GraphFlow: A Graph-Based Workflow Management for Efficient LLM-Agent Serving
Pith reviewed 2026-05-22 07:14 UTC · model grok-4.3
The pith
Representing workflows as a unified graph of atomic operations lets LLM agents generate task-specific instructions dynamically and reuse computations for better efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a unified graph called wGraph, with each node as an atomic operation, provides a shared substrate from which task-specific workflows are dynamically instantiated based on semantics and constraints, and that exploiting the graph's structure for Key-Value cache management during serving reduces redundant computation, yielding better performance and lower memory use than template-based systems.
What carries the argument
wGraph, the unified graph in which nodes represent atomic operations and from which task-specific workflows are dynamically constructed while guiding KV cache reuse.
If this is right
- Task-specific workflows can be assembled from the shared graph without requiring a new template for every novel instruction.
- KV cache management guided by graph connections avoids recomputing common operation sequences across different tasks.
- The combined designs produce measurable gains in task completion rates while lowering the memory needed to run the agent.
- Workflow integration happens inside the serving loop rather than as a separate preprocessing step.
Where Pith is reading between the lines
- Extending the set of atomic nodes over time could let the system support progressively more complex agent behaviors without redesigning the core infrastructure.
- Similar graph substrates might be constructed for planning in non-LLM agents such as robotic controllers if their primitive actions can be enumerated.
- The memory savings would likely increase in long multi-turn interactions where many workflow fragments overlap.
Load-bearing premise
A unified graph of atomic operations can capture deep semantic relationships and support generalization to unseen tasks more effectively than predefined templates and shallow matching.
What would settle it
Running GraphFlow on a collection of tasks whose required operations lie entirely outside the atomic nodes defined in the initial wGraph and checking whether accuracy falls to the level of template baselines would test the generalization claim.
Figures






read the original abstract
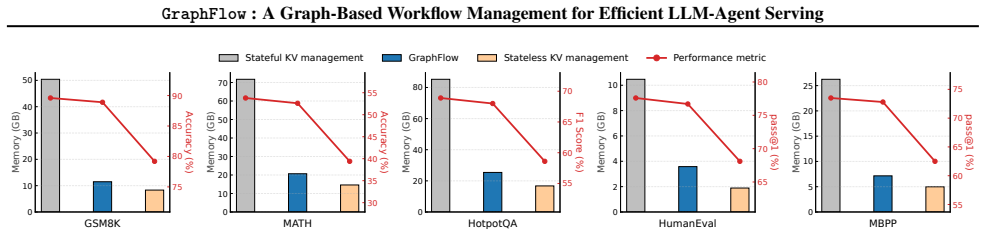
Large Language Model (LLM)-based agents demonstrate strong reasoning and execution capabilities on complex tasks when guided by structured instructions, commonly referred to as workflows. However, existing workflow-assisted agent serving systems typically rely on predefined templates and shallow matching mechanisms, which limit their ability to capture deep semantic relationships and generalize to previously unseen tasks. To address these limitations, we propose a new workflow management paradigm that represents workflows using a unified graph, termed wGraph, where each node corresponds to an atomic operation. wGraph serves as a shared substrate from which task-specific workflows are dynamically instantiated. Building on wGraph primitives, we introduce GraphFlow, a system that efficiently integrates workflows into agent serving through two key designs. First, adaptive workflow generation dynamically constructs workflows from wGraph based on task semantics and constraint requirements. Second, workflow state management exploits wGraph structure to efficiently manage Key-Value (KV) caches, reducing redundant computation during agent serving. Extensive experiments across five benchmark datasets show that GraphFlow consistently outperforms state-of-the-art methods, yielding an average performance improvement of approximately 4.95 percentage points, while achieving an approximately 4$\times$ reduction in memory footprint.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GraphFlow, a graph-based workflow management system for efficient LLM-agent serving. Workflows are represented via a unified graph (wGraph) whose nodes are atomic operations; task-specific workflows are dynamically instantiated from this shared substrate. The system introduces two main designs: adaptive workflow generation that constructs workflows from wGraph according to task semantics and constraints, and workflow state management that exploits wGraph structure for KV-cache reuse to reduce redundant computation. Experiments on five benchmark datasets report an average performance gain of approximately 4.95 percentage points and an approximately 4× reduction in memory footprint relative to state-of-the-art methods.
Significance. If the reported gains are reproducible under standard controls, the work offers a practical advance in LLM-agent serving by replacing rigid template-based workflows with a more flexible, graph-structured substrate that supports better generalization. The KV-cache exploitation mechanism is a concrete engineering contribution that directly targets memory efficiency in long-horizon agent execution.
major comments (1)
- [Abstract and experimental evaluation] Abstract and experimental evaluation: the central claim of consistent outperformance (4.95 pp average gain) and 4× memory reduction is presented without any description of baselines, statistical significance testing, variance across runs, or implementation details of the adaptive generation procedure. This information is load-bearing for assessing whether the gains are attributable to the proposed wGraph design rather than experimental artifacts.
minor comments (1)
- The term 'wGraph' is introduced without an accompanying formal definition or illustrative diagram in the main text; a small example graph with node/edge semantics would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below and will revise the paper to improve clarity and rigor in the presentation of results.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation] Abstract and experimental evaluation: the central claim of consistent outperformance (4.95 pp average gain) and 4× memory reduction is presented without any description of baselines, statistical significance testing, variance across runs, or implementation details of the adaptive generation procedure. This information is load-bearing for assessing whether the gains are attributable to the proposed wGraph design rather than experimental artifacts.
Authors: We agree that the abstract and experimental evaluation would benefit from greater specificity to allow readers to fully assess the source of the reported gains. In the revised manuscript we will (1) expand the abstract to name the concrete state-of-the-art baselines used for comparison, (2) add statistical significance testing (paired t-tests with p-values) and report standard deviations or confidence intervals across repeated runs in the main results tables, and (3) insert a concise but explicit description of the adaptive workflow generation procedure, including the core algorithm, semantic matching criteria, and key hyperparameters. These additions will be placed in both the abstract and the experimental section so that the attribution of improvements to the wGraph substrate is transparent. We do not believe any new experiments are required; the existing data already support the claims once the missing details are supplied. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an engineering system (wGraph as shared substrate, adaptive workflow generation from task semantics, and KV-cache management exploiting graph structure) whose performance claims are presented as direct outcomes of experiments on five benchmark datasets. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text. The central claims rest on empirical evaluation rather than reducing to inputs by construction, self-citation chains, or ansatz smuggling. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Workflows can be represented as graphs with atomic operations as nodes that serve as a shared substrate for dynamic instantiation.
invented entities (1)
-
wGraph
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
wGraph ... each node corresponds to an atomic operation ... task-specific workflows are dynamically instantiated ... GNN-based representation learning ... differential-based KV cache ... KV(P, v) = KVbase(v) + ΔKV(P, v)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
topology-aware state management ... effective path pruning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Workflowllm: Enhanc- ing workflow orchestration capability of large language models
Fan, S., Cong, X., Fu, Y ., Zhang, Z., Zhang, S., Liu, Y ., Wu, Y ., Lin, Y ., Liu, Z., and Sun, M. Workflowllm: Enhanc- ing workflow orchestration capability of large language models. InInternational Conference on Learning Repre- sentations, volume 2025, pp. 24498–24525,
work page 2025
-
[5]
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Fourney, A., Bansal, G., Mozannar, H., Tan, C., Salinas, E., Niedtner, F., Proebsting, G., Bassman, G., Gerrits, J., Alber, J., et al. Magentic-one: A generalist multi- agent system for solving complex tasks.arXiv preprint arXiv:2411.04468,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Metagpt: Meta programming for a multi-agent collaborative frame- work
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y ., Wang, J., Zhang, C., Yau, S., Lin, Z., Zhou, L., et al. Metagpt: Meta programming for a multi-agent collaborative frame- work. InInternational Conference on Learning Repre- sentations, volume 2024, pp. 23247–23275,
work page 2024
-
[8]
Categorical Reparameterization with Gumbel-Softmax
Jang, E., Gu, S., and Poole, B. Categorical repa- rameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
P., Yao, Y ., Wei, J., Paul, D., et al
Josifoski, M., Klein, L., Peyrard, M., Baldwin, N., Li, Y ., Geng, S., Schnitzler, J. P., Yao, Y ., Wei, J., Paul, D., et al. Flows: Building blocks of reasoning and collaborating ai. arXiv preprint arXiv:2308.01285,
-
[10]
Dspy: compiling declarative language model calls into state-of-the-art pipelines
Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., San- thanam, K., Haq, S., Sharma, A., Joshi, T., Moazam, H., Miller, H., et al. Dspy: compiling declarative language model calls into state-of-the-art pipelines. InInterna- tional Conference on Learning Representations, volume 2024, pp. 54928–54958,
work page 2024
-
[11]
Kipf, T. N. and Welling, M. Semi-supervised classifica- tion with graph convolutional networks.arXiv preprint arXiv:1609.02907,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Autoflow: Automated workflow generation for large language model agents
Li, Z., Xu, S., Mei, K., Hua, W., Rama, B., Raheja, O., Wang, H., Zhu, H., and Zhang, Y . Autoflow: Automated workflow generation for large language model agents. arXiv preprint arXiv:2407.12821,
-
[13]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
MemGPT: Towards LLMs as Operating Systems
Packer, C., Wooders, S., Lin, K., Fang, V ., Patil, S. G., Stoica, I., and Gonzalez, J. E. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Taskweaver: A code-first agent framework.arXiv preprint arXiv:2311.17541,
Qiao, B., Li, L., Zhang, X., He, S., Kang, Y ., Zhang, C., Yang, F., Dong, H., Zhang, J., Wang, L., et al. Taskweaver: A code-first agent framework.arXiv preprint arXiv:2311.17541,
-
[16]
Benchmarking agen- tic workflow generation
Qiao, S., Fang, R., Qiu, Z., Wang, X., Zhang, N., Jiang, Y ., Xie, P., Huang, F., and Chen, H. Benchmarking agen- tic workflow generation. InInternational Conference on Learning Representations, volume 2025, pp. 69679– 69703,
work page 2025
-
[17]
Agentsquare: Automatic llm agent search in modular design space
Shang, Y ., Li, Y ., Zhao, K., Ma, L., Liu, J., Xu, F., and Li, Y . Agentsquare: Automatic llm agent search in modular design space. InInternational Conference on Learning Representations, volume 2025, pp. 3841–3865,
work page 2025
-
[18]
Flowmesh: A service fabric for composable llm workflows.arXiv preprint arXiv:2510.26913,
Shen, J., Wadlom, N., Zhou, L., Wang, D., Miao, X., Fang, L., and Lu, Y . Flowmesh: A service fabric for composable llm workflows.arXiv preprint arXiv:2510.26913,
-
[19]
Agent kb: Leveraging cross-domain experience for agentic problem solving
Tang, X., Qin, T., Peng, T., Zhou, Z., Shao, D., Du, T., Wei, X., Xia, P., Wu, F., Zhu, H., et al. Agent kb: Leveraging cross-domain experience for agentic problem solving. arXiv preprint arXiv:2507.06229,
-
[20]
Gemma 2: Improving Open Language Models at a Practical Size
Team, G., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahri- ari, B., Ram ´e, A., et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, G., Xie, Y ., Jiang, Y ., Mandlekar, A., Xiao, C., Zhu, Y ., Fan, L., and Anandkumar, A. V oyager: An open- ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023a. Wang, J., Xu, H., Jia, H., Zhang, X., Yan, M., Shen, W., Zhang, J., Huang, F., and Sang, J. Mobile-agent-v2: Mo- bile device operation assistant with effec...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Wang, W., Ma, Z., Wang, Z., Wu, C., Ji, J., Chen, W., Li, X., and Yuan, Y . A survey of llm-based agents in medicine: How far are we from baymax?Findings of the Association for Computational Linguistics: ACL 2025, pp. 10345–10359, 2025a. Wang, Z. Z., Mao, J., Fried, D., and Neubig, G. Agent work- flow memory. InInternational Conference on Machine Learning...
work page 2025
-
[23]
Wu, Y ., Yue, T., Zhang, S., Wang, C., and Wu, Q. State- flow: Enhancing llm task-solving through state-driven workflows.arXiv preprint arXiv:2403.11322,
-
[24]
Flowbench: Revisiting and bench- marking workflow-guided planning for llm-based agents
Xiao, R., Ma, W., Wang, K., Wu, Y ., Zhao, J., Wang, H., Huang, F., and Li, Y . Flowbench: Revisiting and bench- marking workflow-guided planning for llm-based agents. InFindings of the Association for Computational Linguis- tics: EMNLP 2024, pp. 10883–10900,
work page 2024
-
[25]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhut- dinov, R., and Manning, C. D. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 conference on empirical methods in natural language processing, pp. 2369–2380,
work page 2018
-
[27]
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T., Cao, Y ., and Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023a. Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., and Cao, Y . React: Synergizing reasoning and acting in lang...
-
[28]
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
Zhou, A., Yan, K., Shlapentokh-Rothman, M., Wang, H., and Wang, Y .-X. Language agent tree search unifies reasoning acting and planning in language models.arXiv preprint arXiv:2310.04406,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Zhu, X., Chen, Y ., Tian, H., Tao, C., Su, W., Yang, C., Huang, G., Li, B., Lu, L., Wang, X., et al. Ghost in the minecraft: Generally capable agents for open- world environments via large language models with text-based knowledge and memory.arXiv preprint arXiv:2305.17144,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
11 GraphFlow: A Graph-Based Workflow Management for Efficient LLM-Agent Serving A. Experimental and Implementation Details Data Preparation and Graph Construction.To construct the supervision dataset, we leverage GPT-4o to synthesize high-quality execution traces for queries in the training corpus. These traces are parsed to extract atomic operations and ...
work page 2020
-
[31]
during training. Edge selection is approximated as: ˜si,j =σ ωij +g ij τ , g ij ∼Gumbel(0,1),(12) where τ is a temperature hyperparameter. This relaxation bridges the gap between the discrete graph topology and continuous gradient updates (Fu et al., 2026; Wang et al., 2026). Inference: Constrained Decoding.During inference, we bypass the stochastic relax...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.