Capability Self-Assessment: Teaching LLMs to Know Their Limits
Pith reviewed 2026-06-28 22:24 UTC · model grok-4.3
The pith
Reinforcement learning trains large language models to recognize their own limits and delegate unsolvable tasks while keeping original capabilities intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
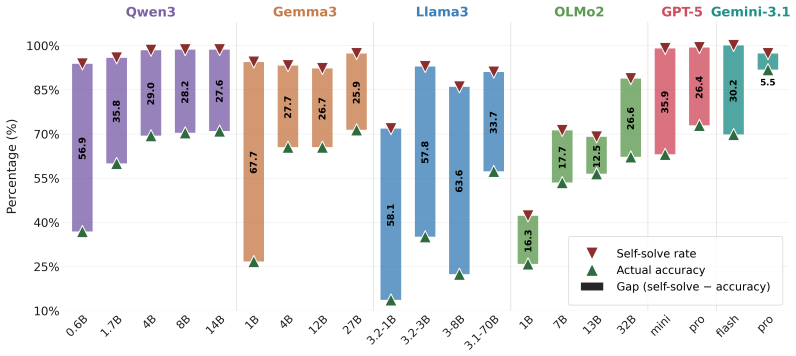
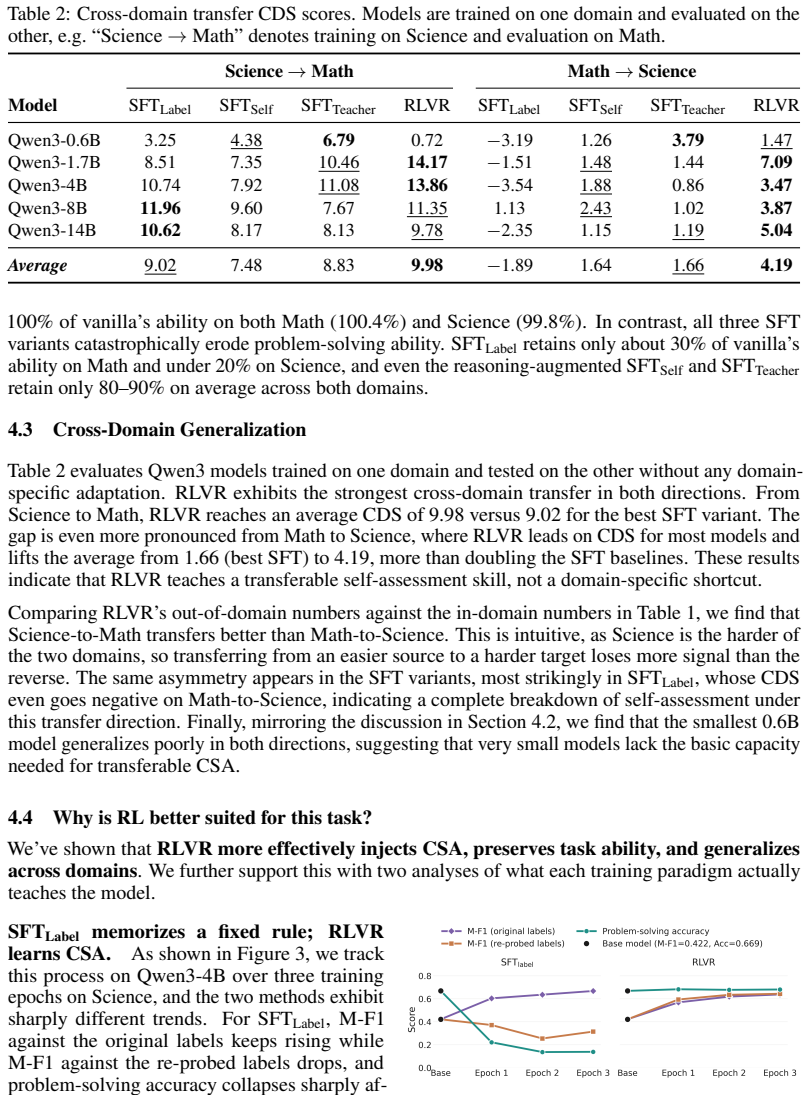
Large language models overestimate their competence across families and scales. Treating self-assessment as a policy-learning problem, reinforcement learning instills accurate capability recognition, outperforms supervised fine-tuning, and leaves the model's original abilities undamaged, whereas supervised fine-tuning degrades the very capabilities being assessed. The acquired behavior generalizes out of distribution and improves inference-time delegation and training-data selection.
What carries the argument
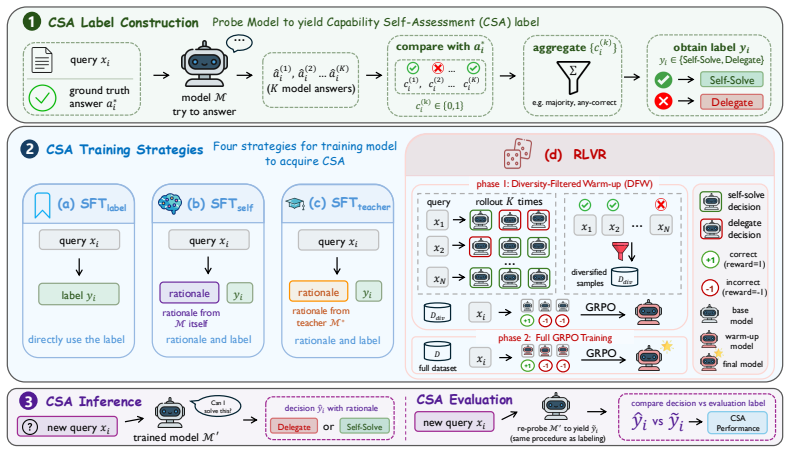
Reinforcement learning applied to a policy that outputs a solve-or-delegate decision for each query, optimized to improve self-assessment accuracy without capability loss.
If this is right
- At inference time, models can route queries they cannot solve to stronger external systems instead of producing incorrect answers.
- During continued training, self-assessment scores can be used to prioritize examples that the model currently cannot handle.
- The learned policy transfers to new task families without retraining, indicating that self-assessment is a general trait rather than task-specific memorization.
- Supervised fine-tuning on self-assessment labels harms downstream performance, so any future alignment method that uses labeled self-knowledge must avoid this degradation path.
Where Pith is reading between the lines
- If the same reinforcement-learning approach succeeds on agentic tasks that involve tool use or multi-step planning, self-assessment could become a standard safety layer before external actions are taken.
- The contrast between reinforcement learning and supervised fine-tuning suggests that capability self-assessment may be more naturally acquired through outcome-based feedback than through direct imitation of human judgments.
- Because the behavior generalizes out of distribution, one could test whether a single reinforcement-learning run on a narrow domain produces useful self-assessment on entirely different modalities such as code or mathematics.
Load-bearing premise
The measured preservation of original capabilities and the superiority of reinforcement learning over supervised fine-tuning depend on evaluation protocols free of post-hoc data exclusions or test-set choices that favor the reinforcement-learning condition.
What would settle it
On a held-out collection of tasks drawn from the same distribution as the training problems, measure whether the reinforcement-learning model still attempts a higher fraction of unsolvable queries than a supervised-fine-tuning model or the base model.
Figures

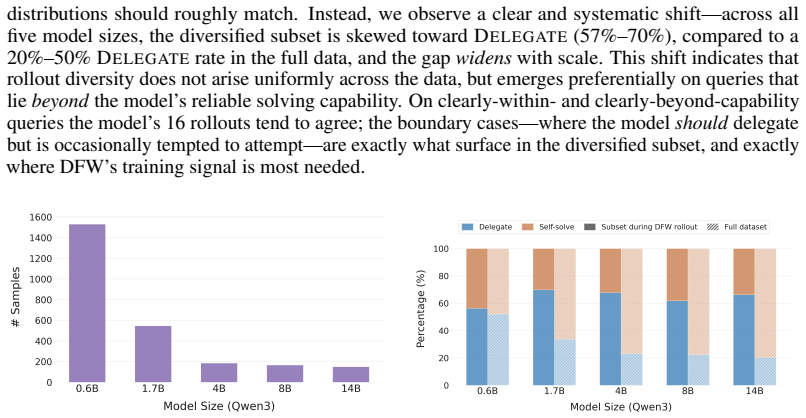


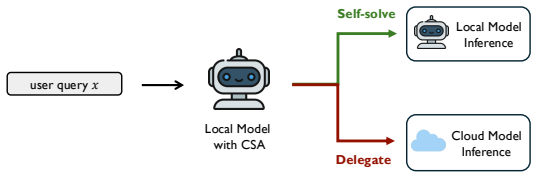
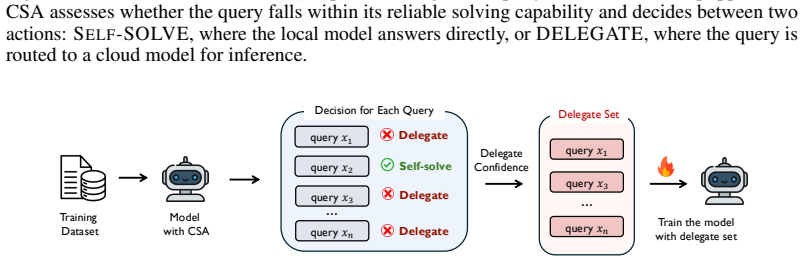
read the original abstract
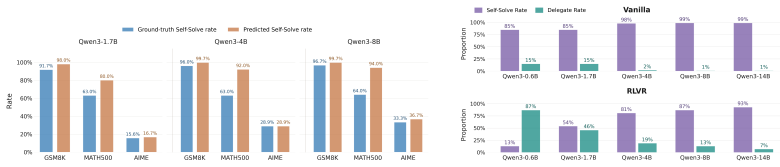
The ability to recognize one's own limitations and decide whether to solve a problem or delegate is fundamental for reliable intelligent systems. Yet we show that modern large language models systematically lack this ability: across diverse model families and scales, they overestimate their competence and attempt queries they cannot solve. We refer to this ability as Capability Self-Assessment (CSA) and formulate it as a policy-learning problem, aiming to improve self-assessment while preserving the model's original capabilities. Our results show that reinforcement learning teaches CSA effectively, significantly outperforming supervised fine-tuning while preserving original capabilities. In contrast, supervised fine-tuning severely degrades the capabilities the model is meant to assess. Moreover, learned self-assessment behavior generalizes well out of distribution, suggesting that CSA is a transferable model trait. Finally, CSA is practically useful: it improves local-cloud decision making at inference time and provides a signal for targeted data selection during training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Capability Self-Assessment (CSA) as the ability of LLMs to recognize their own limitations and decide whether to solve a query or delegate. It shows that current models systematically overestimate competence across families and scales. CSA is formulated as a policy-learning problem; experiments indicate that reinforcement learning trains effective CSA, significantly outperforming supervised fine-tuning while preserving original capabilities, whereas SFT degrades the very capabilities being assessed. The learned behavior generalizes out-of-distribution, and CSA improves local-cloud routing at inference and supplies a signal for targeted data selection during training.
Significance. If the comparative results and preservation claims are robust, the work would be significant for reliable LLM deployment: it supplies a concrete mechanism for models to know when to abstain or delegate, directly addressing overconfidence. The observation that RL preserves capabilities while SFT harms them is a useful distinction for alignment and post-training methods. OOD generalization and the two practical use-cases (inference routing, data selection) broaden the potential impact.
major comments (2)
- [Evaluation / results section] Evaluation / results section: the central claim that RL significantly outperforms SFT while preserving original capabilities (and that SFT severely degrades them) rests on the test-set construction and any filtering steps. The manuscript must explicitly state whether queries were excluded, re-weighted, or selected post-training on the basis of model performance, and must report the exact protocol used to measure capability preservation (including dataset sizes, number of runs, and statistical tests).
- [Results section] Results section: the claim of strong out-of-distribution generalization for the learned CSA policy requires a precise definition of the OOD distribution, the quantitative metrics used to measure it, and a comparison against the in-distribution baseline; without these details the generalization statement cannot be assessed.
minor comments (1)
- [Abstract] Abstract: high-level outcome statements are given without any numerical values, dataset sizes, or controls; moving at least one concrete metric (e.g., accuracy delta or capability retention percentage) into the abstract would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to provide the requested clarifications on experimental protocols.
read point-by-point responses
-
Referee: [Evaluation / results section] Evaluation / results section: the central claim that RL significantly outperforms SFT while preserving original capabilities (and that SFT severely degrades them) rests on the test-set construction and any filtering steps. The manuscript must explicitly state whether queries were excluded, re-weighted, or selected post-training on the basis of model performance, and must report the exact protocol used to measure capability preservation (including dataset sizes, number of runs, and statistical tests).
Authors: We agree that the test-set construction and capability preservation protocol require more explicit description. The revised manuscript now states clearly that no queries were excluded, re-weighted, or selected post-training on the basis of model performance. We have added the exact protocol details, including dataset sizes, number of runs, and statistical tests used to measure preservation of original capabilities. revision: yes
-
Referee: [Results section] Results section: the claim of strong out-of-distribution generalization for the learned CSA policy requires a precise definition of the OOD distribution, the quantitative metrics used to measure it, and a comparison against the in-distribution baseline; without these details the generalization statement cannot be assessed.
Authors: We agree that the OOD generalization claim needs a more precise definition and supporting details for assessment. The revised manuscript now includes an explicit definition of the OOD distribution, the quantitative metrics employed, and a direct comparison to the in-distribution baseline. revision: yes
Circularity Check
No significant circularity; purely empirical comparisons with no derivations or self-referential reductions
full rationale
The paper formulates CSA as a policy-learning problem and reports empirical results comparing reinforcement learning to supervised fine-tuning on capability preservation and out-of-distribution generalization. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Claims rest on experimental outcomes rather than any chain that reduces by construction to its own inputs, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey on data selection for language models.arXiv preprint arXiv:2402.16827,
Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, et al. A survey on data selection for language models.arXiv preprint arXiv:2402.16827, 2024
-
[2]
Conformal prediction: A gentle introduction
Anastasios N Angelopoulos and Stephen Bates. Conformal prediction: A gentle introduction. Foundations and Trends in Machine Learning, 16(4):494–591, 2023
2023
-
[3]
The internal state of an llm knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, 2023
2023
-
[4]
Barkan, Sidney Black, and Oliver Sourbut
Casey O. Barkan, Sidney Black, and Oliver Sourbut. Do large language models know what they are capable of? InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[5]
Classification with a reject option using a hinge loss
Peter L Bartlett and Marten H Wegkamp. Classification with a reject option using a hinge loss. Journal of Machine Learning Research, 9(8), 2008
2008
-
[6]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th annual international conference on machine learning, pages 41–48, 2009
2009
-
[7]
Conformal prediction for natural language processing: A survey.Transactions of the Association for Computational Linguistics, 12:1497–1516, 2024
Margarida Campos, António Farinhas, Chrysoula Zerva, Mário AT Figueiredo, and André FT Martins. Conformal prediction for natural language processing: A survey.Transactions of the Association for Computational Linguistics, 12:1497–1516, 2024
2024
-
[8]
Iván Vicente Moreno Cencerrado, Arnau Padrés Masdemont, Anton Gonzalvez Hawthorne, David Demitri Africa, and Lorenzo Pacchiardi. No answer needed: Predicting llm answer accuracy from question-only linear probes.arXiv preprint arXiv:2509.10625, 2025
-
[9]
Finetuning language models to emit linguistic expressions of uncertainty, 2024
Arslan Chaudhry, Sridhar Thiagarajan, and Dilan Gorur. Finetuning language models to emit linguistic expressions of uncertainty, 2024
2024
-
[10]
Large language model validity via enhanced conformal prediction methods.Advances in Neural Information Processing Systems, 37:114812–114842, 2024
John J Cherian, Isaac Gibbs, and Emmanuel J Candès. Large language model validity via enhanced conformal prediction methods.Advances in Neural Information Processing Systems, 37:114812–114842, 2024
2024
-
[11]
Prateek Chhikara. Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models.arXiv preprint arXiv:2502.11028, 2025
-
[12]
On optimum recognition error and reject tradeoff.IEEE Transactions on information theory, 16(1):41–46, 2003
C Chow. On optimum recognition error and reject tradeoff.IEEE Transactions on information theory, 16(1):41–46, 2003
2003
-
[13]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
2021
-
[14]
Yu Du, Fangyun Wei, and Hongyang Zhang. Anytool: Self-reflective, hierarchical agents for large-scale api calls.arXiv preprint arXiv:2402.04253, 2024
-
[15]
On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(5), 2010
Ran El-Yaniv et al. On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(5), 2010
2010
-
[16]
Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024. 10
2024
-
[17]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Selectivenet: A deep neural network with an integrated reject option
Yonatan Geifman and Ran El-Yaniv. Selectivenet: A deep neural network with an integrated reject option. InInternational conference on machine learning, pages 2151–2159. PMLR, 2019
2019
-
[19]
Conformal prediction with condi- tional guarantees.Journal of the Royal Statistical Society Series B: Statistical Methodology, 87(4):1100–1126, 2025
Isaac Gibbs, John J Cherian, and Emmanuel J Candès. Conformal prediction with condi- tional guarantees.Journal of the Royal Statistical Society Series B: Statistical Methodology, 87(4):1100–1126, 2025
2025
-
[20]
Strictly proper scoring rules, prediction, and estimation
Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102(477):359–378, 2007
2007
-
[21]
Gemini 3.1 Pro model card
Google DeepMind. Gemini 3.1 Pro model card. Technical report, Google DeepMind, 2 2026
2026
-
[22]
The llama 3 herd of models, 2024
Aaron Grattafiori et al. The llama 3 herd of models, 2024
2024
-
[23]
Overconfidence is key: Verbalized uncertainty evaluation in large language and vision-language models
Tobias Groot and Matias Valdenegro-Toro. Overconfidence is key: Verbalized uncertainty evaluation in large language and vision-language models. InProceedings of the 4th Workshop on Trustworthy Natural Language Processing (TrustNLP 2024), pages 145–171, 2024
2024
-
[24]
Data selection via optimal control for language models.arXiv preprint arXiv:2410.07064, 2024
Yuxian Gu, Li Dong, Hongning Wang, Yaru Hao, Qingxiu Dong, Furu Wei, and Minlie Huang. Data selection via optimal control for language models.arXiv preprint arXiv:2410.07064, 2024
-
[25]
On the evaluation of neural selective prediction methods for natural language processing
Zhengyao Gu and Mark Hopkins. On the evaluation of neural selective prediction methods for natural language processing. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7888–7899, 2023
2023
-
[26]
MASH: Modeling Abstention via Selective Help-Seeking
Mustafa Omer Gul, Claire Cardie, and Tanya Goyal. Pay-per-search models are abstention models.arXiv preprint arXiv:2510.01152, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. InInternational conference on machine learning, pages 1321–1330. PMLR, 2017
2017
-
[28]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Uncertainty distillation: Teaching language models to express semantic confidence, 2025
Sophia Hager, David Mueller, Kevin Duh, and Nicholas Andrews. Uncertainty distillation: Teaching language models to express semantic confidence, 2025
2025
-
[30]
Simple factuality probes detect hallucinations in long-form natural language generation
Jiatong Han, Neil Band, Muhammed Razzak, Jannik Kossen, Tim GJ Rudner, and Yarin Gal. Simple factuality probes detect hallucinations in long-form natural language generation. Findings of the Association for Computational Linguistics: EMNLP, pages 16209–16226, 2025
2025
-
[31]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
2025
-
[32]
Yue Huang, Jiawen Shi, Yuan Li, Chenrui Fan, Siyuan Wu, Qihui Zhang, Yixin Liu, Pan Zhou, Yao Wan, Neil Zhenqiang Gong, et al. Metatool benchmark for large language models: Deciding whether to use tools and which to use.arXiv preprint arXiv:2310.03128, 2023
-
[33]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1–38, 2023
2023
-
[34]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022. 11
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Large language models must be taught to know what they don’t know.Advances in Neural Information Processing Systems, 37:85932–85972, 2024
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, and Andrew G Wilson. Large language models must be taught to know what they don’t know.Advances in Neural Information Processing Systems, 37:85932–85972, 2024
2024
-
[36]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. Semantic entropy probes: Robust and cheap hallucination detection in llms.arXiv preprint arXiv:2406.15927, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Bhawesh Kumar, Charlie Lu, Gauri Gupta, Anil Palepu, David Bellamy, Ramesh Raskar, and Andrew Beam. Conformal prediction with large language models for multi-choice question answering.arXiv preprint arXiv:2305.18404, 2023
-
[38]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention, 2023
2023
-
[39]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Selective generation for control- lable language models.Advances in Neural Information Processing Systems, 37:50494–50527, 2024
Minjae Lee, Kyungmin Kim, Taesoo Kim, and Sangdon Park. Selective generation for control- lable language models.Advances in Neural Information Processing Systems, 37:50494–50527, 2024
2024
-
[41]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Deep gamblers: Learning to abstain with portfolio theory.Advances in Neural Information Processing Systems, 32, 2019
Ziyin Liu, Zhikang Wang, Paul Pu Liang, Russ R Salakhutdinov, Louis-Philippe Morency, and Masahito Ueda. Deep gamblers: Learning to abstain with portfolio theory.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[43]
Predict responsibly: Improving fairness and accuracy by learning to defer, 2018
David Madras, Toniann Pitassi, and Richard Zemel. Predict responsibly: Improving fairness and accuracy by learning to defer, 2018
2018
-
[44]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–9017, 2023
2023
-
[45]
Reducing conversational agents’ overconfidence through linguistic calibration.Transactions of the Association for Computational Linguistics, 10:857–872, 2022
Sabrina J Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau. Reducing conversational agents’ overconfidence through linguistic calibration.Transactions of the Association for Computational Linguistics, 10:857–872, 2022
2022
-
[46]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[47]
2 olmo 2 furious, 2025
Team OLMo et al. 2 olmo 2 furious, 2025
2025
-
[48]
GPT-5 system card
OpenAI. GPT-5 system card. Technical report, OpenAI, 8 2025
2025
-
[49]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. InConference on health, inference, and learning, pages 248–260. PMLR, 2022
2022
-
[50]
Conformal language modeling.arXiv preprint arXiv:2306.10193, 2023
Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi S Jaakkola, and Regina Barzilay. Conformal language modeling.arXiv preprint arXiv:2306.10193, 2023
-
[51]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3505–3506, 2020. 12
2020
-
[52]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
2023
-
[53]
A tutorial on conformal prediction.Journal of machine learning research, 9(3), 2008
Glenn Shafer and Vladimir V ovk. A tutorial on conformal prediction.Journal of machine learning research, 9(3), 2008
2008
-
[54]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Cost-aware contrastive routing for LLMs
Reza Shirkavand, Shangqian Gao, Peiran Yu, and Heng Huang. Cost-aware contrastive routing for LLMs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[56]
The curious case of hallucinatory (un) answerability: Finding truths in the hidden states of over-confident large language models
Aviv Slobodkin, Omer Goldman, Avi Caciularu, Ido Dagan, and Shauli Ravfogel. The curious case of hallucinatory (un) answerability: Finding truths in the hidden states of over-confident large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3607–3625, 2023
2023
-
[57]
Api is enough: Conformal prediction for large language models without logit-access
Jiayuan Su, Jing Luo, Hongwei Wang, and Lu Cheng. Api is enough: Conformal prediction for large language models without logit-access. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 979–995, 2024
2024
-
[58]
Fengfei Sun, Ningke Li, Kailong Wang, and Lorenz Goette. Large language models are overconfident and amplify human bias.arXiv preprint arXiv:2505.02151, 2025
-
[59]
Gemma 3 technical report, 2025
Gemma Team et al. Gemma 3 technical report, 2025
2025
-
[60]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages ...
2023
-
[61]
Aime problem set 1983-2024, 2023
Hemish Veeraboina. Aime problem set 1983-2024, 2023
1983
-
[62]
Springer, 2005
Vladimir V ovk, Alexander Gammerman, and Glenn Shafer.Algorithmic learning in a random world. Springer, 2005
2005
-
[63]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024
2024
-
[64]
Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics, 13:529–556, 2025
Bingbing Wen, Jihan Yao, Shangbin Feng, Chenjun Xu, Yulia Tsvetkov, Bill Howe, and Lucy Lu Wang. Know your limits: A survey of abstention in large language models.Transactions of the Association for Computational Linguistics, 13:529–556, 2025
2025
-
[65]
Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36:69798–69818, 2023
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36:69798–69818, 2023
2023
-
[66]
The art of abstention: Selective prediction and error regularization for natural language processing
Ji Xin, Raphael Tang, Yaoliang Yu, and Jimmy Lin. The art of abstention: Selective prediction and error regularization for natural language processing. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1040–1051, 2021
2021
-
[67]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
Qiantong Xu, Fenglu Hong, Bo Li, Changran Hu, Zhengyu Chen, and Jian Zhang. On the tool manipulation capability of open-source large language models.arXiv preprint arXiv:2305.16504, 2023
-
[69]
Qwen3 technical report, 2025
An Yang et al. Qwen3 technical report, 2025
2025
-
[70]
On Verbalized Confidence Scores for LLMs
Daniel Yang, Yao-Hung Hubert Tsai, and Makoto Yamada. On verbalized confidence scores for llms.arXiv preprint arXiv:2412.14737, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[72]
Do large language models know what they don’t know? InFindings of the association for Computational Linguistics: ACL 2023, pages 8653–8665, 2023
Zhangyue Yin, Qiushi Sun, Qipeng Guo, Jiawen Wu, Xipeng Qiu, and Xuan-Jing Huang. Do large language models know what they don’t know? InFindings of the association for Computational Linguistics: ACL 2023, pages 8653–8665, 2023
2023
-
[73]
Dapo: An open-source llm reinforcement learning system at scale, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
2025
-
[74]
learning with rejection
Hanning Zhang, Shizhe Diao, Yong Lin, Yi Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. R-tuning: Instructing large language models to say ‘i don’t know’. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7113...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.