ClawHub Security Signals: When VirusTotal, Static Analysis, and SkillSpector Disagree
Pith reviewed 2026-06-28 16:28 UTC · model grok-4.3
The pith
Three security scanners for AI agent skills agree on under 1 percent of flagged items with disagreement tied to attack surface.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Rather than estimating malicious-skill prevalence, the study shows that the three scanners rarely flag the same skills: any pair overlaps on at most 10.4% of their combined positives, only 0.69% of skills are flagged by all three, and 81.9% of flagged skills are identified by a single scanner. The disagreement is structured by attack surface, with SkillSpector positive for 75.3% of suspicious rows but only 6.8% of malicious rows. The malicious-verdict region shows the inverse profile with 72.8% of malicious rows VirusTotal-positive.
What carries the argument
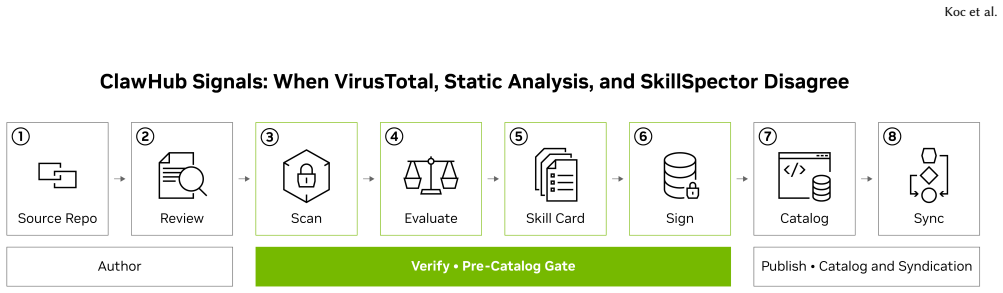
ClawHub Security Signals dataset of 67,453 skill versions paired with automated registry verdicts and evidence from VirusTotal, static analysis, and SkillSpector to quantify scanner disagreement.
If this is right
- Agent-skill security requires layered governance rather than single-scanner allow or block decisions.
- The released corpus supports development of models tailored for skill-security triage.
- Community research can build on this early snapshot while human-annotated subsets are developed.
Where Pith is reading between the lines
- The same structured disagreement pattern may appear when evaluating security of other reusable AI components such as plugins or workflows.
- A multi-scanner ensemble could increase detection coverage across both malware and semantic agentic risks.
- Registry verdicts could be refined by feeding high-disagreement cases into a human review loop.
Load-bearing premise
The registry's automated verdicts are sufficiently consistent to serve as a basis for quantifying scanner disagreement, even though they are not human-annotated ground truth.
What would settle it
A human-annotated ground-truth subset of the skills in which the reported overlap rates of 10.4 percent for pairs, 0.69 percent for all three, and 81.9 percent for single scanners differ substantially.
Figures
read the original abstract
Agent skills extend AI agents with reusable instructions, tools, scripts, references, and workflows, establishing a security boundary distinct from both model safety and traditional package-malware detection. ClawHub Security Signals is a sanitized dataset of 67,453 latest public OpenClaw skill versions. Each row pairs redacted SKILL.md content and sanitized bundled files where present with a final ClawScan registry verdict and evidence from three scanner families: VirusTotal, static heuristic analysis, and NVIDIA SkillSpector. Rather than estimating malicious-skill prevalence, we study scanner disagreement. The three scanners rarely flag the same skills: any pair overlaps on at most 10.4% of their combined positives, only 0.69% of skills are flagged by all three, and 81.9% of flagged skills are identified by a single scanner. The disagreement is structured by attack surface. SkillSpector, which raises semantic agentic-risk advisories rather than malware-reputation signals, is positive for 19,209 of 25,504 suspicious rows (75.3%) but only 14 of 206 malicious rows (6.8%). The malicious-verdict region shows the inverse profile: 150 of 206 malicious rows (72.8%) are VirusTotal-positive, consistent with bundled-code malware evidence. These results show that agent-skill security requires layered governance, not single-scanner allow/block decisions. The corpus is released as a sanitized silver-standard dataset: labels are the registry's automated verdicts, not human-annotated ground truth, and the release represents an early, versioned snapshot intended to support the community while a human-annotated subset is developed. Further research is encouraged, including models tailored for skill-security triage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the ClawHub Security Signals dataset of 67,453 sanitized OpenClaw skill versions. Each entry includes redacted SKILL.md content, sanitized files, a final ClawScan registry verdict, and signals from three scanners (VirusTotal, static heuristic analysis, and NVIDIA SkillSpector). The central claims are low scanner agreement (pairwise overlap at most 10.4% of combined positives, triple overlap 0.69%, 81.9% of flagged skills detected by only one scanner) and structured disagreement by attack surface, with SkillSpector positive on 75.3% of suspicious rows but only 6.8% of malicious rows, while VT is positive on 72.8% of malicious rows. The dataset is released as a silver-standard resource based on automated registry verdicts.
Significance. If the registry verdicts prove independent of the three scanner families, the observational results would usefully illustrate the limitations of single-scanner decisions for agent-skill security and motivate layered governance approaches. The public release of the versioned, sanitized corpus supplies a concrete starting point for community work on skill-specific triage models, even while the silver-standard caveat is stated.
major comments (1)
- [Abstract] Abstract: the manuscript states that each row includes both a 'final ClawScan registry verdict' and 'evidence from three scanner families' but provides no description of how the verdict is computed. The central stratification claim (SkillSpector positive for 75.3% of suspicious rows vs. 6.8% of malicious rows; VT positive for 72.8% of malicious rows) therefore cannot be evaluated for independence; if the verdict incorporates VT hits, static heuristics, or SkillSpector signals, the reported attack-surface structure is at least partly definitional rather than an independent finding about scanner disagreement.
minor comments (1)
- The abstract refers to 'sanitized bundled files where present' without describing the sanitization procedure or redaction criteria applied to SKILL.md content.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for identifying a key omission regarding the computation of the ClawScan registry verdict. This clarification is necessary to support the independence claims. We address the comment below and will incorporate the requested details in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states that each row includes both a 'final ClawScan registry verdict' and 'evidence from three scanner families' but provides no description of how the verdict is computed. The central stratification claim (SkillSpector positive for 75.3% of suspicious rows vs. 6.8% of malicious rows; VT positive for 72.8% of malicious rows) therefore cannot be evaluated for independence; if the verdict incorporates VT hits, static heuristics, or SkillSpector signals, the reported attack-surface structure is at least partly definitional rather than an independent finding about scanner disagreement.
Authors: We agree that the absence of a description of how the ClawScan registry verdict is computed is a significant gap that prevents readers from assessing independence. The current manuscript does not provide this information. In the revised version we will add a dedicated paragraph in the Dataset section (and reference it from the abstract) stating that the registry verdict is produced by an automated ClawScan registry process whose criteria are independent of the three scanner families; the VirusTotal, static-heuristic, and SkillSpector signals are collected after the verdict has been assigned and are not inputs to it. This addition will make the stratification claims evaluable as observations about scanner behavior rather than definitional artifacts. We will also update the abstract to point to the new description. revision: yes
Circularity Check
No circularity; purely observational reporting of dataset counts
full rationale
The manuscript contains no derivation chain, predictive model, ansatz, uniqueness theorem, or fitted parameter. All reported figures (pairwise overlaps ≤10.4%, triple overlap 0.69%, 81.9% single-scanner, SkillSpector 75.3% of suspicious rows vs 6.8% of malicious rows, VT 72.8% of malicious rows) are direct arithmetic on the released 67,453-row counts. The paper states explicitly that verdicts are the registry's automated outputs and that the labels are not human-annotated ground truth; it makes no claim that the verdict is independent of the three scanners. Because no step reduces a claimed result to its own inputs by construction, the circularity score is 0.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Percentages and overlaps are computed by direct division of counts from the 67,453-row dataset.
Forward citations
Cited by 1 Pith paper
-
Understanding and mitigating the risks of OpenClaw for non-technical users: A practical guide with Skill
This work categorizes seven risks of OpenClaw for non-technical users, provides plain-language mitigations, and supplies a companion Skill to automate security configurations.
Reference graph
Works this paper leans on
-
[1]
Moshe Abramovitch, Michael Boone, Sayali Kandarkar, Daniel Major, and Nir Paz. 2026. NVIDIA-Verified Agent Skills Provide Capability Governance for AI Agents. NVIDIA Technical Blog. https://developer.nvidia.com/blog/nvidia- verified-agent-skills-provide-capability-governance-for-ai-agents/
2026
-
[2]
Alex and Oren Yomtov. 2026. ClawHavoc: 341 Malicious Clawed Skills Found by the Bot They Were Targeting. https://www.koi.ai/blog/clawhavoc-341-malicious- clawedbot-skills-found-by-the-bot-they-were-targeting. Koi Research; accessed 31 May 2026
2026
-
[3]
Ron Artstein and Massimo Poesio. 2008. Survey Article: Inter-Coder Agreement for Computational Linguistics.Computational Linguistics34, 4 (2008), 555–596. doi:10.1162/coli.07-034-R2
-
[4]
Emily M. Bender and Batya Friedman. 2018. Data Statements for Natural Lan- guage Processing: Toward Mitigating System Bias and Enabling Better Science. Transactions of the Association for Computational Linguistics6 (2018), 587–604. doi:10.1162/tacl_a_00041
-
[5]
Al Bessey, Ken Block, Ben Chelf, Andy Chou, Bryan Fulton, Seth Hallem, Charles Henri-Gros, Asya Kamsky, Scott McPeak, and Dawson Engler. 2010. A Few Koc et al. Billion Lines of Code Later: Using Static Analysis to Find Bugs in the Real World. Commun. ACM53, 2 (2010), 66–75. doi:10.1145/1646353.1646374
-
[6]
Arnold Cartagena and Ariane Teixeira. 2026. Mind the GAP: Text Safety Does Not Transfer to Tool-Call Safety in LLM Agents. arXiv:2602.16943 [cs.AI] https: //arxiv.org/abs/2602.16943
arXiv 2026
-
[7]
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, Vol. 37. doi:10.52202/079017-2636
-
[8]
Ruian Duan, Omar Alrawi, Ranjita Pai Kasturi, Ryan Elder, Brendan Saltafor- maggio, and Wenke Lee. 2021. Towards Measuring Supply Chain Attacks on Package Managers for Interpreted Languages. InProceedings of the 28th Network and Distributed System Security Symposium (NDSS). doi:10.14722/ndss.2021.23055
-
[9]
Elliott, Tari Turner, Ornella Clavisi, James Thomas, Julian P
Julian H. Elliott, Tari Turner, Ornella Clavisi, James Thomas, Julian P. T. Higgins, Chris Mavergames, and Russell L. Gruen. 2014. Living Systematic Reviews: An Emerging Opportunity to Narrow the Evidence-Practice Gap.PLoS Medicine11, 2 (2014), e1001603. doi:10.1371/journal.pmed.1001603
-
[10]
Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. 2024. LLM Agents can Autonomously Exploit One-day Vulnerabilities. arXiv:2404.08144 [cs.CR] https://arxiv.org/abs/2404.08144
Pith/arXiv arXiv 2024
-
[11]
Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. 2024. LLM Agents can Autonomously Hack Websites. arXiv:2402.06664 [cs.CR] https: //arxiv.org/abs/2402.06664
arXiv 2024
-
[12]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. Datasheets for Datasets. Commun. ACM64, 12 (2021), 86–92. doi:10.1145/3458723
-
[13]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security. 79–90. doi:10.1145/3605764.3623985
-
[14]
Wenbo Guo, Zhengzi Xu, Chengwei Liu, Cheng Huang, Yong Fang, and Yang Liu. 2023. An Empirical Study of Malicious Code In PyPI Ecosystem. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). doi:10.1109/ASE56229.2023.00135 arXiv:2309.11021
-
[15]
Zihan Guo, Zhiyu Chen, Xiaohang Nie, Jianghao Lin, Yuanjian Zhou, and Weinan Zhang. 2026. SkillProbe: Security Auditing for Emerging Agent Skill Marketplaces via Multi-Agent Collaboration. arXiv:2603.21019 [cs.CR] https: //arxiv.org/abs/2603.21019
arXiv 2026
-
[16]
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. 2025. Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions. arXiv:2503.23278 [cs.CR] https://arxiv.org/abs/2503.23278
Pith/arXiv arXiv 2025
-
[17]
Invariant Labs. 2025. MCP Security Notification: Tool Poisoning Attacks. In- variant Labs blog. https://invariantlabs.ai/blog/mcp-security-notification-tool- poisoning-attacks
2025
-
[18]
Umar Iqbal, Tadayoshi Kohno, and Franziska Roesner. 2024. LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI’s ChatGPT Plugins. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 7. 611–623. arXiv:2309.10254 [cs.CR] doi:10.1609/aies.v7i1.31664
-
[19]
Brittany Johnson, Yoonki Song, Emerson Murphy-Hill, and Robert Bowdidge
-
[20]
InProceedings of the 35th International Conference on Software Engineering (ICSE)
Why Don’t Software Developers Use Static Analysis Tools to Find Bugs?. InProceedings of the 35th International Conference on Software Engineering (ICSE). 672–681. doi:10.1109/ICSE.2013.6606613
-
[21]
Vincent Koc, Jacques Verre, Douglas Blank, and Abigail Morgan. 2025. Mind the Metrics: Patterns for Telemetry-Aware In-IDE AI Application Development using the Model Context Protocol (MCP). arXiv:2506.11019 [cs.SE] https://arxiv. org/abs/2506.11019
arXiv 2025
-
[22]
Deepak Kumar, Riccardo Paccagnella, Paul Murley, Eric Hennenfent, Joshua Mason, Adam Bates, and Michael Bailey. 2018. Skill Squatting Attacks on Amazon Alexa. InProceedings of the 27th USENIX Security Symposium. 33–47
2018
-
[23]
Piergiorgio Ladisa, Serena Elisa Ponta, Nicola Ronzoni, Matias Martinez, and Olivier Barais. 2023. On the Feasibility of Cross-Language Detection of Malicious Packages in npm and PyPI. InAnnual Computer Security Applications Conference (ACSAC ’23). doi:10.1145/3627106.3627138 arXiv:2310.09571
-
[24]
Christopher Lentzsch, Sheel Jayesh Shah, Benjamin Andow, Martin Degeling, Anupam Das, and William Enck. 2021. Hey Alexa, is this Skill Safe?: Taking a Closer Look at the Alexa Skill Ecosystem. InProceedings of the 28th Network and Distributed System Security Symposium (NDSS). doi:10.14722/ndss.2021.23111
-
[25]
Zhiyuan Li, Jingzheng Wu, Xiang Ling, Xing Cui, and Tianyue Luo. 2026. Towards Secure Agent Skills: Architecture, Threat Taxonomy, and Security Analysis. arXiv:2604.02837 [cs.CR] https://arxiv.org/abs/2604.02837
Pith/arXiv arXiv 2026
-
[26]
Yi Liu, Zhihao Chen, Yanjun Zhang, Gelei Deng, Yuekang Li, Jianting Ning, Ying Zhang, and Leo Yu Zhang. 2026. Malicious Agent Skills in the Wild: A Large-Scale Security Empirical Study. arXiv:2602.06547 [cs.CR] https://arxiv. org/abs/2602.06547
Pith/arXiv arXiv 2026
-
[27]
Yi Liu, Weizhe Wang, Ruitao Feng, Yao Zhang, Guangquan Xu, Gelei Deng, Yuekang Li, and Leo Zhang. 2026. Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale. arXiv:2601.10338 [cs.CR] https://arxiv.org/ abs/2601.10338
Pith/arXiv arXiv 2026
-
[28]
Microsoft. 2026. How Microsoft Identifies Malware and Potentially Unwanted Ap- plications. https://learn.microsoft.com/en-us/unified-secops/criteria. Accessed 31 May 2026
2026
-
[29]
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model Cards for Model Reporting. InProceedings of the Conference on Fairness, Accountability, and Transparency. 220–229. doi:10.1145/3287560.3287596
-
[30]
José Miguel Moreno, Narseo Vallina-Rodriguez, and Juan Tapiador. 2024. Did I Vet You Before? Assessing the Chrome Web Store Vetting Process through Browser Extension Similarity. arXiv:2406.00374 [cs.CR] https://arxiv.org/abs/2406.00374
arXiv 2024
-
[31]
National Institute of Standards and Technology. 2023. Artificial Intelligence Risk Management Framework (AI RMF 1.0). doi:10.6028/NIST.AI.100-1
-
[32]
NVIDIA. 2026. Scan Agent Skills Before Installation. NVIDIA Skill Documenta- tion. https://docs.nvidia.com/skills/scanning-agent-skills
2026
-
[33]
NVIDIA. 2026. Trust Controls for Agent Skills. NVIDIA Skill Documentation. https://docs.nvidia.com/skills
2026
-
[34]
NVIDIA. 2026. Write Skill Cards People Can Trust. NVIDIA Skill Documentation. https://docs.nvidia.com/skills/skill-cards
2026
-
[35]
Marc Ohm, Henrik Plate, Arnold Sykosch, and Michael Meier. 2020. Backstabber’s Knife Collection: A Review of Open Source Software Supply Chain Attacks. In Detection of Intrusions and Malware, and Vulnerability Assessment (DIMV A 2020) (LNCS, Vol. 12223). 23–43. doi:10.1007/978-3-030-52683-2_2
-
[36]
OWASP Foundation. 2026. OWASP Agentic Skills Top 10. https://owasp.org/ www-project-agentic-skills-top-10/
2026
-
[37]
OWASP Gen AI Security Project. 2025. OWASP Top 10 for LLM Applications 2025. https://genai.owasp.org/resource/owasp-top-10-for-llm-applications-2025/
2025
-
[38]
OWASP Gen AI Security Project. 2026. OWASP Top 10 for Agentic Applications
2026
-
[39]
https://genai.owasp.org/resource/owasp-top-10-for-agentic-applications- for-2026/
2026
-
[40]
Nir Paz, Keshav Pradeep, Narendran Raghavan, Ashley Nikirk, Yashraj Basavaraj Patil, and Mohit Gupta. 2026. SkillSpector: A Pre-Publication Security Control for Agent Skills. OpenReview / AgentSkills 2026 Poster. https://openreview.net/ forum?id=rVAPXHmGHN
2026
-
[41]
Fábio Perez and Ian Ribeiro. 2022. Ignore Previous Prompt: Attack Techniques For Language Models. arXiv:2211.09527 [cs.CL] https://arxiv.org/abs/2211.09527
Pith/arXiv arXiv 2022
-
[42]
Brandon Radosevich and John Halloran. 2025. MCP Safety Audit: LLMs with the Model Context Protocol Allow Major Security Exploits. arXiv:2504.03767 [cs.CR] https://arxiv.org/abs/2504.03767
arXiv 2025
-
[43]
Bach, Henry Ehrenberg, Jason Fries, Sen Wu, and Christopher Ré
Alexander Ratner, Stephen H. Bach, Henry Ehrenberg, Jason Fries, Sen Wu, and Christopher Ré. 2020. Snorkel: Rapid Training Data Creation with Weak Supervision.The VLDB Journal29, 2 (2020), 709–730. doi:10.1007/s00778-019- 00552-1
-
[44]
van Mulligen, Ning Kang, Jan Kors, David Milward, Peter Corbett, Ekaterina Buyko, Katrin Tomanek, Elena Beisswanger, and Udo Hahn
Dietrich Rebholz-Schuhmann, Antonio José Jimeno Yepes, Erik M. van Mulligen, Ning Kang, Jan Kors, David Milward, Peter Corbett, Ekaterina Buyko, Katrin Tomanek, Elena Beisswanger, and Udo Hahn. 2010. The CALBC Silver Standard Corpus for Biomedical Named Entities — A Study in Harmonizing the Contri- butions from Four Independent Named Entity Taggers. InPro...
2010
-
[45]
Nusrat Zahan, Philipp Burckhardt, Mikola Lysenko, Feross Aboukhadijeh, and Laurie Williams. 2024. MalwareBench: Malware Samples are Not Enough. In Proceedings of the 21st International Conference on Mining Software Repositories (MSR ’24). 728–732. doi:10.1145/3643991.3644883
-
[46]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. InFindings of the Association for Computational Linguistics: ACL
2024
-
[47]
doi:10.18653/v1/2024.findings-acl.624
Association for Computational Linguistics, Bangkok, Thailand, 10471– 10506. doi:10.18653/v1/2024.findings-acl.624
-
[48]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track. https://arxiv.org/ab...
Pith/arXiv arXiv 2023
-
[49]
Markus Zimmermann, Cristian-Alexandru Staicu, Cam Tenny, and Michael Pradel. 2019. Small World with High Risks: A Study of Security Threats in the npm Ecosystem. InProceedings of the 28th USENIX Security Symposium. 995–1010
2019
-
[50]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2025. Poisone- dRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language Models. In34th USENIX Security Symposium (USENIX Security 25). USENIX Association, Seattle, WA, 3827–3844. https://www.usenix.org/ conference/usenixsecurity25/presentation/zou-poisonedrag
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.