SWE-Router: Routing in Multi-turn Agentic Software Engineering Tasks
Pith reviewed 2026-07-02 18:17 UTC · model grok-4.3
The pith
SWE-Router conditions routing decisions on a partial trajectory from cheap-model exploration to achieve Bayes-optimal outcomes in multi-turn agentic software engineering tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
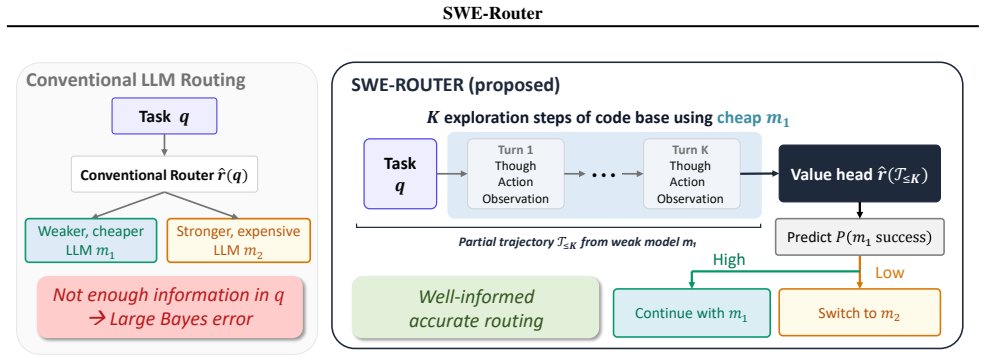
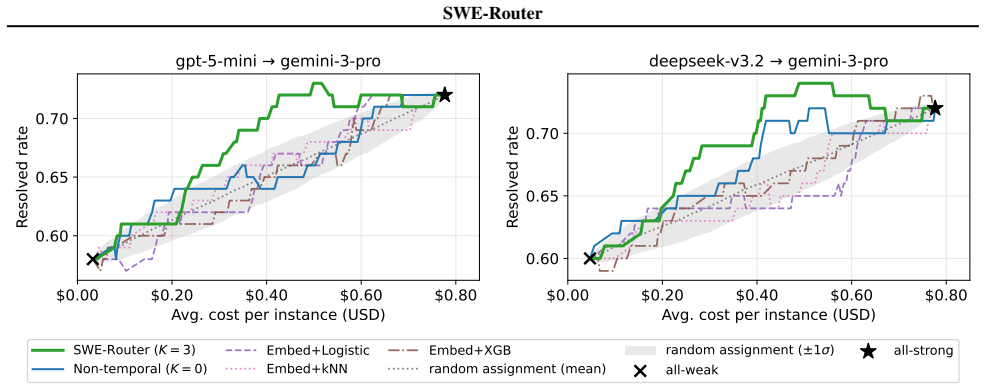
SWE-Router is a value-based temporal routing method that first lets a cheap model generate a partial trajectory through exploratory turns, then uses that trajectory to decide continuation or escalation. A Bayes-optimality theorem shows that conditioning the routing decision on the partial trajectory never harms performance and is strictly better when exploration is informative. Across contemporary weak-strong LLM pairs this yields substantially better cost efficiency on SWE tasks while retaining the majority of the stronger model's performance.
What carries the argument
The partial trajectory produced by a small number of exploratory turns with the cheap model, which supplies the value estimate used to make the routing decision.
If this is right
- Routing decisions become informed by actual interaction history rather than the prompt alone.
- Cost efficiency improves across model pairs while most performance of the stronger model is retained.
- The Bayes-optimality result guarantees that adding trajectory information cannot degrade routing quality.
- A released multi-LLM trajectory dataset enables further study of trajectory-level routing methods.
Where Pith is reading between the lines
- The same trajectory-conditioning logic could apply to other multi-turn agentic domains where difficulty only becomes visible through interaction.
- Organizations could dynamically allocate model resources to handle more tasks under fixed compute budgets.
- Similar partial-trajectory value estimates might reduce waste in any sequential LLM usage pattern that involves repeated calls.
Load-bearing premise
A small number of exploratory turns with the cheap model produces a partial trajectory whose value estimate is sufficiently accurate and low-cost to justify the routing decision.
What would settle it
A controlled experiment in which routing decisions made after the exploratory turns produce either higher total cost or lower task success rate than a task-description-only router or always using the strong model.
Figures
read the original abstract
Large language models (LLMs) embedded in multi-turn agentic harnesses are reshaping software engineering (SWE), but routing every task to a frontier model is wasteful when many issues admit cheap fixes. Existing LLM routers operate on the task description alone, which inherits an information-theoretic Bayes-error floor in agentic settings: a similar issue can hide either a localized typo or a multi-module refactor, and the prompt does not separate the two. We introduce SWE-Router, a value-based temporal approach that lets a cheap model run for a few exploratory turns and reads the resulting partial trajectory before deciding whether to continue cheaply or to escalate to an expensive model. We provide a Bayes-optimality theorem showing that conditioning on the partial trajectory never harms routing and is strictly better whenever exploration is informative. Across the LLM pairs of weak and strong models spanning the contemporary cost--capability frontier, we show that SWE-Router greatly improves the cost efficiency of SWE tasks, while maintaining the majority of the performances of the stronger model. We additionally release a multi-LLM trajectory dataset which allows reproduction of our trajectory-level routing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SWE-Router, a value-based temporal routing approach for multi-turn agentic software engineering tasks. A cheap model performs a small number of exploratory turns to produce a partial trajectory; the router then decides whether to continue with the cheap model or escalate to a stronger model. The central theoretical claim is a Bayes-optimality theorem asserting that conditioning on the partial trajectory never harms routing performance and is strictly better whenever the trajectory is informative. Empirically, the method is reported to improve cost efficiency across pairs of weak and strong LLMs while preserving most of the stronger model's task performance; a multi-LLM trajectory dataset is also released.
Significance. If the theorem is correctly derived and the empirical gains survive scrutiny of value-estimate accuracy, the work would offer a principled, trajectory-aware alternative to task-only routing and could materially reduce the cost of deploying agentic LLM systems on SWE benchmarks. The dataset release supports reproducibility and follow-on research.
major comments (3)
- [Abstract / Theorem] Abstract and theorem section: the Bayes-optimality claim is load-bearing yet the manuscript supplies no derivation, proof sketch, or explicit statement of the posterior-value estimator. Without these details it is impossible to verify that the practical routing rule inherits the stated optimality guarantee once the cost of the exploratory turns is subtracted.
- [Method / Routing rule] Value-estimate accuracy (weakest assumption identified in the stress-test note): the routing policy presupposes that a small fixed number of cheap-model turns yields a sufficiently accurate and low-variance estimate of continuation value. The paper provides no error analysis, variance bounds, or ablation on the number of exploratory turns, leaving open the possibility that noisy estimates produce net-negative routing decisions even when the theoretical statement remains formally true.
- [Experiments] Empirical results: the abstract asserts "greatly improves the cost efficiency" and "maintains the majority of the performances," but the available text contains neither quantitative tables, baseline comparisons (task-only routing, oracle routing), nor error bars. These data are required to substantiate the central empirical claim.
minor comments (2)
- [Notation / Method] Clarify the precise functional form of the value estimator and the decision threshold that trades off expected gain against exploration cost.
- [Data release] The dataset release is welcome; the paper should state the exact license, format, and reproduction instructions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Theorem] Abstract and theorem section: the Bayes-optimality claim is load-bearing yet the manuscript supplies no derivation, proof sketch, or explicit statement of the posterior-value estimator. Without these details it is impossible to verify that the practical routing rule inherits the stated optimality guarantee once the cost of the exploratory turns is subtracted.
Authors: We agree that the main text would benefit from greater self-containment. The full derivation appears in Appendix A, but we will insert a concise proof sketch into Section 3 together with an explicit statement of the posterior-value estimator (the conditional expectation of continuation value given the partial trajectory). This will make the inheritance of the optimality guarantee, net of exploratory cost, directly verifiable from the main body. revision: yes
-
Referee: [Method / Routing rule] Value-estimate accuracy (weakest assumption identified in the stress-test note): the routing policy presupposes that a small fixed number of cheap-model turns yields a sufficiently accurate and low-variance estimate of continuation value. The paper provides no error analysis, variance bounds, or ablation on the number of exploratory turns, leaving open the possibility that noisy estimates produce net-negative routing decisions even when the theoretical statement remains formally true.
Authors: The Bayes-optimality theorem is agnostic to estimation error, yet we concur that empirical validation of the assumption is necessary. We will add (i) an ablation varying the number of exploratory turns (1, 3, 5) and (ii) a variance analysis of the value estimates across the released dataset. These additions will quantify the regimes in which the routing decisions remain net-positive. revision: yes
-
Referee: [Experiments] Empirical results: the abstract asserts "greatly improves the cost efficiency" and "maintains the majority of the performances," but the available text contains neither quantitative tables, baseline comparisons (task-only routing, oracle routing), nor error bars. These data are required to substantiate the central empirical claim.
Authors: Section 4 of the manuscript already contains tables reporting cost and performance metrics for multiple weak–strong LLM pairs, with explicit comparison to task-only routing. To address the concern we will (i) add error bars computed over repeated runs and (ii) include an oracle-routing baseline. We will also ensure the experimental section is fully present in the revision. revision: partial
Circularity Check
No significant circularity; theorem applies standard decision theory without self-referential reduction
full rationale
The paper's central Bayes-optimality claim is a general result that additional observations (partial trajectory) cannot harm and can only improve routing decisions under standard Bayesian updating; this is independent of any fitted parameters or prior self-citations. No equations or sections in the abstract or reader's summary reduce a prediction to a self-defined input, a fitted value renamed as output, or a load-bearing self-citation chain. The empirical routing policy is presented as an application of this theorem plus a value-based temporal approach, with no indication that the value estimates are constructed by definition from the routing outcomes themselves. The derivation chain remains self-contained against external benchmarks of decision theory.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Partial trajectories from cheap-model exploration are informative about task complexity and repair cost
Reference graph
Works this paper leans on
-
[1]
KaShun SHUM and Binyuan Hui and Jiawei Chen and Lei Zhang and X. W. and Jiaxi Yang and Yuzhen Huang and Junyang Lin and Junxian He , booktitle=. 2026 , url=
2026
-
[2]
arXiv preprint arXiv:2502.08773 , year=
Universal model routing for efficient llm inference , author=. arXiv preprint arXiv:2502.08773 , year=
-
[3]
Richard Zhuang and Tianhao Wu and Zhaojin Wen and Andrew Li and Jiantao Jiao and Kannan Ramchandran , booktitle=. Embed. 2025 , url=
2025
-
[4]
Gonzalez and M Waleed Kadous and Ion Stoica , booktitle=
Isaac Ong and Amjad Almahairi and Vincent Wu and Wei-Lin Chiang and Tianhao Wu and Joseph E. Gonzalez and M Waleed Kadous and Ion Stoica , booktitle=. Route. 2025 , url=
2025
-
[5]
The Eleventh International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[6]
2025 , url=
John Yang and Kilian Lieret and Carlos E Jimenez and Alexander Wettig and Kabir Khandpur and Yanzhe Zhang and Binyuan Hui and Ofir Press and Ludwig Schmidt and Diyi Yang , booktitle=. 2025 , url=
2025
-
[7]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Swe-bench pro: Can ai agents solve long-horizon software engineering tasks? , author=. arXiv preprint arXiv:2509.16941 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
2024 , url=
Jimenez, Carlos E and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=. 2024 , url=
2024
-
[9]
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle =. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering , url =. doi:10.52202/079017-1601 , editor =
-
[10]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
ArXiv , year=
Evaluating Large Language Models Trained on Code , author=. ArXiv , year=
-
[12]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Neural Information Processing Systems , year=
Measuring Coding Challenge Competence With APPS , author=. Neural Information Processing Systems , year=
-
[14]
ArXiv , year=
SWE-smith: Scaling Data for Software Engineering Agents , author=. ArXiv , year=
-
[15]
Introducing swe-bench verified | openai ,author=
-
[16]
arXiv preprint arXiv:2404.02605 , year=
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving , author=. arXiv preprint arXiv:2404.02605 , year=
-
[17]
Neural Information Processing Systems , year=
CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion , author=. Neural Information Processing Systems , year=
-
[18]
RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems
RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems , author=. arXiv preprint arXiv:2306.03091 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , author=. arXiv preprint arXiv:2406.15877 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains? , author=. arXiv preprint arXiv:2410.03859 , year=
-
[21]
Neural Information Processing Systems , year=
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering , author=. Neural Information Processing Systems , year=
-
[22]
ACM SIGSOFT International Symposium on Software Testing and Analysis , year=
AutoCodeRover: Autonomous Program Improvement , author=. ACM SIGSOFT International Symposium on Software Testing and Analysis , year=
-
[23]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
OpenHands: An Open Platform for AI Software Developers as Generalist Agents , author=. arXiv preprint arXiv:2407.16741 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation , author=. arXiv preprint arXiv:2312.13010 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
International Conference on Machine Learning , year=
Executable Code Actions Elicit Better LLM Agents , author=. International Conference on Machine Learning , year=
-
[26]
Agentless: Demystifying LLM-based Software Engineering Agents
Agentless: Demystifying LLM-based Software Engineering Agents , author=. arXiv preprint arXiv:2407.01489 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Proceedings of the ACM on Software Engineering , year=
CodePlan: Repository-level Coding using LLMs and Planning , author=. Proceedings of the ACM on Software Engineering , year=
-
[28]
Benchmark Data Contamination of Large Language Models: A Survey
Benchmark Data Contamination of Large Language Models: A Survey , author=. arXiv preprint arXiv:2406.04244 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Investigating Data Contamination in Modern Benchmarks for Large Language Models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=. 2024 , address=
2024
-
[30]
arXiv preprint arXiv:2502.14425 (2025)
A Survey on Data Contamination for Large Language Models , author=. arXiv preprint arXiv:2502.14425 , year=
-
[31]
arXiv preprint arXiv:2410.06992 , year=
SWE-Bench+: Enhanced Coding Benchmark for LLMs , author=. arXiv preprint arXiv:2410.06992 , year=
-
[32]
SWE-bench Goes Live! , author=. arXiv preprint arXiv:2505.23419 , year=
-
[33]
2009 IEEE 31st International Conference on Software Engineering , pages=
Predicting faults using the complexity of code changes , author=. 2009 IEEE 31st International Conference on Software Engineering , pages=. 2009 , organization=
2009
-
[34]
Empirical Software Engineering , volume=
Evaluating code complexity triggers, use of complexity measures and the influence of code complexity on maintenance time , author=. Empirical Software Engineering , volume=. 2017 , publisher=
2017
-
[35]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[36]
ArXiv , year=
LiveBench: A Challenging, Contamination-Free LLM Benchmark , author=. ArXiv , year=
-
[37]
ArXiv , year=
Agent-RLVR: Training Software Engineering Agents via Guidance and Environment Rewards , author=. ArXiv , year=
-
[38]
ArXiv , year=
SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories? , author=. ArXiv , year=
-
[39]
ArXiv , year=
A Careful Examination of Large Language Model Performance on Grade School Arithmetic , author=. ArXiv , year=
-
[40]
arXiv preprint arXiv:2311.09783 , year=
Investigating the Impact of Data Contamination of Large Language Models in Text-to-SQL Translation , author=. arXiv preprint arXiv:2311.09783 , year=
-
[41]
Efficient Training-Free Online Routing for High-Volume Multi-LLM Serving , author=
-
[42]
arXiv preprint arXiv:2410.03834 , year=
Graphrouter: A graph-based router for llm selections , author=. arXiv preprint arXiv:2410.03834 , year=
-
[43]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[44]
arXiv preprint arXiv:2505.16881 , year=
CASTILLO: Characterizing Response Length Distributions of Large Language Models , author=. arXiv preprint arXiv:2505.16881 , year=
-
[45]
arXiv preprint arXiv:2407.10834 , year=
Metallm: A high-performant and cost-efficient dynamic framework for wrapping llms , author=. arXiv preprint arXiv:2407.10834 , year=
-
[46]
arXiv preprint arXiv:2504.09858 , year=
Reasoning models can be effective without thinking , author=. arXiv preprint arXiv:2504.09858 , year=
-
[47]
arXiv preprint arXiv:2503.10657 , year=
Routereval: A comprehensive benchmark for routing llms to explore model-level scaling up in llms , author=. arXiv preprint arXiv:2503.10657 , year=
-
[48]
Lingjiao Chen and Matei Zaharia and James Zou , journal=. Frugal. 2024 , url=
2024
-
[49]
arXiv preprint arXiv:2408.12320 , year=
Tensoropera router: A multi-model router for efficient llm inference , author=. arXiv preprint arXiv:2408.12320 , year=
-
[50]
Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages=
Fly-swat or cannon? cost-effective language model choice via meta-modeling , author=. Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages=
-
[51]
Advances in Neural Information Processing Systems , volume=
Routerdc: Query-based router by dual contrastive learning for assembling large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
arXiv preprint arXiv:2308.11601 , year=
Tryage: Real-time, intelligent routing of user prompts to large language models , author=. arXiv preprint arXiv:2308.11601 , year=
-
[53]
Cost-aware contrastive routing for llms.arXiv preprint arXiv:2508.12491,
Cost-Aware Contrastive Routing for LLMs , author=. arXiv preprint arXiv:2508.12491 , year=
-
[54]
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Hybrid llm: Cost-efficient and quality-aware query routing , author=. arXiv preprint arXiv:2404.14618 , year=
-
[55]
AutoMix: Automatically Mixing Language Models
Automix: Automatically mixing language models , author=. arXiv preprint arXiv:2310.12963 , year=
-
[56]
arXiv preprint arXiv:2306.02561 , year=
Llm-blender: Ensembling large language models with pairwise ranking and generative fusion , author=. arXiv preprint arXiv:2306.02561 , year=
-
[57]
IEEE Transactions on Knowledge and Data Engineering , year=
A survey on mixture of experts in large language models , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[58]
The Twelfth International Conference on Learning Representations , year=
Large Language Model Cascades with Mixture of Thought Representations for Cost-Efficient Reasoning , author=. The Twelfth International Conference on Learning Representations , year=
-
[59]
FusionFactory: Fusing LLM Capabilities with Multi-LLM Log Data
FusionFactory: Fusing LLM Capabilities with Multi-LLM Log Data , author=. arXiv preprint arXiv:2507.10540 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
arXiv preprint arXiv:2504.07113 , year=
How Robust Are Router-LLMs? Analysis of the Fragility of LLM Routing Capabilities , author=. arXiv preprint arXiv:2504.07113 , year=
-
[61]
arXiv preprint arXiv:2502.03261 , year=
Carrot: A cost aware rate optimal router , author=. arXiv preprint arXiv:2502.03261 , year=
-
[62]
arXiv preprint arXiv:2509.06274 , year=
IPR: Intelligent Prompt Routing with User-Controlled Quality-Cost Trade-offs , author=. arXiv preprint arXiv:2509.06274 , year=
-
[63]
arXiv preprint arXiv:2502.20576 , year=
OmniRouter: Budget and Performance Controllable Multi-LLM Routing , author=. arXiv preprint arXiv:2502.20576 , year=
-
[64]
arXiv preprint arXiv:2510.00202 , year=
RouterArena: An Open Platform for Comprehensive Comparison of LLM Routers , author=. arXiv preprint arXiv:2510.00202 , year=
-
[65]
arXiv preprint arXiv:2506.01048 , year=
IRT-Router: Effective and Interpretable Multi-LLM Routing via Item Response Theory , author=. arXiv preprint arXiv:2506.01048 , year=
-
[66]
2025 , howpublished=
vLLM Semantic Router , author=. 2025 , howpublished=
2025
-
[67]
2026 , note =
LLM Router – Chat UI Configuration , author =. 2026 , note =
2026
-
[68]
2025 , author =
RequestyAI: Unified LLM Gateway Routing , howpublished =. 2025 , author =
2025
-
[69]
arXiv preprint arXiv:2505.19435 , year=
Route to Reason: Adaptive Routing for LLM and Reasoning Strategy Selection , author=. arXiv preprint arXiv:2505.19435 , year=
-
[70]
arXiv preprint arXiv:2506.05901 , year=
Route-and-Reason: Scaling Large Language Model Reasoning with Reinforced Model Router , author=. arXiv preprint arXiv:2506.05901 , year=
-
[71]
2026 , eprint=
Think When Needed: Model-Aware Reasoning Routing for LLM-based Ranking , author=. 2026 , eprint=
2026
-
[72]
arXiv preprint arXiv:2510.08731 , year=
When to Reason: Semantic Router for vLLM , author=. arXiv preprint arXiv:2510.08731 , year=
-
[73]
2025 , note =
Auto Router , author =. 2025 , note =
2025
-
[74]
arXiv preprint arXiv:2310.01542 , year=
Fusing models with complementary expertise , author=. arXiv preprint arXiv:2310.01542 , year=
-
[75]
2023 , publisher =
OpenHermes 2.5: An Open Dataset of Synthetic Data for Generalist LLM Assistants , author =. 2023 , publisher =
2023
-
[76]
2025 , author =
NotDiamond: Routing Between AI Models , howpublished =. 2025 , author =
2025
-
[77]
Model router for Microsoft Foundry , author =
-
[78]
RouterBench: A Benchmark for Multi-LLM Routing System
Routerbench: A benchmark for multi-llm routing system , author=. arXiv preprint arXiv:2403.12031 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Sparsity in LLMs (SLLM): Deep Dive into Mixture of Experts, Quantization, Hardware, and Inference , year=
Faster, Cheaper, Just as Good: Cost-and Latency-Constrained Routing for LLMs , author=. Sparsity in LLMs (SLLM): Deep Dive into Mixture of Experts, Quantization, Hardware, and Inference , year=
-
[80]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.