linxi Fan. Egoscale: Scaling dexterous manipulation with diverse egocentric human data, 2026. 33
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.