Decision-Aligned Evaluation of Uncertainty Quantification
Pith reviewed 2026-06-26 05:40 UTC · model grok-4.3
The pith
Many standard uncertainty metrics misalign with downstream decision utilities, while prior-weighted utility metrics align consistently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Decision-alignment is the criterion that reveals which uncertainty evaluation metrics meaningfully align with downstream utilities. Applying it shows that many widely used metrics are either misaligned with common decision problems or encode pathological prior beliefs about the downstream task. Prior-weighted utility metrics, defined as a special class of proper scoring rules, provide decision-aligned uncertainty evaluation. Across benchmark experiments and real-world case studies these metrics consistently align with realized decision utility while conventional metrics do not.
What carries the argument
The decision-alignment criterion, which tests whether a metric's performance on uncertainty estimates corresponds to the expected utility of decisions that use those estimates.
If this is right
- Uncertainty evaluation protocols should incorporate explicit utility functions that reflect the intended downstream decisions.
- Benchmarks that rely solely on calibration or likelihood metrics may systematically favor metrics that do not improve decisions.
- Proper scoring rules can be extended to decision relevance by weighting them according to priors over possible utility functions.
- Real-world deployment of uncertainty estimates should be validated against observed decision outcomes rather than generic scores alone.
Where Pith is reading between the lines
- The framework could be applied to other evaluation settings in machine learning where generic metrics are known to diverge from task-specific value.
- Teams adopting this approach would need to articulate their decision utilities explicitly before selecting an evaluation metric.
- The results suggest that metric choice itself encodes implicit assumptions about how uncertainty will be used, which can be made visible and adjustable.
Load-bearing premise
The downstream decision problems can be faithfully represented by the utility functions and priors used to define the proposed metrics and the decision-alignment criterion.
What would settle it
An experiment on a new decision task in which prior-weighted utility metrics exhibit lower correlation with realized decision utility than expected calibration error or negative log-likelihood.
Figures
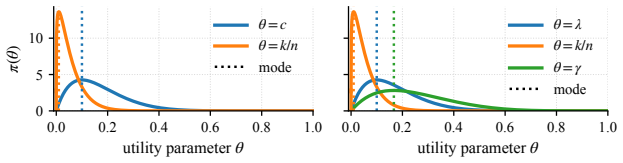
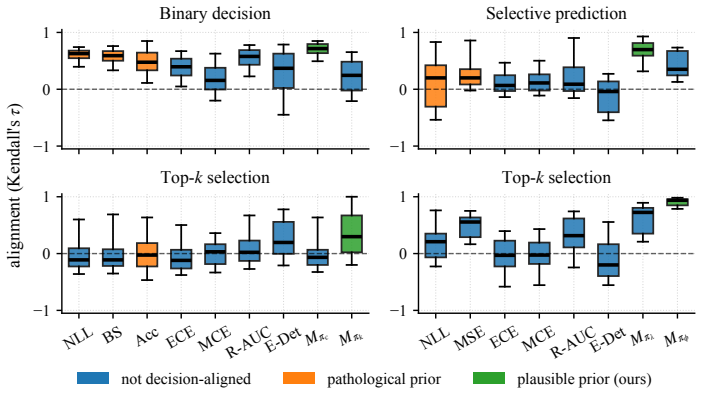
read the original abstract
Uncertainty estimates in machine learning are typically evaluated using generic metrics such as the negative log-likelihood and expected calibration error, yet good performance on such metrics does not necessarily imply high utility in downstream decisions. We introduce decision-alignment, a criterion that reveals which evaluation metrics meaningfully align with downstream utilities. Applying this framework, we show that many widely used uncertainty metrics are either misaligned with common decision problems or encode pathological prior beliefs about the downstream task. We then propose prior-weighted utility metrics, a special class of proper scoring rules that provides decision-aligned uncertainty evaluation. Across benchmark experiments and real-world case studies, our metrics consistently align with realized decision utility, while conventional metrics do not. Our results surface flaws in the current UQ evaluation protocol and offer a principled extension of existing metrics toward decision-relevant UQ evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a decision-alignment criterion for assessing uncertainty quantification metrics according to their alignment with downstream decision utilities. It argues that standard metrics such as negative log-likelihood and expected calibration error are frequently misaligned with common decision problems or encode pathological priors about the task. The authors propose prior-weighted utility metrics as a class of proper scoring rules that achieve decision alignment. They report that these metrics consistently match realized decision utility across benchmark experiments and real-world case studies, whereas conventional metrics do not, and conclude that current UQ evaluation protocols require principled extension toward decision-relevant evaluation.
Significance. If the chosen utilities and priors are representative of actual deployment problems and the empirical results are robust, the work would provide a concrete way to make UQ evaluation decision-relevant rather than generic, addressing a recognized disconnect between calibration metrics and practical utility. The framing via external decision-theoretic concepts and the identification of a special class of proper scoring rules constitute a clear conceptual contribution; reproducible code or machine-checked elements are not mentioned.
major comments (2)
- [Abstract] Abstract: the central empirical claim states that the proposed metrics 'consistently align with realized decision utility, while conventional metrics do not' across benchmarks and case studies, yet the abstract supplies no information on experimental design, data exclusion rules, error bars, statistical tests, or the elicitation procedure for the decision utilities and priors. Without these details the claim cannot be evaluated and may rest on post-hoc selection.
- [Framework definition and experimental setup] Framework definition and experimental setup: the decision-alignment criterion and prior-weighted utility metrics are defined relative to the authors' chosen utility functions and priors. The reported alignment therefore holds only inside those choices. No independent verification is described that the selected utilities match the true downstream problems encountered in deployment, nor are robustness results shown under plausible alternative utilities; this directly affects whether the generalization that 'many widely used uncertainty metrics are either misaligned ... or encode pathological prior beliefs' follows.
minor comments (1)
- [Abstract] The abstract refers to 'pathological prior beliefs' encoded by conventional metrics without giving concrete examples of those priors or the decision problems they distort; adding one or two explicit illustrations would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we address each major point directly, clarifying the intended scope of our claims while agreeing to revisions that improve transparency without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim states that the proposed metrics 'consistently align with realized decision utility, while conventional metrics do not' across benchmarks and case studies, yet the abstract supplies no information on experimental design, data exclusion rules, error bars, statistical tests, or the elicitation procedure for the decision utilities and priors. Without these details the claim cannot be evaluated and may rest on post-hoc selection.
Authors: The abstract is intentionally concise to highlight the conceptual contribution. Full experimental details—including benchmark designs, case-study protocols, utility elicitation from domain experts, and statistical reporting—are provided in Sections 4–5 of the manuscript. We agree the abstract could better signal this scope and will revise it to note the use of standard benchmarks, real-world case studies with elicited utilities, and that results include variability measures across runs. The utilities were selected a priori from common decision tasks in the literature rather than post-hoc; the manuscript does not claim universality but shows consistent patterns across the chosen settings. revision: partial
-
Referee: [Framework definition and experimental setup] Framework definition and experimental setup: the decision-alignment criterion and prior-weighted utility metrics are defined relative to the authors' chosen utility functions and priors. The reported alignment therefore holds only inside those choices. No independent verification is described that the selected utilities match the true downstream problems encountered in deployment, nor are robustness results shown under plausible alternative utilities; this directly affects whether the generalization that 'many widely used uncertainty metrics are either misaligned ... or encode pathological prior beliefs' follows.
Authors: Decision alignment is defined relative to a utility and prior by construction; this is the central methodological point, as generic metrics cannot be expected to align with every possible downstream task. The utilities used are drawn from standard decision problems in classification/regression and from practitioner-elicited preferences in the case studies. While the paper does not claim these exhaust all deployment scenarios, it demonstrates misalignment of conventional metrics for these representative choices. We agree that explicit robustness checks under alternative utilities would strengthen the generalization claim and will add sensitivity analyses in the revision. revision: yes
Circularity Check
No circularity: framework derived from external decision theory
full rationale
The paper introduces a decision-alignment criterion and prior-weighted utility metrics as a class of proper scoring rules grounded in decision-theoretic concepts. No equations or definitions in the abstract reduce the proposed metrics to fitted parameters or experimental outcomes by construction. The claim that the new metrics align with realized decision utility while conventional ones do not is presented as an empirical finding from benchmarks and case studies, not a definitional tautology. The derivation chain relies on external decision theory rather than self-referential fitting or self-citation chains, making the result self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Downstream tasks admit well-defined utility functions that can be used to evaluate decisions
- domain assumption Proper scoring rules can be adapted via prior weighting to produce decision-aligned evaluation
invented entities (2)
-
decision-alignment criterion
no independent evidence
-
prior-weighted utility metrics
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sculley, Sebastian Nowozin, Joshua V
Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, D. Sculley, Sebastian Nowozin, Joshua V . Dillon, Balaji Lakshminarayanan, and Jasper Snoek. Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift. InProceedings of the 33rd International Conference on Neural Information Processing Systems, volume 32. Curran Associa...
2019
-
[2]
URSABench: A system for comprehensive benchmarking of bayesian deep neural net- work models and inference methods
Meet P Vadera, Jinyang Li, Adam D Cobb, Brian Jalaian, Tarek Abdelzaher, and Benjamin M Marlin. URSABench: A system for comprehensive benchmarking of bayesian deep neural net- work models and inference methods. InProceedings of Machine Learning and Systems, volume 4, pages 217–237, 2022. URL https://proceedings.mlsys.org/paper_files/paper/2022/file/ 4a420...
2022
-
[3]
A benchmark on uncertainty quantifi- cation for deep learning prognostics.Reliability Engineering & System Safety, 253:110513, 2025
Luis Basora, Arthur Viens, Manuel Arias Chao, and Xavier Olive. A benchmark on uncertainty quantifi- cation for deep learning prognostics.Reliability Engineering & System Safety, 253:110513, 2025. URL https://linkinghub.elsevier.com/retrieve/pii/S0951832024005854
2025
-
[4]
Decision curve analysis: a novel method for evaluating prediction models
Andrew J. Vickers and Elena B. Elkin. Decision curve analysis: A novel method for evaluating prediction models.Medical Decision Making, 26(6):565–574, 2006. URL https://journals.sagepub.com/ doi/10.1177/0272989X06295361
-
[5]
Michael W. Dusenberry, Dustin Tran, Edward Choi, Jonas Kemp, Jeremy Nixon, Ghassen Jerfel, Katherine Heller, and Andrew M. Dai. Analyzing the role of model uncertainty for electronic health records. In Proceedings of the ACM Conference on Health, Inference, and Learning, pages 204–213. ACM, 2020. URLhttps://dl.acm.org/doi/10.1145/3368555.3384457
-
[6]
Evaluating posterior probabilities: Decision theory, proper scoring rules, and calibration.Transactions on Machine Learning Research, 2025
Luciana Ferrer and Daniel Ramos. Evaluating posterior probabilities: Decision theory, proper scoring rules, and calibration.Transactions on Machine Learning Research, 2025. URL https://openreview. net/forum?id=qbrE0LR7fF
2025
-
[7]
Patterns, predictions, and actions: A story about machine learning,
Moritz Hardt and Benjamin Recht. Patterns, predictions, and actions: A story about machine learning,
-
[8]
URLhttp://arxiv.org/abs/2102.05242
-
[9]
Zachary Nado, Neil Band, Mark Collier, Josip Djolonga, Michael W. Dusenberry, Sebastian Farquhar, Qixuan Feng, Angelos Filos, Marton Havasi, Rodolphe Jenatton, Ghassen Jerfel, Jeremiah Liu, Zelda Mariet, Jeremy Nixon, Shreyas Padhy, Jie Ren, Tim G. J. Rudner, Faris Sbahi, Yeming Wen, Florian Wenzel, Kevin Murphy, D. Sculley, Balaji Lakshminarayanan, Jaspe...
arXiv 2022
-
[10]
URLhttps://doi.org/10.1198/016214506000001437
Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation.Journal of the American Statistical Association, 102(477):359–378, 2007. URL http://www.tandfonline. com/doi/abs/10.1198/016214506000001437
-
[11]
Measuring, refining and calibrating speaker and language in- formation extracted from speech, 2010
Niko Brümmer. Measuring, refining and calibrating speaker and language in- formation extracted from speech, 2010. URL https://scispace.com/pdf/ measuring-refining-and-calibrating-speaker-and-language-53glvzuiuj.pdf . PhD Thesis
2010
-
[12]
Romain Pic, Clément Dombry, Philippe Naveau, and Maxime Taillardat. Proper scoring rules for multi- variate probabilistic forecasts based on aggregation and transformation.Advances in Statistical Clima- tology, Meteorology and Oceanography, 11(1):23–58, 2025. URL https://ascmo.copernicus.org/ articles/11/23/2025/
2025
-
[13]
The neu- ral testbed: Evaluating joint predictions
Ian Osband, Zheng Wen, Seyed Mohammad Asghari, Brendan O’Donoghue, Botao Hao, Dieterich Lawson, Morteza Ibrahimi, Xiuyuan Lu, Vikranth Dwaracherla, and Benjamin Van Roy. The neu- ral testbed: Evaluating joint predictions. InProceedings of the 36th International Conference on Neural Information Processing Systems, volume 35 ofNIPS ’22, pages 12554–12565. C...
2022
-
[14]
Theory and applications of proper scoring rules.METRON, 72(2):169–183, 2014
Alexander Philip Dawid and Monica Musio. Theory and applications of proper scoring rules.METRON, 72(2):169–183, 2014. URLhttp://link.springer.com/10.1007/s40300-014-0039-y
-
[15]
Leonard J. Savage. Elicitation of personal probabilities and expectations.Journal of the American Statistical Association, 66(336):783–801, 1971. ISSN 0162-1459, 1537-274X. doi: 10.1080/01621459.1971. 10482346. URLhttp://www.tandfonline.com/doi/abs/10.1080/01621459.1971.10482346
- [16]
-
[17]
Loss functions for binary class probability estimation and classification: Structure and applications, 2005
Andreas Buja, Werner Stuetzle, and Yi Shen. Loss functions for binary class probability estimation and classification: Structure and applications, 2005. URL http://stat.wharton.upenn.edu/~buja/ PAPERS/paper-proper-scoring.pdf
2005
-
[18]
Reid and Robert C
Mark D. Reid and Robert C. Williamson. Information, divergence and risk for binary experiments.Journal of Machine Learning Research, 12:731–817, 2011. URL https://jmlr.csail.mit.edu/papers/ v12/reid11a.html
2011
-
[19]
Werner Ehm, Tilmann Gneiting, Alexander Jordan, and Fabian Krüger. Of quantiles and expectiles: Consistent scoring functions, choquet representations and forecast rankings.Journal of the Royal Statistical Society Series B: Statistical Methodology, 78(3):505–562, 2016. URL https://academic.oup.com/ jrsssb/article/78/3/505/7040984
2016
-
[20]
Well-calibrated regression uncertainty in medical imaging with deep learning
Max-Heinrich Laves, Sontje Ihler, Jacob F Fast, Luder A Kahrs, and Tobias Ortmaier. Well-calibrated regression uncertainty in medical imaging with deep learning. InProceedings of the Third Conference on Medical Imaging with Deep Learning, volume 121, pages 393–412. PMLR, 2020. URL https: //proceedings.mlr.press/v121/laves20a.html
2020
-
[21]
Ruotao Zhang, Constantine Gatsonis, and Jon Arni Steingrimsson. Role of calibration in uncertainty- based referral for deep learning.Statistical Methods in Medical Research, 32(5):927–943, 2023. URL https://journals.sagepub.com/doi/10.1177/09622802231158811
-
[22]
Sebastian G. Gruber and Florian Buettner. Better uncertainty calibration via proper scores for classification and beyond. In36th Conference on Neural Information Processing Systems, 2022. URL http://arxiv. org/abs/2203.07835
arXiv 2022
-
[23]
U-calibration: Forecasting for an unknown agent
Robert Kleinberg, Renato Paes Leme, Jon Schneider, and Yifeng Teng. U-calibration: Forecasting for an unknown agent. InProceedings of Machine Learning Research, volume 195, pages 1–3, 2023. URL https://proceedings.mlr.press/v195/kleinberg23a/kleinberg23a.pdf
2023
-
[24]
Calibration error for decision making, 2024
Lunjia Hu and Yifan Wu. Calibration error for decision making, 2024. URL http://arxiv.org/abs/ 2404.13503
arXiv 2024
-
[25]
Truthfulness of decision-theoretic calibration measures, 2025
Mingda Qiao and Eric Zhao. Truthfulness of decision-theoretic calibration measures, 2025. URL http://arxiv.org/abs/2503.02384
arXiv 2025
-
[26]
Cost-aware calibration of classifiers.INFORMS Journal on Data Science, 4 (2):101–113, 2025
Mochen Yang and Xuan Bi. Cost-aware calibration of classifiers.INFORMS Journal on Data Science, 4 (2):101–113, 2025. URLhttps://pubsonline.informs.org/doi/10.1287/ijds.2024.0038
-
[27]
Jordan, and Aymeric Dieuleveut
Mahmoud Hegazy, Michael I. Jordan, and Aymeric Dieuleveut. Scalable utility-aware multiclass calibration,
-
[28]
URLhttp://arxiv.org/abs/2510.25458
-
[29]
Rank-based decomposable losses in machine learning: A survey
Shu Hu, Xin Wang, and Siwei Lyu. Rank-based decomposable losses in machine learning: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–20, 2023. URL https: //ieeexplore.ieee.org/document/10184478/
arXiv 2023
-
[30]
The foundations of cost-sensitive learning
Charles Elkan. The foundations of cost-sensitive learning. InProceedings of the 17th International Joint Conference on Artificial Intelligence, volume 2 ofIJCAI’01, pages 973–978. Morgan Kaufmann Publishers Inc., 2001. URLhttps://dl.acm.org/doi/abs/10.5555/1642194.1642224
-
[31]
Yan-Martin Tamm, Rinchin Damdinov, and Alexey Vasilev. Quality metrics in recommender systems: Do we calculate metrics consistently? InFifteenth ACM Conference on Recommender Systems, pages 708–713, 2021. URLhttp://arxiv.org/abs/2206.12858
arXiv 2021
-
[32]
A no-regret generalization of hierarchical softmax to extreme multi-label classification
Marek Wydmuch, Kalina Jasinska, Mikhail Kuznetsov, Róbert Busa-Fekete, and Krzysztof Dembczy´nski. A no-regret generalization of hierarchical softmax to extreme multi-label classification. In32nd Conference on Neural Information Processing Systems, 2018. URLhttp://arxiv.org/abs/1810.11671. 11
Pith/arXiv arXiv 2018
-
[33]
Model cards for model reporting
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. InProceedings of the Conference on Fairness, Accountability, and Transparency, FAT* ’19, page 220–229, New York, NY , USA,
-
[34]
Association for Computing Machinery. URLhttps://doi.org/10.1145/3287560.3287596
-
[35]
Day-ahead bidding strategies for wind farm operators under a one-price balancing scheme
Max Bruninx, Timothy Verstraeten, Jalal Kazempour, and Jan Helsen. Day-ahead bidding strategies for wind farm operators under a one-price balancing scheme. InProceedings of the 16th ACM International Conference on Future and Sustainable Energy Systems, pages 719–726. ACM, 2025. URL https: //dl.acm.org/doi/10.1145/3679240.3734639
-
[36]
Pitfalls of epistemic uncertainty quantifica- tion through loss minimisation
Viktor Bengs, Eyke Hüllermeier, and Willem Waegeman. Pitfalls of epistemic uncertainty quantifica- tion through loss minimisation. InAdvances in Neural Information Processing Systems, volume 35, pages 29205–29216. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_ files/paper/2022/file/bc1d640f841f752c689aae20b31198c1-Paper-Conference.pdf
2022
-
[37]
On second-order scoring rules for epistemic uncertainty quantification
Viktor Bengs, Eyke Hüllermeier, and Willem Waegeman. On second-order scoring rules for epistemic uncertainty quantification. InProceedings of the 40th International Conference on Machine Learning, volume 202, pages 2078–2091. PMLR, 23–29 Jul 2023. URL https://proceedings.mlr.press/ v202/bengs23a.html
2078
-
[38]
Random-set neural networks
Shireen Kudukkil Manchingal, Muhammad Mubashar, Kaizheng Wang, Keivan K1 Shariatmadar, and Fabio Cuzzolin. Random-set neural networks. InInternational Conference on Learning Representations,
-
[39]
URLhttps://openreview.net/forum?id=pdjkikvCch
-
[40]
Shireen Kudukkil Manchingal, Andrew Bradley, Julian F. P. Kooij, Keivan K1 Shariatmadar, Neil Yorke- Smith, and Fabio Cuzzolin. Epistemic artificial intelligence is essential for machine learning models to truly’know when they do not know’, 2025. URLhttps://arxiv.org/abs/2505.04950
arXiv 2025
-
[41]
A. Allen Bradley and Stuart S. Schwartz. Summary verification measures and their interpretation for ensemble forecasts.Monthly Weather Review, 139(9):3075–3089, 2011. URL https://journals. ametsoc.org/doi/10.1175/2010MWR3305.1
-
[42]
Aligning the evaluation of probabilistic predictions with downstream value, 2025
Novin Shahroudi, Viacheslav Komisarenko, and Meelis Kull. Aligning the evaluation of probabilistic predictions with downstream value, 2025. URLhttp://arxiv.org/abs/2508.18251
arXiv 2025
-
[43]
Williamson
Rabanus Derr and Robert C. Williamson. Forecast evaluation and the relationship of regret and calibration,
-
[44]
URLhttp://arxiv.org/abs/2401.14483
-
[45]
Aligning evaluation with clinical priorities: Calibration, label shift, and error costs
Gerardo A Flores, Alyssa H Smith, Julia A Fukuyama, and Ashia C Wilson. Aligning evaluation with clinical priorities: Calibration, label shift, and error costs. InThe 39th Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=b7Ka31HvXU
2025
-
[46]
Gerardo Flores, Abigail Schiff, Alyssa H. Smith, Julia A. Fukuyama, and Ashia C. Wilson. A con- sequentialist critique of binary classification evaluation: Theory, practice, and tools, 2026. URL http://arxiv.org/abs/2504.04528
arXiv 2026
-
[47]
Calibrated reliable regression using maximum mean discrepancy
Peng Cui, Wenbo Hu, and Jun Zhu. Calibrated reliable regression using maximum mean discrepancy. In Proceedings of the 34th International Conference on Neural Information Processing Systems, volume 33 of NIPS ’20, pages 17164–17175. Curran Associates, Inc., 2020. URL https://proceedings.neurips. cc/paper_files/paper/2020/file/c74c4bf0dad9cbae3d80faa054b7d8...
2020
-
[48]
Andrey Malinin, Neil Band, Ganshin, Alexander, German Chesnokov, Yarin Gal, Mark J. F. Gales, Alexey Noskov, Andrey Ploskonosov, Liudmila Prokhorenkova, Ivan Provilkov, Vatsal Raina, Vyas Raina, Roginskiy, Denis, Mariya Shmatova, Panos Tigas, and Boris Yangel. Shifts: A dataset of real distributional shift across multiple large-scale tasks. In35th Confere...
2021
-
[49]
Towards clear expecta- tions for uncertainty estimation, 2022
Victor Bouvier, Simona Maggio, Alexandre Abraham, and Léo Dreyfus-Schmidt. Towards clear expecta- tions for uncertainty estimation, 2022. URLhttp://arxiv.org/abs/2207.13341
arXiv 2022
-
[50]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. In Proceedings of the 34th International Conference on Machine Learning, volume 70, pages 1321–1330. PMLR, 2017. URLhttps://proceedings.mlr.press/v70/guo17a.html
2017
-
[51]
Martin, Suyog Chandramouli, Marcelo Hartmann, Oriol Abril Pla, Owen Thomas, Henri Pesonen, Jukka Corander, Aki Vehtari, Samuel Kaski, Paul-Christian Bürkner, and Arto Klami
Petrus Mikkola, Osvaldo A. Martin, Suyog Chandramouli, Marcelo Hartmann, Oriol Abril Pla, Owen Thomas, Henri Pesonen, Jukka Corander, Aki Vehtari, Samuel Kaski, Paul-Christian Bürkner, and Arto Klami. Prior knowledge elicitation: The past, present, and future.Bayesian Analysis, 19(4):1129–1161,
-
[52]
URLhttps://doi.org/10.1214/23-BA1381. 12
-
[53]
Scalable variational gaussian process classification
James Hensman, Alexander Matthews, and Zoubin Ghahramani. Scalable variational gaussian process classification. InProceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, volume 38, pages 351–360. PMLR, 2015. URL https://proceedings.mlr.press/v38/ hensman15.html
2015
-
[54]
TabPFN: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A transformer that solves small tabular classification problems in a second. InThe 11th International Conference on Learning Representations, 2023. URLhttps://openreview.net/pdf?id=cp5PvcI6w8_
2023
-
[55]
Revisiting deep learning models for tabular data
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data. InAdvances in Neural Information Processing Systems, volume 34, pages 18932– 18943. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/ paper/2021/file/9d86d83f925f2149e9edb0ac3b49229c-Paper.pdf
2021
-
[56]
Bayan Bruss, and Tom Goldstein
Gowthami Somepalli, Avi Schwarzschild, Micah Goldblum, C. Bayan Bruss, and Tom Goldstein. SAINT: Improved neural networks for tabular data via row attention and contrastive pre-training. In NeurIPS 2022 First Table Representation Workshop, 2022. URL https://openreview.net/forum? id=FiyUTAy4sB8
2022
-
[57]
Simple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/ paper/2017/file/9ef2ed4b7fd2c810847ffa5fa85bce38-Paper.pdf
2017
-
[58]
NGBoost: Natural gradient boosting for probabilistic prediction
Tony Duan, Anand Avati, Daisy Yi Ding, Khanh K Thai, Sanjay Basu, Andrew Ng, and Alejandro Schuler. NGBoost: Natural gradient boosting for probabilistic prediction. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research. PMLR,
-
[59]
URLhttps://proceedings.mlr.press/v119/duan20a.html
-
[60]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011. URLhttps://jmlr.org/papers/v12/pedregosa11a.html
2011
-
[61]
Gpytorch: Blackbox matrix-matrix gaussian process inference with gpu acceleration
Jacob R Gardner, Geoff Pleiss, David Bindel, Kilian Q Weinberger, and Andrew Gordon Wilson. Gpytorch: Blackbox matrix-matrix gaussian process inference with gpu acceleration. InAdvances in Neural In- formation Processing Systems, 2018. URL https://proceedings.neurips.cc/paper/2018/hash/ 27e8e17134dd7083b050476733207ea1-Abstract.html
2018
-
[62]
The UCI machine learning repository, 2025
Markelle Kelly, Rachel Longjohn, and Kolby Nottingham. The UCI machine learning repository, 2025. URLhttps://archive.ics.uci.edu
2025
-
[63]
S Moro, P Rita, and P Cortez. Bank marketing, 2014. URLhttps://doi.org/10.24432/C5K306
-
[64]
Andras Janosi, William Steinbrunn, Matthias Pfisterer, and Robert Detrano. Heart disease, 1989. URL https://doi.org/10.24432/C52P4X
-
[65]
Ionosphere, 1989
V Sigillito, S Wing, L Hutton, and K Baker. Ionosphere, 1989. URL https://doi.org/10.24432/ C5W01B
1989
-
[66]
Jeff Schlimmer. Mushroom, 1981. URLhttps://doi.org/10.24432/C5959T
-
[67]
Connectionist bench (sonar, mines vs
T Sejnowski and R Gorman. Connectionist bench (sonar, mines vs. rocks), 1988. URL https://doi. org/10.24432/C5T01Q
-
[68]
S Vito. Air quality, 2008. URLhttps://doi.org/10.24432/C59K5F
-
[69]
R Quinlan. Auto MPG, 1993. URLhttps://doi.org/10.24432/C5859H
-
[70]
Energy efficiency, 2012
Athanasios Tsanas and Angeliki Xifara. Energy efficiency, 2012. URL https://doi.org/10.24432/ C51307
2012
-
[71]
Combined cycle power plant, 2014
P Tfekci and H Kaya. Combined cycle power plant, 2014. URL https://doi.org/10.24432/C5002N
-
[72]
Wine quality, 2009
P Cortez, A Cerdeira, F Almeida, T Matos, and J Reis. Wine quality, 2009. URL https://doi.org/10. 24432/C56S3T
2009
-
[73]
Elia open data platform, 2025
Elia. Elia open data platform, 2025. URLhttps://opendata.elia.be. 13
2025
-
[74]
ENTSO-e transparency platform,
European Network of Transmission System Operators for Electricity. ENTSO-e transparency platform,
-
[75]
URLhttps://transparency.entsoe.eu
-
[76]
Example-dependent cost-sensitive logistic regression for credit scoring
Alejandro Correa Bahnsen, Djamia Aouada, and Bjorn Ottersten. Example-dependent cost-sensitive logistic regression for credit scoring. In13th International Conference on Machine Learning and Applications, pages 263–269. IEEE, 2014. URLhttp://ieeexplore.ieee.org/document/7033125/
arXiv 2014
-
[77]
Credit risk assessment on a private label credit card application, 2009
PAKDD. Credit risk assessment on a private label credit card application, 2009. URL https://pakdd. org/archive/pakdd2009/front/show/competition.html. Data Mining Competition
2009
-
[78]
GiveMeSomeCredit, 2011
Will Cukierski. GiveMeSomeCredit, 2011. URL https://kaggle.com/competitions/ GiveMeSomeCredit. Credit Fusion
2011
-
[79]
costcla, 2016
Alejandro Correa Bahnsen. costcla, 2016. URL https://github.com/albahnsen/ CostSensitiveClassification
2016
-
[80]
Ajay Byanjankar, József Mezei, and Markku Heikkilä. Data-driven optimization of peer-to-peer lending portfolios based on the expected value framework.Intelligent Systems in Accounting, Finance and Management, 28(2):119–129, 2021. URL https://onlinelibrary.wiley.com/doi/10.1002/isaf. 1490
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.