SMSR: Certified Defence Against Runtime Memory Poisoning in Persistent LLM Agent Systems
Pith reviewed 2026-06-27 08:56 UTC · model grok-4.3
The pith
SMSR certifies the first robustness bound against multi-session memory poisoning in persistent LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
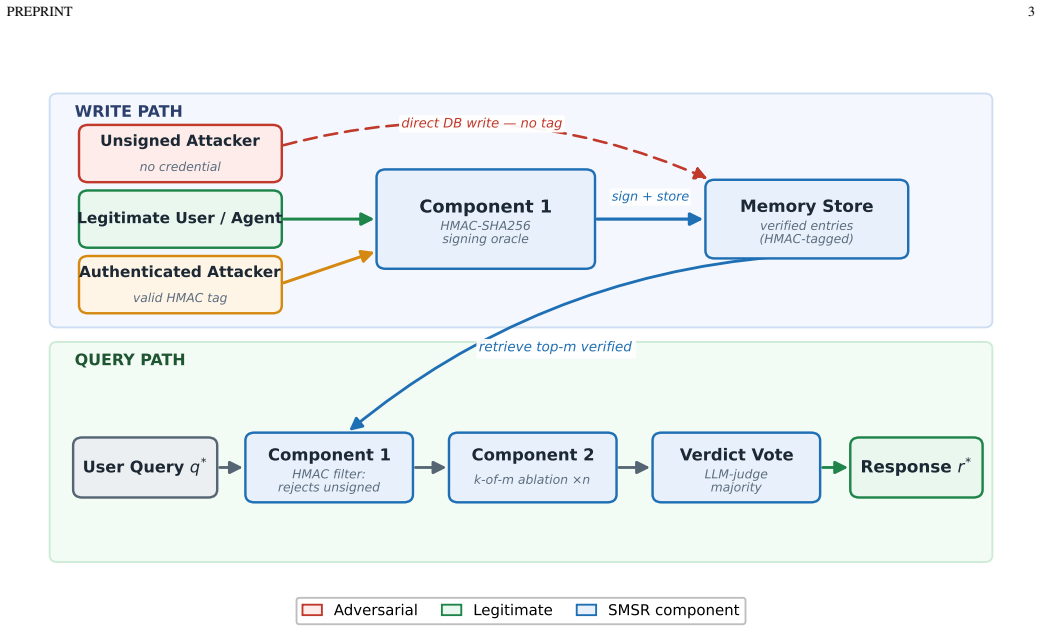
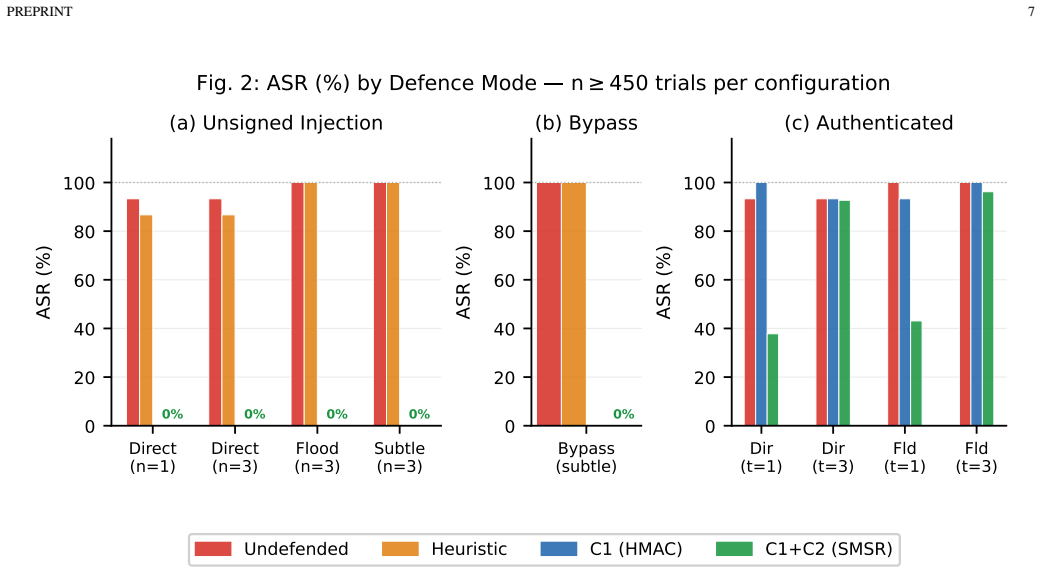
SMSR is the first defense with a certified robustness bound for multi-session memory poisoning. Component 1 uses HMAC-SHA256 provenance to block all unsigned injections. Component 2 applies randomized memory ablation and verdict-based majority voting to bound the influence of an authenticated adversary; the paper derives the corresponding hypergeometric certificate and formalizes the Consistent Minority Effect that explains why verdict voting succeeds where string-based voting fails. No provenance-free retrieval filter can certify against adaptive injection.
What carries the argument
Signed Memory with Smoothed Retrieval, consisting of HMAC-SHA256 provenance at write time together with randomized ablation and verdict-based majority voting at query time.
If this is right
- Unsigned memory injections are eliminated entirely by the provenance check.
- Authenticated single-injection success is bounded by the hypergeometric certificate derived from randomized ablation and verdict voting.
- End-to-end query-only attacks, where the agent itself writes the poison, drop from 65 percent to 5 percent success.
- Clean-query utility remains at 90 percent with signatures alone and 85 percent with both components.
Where Pith is reading between the lines
- The same signing-plus-ablation pattern could be applied to other forms of persistent state that agents accumulate over sessions.
- Testing the bound under multi-injection scenarios would clarify how the certificate scales when more than one poisoned memory is present.
- Combining SMSR with existing RAG optimizations might recover additional utility while preserving the certified guarantee.
Load-bearing premise
The hypergeometric certificate for the smoothed component assumes the adversary cannot control the random ablation process or the model's internal verdict generation beyond the injected memory content.
What would settle it
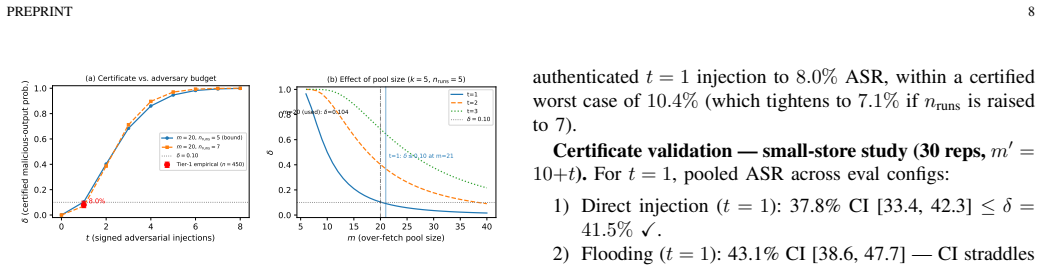
An experiment in which an adaptive attacker manipulates model verdicts or the ablation randomness to produce attack success rates materially above the certified 8 percent bound on authenticated single-injection attacks.
Figures

read the original abstract
Retrieval-augmented generation (RAG) agents increasingly run with persistent memory that accumulates across user sessions. This creates a new attack surface: an adversary interacting only through normal channels can inject crafted memories that, once retrieved, steer the agent's responses for future users, without touching model weights or code. We call this Multi-Session Memory Poisoning (MSMP) and show that no existing defence certifies against it; static-corpus defences (RobustRAG, ReliabilityRAG) assume a fixed knowledge base, and heuristic filters are bypassed by fluent enterprise-style text. We present Signed Memory with Smoothed Retrieval (SMSR), the first defence with a certified robustness bound for this setting. Component 1 adds HMAC-SHA256 provenance at write time, blocking unsigned injection. Component 2 applies randomised memory ablation with verdict-based majority voting at query time, bounding the influence of authenticated adversaries. We prove that no provenance-free retrieval-time filter can certify against adaptive injection, derive a hypergeometric certificate for Component 2, and formalise the Consistent Minority Effect, whereby a consistent adversarial answer wins string-based voting as a numerical minority while verdict-based voting removes it. Across 15 enterprise scenarios (3,150 repeated trials), Component 1 cuts attack success from 93-100% to 0% for all unsigned variants. For an authenticated adversary with a single injection, Component 2 holds success to 8.0% (95% CI [5.8, 10.9], n=450), below the certified worst case. In an end-to-end query-only attack where the agent itself writes the poison rather than it being pre-seeded, SMSR reduces success from 65.3% to 5.3% (n=150, non-overlapping CIs) on a live agent stack. Clean-query utility is 90% (Component 1) and 85% (combined).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SMSR as the first certified defense against Multi-Session Memory Poisoning (MSMP) in persistent LLM agent systems. Component 1 uses HMAC-SHA256 provenance to block all unsigned injections at write time. Component 2 applies randomized memory ablation followed by verdict-based majority voting at query time, with a hypergeometric tail bound providing a certified robustness guarantee against authenticated single-injection adversaries. The paper proves that no provenance-free retrieval-time filter can certify against adaptive injection, formalizes the Consistent Minority Effect, and reports empirical results on 15 enterprise scenarios (3,150 trials) showing attack success reduced from 93-100% to 0% (unsigned) and to 8.0% (95% CI [5.8, 10.9], n=450) for authenticated single injection, plus an end-to-end query-only attack reduction from 65.3% to 5.3% (n=150).
Significance. If the hypergeometric certificate holds under its stated assumptions, the work would be a significant contribution as the first to deliver a formal robustness bound for runtime memory poisoning in multi-session RAG agents, filling a gap left by static-corpus defenses such as RobustRAG. The combination of a non-existence proof for provenance-free filters, the Consistent Minority Effect formalization, and concrete empirical reductions with confidence intervals on realistic scenarios strengthens the paper. Reproducible trial counts and non-overlapping CIs are positive features.
major comments (2)
- [hypergeometric certificate derivation] Derivation of the hypergeometric certificate for Component 2 (abstract and associated proof section): the bound is derived from a hypergeometric tail on surviving poisoned memories after random ablation plus majority vote on model verdicts. This requires that (1) the ablation mask is sampled independently of the adversary and (2) each verdict is a deterministic function of memory content alone. The manuscript states the premise but supplies no experiments validating it against an adaptive attacker who can also shape prompt context, retrieval scoring, or the verdict model's behavior through the agent interface; this assumption is load-bearing for the certified robustness claim.
- [empirical evaluation of Component 2] Evaluation of Component 2 (abstract and § on empirical results): the reported 8.0% success rate (n=450) is stated to lie below the certified worst case, but the exact hypergeometric parameters (number of memories, ablation rate, number of votes) and how they were selected are not cross-referenced to the bound derivation, preventing verification that the bound actually covers the evaluated adaptive case.
minor comments (1)
- [abstract] The abstract reports concrete success rates and CIs but does not list the precise ablation rate or vote threshold used in the hypergeometric bound, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the significance of the certified bound for multi-session memory poisoning. We address each major comment below.
read point-by-point responses
-
Referee: [hypergeometric certificate derivation] Derivation of the hypergeometric certificate for Component 2 (abstract and associated proof section): the bound is derived from a hypergeometric tail on surviving poisoned memories after random ablation plus majority vote on model verdicts. This requires that (1) the ablation mask is sampled independently of the adversary and (2) each verdict is a deterministic function of memory content alone. The manuscript states the premise but supplies no experiments validating it against an adaptive attacker who can also shape prompt context, retrieval scoring, or the verdict model's behavior through the agent interface; this assumption is load-bearing for the certified robustness claim.
Authors: The hypergeometric certificate is derived as a conditional bound that holds precisely when the ablation mask is chosen independently of the adversary and when each verdict depends deterministically on memory content alone; both premises are stated in the proof section. We agree that an adaptive adversary able to influence verdict behavior through the agent interface could in principle violate the second premise when verdicts are produced by an LLM. The current manuscript therefore presents the bound under these explicit assumptions rather than claiming unconditional robustness. In revision we will expand the discussion to clarify the scope of the certificate, note the potential gap when verdicts are LLM-mediated, and state that full empirical validation against such interface-level adaptation remains future work while the reported empirical rates already lie below the certified worst-case under the evaluated threat model. revision: partial
-
Referee: [empirical evaluation of Component 2] Evaluation of Component 2 (abstract and § on empirical results): the reported 8.0% success rate (n=450) is stated to lie below the certified worst case, but the exact hypergeometric parameters (number of memories, ablation rate, number of votes) and how they were selected are not cross-referenced to the bound derivation, preventing verification that the bound actually covers the evaluated adaptive case.
Authors: We agree that explicit cross-referencing is needed for verifiability. In the revised manuscript we will add direct pointers from the empirical results section to the precise hypergeometric parameters (memory pool size, ablation probability, and vote count) used in the evaluation, together with a short explanation of how those parameters were chosen to match the single-injection authenticated threat model and the bound derivation. revision: yes
Circularity Check
No circularity: hypergeometric certificate is a standard worst-case bound independent of evaluation data
full rationale
The paper's central derivation is a hypergeometric tail bound on surviving poisoned memories after random ablation followed by verdict-based majority vote. This is a first-principles probabilistic argument whose parameters (ablation rate, vote count, memory pool size) are chosen explicitly and whose validity rests on the stated modeling assumptions rather than on any fit to the 15 enterprise scenarios. No equations reduce a claimed prediction to a fitted input by construction, no self-citation chain supports the uniqueness or certificate claims, and the empirical success rates (8.0 % observed vs. certified worst-case) are reported as separate validation rather than used to tune the bound. The proof that no provenance-free filter certifies against adaptive injection is likewise an internal argument presented in the manuscript. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The random ablation process is independent of the adversary's choice of injected content and timing.
- domain assumption Verdict-based majority voting removes consistent minority answers that would win string-based voting.
Reference graph
Works this paper leans on
-
[1]
OW ASP top 10 for Large Language Model applications v2.0
OW ASP Foundation. OW ASP top 10 for Large Language Model applications v2.0. https://owasp.org/ www-project-top-10-for-large-language-model-applications/, 2025
2025
-
[2]
Governance and NIST AI agent standards: Agentic governance v1
Cloud Security Alliance. Governance and NIST AI agent standards: Agentic governance v1. Technical report, Cloud Security Alliance, 2026
2026
-
[3]
MINJA: Memory injection attacks on LLM agents via query-only interaction
Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang. MINJA: Memory injection attacks on LLM agents via query-only interaction. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. Michigan State / U. Georgia / Singapore Management Univ. arXiv:2503.03704
arXiv 2025
-
[4]
AgentPoison: Red-teaming LLM agents via poisoning memory or knowledge bases
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. AgentPoison: Red-teaming LLM agents via poisoning memory or knowledge bases. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2407.12784
arXiv 2024
-
[5]
Saksham Sahai Srivastava and Haoyu He. MemoryGraft: Persistent compromise of LLM agents via poisoned experience retrieval.arXiv preprint arXiv:2512.16962, 2025. University of Georgia
arXiv 2025
-
[6]
Certifiably robust RAG against retrieval corruption,
Chong Xiang, Tong Wu, Zexuan Zhong, David Wagner, Danqi Chen, and Prateek Mittal. Certifiably robust RAG against retrieval corruption,
-
[7]
ReliabilityRAG: Effective and provably robust defense for RAG-based web-search
Zeyu Shen, Basileal Imana, Tong Wu, Chong Xiang, Prateek Mittal, and Aleksandra Korolova. ReliabilityRAG: Effective and provably robust defense for RAG-based web-search. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. arXiv:2509.23519
arXiv 2025
-
[8]
Qianshan Wei, Tengchao Yang, Yaochen Wang, Xinfeng Li, Lijun Li, Zhenfei Yin, Yi Zhan, Thorsten Holz, Zhiqiang Lin, and XiaoFeng Wang. A-MemGuard: A proactive defense framework for LLM-based agent memory.arXiv preprint arXiv:2510.02373, 2025
arXiv 2025
-
[9]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self- consistency improves chain of thought reasoning in language models. InProceedings of the 11th International Conference on Learning Representations (ICLR), 2023. arXiv:2203.11171
Pith/arXiv arXiv 2023
-
[10]
LangGraph: Building stateful multi-actor applications with LLMs
LangChain Inc. LangGraph: Building stateful multi-actor applications with LLMs. https://langchain-ai.github.io/langgraph/, 2024
2024
-
[11]
Auto- Gen: Enabling next-gen LLM applications via multi-agent conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Auto- Gen: Enabling next-gen LLM applications via multi-agent conversation. arXiv preprint arXiv:2308.08155, 2023
Pith/arXiv arXiv 2023
-
[12]
Agent security bench (ASB): Formalizing and benchmarking attacks and defenses in LLM-based agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (ASB): Formalizing and benchmarking attacks and defenses in LLM-based agents. InProceedings of the International Conference on Learning Representations (ICLR), 2025. arXiv:2410.02644. PREPRINT 12
Pith/arXiv arXiv 2025
-
[13]
Balachandra Devarangadi Sunil, Isheeta Sinha, Piyush Maheshwari, Shantanu Todmal, Shreyan Mallik, and Shuchi Mishra. Memory poison- ing attack and defense on memory-based LLM-agents.arXiv preprint arXiv:2601.05504, 2026
arXiv 2026
-
[14]
Alexandra Boldyreva and Tianxin Tang. Privacy-preserving approxi- matek-nearest-neighbors search that hides access, query and volume patterns.Proceedings on Privacy Enhancing Technologies (PoPETS), 2021(4):549–574, 2021
2021
-
[15]
Andreea-Elena Bodea, Stephen Meisenbacher, Alexandra Klymenko, and Florian Matthes. SoK: Privacy risks and mitigations in retrieval- augmented generation systems.arXiv preprint arXiv:2601.03979, 2026. IEEE SaTML 2026
arXiv 2026
-
[16]
Cohen, Elan Rosenfeld, and J
Jeremy M. Cohen, Elan Rosenfeld, and J. Zico Kolter. Certified adversarial robustness via randomized smoothing. InProceedings of the 36th International Conference on Machine Learning (ICML), pages 1310–1320, 2019
2019
-
[17]
Robustness certificates for sparse adversarial attacks by randomized ablation
Alexander Levine and Soheil Feizi. Robustness certificates for sparse adversarial attacks by randomized ablation. InProceedings of the AAAI Conference on Artificial Intelligence, 2020. arXiv:1911.09272. Randomised L0-ablation certificate for image classifiers
arXiv 2020
-
[18]
Certified robustness to text adversarial attacks by randomized [MASK]
Jiehang Zeng, Jianhan Xu, Xiaoqing Zheng, and Xuanjing Huang. Certified robustness to text adversarial attacks by randomized [MASK]. Computational Linguistics, 49(2):395–427, 2023. Text adaptation of randomised ablation
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.