GCT-MARL: Graph-Based Contrastive Transfer for Sample-Efficient Cooperative Multi-Agent Reinforcement Learning
Pith reviewed 2026-06-26 00:11 UTC · model grok-4.3
The pith
GCT-MARL augments graph contrastive methods with weighted alignment and two-phase training to transfer knowledge across MARL tasks with different agent counts and types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
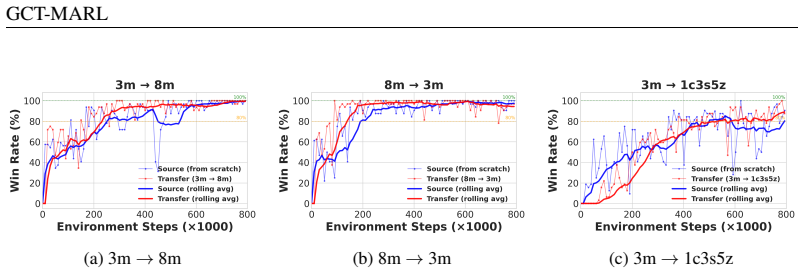
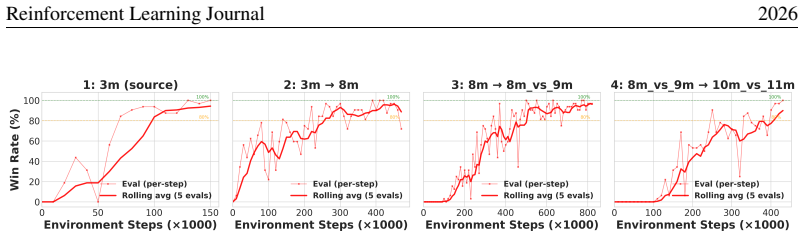
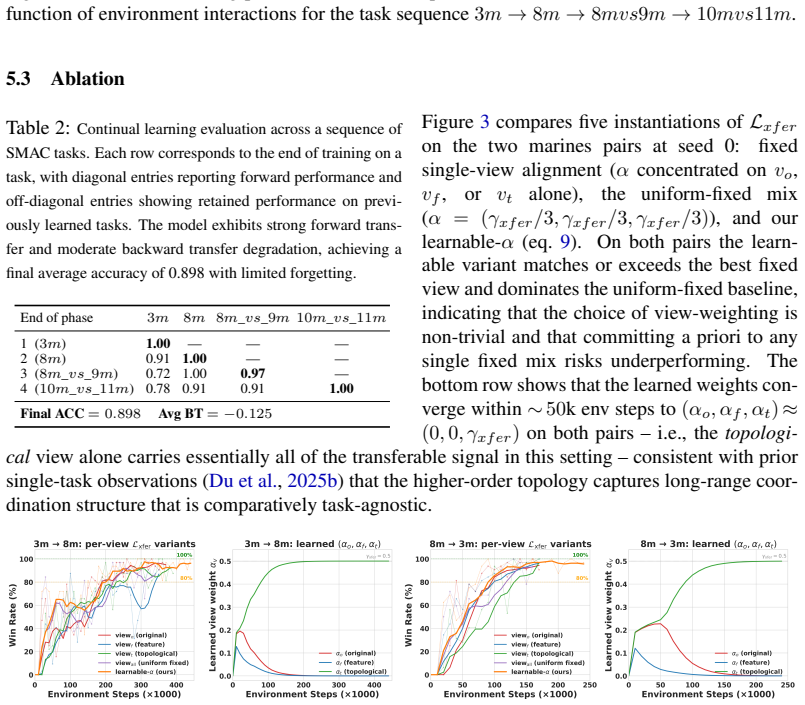
GCT-MARL builds on the multi-view graph contrastive backbone of MAIL and augments it with a per-view, adaptively weighted alignment loss and a two-phase training protocol specifically designed for transfer across populations of varying sizes and compositions. The framework markedly accelerates convergence on the target task relative to from-scratch training in both homogeneous (within-faction, varying N) and heterogeneous (cross-faction and mixed unit-type) transfer scenarios. It also supports continual learning by sequentially chaining the two-phase transfer protocol across a series of related tasks.
What carries the argument
Multi-view graph contrastive backbone augmented with per-view adaptively weighted alignment loss and two-phase training protocol for population transfer.
If this is right
- Convergence on target tasks accelerates relative to from-scratch baselines in within-faction transfers with varying numbers of agents.
- Convergence accelerates in cross-faction and mixed unit-type transfers.
- Sequential application of the two-phase protocol enables continual learning across a chain of related tasks.
- The same backbone supports both homogeneous and heterogeneous population shifts without separate redesign.
Where Pith is reading between the lines
- The approach could lower total compute budgets when a sequence of related MARL environments must be solved in deployment.
- If the alignment loss weighting adapts reliably, similar per-view mechanisms might stabilize transfer in other graph-structured multi-agent settings.
- Chaining the protocol suggests a route to lifelong MARL agents that accumulate skills across changing team sizes without full retraining.
Load-bearing premise
The multi-view graph contrastive backbone of MAIL can be augmented with a per-view, adaptively weighted alignment loss and a two-phase training protocol specifically designed for transfer across populations of varying sizes and compositions.
What would settle it
Running the target-task experiments and finding no measurable reduction in episodes or steps to convergence when using GCT-MARL versus training from scratch in the homogeneous or heterogeneous settings.
Figures
read the original abstract
In cooperative multi-agent reinforcement learning (MARL), from a deployment perspective, it is challenging and expensive to train agents from scratch for each new environment or task. In this work, we propose GCT-MARL, a transfer learning framework that builds on the multi-view graph contrastive backbone of MAIL and augments it with a per-view, adaptively weighted alignment loss and a two-phase training protocol specifically designed for transfer across populations of varying sizes and compositions. We empirically demonstrate that the proposed framework markedly accelerates convergence on the target task relative to from-scratch training, in both homogeneous (within-faction, varying N) and heterogeneous (cross-faction and mixed unit-type) transfer scenarios. Furthermore, we show that the framework naturally supports continual learning by sequentially chaining the two-phase transfer protocol across a series of related tasks. Overall, this work provides a unified approach to mitigating key limitations in current MARL transfer methods with new insights at both methodological and empirical levels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GCT-MARL, a transfer learning framework for cooperative multi-agent reinforcement learning. It augments the multi-view graph contrastive backbone of MAIL with a per-view adaptively weighted alignment loss and a two-phase training protocol designed for transfer across agent populations of varying sizes and compositions. The central claims are that the framework markedly accelerates convergence on target tasks relative to from-scratch training in both homogeneous (within-faction, varying N) and heterogeneous (cross-faction, mixed unit-type) scenarios, and that it supports continual learning via sequential chaining of the two-phase protocol.
Significance. If the empirical results hold with appropriate controls and statistical support, the work would offer a unified methodological approach to sample-efficient transfer in MARL, directly addressing the practical cost of retraining agents for new environments or tasks.
major comments (1)
- [Abstract] Abstract: the claim that the framework 'markedly accelerates convergence on the target task relative to from-scratch training' is presented without any experimental details, baselines, metrics, statistical tests, environment descriptions, or result tables, rendering it impossible to evaluate whether the data support the stated empirical contributions.
Simulated Author's Rebuttal
We thank the referee for the review. Below we address the single major comment point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the framework 'markedly accelerates convergence on the target task relative to from-scratch training' is presented without any experimental details, baselines, metrics, statistical tests, environment descriptions, or result tables, rendering it impossible to evaluate whether the data support the stated empirical contributions.
Authors: Abstracts are concise summaries whose purpose is to state the central claim; they are not required (and typically cannot) contain full experimental protocols, tables, or statistical details. The supporting evidence for the claim—including environment descriptions (StarCraft II and related MARL benchmarks), baselines (from-scratch training plus MAIL and other transfer methods), metrics (episode reward and convergence speed), statistical reporting (means and standard deviations over multiple random seeds), and result tables/figures—is provided in full in Sections 4–5 of the manuscript. This is the standard structure of research papers in the field. The abstract therefore does not render evaluation impossible; the manuscript body supplies the necessary information for such evaluation. revision: no
Circularity Check
No significant circularity
full rationale
The paper's central contribution is an empirical demonstration of accelerated convergence and continual learning support in MARL transfer scenarios via an augmented MAIL backbone. No equations, derivations, or analytical claims are advanced that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The framework is described at a high level as an augmentation of prior work, with results presented as experimental outcomes rather than forced predictions or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI) , pages =
Multi-Agent Communication with Information Preserving Graph Contrastive Learning , author =. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI) , pages =
-
[2]
arXiv preprint arXiv:1905.01303 , year=
Autonomous air traffic controller: A deep multi-agent reinforcement learning approach , author=. arXiv preprint arXiv:1905.01303 , year=
Pith/arXiv arXiv 1905
-
[3]
, author=
Multi-Agent Reinforcement Learning for Automated Peer-to-Peer Energy Trading in Double-Side Auction Market. , author=. IJCAI , pages=
-
[4]
Proceedings of the 36th International Conference on Machine Learning (ICML) , pages =
Simplifying Graph Convolutional Networks , author =. Proceedings of the 36th International Conference on Machine Learning (ICML) , pages =
-
[5]
International Conference on Learning Representations (ICLR) , year =
Graph Attention Networks , author =. International Conference on Learning Representations (ICLR) , year =
-
[6]
International Conference on Learning Representations (ICLR) , year =
Deep Graph Infomax , author =. International Conference on Learning Representations (ICLR) , year =
-
[7]
Proceedings of the 37th International Conference on Machine Learning (ICML) , pages =
Contrastive Multi-View Representation Learning on Graphs , author =. Proceedings of the 37th International Conference on Machine Learning (ICML) , pages =
-
[8]
Proceedings of The Web Conference (WWW) , pages =
Graph Representation Learning via Graphical Mutual Information Maximization , author =. Proceedings of The Web Conference (WWW) , pages =
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , pages =
Attribute and Structure Preserving Graph Contrastive Learning , author =. Proceedings of the AAAI Conference on Artificial Intelligence , pages =
-
[10]
International Conference on Learning Representations (ICLR) , year =
Graph Convolutional Reinforcement Learning , author =. International Conference on Learning Representations (ICLR) , year =
-
[11]
Proceedings of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , pages =
Multi-Agent Graph-Attention Communication and Teaming , author =. Proceedings of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , pages =
-
[12]
Proceedings of the 36th International Conference on Machine Learning (ICML) , pages =
TarMAC: Targeted Multi-Agent Communication , author =. Proceedings of the 36th International Conference on Machine Learning (ICML) , pages =
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , pages =
Learning Multiagent Communication with Backpropagation , author =. Advances in Neural Information Processing Systems (NeurIPS) , pages =
-
[14]
Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , pages =
Learning Structured Communication for Multi-Agent Reinforcement Learning , author =. Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , pages =
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , pages =
Multi-Agent Game Abstraction via Graph Attention Neural Network , author =. Proceedings of the AAAI Conference on Artificial Intelligence , pages =
-
[16]
Proceedings of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , year =
Deep Implicit Coordination Graphs for Multi-Agent Reinforcement Learning , author =. Proceedings of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS) , year =
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , year =
From Few to More: Large-Scale Dynamic Multiagent Curriculum Learning , author =. Proceedings of the AAAI Conference on Artificial Intelligence , year =
-
[18]
Proceedings of the 38th International Conference on Machine Learning (ICML) , year =
Randomized Entity-wise Factorization for Multi-Agent Reinforcement Learning , author =. Proceedings of the 38th International Conference on Machine Learning (ICML) , year =
-
[19]
Lateral Transfer Learning for Multiagent Reinforcement Learning , year=
Shi, Haobin and Li, Jingchen and Mao, Jiahui and Hwang, Kao-Shing , journal=. Lateral Transfer Learning for Multiagent Reinforcement Learning , year=
-
[20]
International Conference on Learning Representations (ICLR) , year =
Evolutionary Population Curriculum for Scaling Multi-Agent Reinforcement Learning , author =. International Conference on Learning Representations (ICLR) , year =
-
[21]
Cooperative Multiagent Transfer Learning With Coalition Pattern Decomposition , year=
Zhou, Tianze and Zhang, Fubiao and Shao, Kun and Dai, Zipeng and Li, Kai and Huang, Wenhan and Wang, Weixun and Wang, Bin and Li, Dong and Liu, Wulong and Hao, Jianye , journal=. Cooperative Multiagent Transfer Learning With Coalition Pattern Decomposition , year=
-
[22]
Samvelyan, Mikayel and Rashid, Tabish and de Witt, Christian Schroeder and Farquhar, Gregory and Nardelli, Nantas and Rudner, Tim G. J. and Hung, Chia-Man and Torr, Philip H. S. and Foerster, Jakob and Whiteson, Shimon , booktitle =. The
-
[23]
, booktitle =
Oliehoek, Frans A. , booktitle =. Decentralized. 2012 , publisher =
2012
-
[24]
Proceedings of the National Academy of Sciences , volume =
Overcoming Catastrophic Forgetting in Neural Networks , author =. Proceedings of the National Academy of Sciences , volume =
-
[25]
Proceedings of the 35th International Conference on Machine Learning (ICML) , year =
Progress & Compress: A Scalable Framework for Continual Learning , author =. Proceedings of the 35th International Conference on Machine Learning (ICML) , year =
-
[26]
IEEE Transactions on Vehicular Technology , year =
A Multi-Agent Reinforcement Learning Based Control Method for Connected and Autonomous Vehicles in a Mixed Platoon , author =. IEEE Transactions on Vehicular Technology , year =
-
[27]
Zhang, Yutian and Zheng, Guohong and Liu, Zhiyuan and others , journal =
-
[28]
and Mathieu, Micha
Vinyals, Oriol and Babuschkin, Igor and Czarnecki, Wojciech M. and Mathieu, Micha. Grandmaster Level in. Nature , volume =
-
[29]
, author=
Transfer learning for reinforcement learning domains: A survey. , author=. Journal of Machine Learning Research , volume=
-
[30]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Transfer learning in deep reinforcement learning: A survey , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2023 , publisher=
2023
-
[31]
, author=
Deep multiagent reinforcement learning: challenges and directions. , author=. Artificial Intelligence Review , volume=
-
[32]
Advances in neural information processing systems , volume=
Multi-agent actor-critic for mixed cooperative-competitive environments , author=. Advances in neural information processing systems , volume=
-
[33]
International Conference on Machine Learning , pages=
Lazy agents: A new perspective on solving sparse reward problem in multi-agent reinforcement learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[34]
Journal of Machine Learning Research , volume=
Monotonic value function factorisation for deep multi-agent reinforcement learning , author=. Journal of Machine Learning Research , volume=
-
[35]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Expressive multi-agent communication via identity-aware learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[36]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , pages=
Multi-agent communication with information preserving graph contrastive learning , author=. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , pages=
-
[37]
Proceedings of the AAAI conference on artificial intelligence , volume=
A transfer approach using graph neural networks in deep reinforcement learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[38]
Proceedings of the AAAI conference on artificial intelligence , volume=
Attribute and structure preserving graph contrastive learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[39]
arXiv preprint arXiv:1511.06295 , year=
Policy distillation , author=. arXiv preprint arXiv:1511.06295 , year=
-
[40]
Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems , pages=
Zero shot transfer learning for robot soccer , author=. Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems , pages=
-
[41]
Journal of machine learning research , volume=
Domain-adversarial training of neural networks , author=. Journal of machine learning research , volume=
-
[42]
Proceedings of the AAAI conference on artificial intelligence , volume=
Return of frustratingly easy domain adaptation , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[43]
Proceedings of the IEEE international conference on computer vision , pages=
Unpaired image-to-image translation using cycle-consistent adversarial networks , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[44]
International conference on machine learning , pages=
Deep decentralized multi-task multi-agent reinforcement learning under partial observability , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[45]
Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models , author=. Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=. 2010 , organization=
2010
-
[46]
IEEE transactions on pattern analysis and machine intelligence , volume=
Learning without forgetting , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2017 , publisher=
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.