REVIEW 2 major objections 2 minor 3 cited by
Online Monte Carlo estimation of an energy term allows sampling from optimal RL policies at test time without training.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-21 14:00 UTC pith:OQOO75CB
load-bearing objection ETS gives a test-time sampling method for RL-aligned LMs by estimating an energy term online with Monte Carlo, but the sequential dependence risks bias that the convergence claims may not fully resolve. the 2 major comments →
ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Energy-Guided Test-Time Scaling estimates the energy term via online Monte Carlo with a provable convergence rate and applies modern acceleration frameworks plus tailored importance sampling estimators to cut inference latency while provably preserving sampling quality, producing consistent gains on reasoning, coding, and science benchmarks for both autoregressive and diffusion language models.
What carries the argument
Energy-Guided Test-Time Scaling, which guides each sampling step by adding an estimated energy term to a reference policy inside the masked language modeling transition probability.
Load-bearing premise
The transition probability decomposes into a reference policy and an energy term that can be estimated online without bias that would invalidate the optimality guarantee.
What would settle it
Generate outputs from both a fully trained RL policy and from ETS on the same prompts, then measure whether their quality distributions or benchmark scores diverge significantly.
If this is right
- Generation quality improves on reasoning, coding, and science tasks without any RL training.
- The same procedure works for both autoregressive and diffusion language models.
- Inference latency drops through acceleration and importance sampling while sampling quality remains provably intact.
- Convergence of the online energy estimate is guaranteed at a known rate.
Where Pith is reading between the lines
- The same energy-estimation trick could be tried in non-language sequential tasks where an optimal policy is hard to train directly.
- Teams with limited compute might use ETS to prototype alignment behaviors before committing to full training.
- Combining ETS with lightweight fine-tuning could produce hybrid systems that start from a base model and refine further at test time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Energy-Guided Test-Time Scaling (ETS), a training-free inference-time method to sample directly from the optimal RL-aligned policy for language models. For Masked Language Modeling, the transition probability is expressed as the product of a reference policy and an energy term; ETS estimates the energy term via online Monte Carlo sampling and claims a provable convergence rate. Practical efficiency is achieved through modern acceleration frameworks and tailored importance sampling estimators that are asserted to reduce latency while preserving sampling quality. Experiments across reasoning, coding, and science benchmarks on both autoregressive and diffusion language models report consistent quality improvements.
Significance. If the claimed convergence rate and unbiased quality preservation hold under sequential sampling, ETS would constitute a practical, low-cost alternative to RL post-training for alignment. The open-sourced code supports reproducibility and allows direct verification of the Monte Carlo and importance-sampling implementations.
major comments (2)
- [Theoretical Analysis / Convergence Proof] The convergence-rate claim for the online Monte Carlo estimator of the energy term (stated in the abstract and presumably detailed in the theoretical section) does not address the dependence between the estimator and the partially generated sequence under the current approximate policy. In sequential or masked decoding, Monte Carlo samples drawn from the trajectory itself can introduce bias that is not automatically canceled by the stated rate, undermining the exact optimality guarantee.
- [Method / Transition Probability Formulation] The transition probability definition p(y|x) = reference_policy(y|x) * energy_term(y|x) is central to the optimality claim, yet the manuscript provides no explicit derivation or error analysis showing that replacing the energy term by its online estimate preserves the exact target distribution when the estimator is embedded inside the autoregressive loop.
minor comments (2)
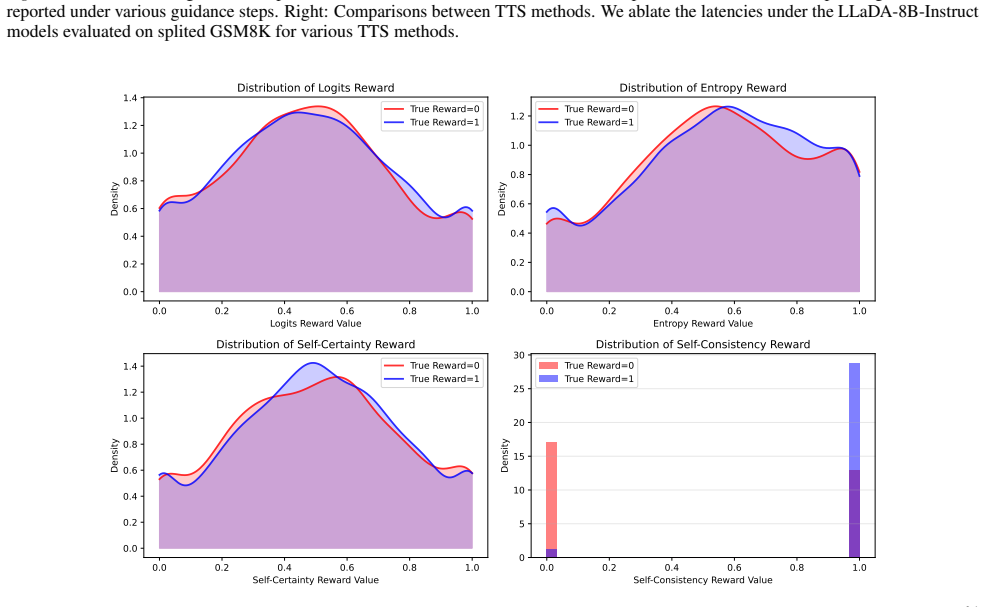
- [Experiments] Figure captions and experimental tables would benefit from explicit reporting of the number of Monte Carlo samples used per token and the resulting wall-clock overhead relative to the baseline reference policy.
- [Method] Notation for the importance-sampling estimator should be introduced with a clear distinction between the proposal distribution and the target energy term to avoid ambiguity in the latency-reduction claims.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify areas where our theoretical claims require additional rigor to fully address sequential sampling effects, and we will incorporate clarifications and new analysis in the revised manuscript.
read point-by-point responses
-
Referee: [Theoretical Analysis / Convergence Proof] The convergence-rate claim for the online Monte Carlo estimator of the energy term (stated in the abstract and presumably detailed in the theoretical section) does not address the dependence between the estimator and the partially generated sequence under the current approximate policy. In sequential or masked decoding, Monte Carlo samples drawn from the trajectory itself can introduce bias that is not automatically canceled by the stated rate, undermining the exact optimality guarantee.
Authors: We agree that dependence between the online Monte Carlo estimator and the partially generated sequence is a subtle but important issue in sequential decoding that our current analysis does not explicitly bound. The stated convergence rate in Section 3 assumes independent samples conditional on the current policy; we will add a new proposition in the revised theoretical section that treats the process as a martingale difference sequence and derives an explicit bound on the accumulated bias in total variation distance. This will show that the bias remains controlled and vanishes as the per-step sample count increases, thereby restoring the asymptotic optimality guarantee under the autoregressive loop. revision: partial
-
Referee: [Method / Transition Probability Formulation] The transition probability definition p(y|x) = reference_policy(y|x) * energy_term(y|x) is central to the optimality claim, yet the manuscript provides no explicit derivation or error analysis showing that replacing the energy term by its online estimate preserves the exact target distribution when the estimator is embedded inside the autoregressive loop.
Authors: The transition probability is obtained by rewriting the optimal RL policy as the reference policy multiplied by an energy term derived from the reward. We will insert a dedicated derivation subsection (with full steps from the RL objective) and a supporting theorem that quantifies the distributional error when the energy term is replaced by its online Monte Carlo estimate. The proof will leverage the unbiasedness of the importance-sampling estimator conditional on the current prefix and show that the overall sampling distribution converges in KL divergence to the target at the same rate as the per-step estimation error. revision: partial
Circularity Check
No significant circularity detected; derivation introduces independent estimators
full rationale
The paper's central derivation defines the transition probability for MLM as reference_policy times an energy term, then introduces a new online Monte Carlo estimator for that term along with importance sampling accelerations and a claimed convergence rate. This construction does not reduce any prediction to a fitted input by definition, nor does it rely on self-citation chains or imported uniqueness theorems to force the result. The optimality claim and sampling-quality preservation are presented as following from the new estimators rather than tautologically from prior fits or renamings. The method is therefore self-contained against external benchmarks with independent technical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transition probability in MLM is reference policy plus energy term
read the original abstract
Reinforcement Learning (RL) post-training alignment for language models is effective, but also costly and unstable in practice, owing to its complicated training process. To address this, we propose a training-free inference method to sample directly from the optimal RL policy. The transition probability applied to Masked Language Modeling (MLM) consists of a reference policy model and an energy term. Based on this, our algorithm, Energy-Guided Test-Time Scaling (ETS), estimates the key energy term via online Monte Carlo, with a provable convergence rate. Moreover, to ensure practical efficiency, ETS leverages modern acceleration frameworks alongside tailored importance sampling estimators, substantially reducing inference latency while provably preserving sampling quality. Experiments on MLM (including autoregressive models and diffusion language models) across reasoning, coding, and science benchmarks show that our ETS consistently improves generation quality, validating its effectiveness and design. The code is available at https://github.com/sheriyuo/ETS.
Figures









Forward citations
Cited by 3 Pith papers
-
Detecting and Mitigating the Correct-Answer Extinction Window in Test-Time Reinforcement Learning with Majority Voting
TTRL gains are reinterpreted as mostly sharpening rather than learning, with an identified extinction window causing net corruption; TTRL-Guard mitigates via FRS, MPS, and RCSU for improved pass@1.
-
Detecting and Mitigating the Correct-Answer Extinction Window in Test-Time Reinforcement Learning with Majority Voting
TTRL-Guard mitigates the Correct-Answer Extinction Window in test-time RL via flip-rate-aware reward scaling, minority-preserving sampling, and risk-conditioned sparse updates, yielding best average pass@1 on Qwen mod...
-
HTAM: Hierarchical Transition-Attended Memory for Operator Optimization
HTAM builds a Hierarchical Transition Graph to organize coarse global directions and detailed local strategies for guiding LLM-based CUDA kernel optimization, improving results on KernelBench.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. Preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y ., Kadavath, S., Kundu, S., et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. Preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Casper, S., Davies, X., Shi, C., Gilbert, T. K., Scheurer, J., Rando, J., Freedman, R., Korbak, T., Lindner, D., Freire, P., et al. Open problems and fundamental limitations of reinforcement learning from human feedback. Preprint arXiv:2307.15217,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Step-level verifier- guided hybrid test-time scaling for large language models
Chang, K., Shi, Y ., Wang, C., Zhou, H., Hu, C., Liu, X., Luo, Y ., Ge, Y ., Xiao, T., and Zhu, J. Step-level verifier- guided hybrid test-time scaling for large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,
work page 2025
-
[5]
Evaluating Large Language Models Trained on Code
Chen, M. Evaluating large language models trained on code. Preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Inference-aware fine-tuning for best-of-N sampling in large language models, 2024
Chow, Y ., Tennenholtz, G., Gur, I., Zhuang, V ., Dai, B., Thiagarajan, S., Boutilier, C., Agarwal, R., Ku- mar, A., and Faust, A. Inference-aware fine-tuning for best-of-n sampling in large language models. Preprint arXiv:2412.15287,
-
[7]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. Preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Inference-Time Scaling of Diffusion Language Models via Trajectory Refinement
Dang, M., Han, J., Xu, M., Xu, K., Srivastava, A., and Ermon, S. Inference-time scaling of diffusion lan- guage models with particle gibbs sampling. Preprint arXiv:2507.08390,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Analyzes collapse in Search-R1-style tool-integrated GRPO via Lazy Likelihood Displacement
Deng, W., Li, Y ., Gong, B., Ren, Y ., Thrampoulidis, C., and Li, X. On grpo collapse in search-r1: The lazy likelihood- displacement death spiral. Preprint arXiv:2512.04220,
-
[10]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
Fu, W., Gao, J., Shen, X., Zhu, C., Mei, Z., He, C., Xu, S., Wei, G., Mei, J., Wang, J., et al. Areal: A large-scale asynchronous reinforcement learning system for language reasoning. Preprint arXiv:2505.24298,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
URL https://zenodo.org/records/12608602. 9 ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning. Preprint arXiv:2501.12948,
-
[12]
Chatglm- rlhf: Practices of aligning large language models with human feedback
Hou, Z., Niu, Y ., Du, Z., Zhang, X., Liu, X., et al. Chatglm- rlhf: Practices of aligning large language models with human feedback. Preprint arXiv:2404.00934,
-
[13]
Hu, Z., Meng, J., Akhauri, Y ., Abdelfattah, M. S., Seo, J.-s., Zhang, Z., and Gupta, U. Flashdlm: Accelerating diffu- sion language model inference via efficient kv caching and guided diffusion. Preprint arXiv:2505.21467,
-
[14]
Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning
Huan, M., Li, Y ., Zheng, T., Xu, X., Kim, S., Du, M., Poovendran, R., Neubig, G., and Yue, X. Does math reasoning improve general llm capabilities? un- derstanding transferability of llm reasoning. Preprint arXiv:2507.00432,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Language Models (Mostly) Know What They Know
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield-Dodds, Z., DasSarma, N., Tran-Johnson, E., et al. Language models (mostly) know what they know. Preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Scalable Best-of-N Selection for Large Language Models via Self-Certainty
Kang, Z., Zhao, X., and Song, D. Scalable best-of-n selec- tion for large language models via self-certainty. Preprint arXiv:2502.18581,
-
[17]
Reasoning with Sampling: Your Base Model is Smarter Than You Think
Karan, A. and Du, Y . Reasoning with sampling: Your base model is smarter than you think. Preprint arXiv:2510.14901,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Kuhn, L., Gal, Y ., and Farquhar, S. Semantic uncertainty: Linguistic invariances for uncertainty estimation in nat- ural language generation. Preprint arXiv:2302.09664,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
arXiv preprint arXiv:2502.21321 , year=
Kumar, K., Ashraf, T., Thawakar, O., Anwer, R. M., Cholakkal, H., Shah, M., Yang, M.-H., Torr, P. H., Khan, F. S., and Khan, S. Llm post-training: A deep dive into reasoning large language models. Preprint arXiv:2502.21321,
-
[20]
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Li, Y ., Wei, F., Zhang, C., and Zhang, H. Eagle-3: Scaling up inference acceleration of large language models via training-time test. Preprint arXiv:2503.01840,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Towards a theoretical understanding to the generalization of rlhf
Li, Z., Yi, M., Wang, Y ., Cui, S., and Liu, Y . Towards a theoretical understanding to the generalization of rlhf. Preprint arXiv:2601.16403,
-
[22]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al. Deepseek-v3. 2: Pushing the frontier of open large language models. Preprint arXiv:2512.02556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
WebGPT: Browser-assisted question-answering with human feedback
Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V ., Saunders, W., et al. Webgpt: Browser-assisted question-answering with hu- man feedback. Preprint arXiv:2112.09332,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Large Language Diffusion Models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y ., Wen, J.-R., and Li, C. Large language diffusion models. Preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
10 ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., and Ermon, S. Direct preference optimization: Your language model is secretly a reward model. Preprint arXiv:2305.18290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. Preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Parshin Shojaee, Aneesh Jain, Sindhu Tipirneni, and Chandan K
Shafayat, S., Tajwar, F., Salakhutdinov, R., Schneider, J., and Zanette, A. Can large reasoning models self-train? (arXiv:2505.21444),
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. (arXiv:2402.03300),
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. Hybridflow: A flexible and efficient rlhf framework. Preprint arXiv:2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Singhal, R., Horvitz, Z., Teehan, R., Ren, M., Yu, Z., McK- eown, K., and Ranganath, R. A general framework for inference-time scaling and steering of diffusion models. Preprint arXiv:2501.06848,
-
[31]
Reveal the mystery of dpo: The connection between dpo and rl algorithms
Su, X., Wang, Y ., Zhu, J., Yi, M., Xu, F., Ma, Z., and Liu, Y . Reveal the mystery of dpo: The connection between dpo and rl algorithms. Preprint arXiv:2502.03095,
-
[32]
LongCat-Image Technical Report
Team, M. L., Ma, H., Tan, H., Huang, J., Wu, J., He, J.-Y ., Gao, L., Xiao, S., Wei, X., Ma, X., et al. Longcat-image technical report. Preprint arXiv:2512.07584,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Fine-Tuning of Continuous-Time Diffusion Models as Entropy-Regularized Control
Uehara, M., Zhao, Y ., Black, K., Hajiramezanali, E., Scalia, G., Diamant, N. L., Tseng, A. M., Biancalani, T., and Levine, S. Fine-tuning of continuous-time dif- fusion models as entropy-regularized control. Preprint arXiv:2402.15194,
-
[34]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency im- proves chain of thought reasoning in language models. Preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Transformers: State-of-the-art natural language processing
Wolf, T., Debut, L., Sanh, V ., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., et al. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 conference on em- pirical methods in natural language processing: system demonstrations,
work page 2020
-
[36]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Wu, C., Zhang, H., Xue, S., Liu, Z., Diao, S., Zhu, L., Luo, P., Han, S., and Xie, E. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding. Preprint arXiv:2505.22618,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. Preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Zhang, Q., Lyu, F., Sun, Z., Wang, L., Zhang, W., Hua, W., Wu, H., Guo, Z., Wang, Y ., Muennighoff, N., et al. A sur- vey on test-time scaling in large language models: What, how, where, and how well? Preprint arXiv:2503.24235, 2025a. 11 ETS: Energy-Guided Test-Time Scaling for Training-Free RL Alignment Zhang, Y ., Fan, M., Fan, J., Yi, M., Luo, Y ., Tan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Zhu, F., Wang, R., Nie, S., Zhang, X., Wu, C., Hu, J., Zhou, J., Chen, J., Lin, Y ., Wen, J.-R., et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models. Preprint arXiv:2505.19223,
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Therefore, we get TV(q(x0 |y)∥p(x 0 |y))≤I 2ϵ+h(ϵ, M, λ, D) C−ϵ−h(ϵ, M, λ, D) +Iϵ(34) Finally, note thath(ϵ, M, λ, D) = ˜O(1/ √ M), so the overall bound is ˜O I/ √ M+Iϵ . Lemma 1.For any given queryyand responsex ti, if |E(y,x ti )− bE(y,x ti )| ≤δ(35) forδ=ϵ, then Ep(xti−1 |y,xti )[f(x ti−1 )]−E q(xti−1 |y,xti )[f(x ti−1 )] ≤ 2ϵ+h(ϵ, M, λ, D) C−ϵ−h(ϵ, M,...
work page 2016
-
[41]
Let the guidance block size be B=d x/I. The number of tokens generated overIsteps is Ntokens = IX i=1 M(B+K(d x −iB)) =M d x +IM Kd x − 1 2 (I+ 1)M Kd x =M 1 + I−1 2 K dx. (54) Thus, the latency of ETS is approximately Ntokens/dx times that of a standard single-pass inference, which serves as a worst-case upper bound for both ARMs and DLMs. In practice, A...
work page 2025
-
[42]
and (Nie et al., 2025). Best-of-N is naturally integrated into our ETS framework as a special case, with detailed hyperparameters provided in Appendix C.2. For Beam Search, we use the standard implementation in the transformers (Wolf et al.,
work page 2025
-
[43]
to evaluate ARMs with original temperature t= 0.7 (refer to Appendix D.3), leveraging its parallel decoding via batching. For DLMs, we implement beam search ourselves; however, due to their iterative generation nature, DLMs cannot be accelerated via batching in the same way as ARMs. For Power Sampling (Karan & Du, 2025), we retain the original α= 0.25, N ...
work page 2025
-
[44]
Figure 10.Effect of temperature on ETS. We ablate the temperature on Qwen3-8B and plot GPQA accuracies (left) with corresponding latencies (right). Empirically, the optimal temperature is shared between Best-of-N and ETS with comparable latency (Chow et al., 2024), while Beam Search is insensitive to temperature (so we fixt= 0.7 ). Based on this, extensiv...
work page 2024
-
[45]
Based on this efficiency trade-off, we fix dx = 512for all main experiments on ARMs
are beneficial, due to their more complex reasoning chains. Based on this efficiency trade-off, we fix dx = 512for all main experiments on ARMs. For DLMs, we follow the original settings of LLaDA (in Table 4). Table 6.Performance across generation lengths. We ablate the dx on Qwen3-8B and bold the best accuracy value for each method across different gener...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.