Reroute, Don't Remove: Recoverable Visual Token Routing for Vision-Language Models
Pith reviewed 2026-06-27 09:33 UTC · model grok-4.3
The pith
Recoverable routing of visual tokens improves grounding in vision-language models by deferring rather than discarding low-ranked tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
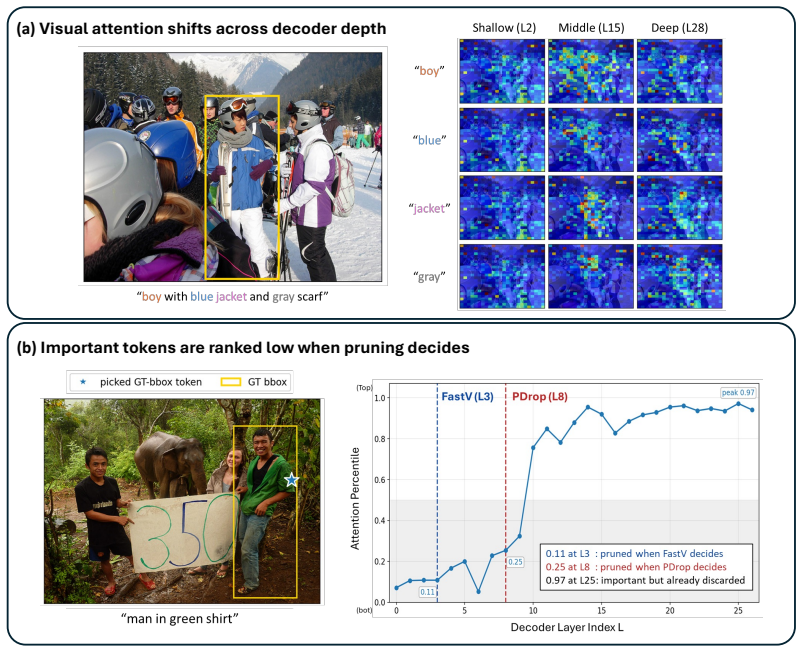
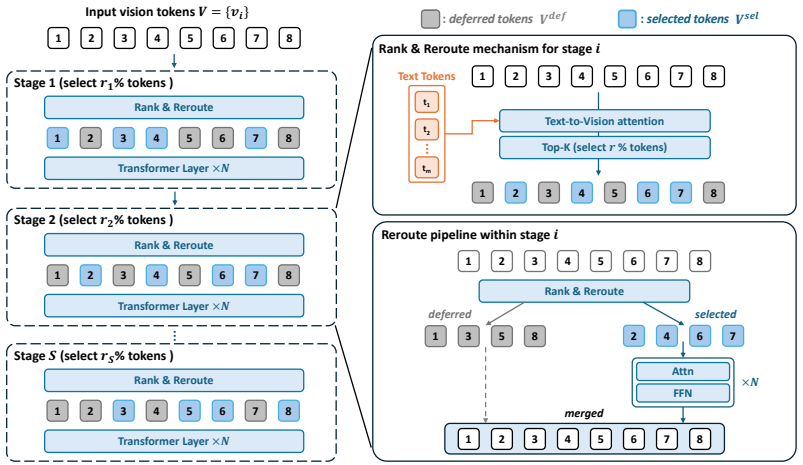
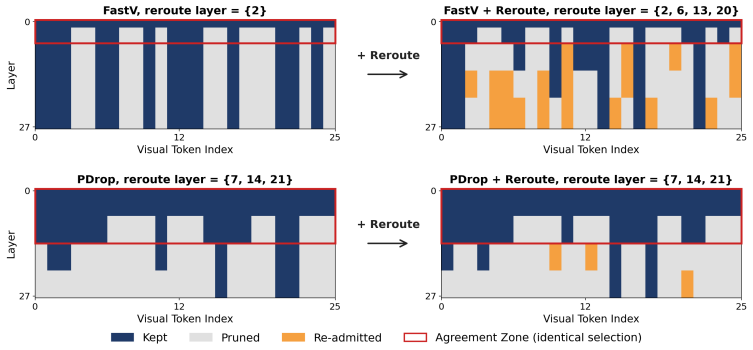
Replacing rank-and-remove with recoverable routing—where selected tokens pass through decoder blocks while others bypass the stage and re-enter the pool at the next decision—recovers grounding performance lost to irreversible pruning, all without changing the theoretical TFLOPs or KV-cache budget of the underlying method.
What carries the argument
Recoverable visual token routing, a bypass mechanism that defers tokens to re-enter the candidate pool at subsequent routing stages while reusing attention-score ranking rules.
If this is right
- Reroute augments existing methods like FastV, PDrop, and Nuwa without altering their computational class.
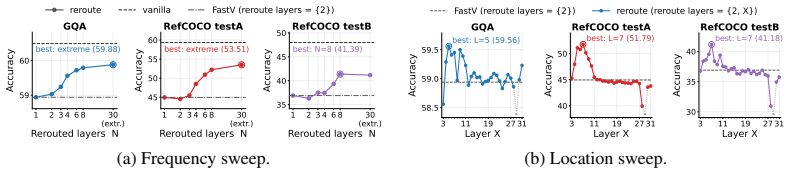
- Grounding improves under aggressive token reduction on LLaVA-1.5 and Qwen backbones.
- General VQA performance is maintained at the same reduction levels.
- Token reduction is better viewed as recoverable routing than irreversible pruning.
Where Pith is reading between the lines
- If importance shifts prove query-dependent, making routing decisions conditional on query type could further optimize the bypass logic.
- The bypass pattern might transfer to other efficiency techniques in multimodal models where intermediate representations evolve.
- Testing reroute on tasks beyond grounding and VQA could reveal whether the recoverability benefit holds for broader reasoning or captioning.
Load-bearing premise
Token importance genuinely changes across decoder depth such that re-entry of deferred tokens improves outcomes without hidden overhead or distribution shift invalidating the original pruning schedules.
What would settle it
A controlled experiment on the same models, token budgets, and schedules where reroute produces equal or worse grounding scores than the base removal method.
Figures

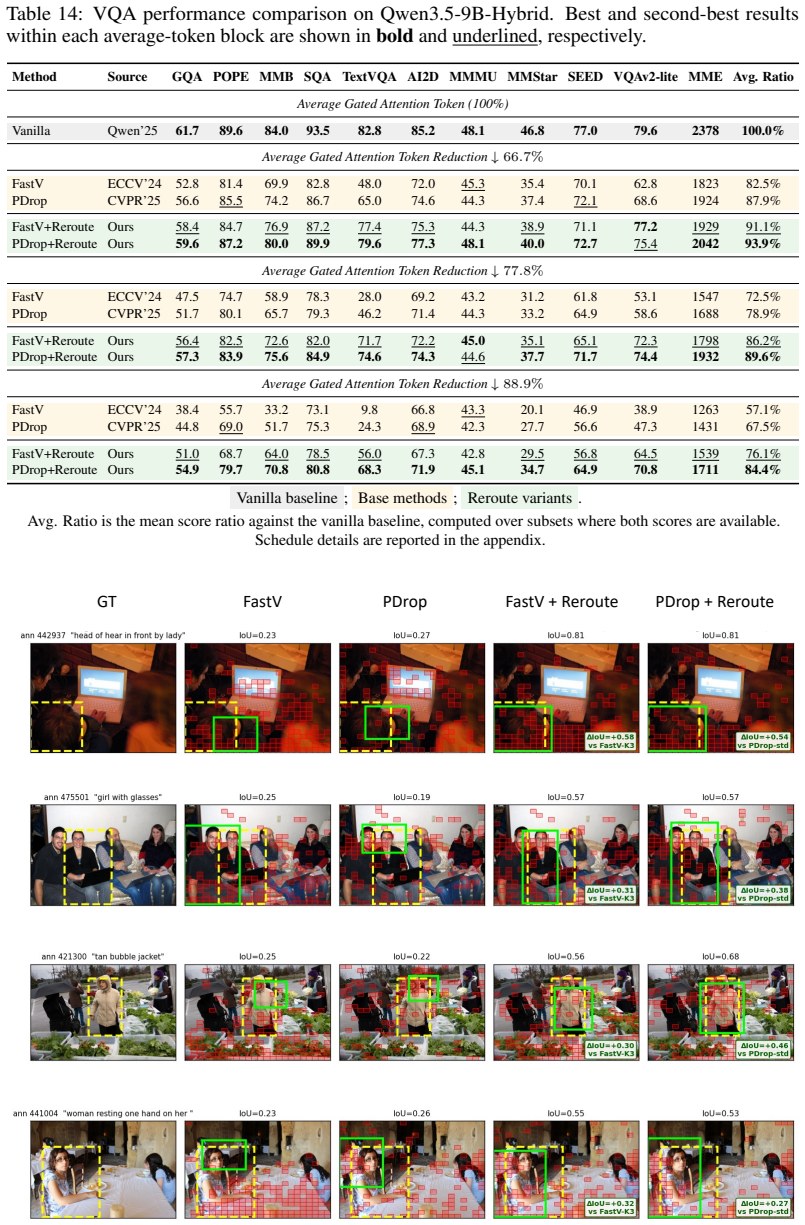

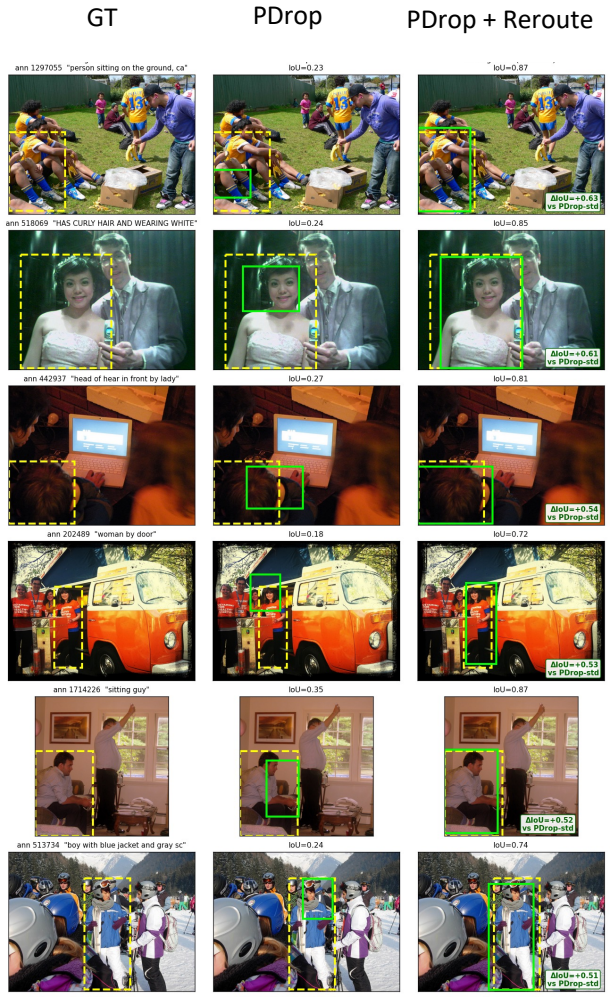
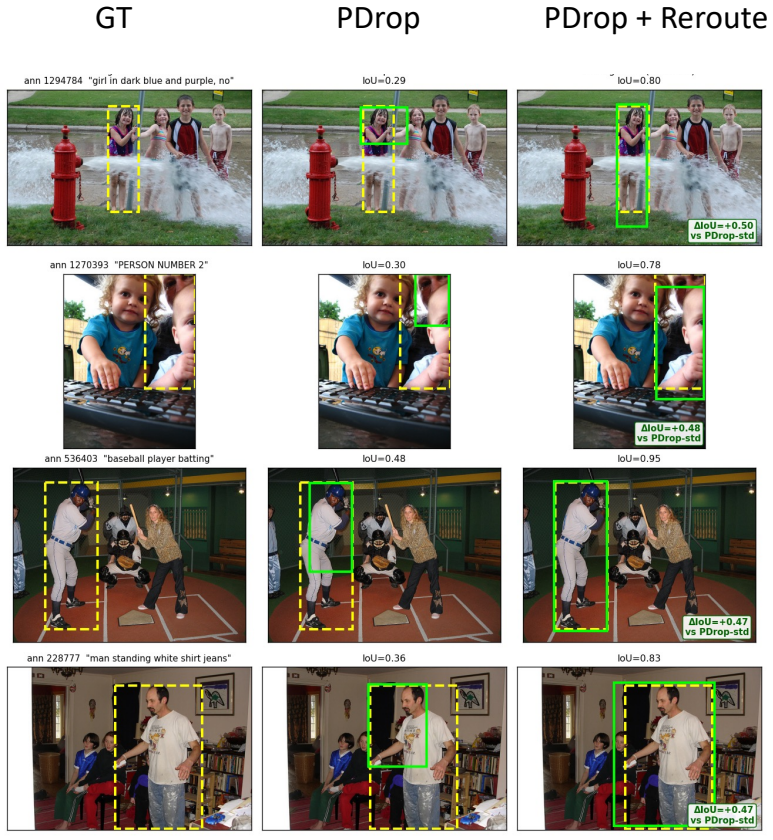

read the original abstract
Vision-language models (VLMs) project images into hundreds to thousands of visual tokens, making decoder inference expensive in both attention computation and KV-cache memory. Existing visual-token reduction methods largely follow a rank-and-remove paradigm: they score visual tokens, keep a compact subset, and permanently discard the rest. We show that this irreversible action is fragile because visual-token importance changes across decoder depth; tokens ranked low at one stage may become relevant in later layers, especially for grounding-sensitive queries. We propose Reroute, a training-free plug-in that replaces removal with recoverable routing. At each routing stage, selected vision tokens pass through decoder blocks, while deferred tokens bypass the stage and re-enter the candidate pool at the next routing decision. Reroute reuses existing attention-score ranking rules and stage-wise schedules, preserving the theoretical TFLOPs and KV-cache budget class of the pruning method it augments. Across FastV, PDrop, and N\"uwa variants on LLaVA-1.5 and Qwen backbones, reroute improves grounding under aggressive token reduction while maintaining general VQA performance. These results suggest that VLM token reduction should not be viewed only as irreversible pruning, but also as recoverable routing. The code can be found here: https://github.com/elmma/mllm-reroute/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Reroute, a training-free plug-in that augments existing visual-token pruning methods (FastV, PDrop, Nuwa) for VLMs. Instead of permanently discarding low-ranked visual tokens, deferred tokens bypass the current decoder stage and re-enter the candidate pool for later routing decisions. The method reuses the base methods' attention-score ranking rules and stage-wise schedules, preserving the original TFLOPs/KV-cache budget class. Experiments on LLaVA-1.5 and Qwen backbones report improved grounding metrics under aggressive token reduction while maintaining general VQA performance.
Significance. If the reported gains hold after verification that bypass-induced distribution shifts do not invalidate the reused ranking schedules, the work demonstrates that recoverable routing can mitigate fragility in irreversible pruning when token importance varies across decoder depth. This reframes token reduction as a routing problem rather than pure pruning and is supported by open-sourced code, which aids reproducibility.
major comments (2)
- [Method] Method description (around the reroute mechanism): the claim that original attention-score ranking rules can be directly reused is load-bearing for the central empirical claim, yet the bypass alters active-token sequence length and thus post-layer hidden states relative to the full-sequence calibration on which the base heuristics were derived. No analysis or ablation quantifies whether this changes subsequent token selections, especially for grounding queries.
- [Experiments] Experiments section (grounding results across FastV/PDrop/Nuwa variants): the performance deltas are the primary evidence, but it is unclear whether identical token budgets were enforced after rerouting and whether multiple-testing correction was applied across backbones and baselines; without this, the cross-method improvement claim cannot be fully assessed.
minor comments (2)
- [Abstract] Abstract: the phrase 'consistent gains' would be clearer if accompanied by the specific token-reduction ratios and effect sizes.
- [Related Work] Related work: ensure explicit citation of the original FastV, PDrop, and Nuwa papers when describing the reused schedules.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Method] Method description (around the reroute mechanism): the claim that original attention-score ranking rules can be directly reused is load-bearing for the central empirical claim, yet the bypass alters active-token sequence length and thus post-layer hidden states relative to the full-sequence calibration on which the base heuristics were derived. No analysis or ablation quantifies whether this changes subsequent token selections, especially for grounding queries.
Authors: We acknowledge that bypassing deferred tokens reduces the active sequence length at each stage, which may induce distribution shifts relative to the original full-sequence derivations of the base heuristics. Reroute reapplies the base scoring function only to the current candidate pool at the decision point; however, we did not quantify how these length changes propagate to later selections. We will add a dedicated discussion paragraph and a targeted ablation (token-selection overlap with/without bypass) in the revised method section. revision: yes
-
Referee: [Experiments] Experiments section (grounding results across FastV/PDrop/Nuwa variants): the performance deltas are the primary evidence, but it is unclear whether identical token budgets were enforced after rerouting and whether multiple-testing correction was applied across backbones and baselines; without this, the cross-method improvement claim cannot be fully assessed.
Authors: Reroute maintains the identical per-stage token count and reduction schedule of each base method, thereby preserving the same TFLOPs and KV-cache budgets; we will make this equivalence explicit with a table in the experiments section. We will also apply multiple-testing correction (Bonferroni) to the reported comparisons across backbones and baselines in the revision. revision: partial
Circularity Check
No circularity: empirical augmentation of existing pruning schedules with no self-referential derivation or fitted prediction.
full rationale
The paper presents Reroute as a training-free plug-in that reuses attention-score ranking rules and stage-wise schedules from prior work (FastV, PDrop, Nuwa) without deriving, fitting, or redefining those rules inside the manuscript. The central claims are empirical performance deltas on grounding and VQA tasks across LLaVA-1.5 and Qwen backbones; no equations, uniqueness theorems, or predictions reduce by construction to quantities defined or fitted within the paper itself. The method description is self-contained as a recoverable-routing modification that preserves the original TFLOPs/KV budget class by design, with no load-bearing self-citation chain or ansatz smuggling. This is the normal case of an empirical method paper whose results stand or fall on external benchmarks rather than internal definitional closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing attention-score ranking rules remain valid when tokens bypass a decoder stage and re-enter the candidate pool.
Reference graph
Works this paper leans on
-
[1]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9392–9401, 2025
2025
-
[2]
Hired: Attention-guided token dropping for efficient inference of high-resolution vision-language models
Kazi Hasan Ibn Arif, JinYi Yoon, Dimitrios S Nikolopoulos, Hans Vandierendonck, Deepu John, and Bo Ji. Hired: Attention-guided token dropping for efficient inference of high-resolution vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 1773–1781, 2025
2025
-
[3]
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, et al. Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation.arXiv preprint arXiv:2507.10524, 2025
-
[4]
Efficient video sampling: Pruning temporally redundant tokens for faster vlm inference, 2025
Natan Bagrov, Eugene Khvedchenia, Borys Tymchenko, Shay Aharon, Lior Kadoch, Tomer Keren, Ofri Masad, Yonatan Geifman, Ran Zilberstein, Tuomas Rintamaki, Matthieu Le, and Andrew Tao. Efficient video sampling: Pruning temporally redundant tokens for faster vlm inference, 2025. URLhttps://arxiv.org/abs/2510.14624
-
[5]
Qwen-vl: A versatile vision-language model for understanding, localization.Text Reading, and Beyond, 2(1):1, 2023
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization.Text Reading, and Beyond, 2(1):1, 2023
2023
-
[6]
Qwen2.5-vl technical report,
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[7]
URLhttps://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Matryoshka multimodal models.arXiv preprint arXiv:2405.17430, 2024
Mu Cai, Jianwei Yang, Jianfeng Gao, and Yong Jae Lee. Matryoshka multimodal models.arXiv preprint arXiv:2405.17430, 2024
-
[10]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Honeybee: Locality- enhanced projector for multimodal llm
Junbum Cha, Wooyoung Kang, Jonghwan Mun, and Byungseok Roh. Honeybee: Locality- enhanced projector for multimodal llm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13817–13827, 2024
2024
-
[12]
Efficient large multi-modal models via visual context compression.Advances in neural information processing systems, 37:73986–74007, 2024
Jieneng Chen, Luoxin Ye, Ju He, Zhao-Yang Wang, Daniel Khashabi, and Alan Yuille. Efficient large multi-modal models via visual context compression.Advances in neural information processing systems, 37:73986–74007, 2024
2024
-
[13]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024. 10
2024
-
[14]
Recover- able compression: A multimodal vision token recovery mechanism guided by text information
Yi Chen, Jian Xu, Xu-Yao Zhang, Wen-Zhuo Liu, Yang-Yang Liu, and Cheng-Lin Liu. Recover- able compression: A multimodal vision token recovery mechanism guided by text information. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 2293–2301, 2025
2025
-
[15]
Evoprune: Early-stage visual token pruning for efficient mllms.arXiv preprint arXiv:2603.03681, 2026
Yuhao Chen, Bin Shan, Xin Ye, and Cheng Chen. Evoprune: Early-stage visual token pruning for efficient mllms.arXiv preprint arXiv:2603.03681, 2026
-
[16]
Tzu-Chun Chien, Chieh-Kai Lin, Shiang-Feng Tsai, Ruei-Chi Lai, Hung-Jen Chen, and Min Sun. Grounding-aware token pruning: Recovering from drastic performance drops in visual grounding caused by pruning, 2025. URLhttps://arxiv.org/abs/2506.21873
-
[17]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
2022
-
[18]
Feather the throttle: Revisiting visual token pruning for vision-language model acceleration
Mark Endo, Xiaohan Wang, and Serena Yeung-Levy. Feather the throttle: Revisiting visual token pruning for vision-language model acceleration. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22826–22835, 2025
2025
-
[19]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. Model tells you what to discard: Adaptive kv cache compression for llms.arXiv preprint arXiv:2310.01801, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Yefei He, Feng Chen, Jing Liu, Wenqi Shao, Hong Zhou, Kaipeng Zhang, and Bohan Zhuang. Zipvl: Efficient large vision-language models with dynamic token sparsification.arXiv preprint arXiv:2410.08584, 2024
-
[23]
Lianyu Hu, Liqing Gao, Fanhua Shang, Liang Wan, and Wei Feng. illava: An image is worth fewer than 1/3 input tokens in large multimodal models.arXiv preprint arXiv:2412.06263, 2024
-
[24]
Ma- tryoshka query transformer for large vision-language models.Advances in Neural Information Processing Systems, 37:50168–50188, 2024
Wenbo Hu, Zi-Yi Dou, Liunian H Li, Amita Kamath, Nanyun Peng, and Kai-Wei Chang. Ma- tryoshka query transformer for large vision-language models.Advances in Neural Information Processing Systems, 37:50168–50188, 2024
2024
-
[25]
Multi-Scale Dense Networks for Resource Efficient Image Classification
Gao Huang, Danlu Chen, Tianhong Li, Felix Wu, Laurens Van Der Maaten, and Kilian Q Weinberger. Multi-scale dense networks for resource efficient image classification.arXiv preprint arXiv:1703.09844, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Wenxuan Huang, Zijie Zhai, Yunhang Shen, Shaosheng Cao, Fei Zhao, Xiangfeng Xu, Zheyu Ye, Yao Hu, and Shaohui Lin. Dynamic-llava: Efficient multimodal large language models via dynamic vision-language context sparsification.arXiv preprint arXiv:2412.00876, 2024
-
[27]
Yihong Huang, Fei Ma, Yihua Shao, Jingcai Guo, Zitong Yu, Laizhong Cui, and Qi Tian. N\" uwa: Mending the spatial integrity torn by vlm token pruning.arXiv preprint arXiv:2602.02951, 2026
-
[28]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
2019
-
[29]
Lei Jiang, Weizhe Huang, Tongxuan Liu, Yuting Zeng, Jing Li, Lechao Cheng, and Xiao- hua Xu. Fopru: Focal pruning for efficient large vision-language models.arXiv preprint arXiv:2411.14164, 2024. 11
-
[30]
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models.arXiv preprint arXiv:2503.03321, 2025
-
[31]
Referitgame: Referring to objects in photographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014
2014
-
[32]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[33]
Learning to skip the middle layers of transformers.arXiv preprint arXiv:2506.21103, 2025
Tim Lawson and Laurence Aitchison. Learning to skip the middle layers of transformers.arXiv preprint arXiv:2506.21103, 2025
-
[34]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed- bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Cumo: Scaling multimodal llm with co-upcycled mixture-of-experts
Jiachen Li, Xinyao Wang, Sijie Zhu, Chia-Wen Kuo, Lu Xu, Fan Chen, Jitesh Jain, Humphrey Shi, and Longyin Wen. Cumo: Scaling multimodal llm with co-upcycled mixture-of-experts. Advances in Neural Information Processing Systems, 37:131224–131246, 2024
2024
-
[36]
Tokenpacker: Efficient visual projector for multimodal llm.International Journal of Computer Vision, 133(10):6794–6812, 2025
Wentong Li, Yuqian Yuan, Jian Liu, Dongqi Tang, Song Wang, Jie Qin, Jianke Zhu, and Lei Zhang. Tokenpacker: Efficient visual projector for multimodal llm.International Journal of Computer Vision, 133(10):6794–6812, 2025
2025
-
[37]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
2023
-
[38]
Snapkv: Llm knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024
2024
-
[39]
Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, Jue Wang, and Pengtao Xie. Not all patches are what you need: Expediting vision transformers via token reorganizations.arXiv preprint arXiv:2202.07800, 2022
-
[40]
Moe-llava: Mixture of experts for large vision-language models
Bin Lin, Zhenyu Tang, Yang Ye, Jinfa Huang, Junwu Zhang, Yatian Pang, Peng Jin, Munan Ning, Jiebo Luo, and Li Yuan. Moe-llava: Mixture of experts for large vision-language models. IEEE Transactions on Multimedia, 2026
2026
-
[41]
Boosting multimodal large language models with visual tokens withdrawal for rapid inference
Zhihang Lin, Mingbao Lin, Luxi Lin, and Rongrong Ji. Boosting multimodal large language models with visual tokens withdrawal for rapid inference. InProceedings of the AAAI Confer- ence on Artificial Intelligence, volume 39, pages 5334–5342, 2025
2025
-
[42]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[43]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
2024
-
[44]
Hiprune: Training-free visual token pruning via hierarchical attention in vision-language models (student abstract)
Jizhihui Liu, Guangdao Zhu, and Feiyi Du. Hiprune: Training-free visual token pruning via hierarchical attention in vision-language models (student abstract). InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 41275–41277, 2026
2026
-
[45]
Ting Liu, Liangtao Shi, Richang Hong, Yue Hu, Quanjun Yin, and Linfeng Zhang. Multi-stage vision token dropping: Towards efficient multimodal large language model.arXiv preprint arXiv:2411.10803, 2024
-
[46]
Fastbert: a self- distilling bert with adaptive inference time
Weijie Liu, Peng Zhou, Zhiruo Wang, Zhe Zhao, Haotang Deng, and Qi Ju. Fastbert: a self- distilling bert with adaptive inference time. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 6035–6044, 2020. 12
2020
-
[47]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[48]
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of impor- tance hypothesis for llm kv cache compression at test time.Advances in Neural Information Processing Systems, 36:52342–52364, 2023
2023
-
[49]
Efficient inference of vision instruction-following models with elastic cache
Zuyan Liu, Benlin Liu, Jiahui Wang, Yuhao Dong, Guangyi Chen, Yongming Rao, Ranjay Krishna, and Jiwen Lu. Efficient inference of vision instruction-following models with elastic cache. InEuropean Conference on Computer Vision, pages 54–69. Springer, 2024
2024
-
[50]
Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in neural information processing systems, 35: 2507–2521, 2022
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in neural information processing systems, 35: 2507–2521, 2022
2022
-
[51]
Yaxin Luo, Gen Luo, Jiayi Ji, Yiyi Zhou, Xiaoshuai Sun, Zhiqiang Shen, and Rongrong Ji. γ−mod: Exploring mixture-of-depth adaptation for multimodal large language models.arXiv preprint arXiv:2410.13859, 2024
-
[52]
Papr: Training- free one-step patch pruning with lightweight convnets for faster inference
Tanvir Mahmud, Burhaneddin Yaman, Chun-Hao Liu, and Diana Marculescu. Papr: Training- free one-step patch pruning with lightweight convnets for faster inference. InEuropean Conference on Computer Vision, pages 110–128. Springer, 2024
2024
-
[53]
Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms
Lingchen Meng, Jianwei Yang, Rui Tian, Xiyang Dai, Zuxuan Wu, Jianfeng Gao, and Yu-Gang Jiang. Deepstack: Deeply stacking visual tokens is surprisingly simple and effective for lmms. Advances in Neural Information Processing Systems, 37:23464–23487, 2024
2024
-
[54]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[55]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
2026
-
[56]
Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021
2021
-
[57]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
David Raposo, Sam Ritter, Blake Richards, Timothy Lillicrap, Peter Conway Humphreys, and Adam Santoro. Mixture-of-depths: Dynamically allocating compute in transformer-based language models.arXiv preprint arXiv:2404.02258, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Confident adaptive language modeling.Advances in Neural Information Processing Systems, 35:17456–17472, 2022
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Tran, Yi Tay, and Donald Metzler. Confident adaptive language modeling.Advances in Neural Information Processing Systems, 35:17456–17472, 2022
2022
-
[59]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22857–22867, 2025
2025
-
[60]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019
2019
-
[61]
Massive Activations in Large Language Models
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models.arXiv preprint arXiv:2402.17762, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Branchynet: Fast inference via early exiting from deep neural networks
Surat Teerapittayanon, Bradley McDanel, and Hsiang-Tsung Kung. Branchynet: Fast inference via early exiting from deep neural networks. In2016 23rd international conference on pattern recognition (ICPR), pages 2464–2469. IEEE, 2016. 13
2016
-
[63]
Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference
Zhongwei Wan, Ziang Wu, Che Liu, Jinfa Huang, Zhihong Zhu, Peng Jin, Longyue Wang, and Li Yuan. Look-m: Look-once optimization in kv cache for efficient multimodal long-context inference. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4065–4078, 2024
2024
-
[64]
Folder: Accelerating multi-modal large language models with enhanced performance
Haicheng Wang, Zhemeng Yu, Gabriele Spadaro, Chen Ju, Victor Quétu, Shuai Xiao, and Enzo Tartaglione. Folder: Accelerating multi-modal large language models with enhanced performance. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23614–23625, 2025
2025
-
[65]
Skipnet: Learning dynamic routing in convolutional networks
Xin Wang, Fisher Yu, Zi-Yi Dou, Trevor Darrell, and Joseph E Gonzalez. Skipnet: Learning dynamic routing in convolutional networks. InProceedings of the European conference on computer vision (ECCV), pages 409–424, 2018
2018
-
[66]
Qiong Wu, Wenhao Lin, Yiyi Zhou, Weihao Ye, Zhanpeng Zen, Xiaoshuai Sun, and Rongrong Ji. Accelerating multimodal large language models via dynamic visual-token exit and the empirical findings.arXiv preprint arXiv:2411.19628, 2024
-
[67]
Routing experts: Learning to route dynamic experts in existing multi-modal large language models
Qiong Wu, Zhaoxi Ke, Yiyi Zhou, Xiaoshuai Sun, and Rongrong Ji. Routing experts: Learning to route dynamic experts in existing multi-modal large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[68]
Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. Retrieval head mecha- nistically explains long-context factuality.arXiv preprint arXiv:2404.15574, 2024
-
[69]
Blockdrop: Dynamic inference paths in residual networks
Zuxuan Wu, Tushar Nagarajan, Abhishek Kumar, Steven Rennie, Larry S Davis, Kristen Grauman, and Rogerio Feris. Blockdrop: Dynamic inference paths in residual networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8817–8826, 2018
2018
-
[70]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[71]
Deebert: Dynamic early exiting for accelerating bert inference
Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, and Jimmy Lin. Deebert: Dynamic early exiting for accelerating bert inference. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 2246–2251, 2020
2020
-
[72]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.arXiv preprint arXiv:2410.17247, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Topv: Compatible token pruning with inference time optimization for fast and low-memory multimodal vision language model
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Chendi Li, Jinghua Yan, Yu Bai, Ponnuswamy Sadayappan, Xia Hu, et al. Topv: Compatible token pruning with inference time optimization for fast and low-memory multimodal vision language model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19803–19813, 2025
2025
-
[74]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792–19802, 2025
2025
-
[75]
Gated delta networks: Improving mamba2 with delta rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=r8H7xhYPwz
2025
-
[76]
Fit and prune: Fast and training-free visual token pruning for multi-modal large language models
Weihao Ye, Qiong Wu, Wenhao Lin, and Yiyi Zhou. Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22128–22136, 2025
2025
-
[77]
Atp-llava: Adaptive token pruning for large vision language models
Xubing Ye, Yukang Gan, Yixiao Ge, Xiao-Ping Zhang, and Yansong Tang. Atp-llava: Adaptive token pruning for large vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24972–24982, 2025. 14
2025
-
[78]
V oco-llama: Towards vision compression with large language models
Xubing Ye, Yukang Gan, Xiaoke Huang, Yixiao Ge, and Yansong Tang. V oco-llama: Towards vision compression with large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29836–29846, 2025
2025
-
[79]
Lifting the veil on visual information flow in mllms: unlocking pathways to faster inference
Hao Yin, Guangzong Si, and Zilei Wang. Lifting the veil on visual information flow in mllms: unlocking pathways to faster inference. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9382–9391, 2025
2025
-
[80]
Modeling context in referring expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. InEuropean conference on computer vision, pages 69–85. Springer, 2016
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.